




1 说明
昨天业务大佬反馈昨晚批量重启应用时报如下错误:

发现是ORA-12514,一个比较熟悉的连接类报错,错误原因一般是以下几类:
- 连接串写错了
- 监听未启动,或实例未注册到监听
- 服务名没配置或者配置错误
2 排查过程
经排查,网络是通的,监听正常,服务名也配置了,告警日志也找不到明显不报错,因此排除上述原因。
还有一个关键信息就是,报错是发生在批量重启应用的时候,这种情况下会同时产生大量的登录连接操作,是有可能导致监听报错的!
所以,需要排查历史连接数和登录次数等情况,分析是否存在异常。
2.1 检查历史连接数情况
登录数据库,使用dba_hist_resource_limit表查看历史process情况:
select a.*, to_date(b.begin_interval_time, 'yyyy-mm-dd hh24:mi:ss')
from dba_hist_resource_limit a, dba_hist_snapshot b
where a.snap_id = b.snap_id
and a.instance_number = b.instance_number
and a.instance_number = &inst_id
and a.resource_name = 'process'
and b.begin_interval_time >= to_date('2025-02-18 00', 'yyyy-mm-dd hh24')
order by a.snap_id;
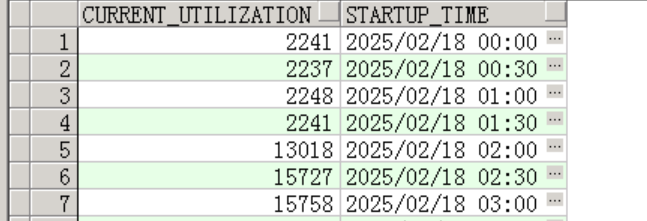
可以看到,在夜里2点开始连接数出现一个激增,从2241飙升到13018,半个小时内连接数犯了6倍。
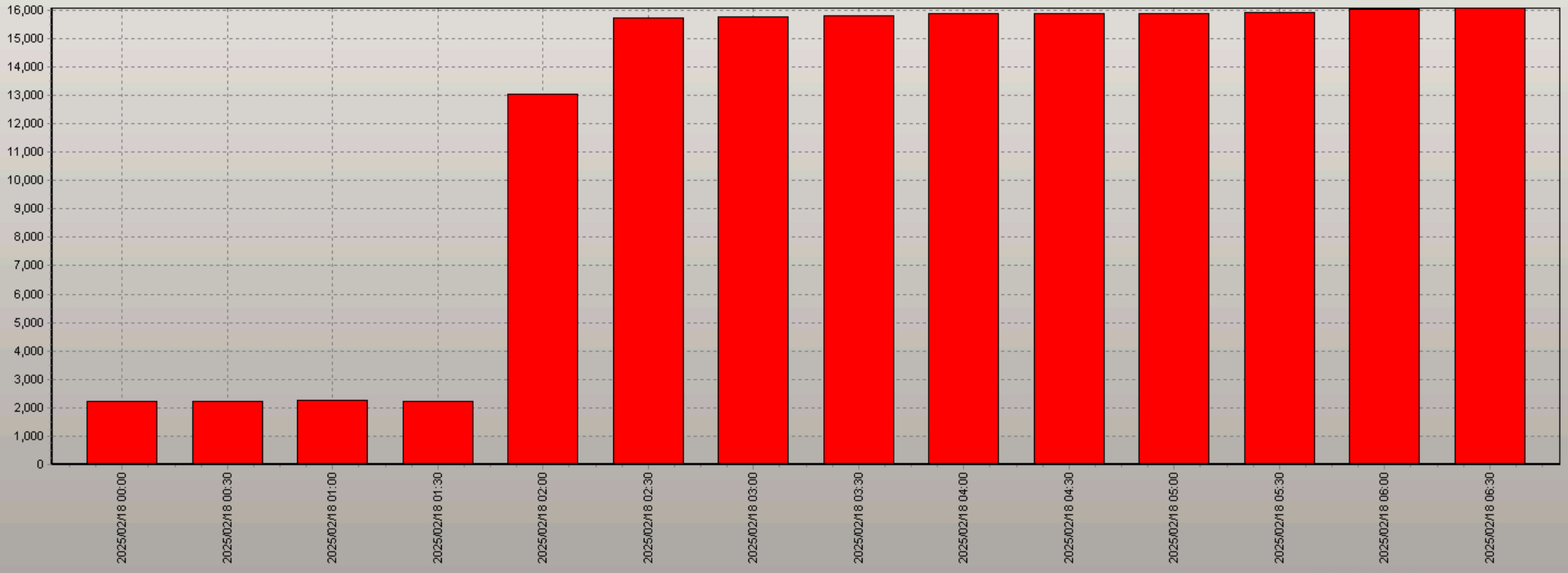
结合plsql dev柱状图更能明显观察到激增情况:
2.2 检查历史登录次数情况
查看监听日志,统计每秒和每分钟登录次数情况。
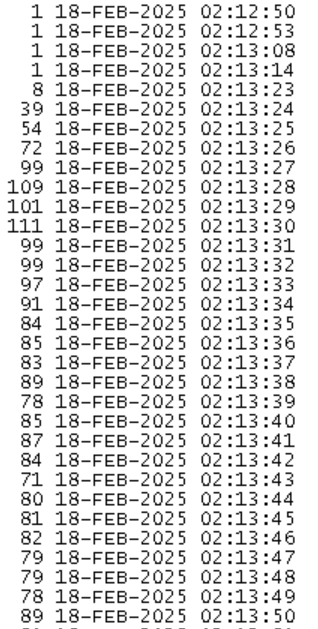
每秒钟登录次数:
grep "18-FFEB-2025 02:1" listener.log | awk '{print $1,$2}' | sort -n | uniq -c
每分钟登录次数:
grep "18-FFEB-2025 02:" listener.log | awk '{print $1,substr($2,1,5)}' | sort -n | uniq -c
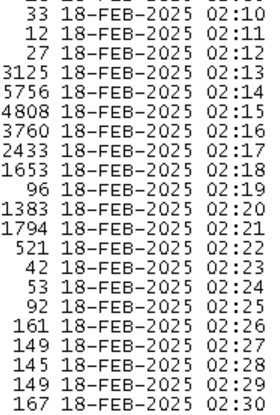
可以看到,从2:13分开始有连接风暴,每秒登录次数高达100次,每分钟平均最高5756次,这种情况就可能会出现应用报错了。
3 优化措施
一、优化应用重启策略
避免一次性批量重启所有应用,采用分批重启的方式,减少并发连接数,避免短时间内产生大量连接请求。
二、实施限流措施
在应用层或网络层实施限流策略,避免突发的大量连接请求。
使用连接池并合理配置连接池参数,避免连接泄漏或过度占用资源。
4 总结
本次 ORA-12514 错误的主要原因是由于批量重启时产生的大量登录连接操作引发连接风暴,即在短时间内产生了大量并发连接请求,导致监听器无法及时处理。这种情况通常发生在批量重启应用或突发高并发场景下。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
