




点击蓝字⬆ 关注我们
本文共计2083字 预计阅读时长7分钟
什么是RAG?
随着数据智能技术的不断发展,以大语言模型(LLM)驱动的AIGC为代表的内容生成技术已经成为企业数据智能能力中不可或缺的一部分。但在实践过程中,LLM(例如ChatGPT)仍存在不少问题,例如信息更新不及时、垂直领域知识匮乏,且可能产生“幻觉”(即生成不准确的内容)等问题。
检索增强生成(Retrieval-Augmented Generation,RAG)技术是一种结合了检索和大语言模型内容生成的技术方案,它通过引用外部知识库,在用户输入Query时检索出知识,然后让模型基于可信的知识进行用户回答。RAG具有较高的可解释性和定制能力,可大幅降低大语言模型的幻觉,适用于问答系统、文档生成、智能助手等多种自然语言处理任务。
本篇文章,将手把手教你基于腾讯云ES与TI-ONE平台,搭建专属AI知识库与DeepSeek大模型,让你快速拥有一个更安全、更懂你、且不会“服务器繁忙,请稍后再试”的AI助手。
为什么选择腾讯云ES?
腾讯云ES是云端全托管海量数据检索分析服务,拥有高性能自研内核,集成X-Pack,支持通过自治索引、存算分离、集群巡检等特性轻松管理集群,也支持免运维、自动弹性、按需使用的 Serverless 模式。在RAG方面,腾讯云ES支持了一站式向量检索、文本+向量混合搜索、倒数排序融合、与大模型集成、GPU高性能推理、字段级别权限控制等能力,同时针对查询性能做了大量优化,有效的提升了数据检索效率,目前已落地微信读书“AI 问书”、微信输入法“问 AI”、腾讯地图、腾讯会议、IMA Copilot、乐享智能搜索等大型应用中。
同时,作为国内公有云首个从自然语言处理、到向量生成/存储/检索、并与大模型集成的端到端一站式技术平台,腾讯云ES作为核心参编单位参与了由中国信通院发起的的RAG标准制定,并成为首个通过RAG权威认证的企业。
通过腾讯云ES,你可以根据自身需求,灵活定制知识库的内容与功能, 打造更懂你、更安全、更可控的专属AI助手。
为什么使用TI-ONE部署大模型?
腾讯云 TI-ONE 训练平台(简称TI-ONE)是为 AI 工程师打造的一站式机器学习平台,为用户提供从数据接入、模型训练、模型管理到模型服务的全流程开发支持。TI-ONE 支持多种训练方式和算法框架,满足不同 AI 应用场景的需求。当前,TI-ONE已在控制台支持了一系列DeepSeek模型的可视化部署,通过TI-ONE平台,我们可在数分钟内快速拉起DeepSeek相关服务,告别“服务器繁忙,请稍后再试”。
AI 助手构建
购买ES 集群
1、登录腾讯云ES控制台
2、点击新建:
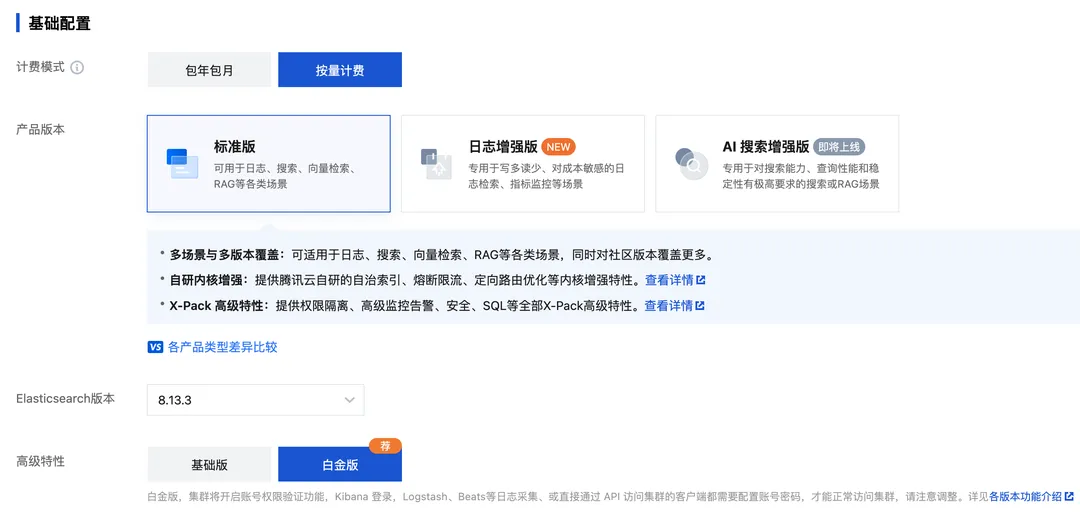
3、计费模式为按量计费,产品版本为标准版、ES 版本为 8.13.3、商业特性为白金版:
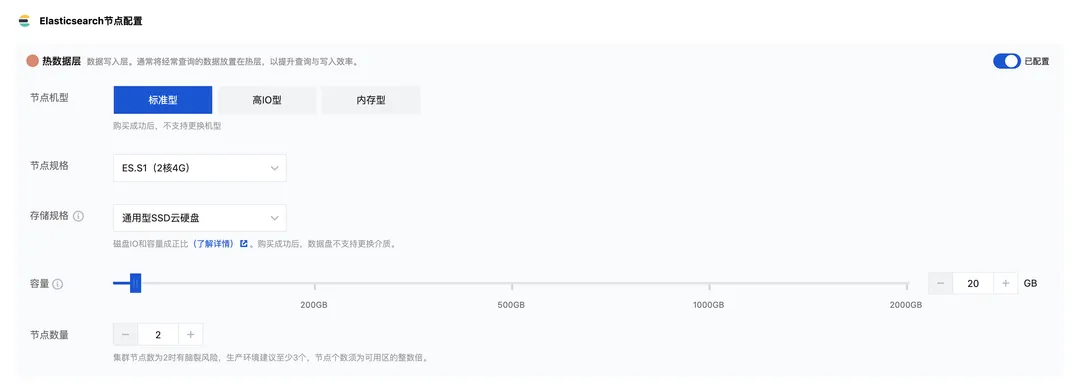
ES 节点配置,测试环境可选择为ES.S1(4核8G),节点数为2,磁盘为通用型SSD,磁盘容量为 20GB:
登录Kibana
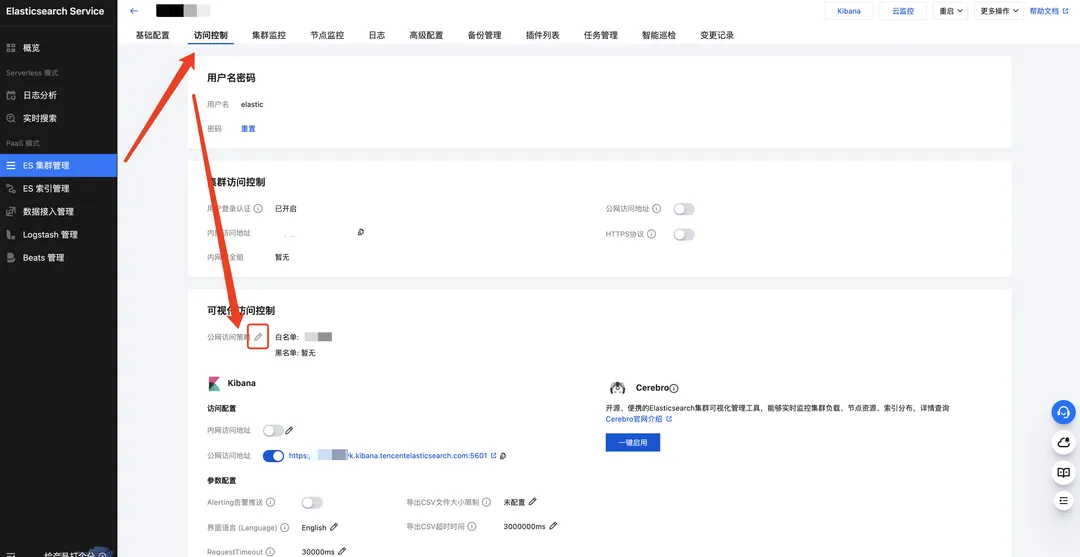
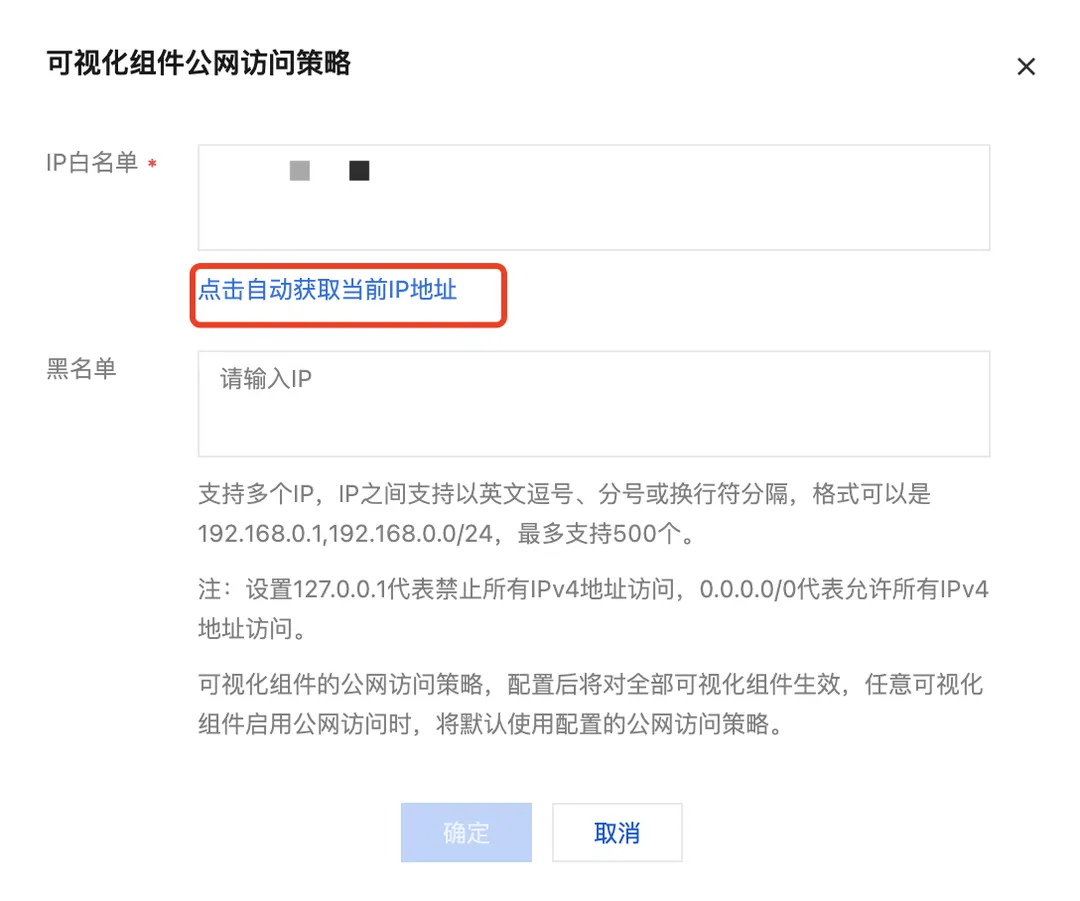
1、集群创建完成后,点击集群名称,进入访问控制页面,在可视化访问控制设置公网访问策略:
2、获取当前 IP 地址并设置到 IP 白名单中:
3、点击Kibana公网访问地址访问Kibana。
部署embedding 模型
在集群购买完成后,就可以前往Kibana部署Embedding模型、创建知识库索引与向量化管道:
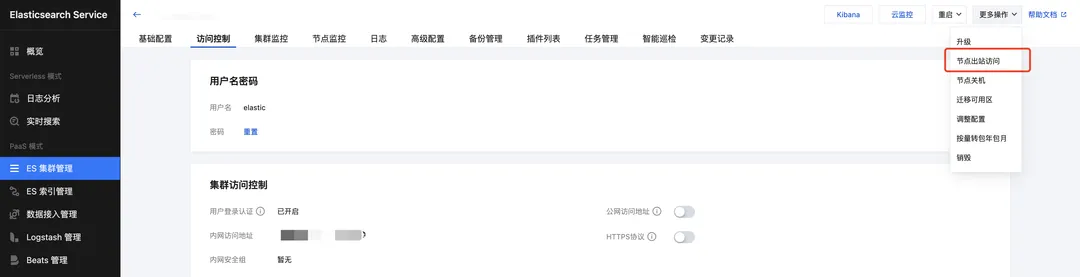
1、开启「节点出站访问」,仅开启数据节点即可,如有专用主节点,仅开启专用主节点即可。(该功能为白名单,请联系工单处理):
注:如需上传自定义模型或第三方平台(如 Huggingface)模型,可参考
https://github.com/elastic/eland
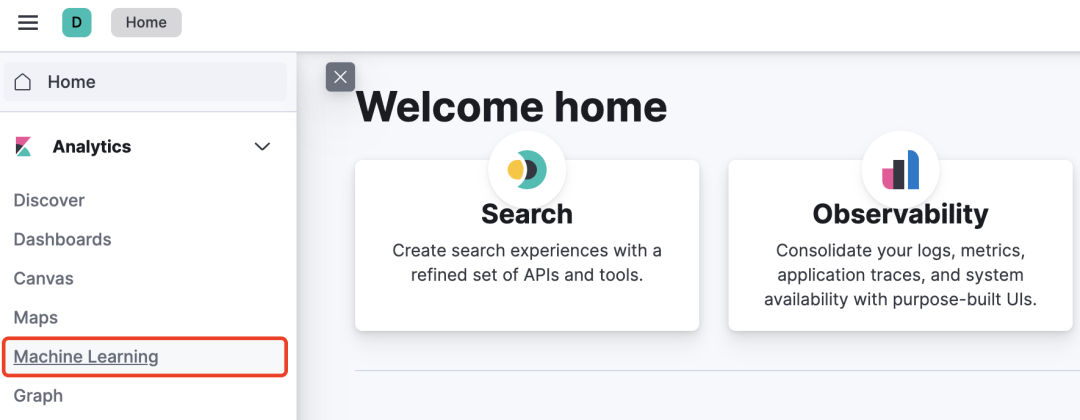
2、登录Kibana之后,在左侧导航栏找到Machine Learning功能:
3、进入模型管理页面,并找到类型为text_embedding的模型:
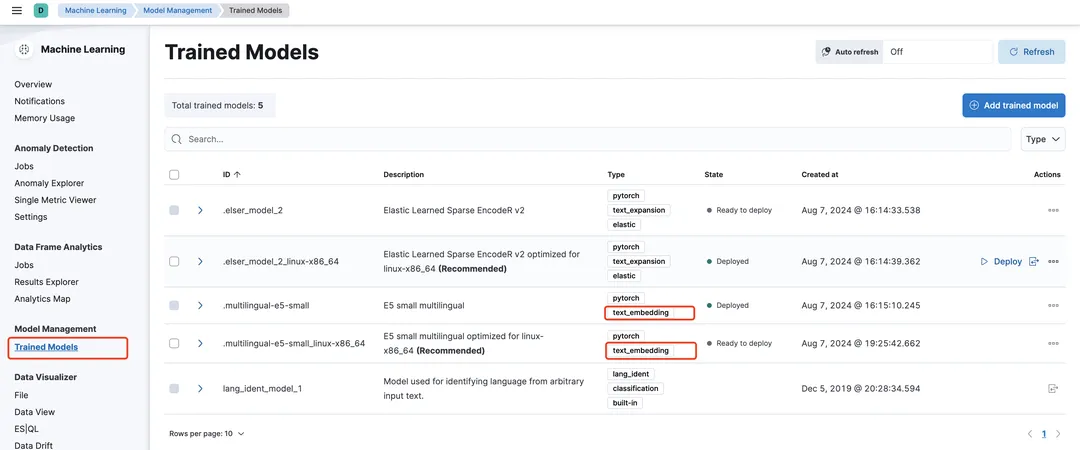
4、如为未下载状态,选中模型,并点击Add trained model,本次演示我们使用.multilingual-e5-small模型,这是一个 384 维的多语言模型:
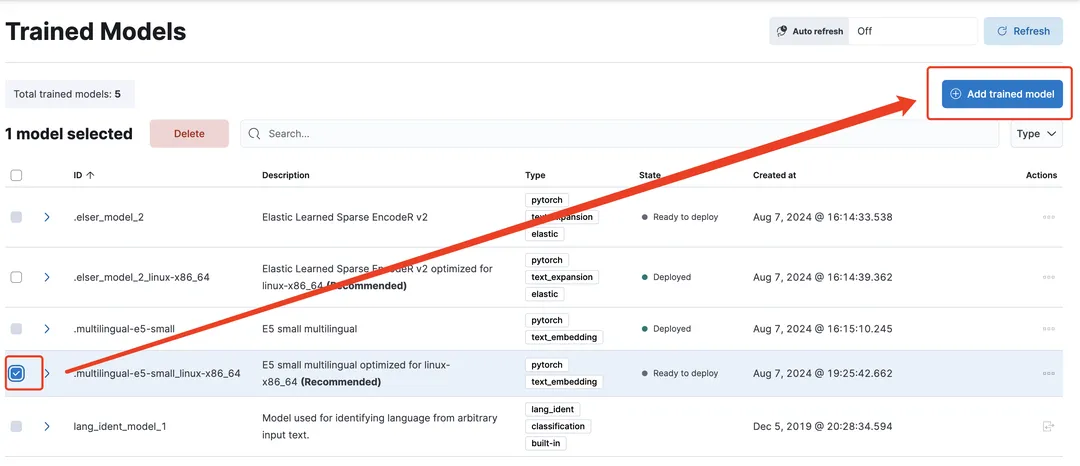
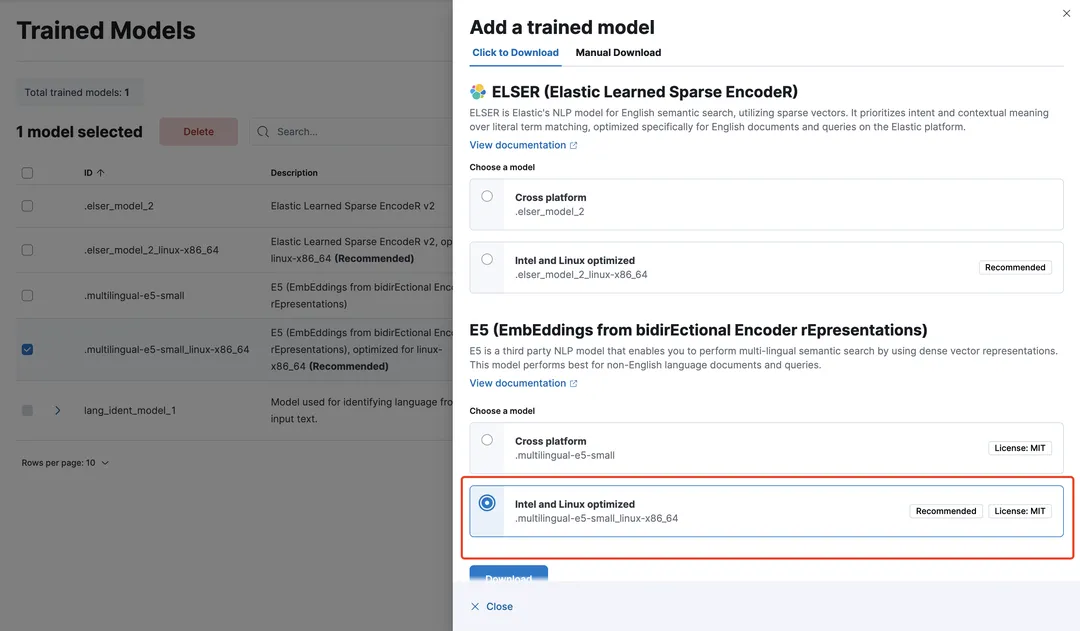
5、下载完成后,点击Deploy,弹窗信息使用默认值即可:

创建索引与向量化管道
1、在Kibana页面点击进入Dev tools:
2、创建知识库索引:index-name为索引名称,实际可按需命名。
PUT index-name{"mappings": {"properties": {"title": {"type": "keyword"},"content": {"type": "text"},"url": {"type": "keyword"},"content_embedding": {"type": "dense_vector","dims": 384}}}}
3、创建推理管道,该管道可用于写入数据时进行数据向量化。
PUT _ingest/pipeline/index-name-pipeline{"description": "Text embedding pipeline","processors": [{"inference": {"model_id": ".multilingual-e5-small_linux-x86_64","input_output": [{"input_field": "content","output_field": "content_embedding"},{"input_field": "title","output_field": "title_embedding"}]}}]}
上述管道,将字段「content、title」的内容,调用.multilingual-e5-small模型向量化之后存储到新的字段中。
写入知识库数据
通过 Bulk API 批量写入数据,可将 title 、content 、url 的内容替换为实际的知识库数据。
POST index-name/_bulk?pipeline=index-name-pipeline&refresh{ "index" : {} }{ "title" : "标题 1","content": "内容 1","url": "https:url1" }{ "index" : {} }{ "title" : "标题 2","content": "内容 2","url": "https:url2" }
基于TI-ONE平台部署DeepSeek模型
1、登录TI-ONE控制台
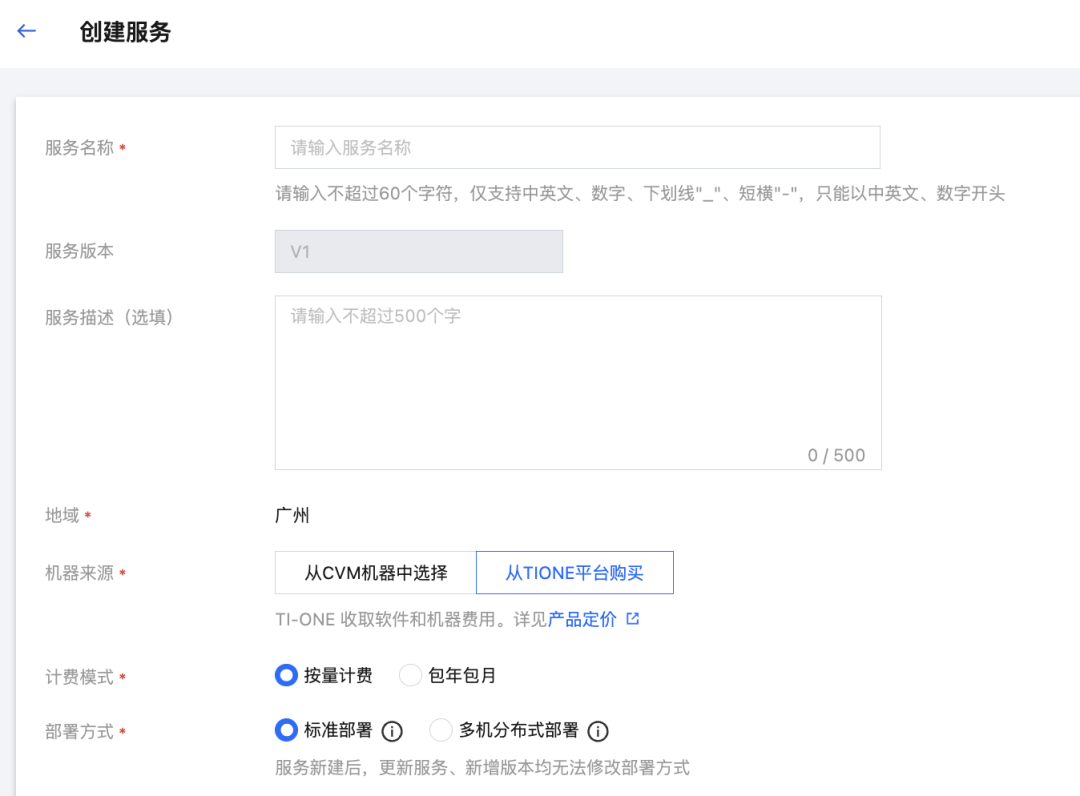
2、进入在线服务界面,点击新建服务,注意地域需与ES集群一致,本文将服务部署到广州地域:
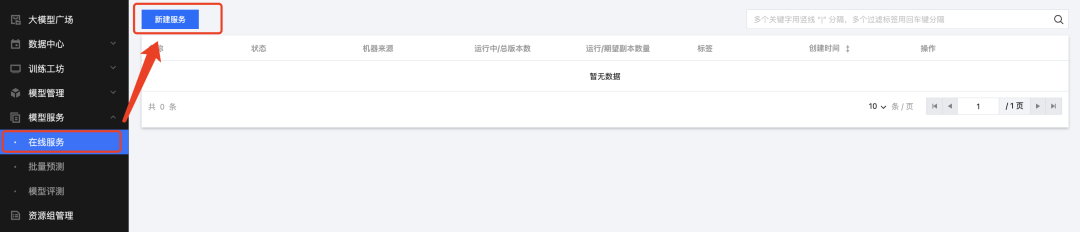
3、填写相关信息:
●机器来源选择从TIONE平台购买
●计费模式选择按量付费
●部署模式选择标准部署
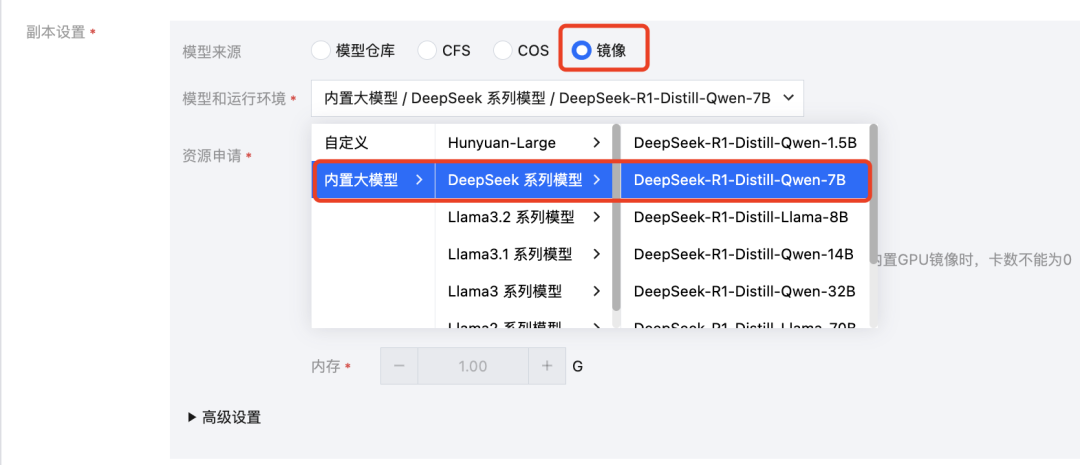
●模型来源选择镜像
●模型和运行环境选择内置大模型->DeepSeek系列模型->DeepSeek-R1-Distill-Qwen-7B
●算力规格选择 12C44GB A10*1
●而后点击启动服务即可
调用DeepSeek大模型
1、 Python 文件命名为tione_ds.py。
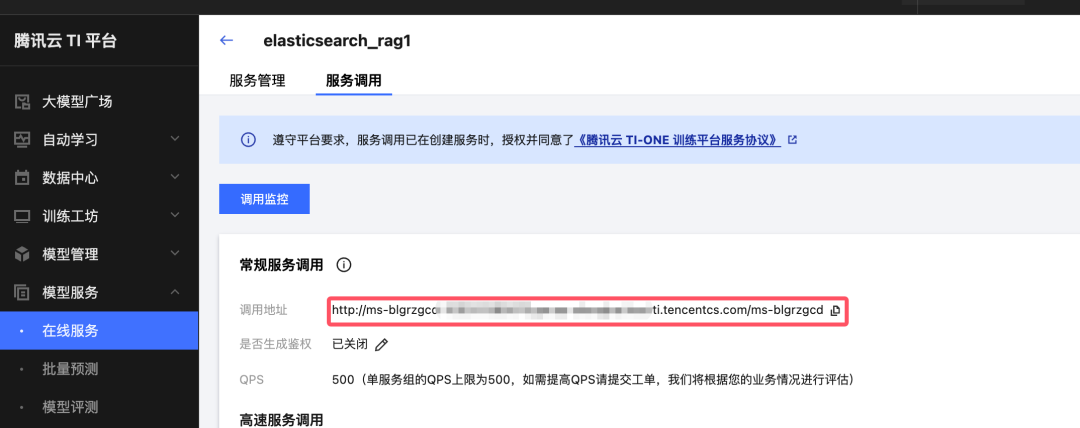
2、在TI-ONE平台获取模型的信息:
3、tione_ds.py内容如下:
import osfrom openai import OpenAI# 替换该地址,使用在TI-ONE平台获取模型的调用地址,并在后面增加/v1(使用openai sdk时,地址后面加上v1)os.environ["OPENAI_BASE_URL"] = "调用地址/v1"# 在TI-ONE平台未开启鉴权时, 任意配置os.environ["OPENAI_API_KEY"] = "any"def deepseek_gpt(system_prompt, user_prompt):# 实例化一个OpenAI的Clientclient = OpenAI()# 发起会话completion = client.chat.completions.create(model="model",messages=[{"role": "system","content": system_prompt,},{"role": "user","content": user_prompt,},],)# 返回字符格式回包return completion.choices[0].message.content
AI助手页面构建
1、安装 streamlit:
pip install streamlit
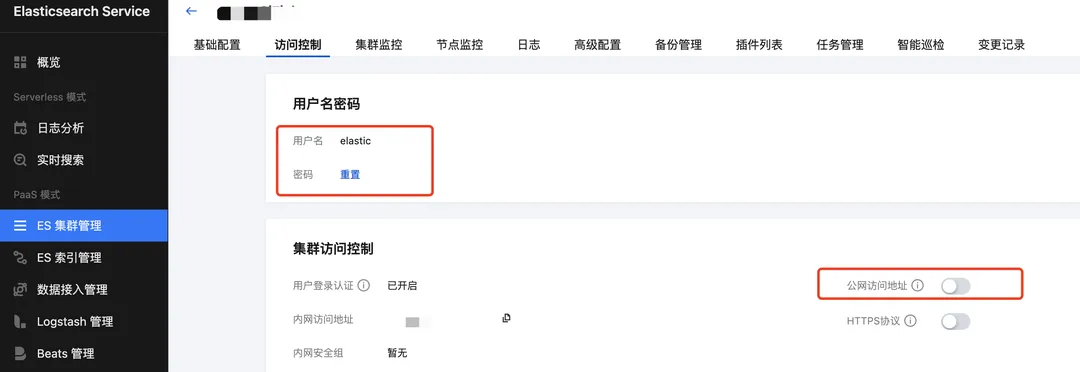
2、获取 ES 访问地址:
用户名为 elastic、密码在创建集群时设置,用本地mac测试时,可开启公网访问,实际生产时,建议使用内网访问地址。
3、Web界面参考如下代码( 可命名为 web_ds.py,需与tione_ds.py在一个目录下)
import streamlit as stfrom elasticsearch import Elasticsearchfrom tione_ds import deepseek_gptes_client = Elasticsearch("ES集群访问地址",basic_auth=("用户名", "密码"))def get_elasticsearch_results(query):es_query = {"knn": {"field": "content_embedding","num_candidates": 100,"query_vector_builder": {"text_embedding": {"model_id": ".multilingual-e5-small","model_text": query}}},"query":{"match":{"content":query}},"rank":{"rrf":{"window_size":100,"rank_constant":20}}}result = es_client.search(index="index-name", body=es_query)return result["hits"]["hits"]def create_deepseek_prompt(results,question):context = ""for hit in results:source_field = hit["_source"]["content"]hit_context = source_fieldcontext += f"{hit_context}\n"prompt = f"""Instructions:结合{context}的信息回答{question}的问题,要求简练高效"""return promptdef generate_deepseek_completion(user_prompt, question):response = deepseek_gpt(user_prompt, question)print(str(response))return response.replace('<think>','').replace('</think>','')def format_result(hit):title = hit["_source"]["title"]return f'[{title}]'def main():st.title("我的专属AI助手")# 创建输入框和查询按钮question = st.text_input("请输入您的问题:")if st.button("查询并生成答案"):# 获取Elasticsearch结果并创建HunYuan提示elasticsearch_results = get_elasticsearch_results(question)user_prompt = create_deepseek_prompt(elasticsearch_results,question)system_prompt = f"""你是一个问答任务的助手。使用呈现的上下文实事求是地回答问题。"""# 使用deepseek模型生成回答openai_completion = generate_deepseek_completion(system_prompt, user_prompt)# 显示结果st.write(openai_completion)# 展示Elasticsearch查询结果st.write("大模型参考的文档:")for hit in elasticsearch_results:st.markdown(format_result(hit))if __name__ == "__main__":main()
在上述 python 文件的目录下,使用如下命令运行系统:
streamlit run web_ds.py
生成的界面如下:
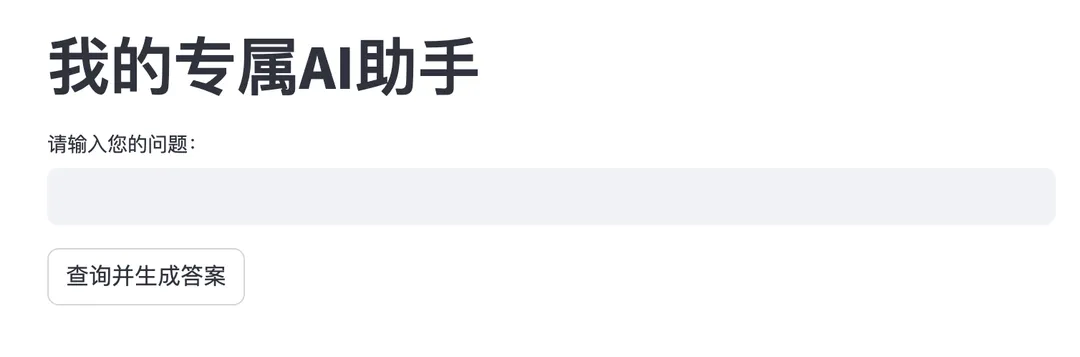
私域数据问答测试
我们使用“介绍腾讯云elasticsearch service的发展历程”这个问题来对比效果:
1、当索引中无相关数据时,可以看到,AI助手对此问题的回答效果相对比较差:

2、写入相关知识库数据:
POST index-name/_bulk?pipeline=index-name-pipeline&refresh{ "index" : {} }{ "title" : "腾讯云ES发展历程介绍","content": "腾讯云 Elasticsearch Service(ES)是云端全托管海量数据检索分析服务,拥有高性能自研内核,集成X-Pack。ES 支持通过自治索引、存算分离、集群巡检等特性轻松管理集群,也支持免运维、自动弹性、按需使用的 Serverless 模式。使用 ES您可以高效构建信息检索、日志分析、运维监控等服务,它独特的向量检索还可助您构建基于语义、图像的AI深度应用。其发展历程如下:2018年,腾讯云ES正式发布,提供开箱即用的云端全托管检索分析服务;2019年,与Elastic达成战略合作,提供X-Pack商业套件;2021年,规模化运营,达百PB规模,提供自研压缩编码等能力;2022年,针对日志场景深度优化,提供一站式数据链路、自治索引等能力;2023年,产品形态升级,提供自动弹性、完全免运维的的Serverless版;2024年,极智搜索,与AI大模型深度结合,提供一站式RAG方案。","url": "https:url1" }
3、重新提问,可以看到,完全准确,且基本没有不相关的信息:

可见,使用腾讯云ES与TI-ONE构建基于DeepSeek的RAG应用,可同时结合DeepSeek强大的推理与内容生成能力、腾讯云ES一站式RAG方案以及TI-ONE平台高效的模型部署能力,显著提高答案生成的准确性、可靠性,有效避免大模型的幻觉问题,为企业提供更加优质的本地知识库智能问答服务。
总结
本文介绍如何通过结合腾讯云ES 与DeepSeek大模型,快速构建RAG 应用。腾讯云ES凭借其在传统PB级日志和海量搜索场景中积累的丰富经验,通过深度重构底层系统,成功地将多年的性能优化、索引构建和运营管理经验应用于RAG领域,并积极探索向量召回与传统搜索技术的融合之道,旨在充分发挥两者的优势,为用户提供更加精准、高效的搜索体验。未来,腾讯云ES将持续深耕智能检索领域,在成本、性能、稳定性等方面持续提升,帮助客户降本增效的同时实现业务价值持续增长,欢迎持续关注!
腾讯云大数据始终致力于为各行业客户提供轻快、易用,智能的大数据平台。
END
关注腾讯云大数据╳探索数据的无限可能

⏬点击阅读原文
了解更多产品详情

我知道你在看哟

