




sklearn.cluster.KMeans 是 Python 中 Scikit-learn 库提供的一个非常流行和常用的聚类算法,用于将数据分成预先指定的数量(即“k”个)集群。尽管 KMeans 算法在很多情况下表现良好,但它也有一些缺点和局限性:
对初始化的敏感性:KMeans 算法的性能很大程度上依赖于初始质心(centroids)的选择。不同的初始化可能导致算法收敛到局部最优解,而非全局最优解。
对异常值敏感:异常值(或称为噪声点)可以显著影响 KMeans 的聚类结果,因为这些点可能会被误分类到离它们最近的质心所在的集群中。
对球形簇形的假设:KMeans 假设所有簇是球形且各向同性的,这意味着簇的形状应该是圆形的,并且每个维度上的方差应该是相同的。
难以确定最佳簇数:确定最佳的簇数 K 是一个挑战。KMeans 需要用户事先指定 K 的值,而实际上选择一个合适的 K 值并不总是直观的。
计算复杂度:KMeans 的计算复杂度是 O(tkn),其中 t 是迭代次数,k 是簇的数量,n 是样本数。随着数据集的增大和/或簇的数量增加,算法的运行时间可能会显著增加。
from sklearn.preprocessing import StandardScaler # 标准化库# 数据归一化scaler = StandardScaler()scalerX = scaler.fit_transform(X)for k in range(3,6):# 模型训练KmeansModel = KMeans(n_clusters=k, random_state=42)KmeansModel.fit(scalerX)# 计算轮轴系数:# 轮廓系数用于计算每个样本的平均簇内距离a(样本i到同簇其他样本的平均距离,ai值越小说明该样本越应该被聚到该类,即簇内不相似度)和平均邻近簇距离b(样本i到其他相邻簇的所有样本的平均距离bi,bi越大说明样本i越不属于其他簇,即簇间不相似度)。# 每个样本的轮廓系数计算公式为:(b-a)/Max(a,b),轮廓系数越接近1说明结果越好(聚类越准确),越接近-1说明结果越差,若值在0值附近,则说明样本在两个簇的边界上score = silhouette_score(scalerX, KmeansModel.labels_, metric='euclidean')print("For n_clusters={}, The Silhouette Coefficient is {}".format(k, score))# 合并数据和特征kmeans_labels = pd.DataFrame(KmeansModel.labels_, columns=['scaler kmean labels'+str(k)])df = df.join(kmeans_labels)df.to_csv('provicedatav2.csv', index=False, header=True, encoding='utf-8')
在实现数据标准化后,我们查看一下数据的规律和分布情况,基本都满足正态分布
import numpy as npscaler = StandardScaler()scalerX = scaler.fit_transform(X)max_values = np.amax(scalerX, axis=0)print("列上的最大值:", max_values)# 计算列上的最小值min_values = np.amin(scalerX, axis=0)print("列上的最小值:", min_values)# 计算列上的平均值mean_values = np.mean(scalerX, axis=0)print("列上的平均值:", mean_values)# 列上的最大值:# [2.95274386 1.94360996 1.94360996 1.94360996 2.71394433# 3.05643864 3.58884568 3.81979393 2.92766957 3.29469106# 2.85150009 3.18538812 3.12650613 3.53887138]# 列上的最小值:# [-1.17588455 -1.50879078 -1.50879078 -1.50879078 -1.38798558# -1.95537756 -0.69273214 -0.62470284 -0.68714838 -1.15992496# -1.53665505 -0.95225614 -1.08900741 -0.79803214]# 列上的平均值:# [-2.65020980e-16 -2.44428134e-16 -2.44428134e-16 -2.44428134e-16 -5.73018335e-17# -5.01391043e-17 3.58136460e-17 0.00000000e+00 -2.50695522e-17 7.52086565e-17# 1.66029824e-16 -1.21766396e-16 -1.75486865e-16 1.43254584e-17]
接下来是数据可视化,基于cartopy和matplotlib实现地理数据的展示,基于geopandas实现矢量地图文件的加载。
china.rar文件包括各省边界、各市边界、各县边界、中国边界(含九/十段线),已共享到百度网盘中,见链接: https://pan.baidu.com/s/128281wae901QfViNHtlUwA?pwd=8888 提取码: 8888
一般用geopandas来读取shp文件
china = gpd.read_file(r'E:\shp\china\中国_省_Areas.shp')print(china.head())
我们看一下数据格式,包括了各省市自治区名称,面积和边界点,shp文件中的各省市自治区名称和国家统计局是一样的,因此不需要转换。
LAYER name gb geometry
0 Unknown Area Type 河南省 156410000 MULTIPOLYGON (((111.02261 33.17939, 111.00594 ...
1 Unknown Area Type 浙江省 156330000 MULTIPOLYGON (((121.08199 27.47084, 121.09719 ...
2 Unknown Area Type 海南省 156460000 MULTIPOLYGON (((112.05623 3.83753, 112.04267 3...
3 Unknown Area Type 台湾省 156710000 MULTIPOLYGON (((121.60056 22.02062, 121.59325 ...
4 Unknown Area Type 甘肃省 156620000 POLYGON ((97.17195 42.79342, 97.84515 41.65423...
下面代码是实现聚类后各省分类的可视化代码,有一个在不同pandas之间进行数据赋值转换的过程。
import matplotlib.pyplot as pltimport cartopy.crs as ccrsimport cartopy.feature as cfeatureimport geopandas as gpdimport pandas as pdpd.set_option('display.max_columns', None)# 显示所有行pd.set_option('display.max_rows', None)# 不换行显示pd.set_option('display.width', 1000)# 行列对齐显示,显示不混乱pd.set_option('display.unicode.ambiguous_as_wide', True)pd.set_option('display.unicode.east_asian_width', True)# 显示精度pd.set_option('display.precision', 4)# 显示小数位数pd.get_option("display.precision")# 加载中国各省的地理数据# 你需要从网上下载中国各省的shapefile文件,例如从GADM (https://gadm.org/download_country_v3.html)china = gpd.read_file(r'E:\shp\china\中国_省_Areas.shp')# 加载九段线数据,九段线数据可以从自然资源部或其他公开数据源获取nine_dash_line = gpd.read_file(r'E:\shp\china\中国_省_Lines.shp')# 加载上次另存的数据data_path = r'E:\JetBrains\PythonProject\DeepLearning\Sklearn\provicedatav2.csv'df = pd.read_csv(data_path)# 将kmean label3、kmean label4 、kmean label5china['scaler kmean labels3'] = china['name'].map(df.set_index('city')['scaler kmean labels3'])china['scaler kmean labels4'] = china['name'].map(df.set_index('city')['scaler kmean labels4'])china['scaler kmean labels5'] = china['name'].map(df.set_index('city')['scaler kmean labels5'])def drawchina(df,columnname):# 创建地图fig = plt.figure(figsize=(12, 8))ax = fig.add_subplot(1, 1, 1, projection=ccrs.PlateCarree())# 设置地图范围为中国(包括南海区域)ax.set_extent([73, 135, 3, 54], crs=ccrs.PlateCarree())# 添加地理特征ax.add_feature(cfeature.COASTLINE.with_scale('50m'))ax.add_feature(cfeature.BORDERS.with_scale('50m'), linestyle=':')ax.add_feature(cfeature.LAND.with_scale('50m'), edgecolor='black')ax.add_feature(cfeature.OCEAN.with_scale('50m'))ax.add_feature(cfeature.LAKES.with_scale('50m'))# 绘制各省地图并根据数据着色df.plot(column=columnname, ax=ax, legend=True, cmap='OrRd', legend_kwds={'label': "Data by Province"})# df.plot(column=columnname, ax=ax, linewidth=2,legend_kwds={'label': "Data by Province"})# 绘制九段线nine_dash_line.plot(ax=ax, color='blue', linewidth=2, label='Nine-Dash Line')plt.legend()# 添加标题plt.title('China Provinces Data with Nine-Dash Line')# 显示地图plt.tight_layout()plt.show()drawchina(china, 'scaler kmean labels3')drawchina(china, 'scaler kmean labels4')drawchina(china, 'scaler kmean labels5')
可视化呈现效果如下:三个分类的,似乎不太准,北京上海浙江属于经济发达的小省市,橙色区域经济一般。
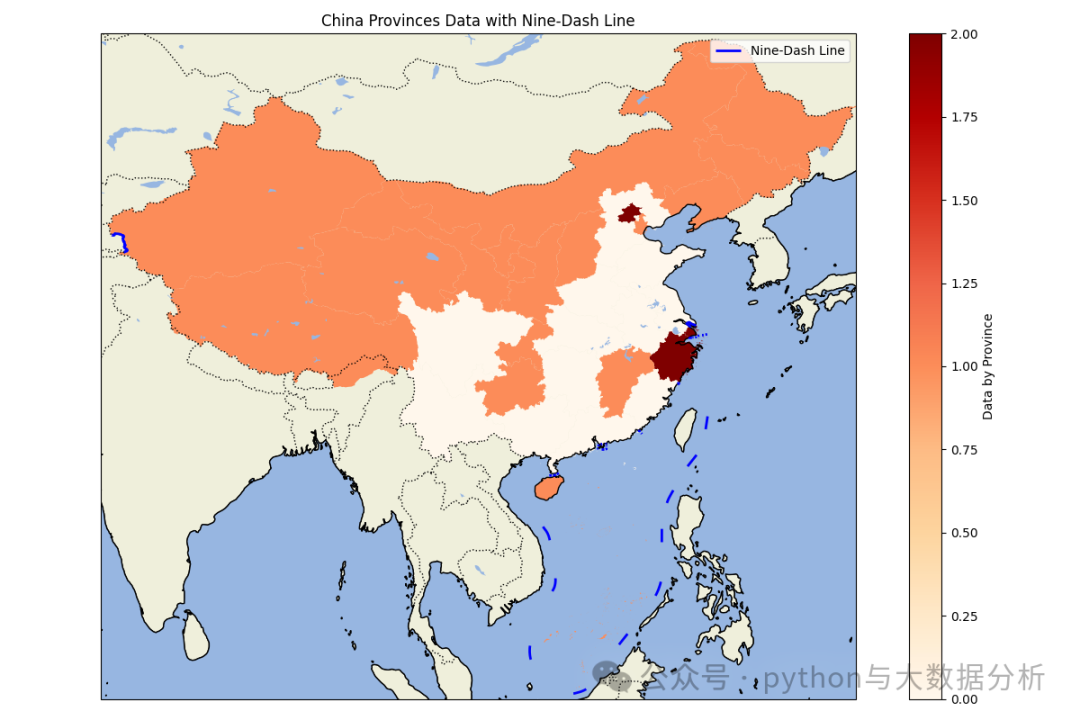
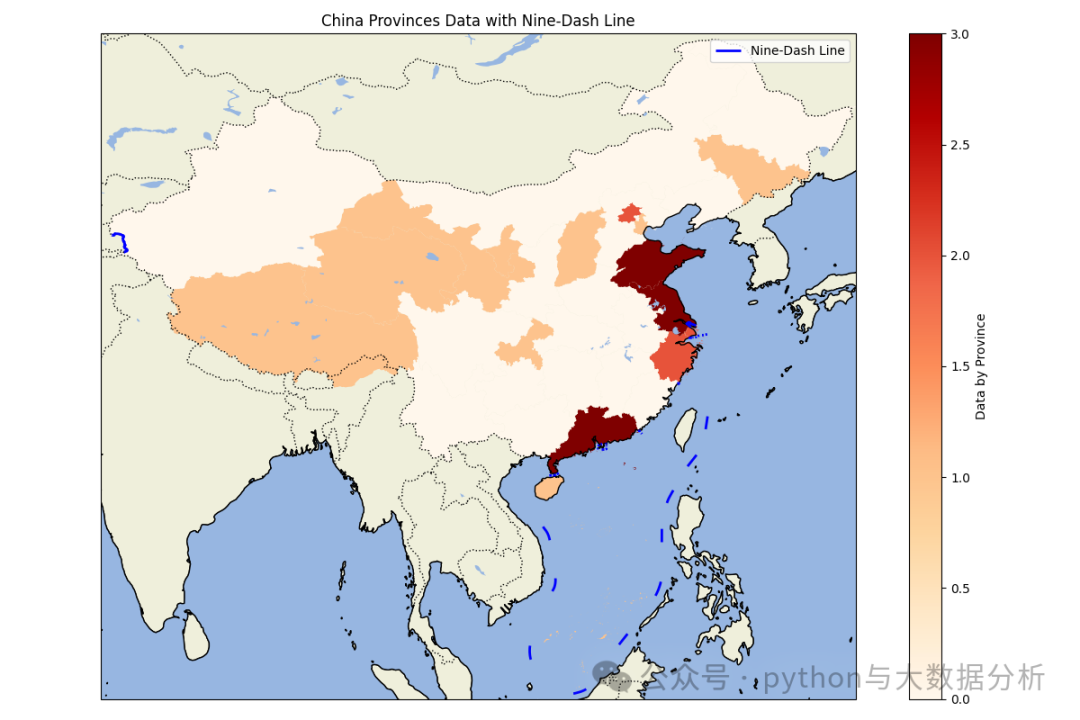
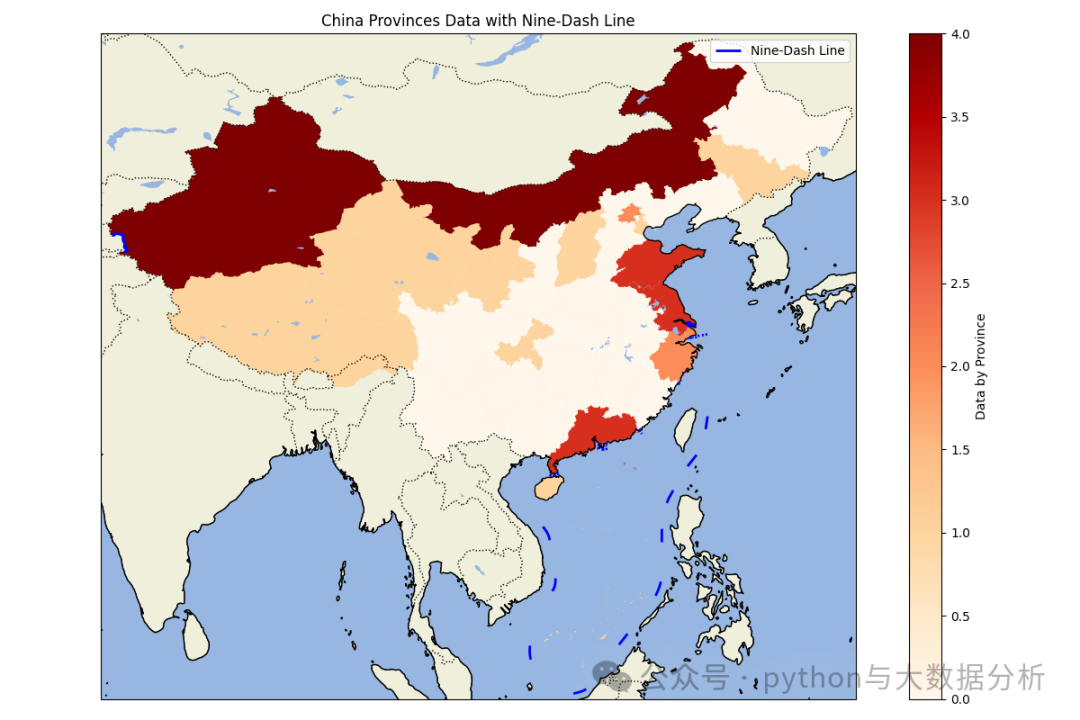
最后欢迎关注公众号:python与大数据分析

