




K-Means聚类算法是一种常用的聚类方法,具有简单、快速的特点,适用于处理大数据集。
基本原理
K-Means聚类算法的核心思想是将数据集分成K个簇,每个簇由其质心(中心点)代表。算法首先随机选择K个数据点作为初始质心,然后根据每个数据点到各个质心的距离,将其分配到最近的质心所代表的簇中。接着,重新计算每个簇的质心,如果新的质心与旧的质心变化很小,则算法收敛,聚类结束;否则继续迭代。
数据来自国家统计局 https://www.stats.gov.cn/sj/#,地区数据-分省年度数据-2023年数据。
手工获取的数据已放到网盘,自行下载:
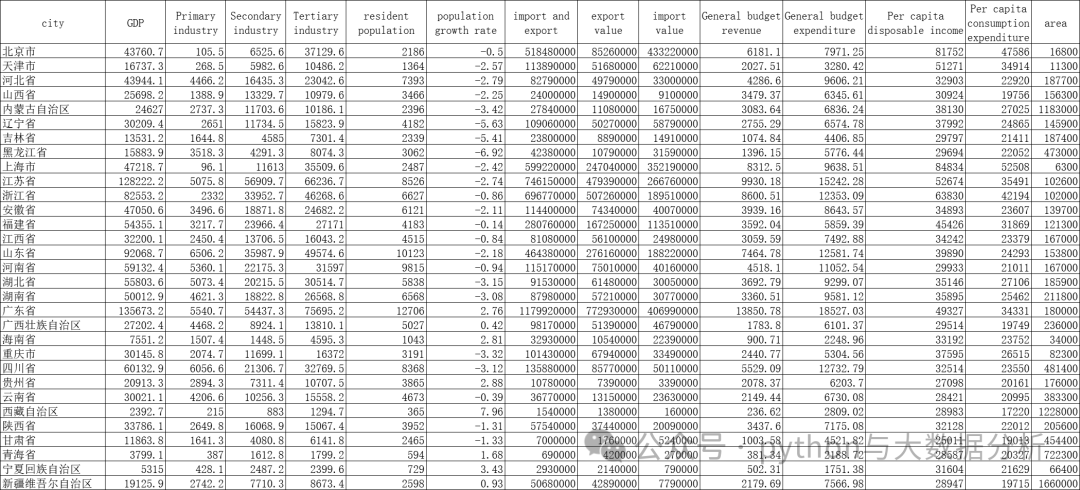
# 导入库import pandas as pd # panda库from sklearn.cluster import KMeans # 导入sklearn聚类模块from sklearn.metrics import silhouette_score # 效果评估模块# 替换为你的文件路径data_path = r'E:\JetBrains\PythonProject\DeepLearning\provicedata.csv'df = pd.read_csv(data_path)# 相关数据来自国家统计局 https://www.stats.gov.cn/sj/# 地区数据-分省年度数据-2023年数据# GDP,第一产业,第二产业,第三产业,# 常驻居民人数,居民人口增长率,# 进出口额,出口额,进口额,# 一般预算收入、一般预算支出、# 人均可支配收入、人均消费支出、地区面积features = ['GDP', 'Primary industry', 'Primary industry','Primary industry','resident population','population growth rate','import and export','export value','import value','General budget revenue','General budget expenditure','Per capita disposable income','Per capita consumption expenditure','area'] # 替换为你的特征列名X = df[features]n_samples, n_features = X.shapeprint('样本数:%d , 特征数:%d' % (n_samples, n_features))
sklearn.cluster.KMeans是scikit-learn库中的一个聚类算法,主要用于将数据集分成K个簇,使得每个簇内的数据点相似度最大,而簇间的数据点相似度最小。K-means算法的核心思想是通过迭代地更新簇中心来优化簇的划分。
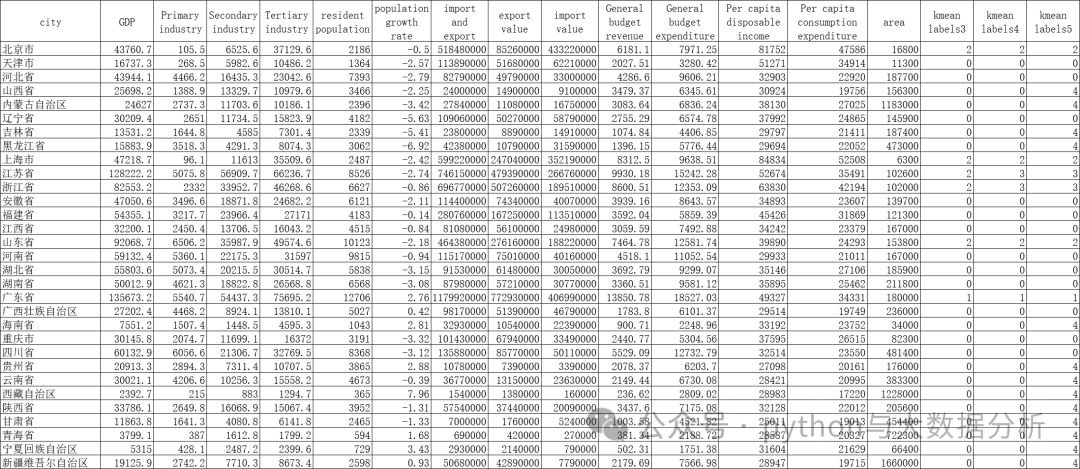
这里我们分别将聚类簇数设置为3、4、5
# 导入库# sklearn.cluster.KMeans(n_clusters=K)# 1. n_cluster:聚类个数(即K),默认值是8。# 2. init:初始化类中心的方法(即选择初始中心点的根据),默认“K-means++”,其他可选参数包括“random”。# 3. n_init:使用不同类中心运行的次数,默认值是10,即算法会初始化10次簇中心,然后返回最好的一次聚类结果。# 4. max_iter:单次运行KMeans算法的最大迭代次数,默认值是300。# 5. tol:浮点型,两次迭代之间簇内平方和下降的容忍阈值,默认为0.0001,如果两次迭代之间下降的值小于tol所设定的值,迭代就会停下。# 6. verbose:是否输出详细信息,参数类型为整型,默认值为0,1表示每隔一段时间打印一次日志信息。# 7. random_state:控制每次类中心随机初始化的随机种子,作用相当于能够锁定和复现同一次随机结果,默认为none,也可以随机设置数字。# 8. copy_x:在预先计算距离时,首先将数据居中在数值上更准确。如果 copy_x 为 True(默认),则不修改原始数据。# 如果为 False,则修改原始数据,并在函数返回之前放回,但通过减去再添加数据均值可能会引入小的数值差异。# 请注意,如果原始数据不是C-contiguous,即使copy_x 为False,也会进行复制。如果原始数据是稀疏的,但不是 CSR 格式,即使 copy_x 为 False,也会进行复制。# 9. algorithm:有三种参数可选:auto”, “full”, “elkan”,默认为auto。K-means 算法使用。# 经典的EM-style算法是“full”。通过使用三角不等式,“elkan” 变体对具有明确定义的集群的数据更有效。# 然而,由于分配了一个额外的形状数组(n_samples,n_clusters),它更加占用内存。for k in range(3,6):# 模型训练KmeansModel = KMeans(n_clusters=k, random_state=42)KmeansModel.fit(X)# 计算轮轴系数:# 轮廓系数用于计算每个样本的平均簇内距离a(样本i到同簇其他样本的平均距离,ai值越小说明该样本越应该被聚到该类,即簇内不相似度)和平均邻近簇距离b(样本i到其他相邻簇的所有样本的平均距离bi,bi越大说明样本i越不属于其他簇,即簇间不相似度)。# 每个样本的轮廓系数计算公式为:(b-a)/Max(a,b),轮廓系数越接近1说明结果越好(聚类越准确),越接近-1说明结果越差,若值在0值附近,则说明样本在两个簇的边界上score = silhouette_score(X, KmeansModel.labels_, metric='euclidean')print("For n_clusters={}, The Silhouette Coefficient is {}".format(k, score))# 合并数据和特征kmeans_labels = pd.DataFrame(KmeansModel.labels_, columns=['kmean labels'+str(k)])df = df.join(kmeans_labels)df.to_csv('provicedatav1.csv', index=False, header=True, encoding='utf-8')
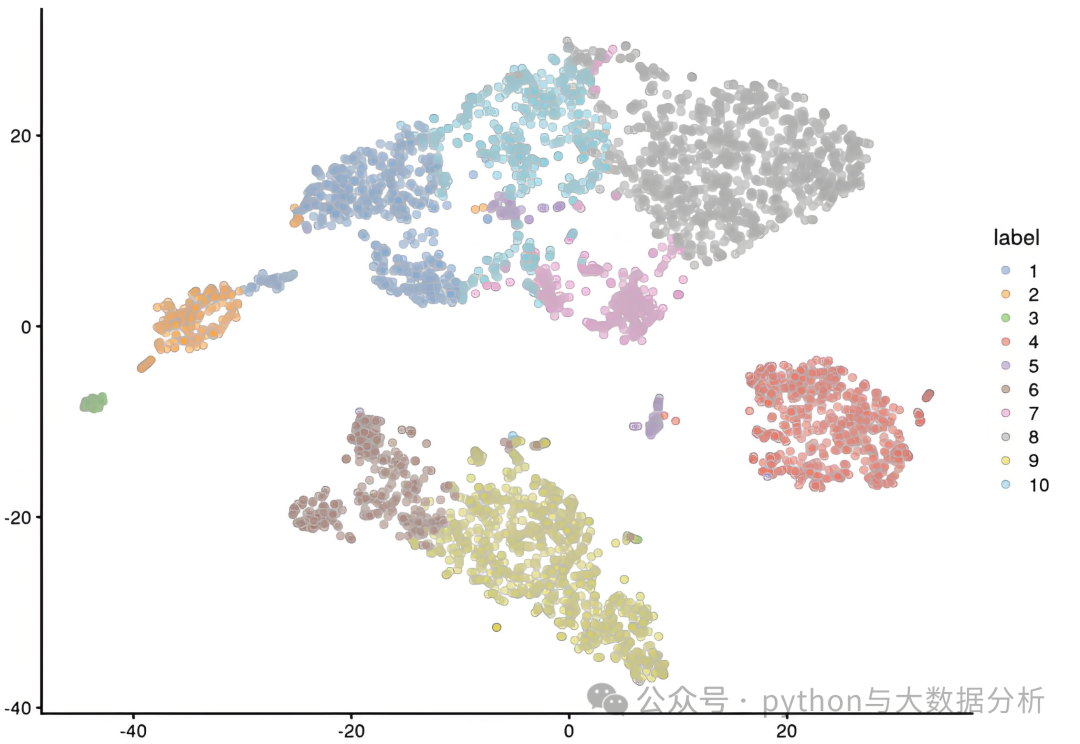
关于聚类结果问题,很难说有一个明确的结论,每个人看待数据都有不同的结论,例如北京、上海基本为一类,浙江、江苏、山东基本为一类,广东有些另类,河南河北山西陕西为一类,内蒙新疆西藏可以为一类,基于不同的逻辑可以分为若干类,我们这里仅做比较,不做结论。后续通过可视化方式,可以看一下
最后欢迎关注公众号:python与大数据分析

文章转载自追梦IT人,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
