本文将分三章,对GBase 8a数据库集群的加载功能模块从原理和架构两方面进行说明,提供加载性能参数调优方案和kafka数据源的加载导出方案,为用户了解和使用GBase 8a加载功能提供参考。
功能特性
GBase 8a集群加载支持本地文件、ftp/sftp、http/https、hdfs、kafka、S3等常用数据源;支持使用平文本、avro/orc(未release)文件格式进行加载;支持使用压缩格式gzip、snnapy、lzo进行加载;支持普通文本、定长、宽松加载模式;支持kerberos认证,多namenode高可用;支持多表、单表并行加载,多数据源并行加载;支持多点传输,多节点并行数据解析,单节点多线程并行。
架构及原理
GBase 8a加载功能架构图如下:
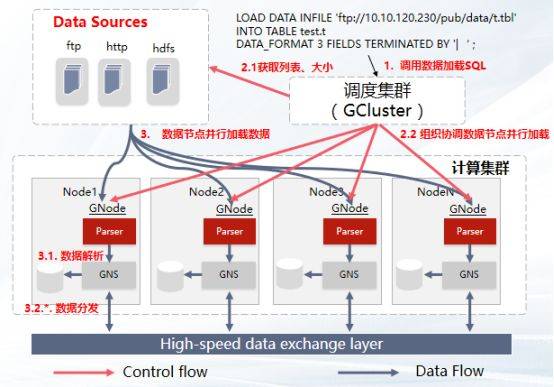
1:数据加载SQL下发,gcluster接收SQL任务。
2:gcluster解析URL生成具体的源数据文件列表;gcluster按gnode加载节点数量均分源数据文件。如15G数据文件均分3个加载节点时,gcluster进行数据切分,每个加载节点5G加载任务;完成数据切分后,gcluster给gnode加载节点下发加载SQL任务。
3:gnode接收加载SQL任务后,去文件服务器上读取指定数据;gnode对读取到的加载数据进行解析;将合法数据按表和hash列分配归入对应表分片的DC中;gnode将DC压缩文件转发到对应的主分片节点上;主分片gnode节点将收到的DC文件组装好后实时转发到副本节点上。
加载性能调优及相关参数
加载性能调优
GBase 8a采用多点传输技术,集群中的每个节点均参与数据的解析和加载,且加载性能可以随着集群节点数的增加线性扩展,通过加载性能调优,仅使用8台服务器即达到33TB/小时的加载速度。
加载性能相关参数
gcluster_loader_max_data_processors
说明:单个加载任务并行加载机的个数
默认值:16
调优值:在加载并发较高、集群节点较多场景下推荐配置为4~8
gbase_loader_parallel_degree
说明:data节点执行单个加载任务的并行度
默认值:0,使用CPU核数一半,当设置值大于线程池数量时,则使用线程池数量。
调优值:配置为4~6。可以通过set方式设置,也可以使用PARALLEL在加载语句中指定。
_gbase_dc_sync_size
说明:数据文件磁盘落地大小
默认值:1TB
调优值:当存在data节点磁盘IO繁忙、加载性能缓慢、CPU资源利用低时,可调小该参数,推荐10M
gbase_parallel_max_thread_in_pool
说明:线程池中的线程总数,用于配置线程池大小。
默认值:CPU核数的2倍
调优值:在每个服务器上部署1个gnode节点的情况下推荐该配置为CPU核数的4~8倍。
gcluster_enable_serial_load、gcluster_serial_exec_query
说明:限制任务并发数,
调优值:开启gcluster_enable_serial_load参数后,每个gcluster节点可以下发gcluster_serial_exec_query个SQL任务(select、insert select、load等),主要控制并发时,下发到gnode的SQL数量,超过后排队。
gbase_loader_max_line_length
说明:超长行大小
默认值:4M
调优值:当数据文件中存在超过4M大小的行时,加载任务会报错中断,增加该值可以跳过该行继续加载,超过4M的数据保存在errdata中
gbase_loader_read_timeout
说明:数据文件读取超时,读取ftp/http/sftp文件超时的时间设置
默认值:300秒,0无限制。
调优值:当集群负载较高、数据源IO或网络较差时,调大该参数可避免数据源读取超时报错
数据源服务器参数
如ftp/sftp并发访问数、端口数等,具体问题具体分析
数据源并发数评估
集群最大并发加载任务数为N,单加载任务最大加载机数(max_data_processors)为M时,数据源推荐的并发数不低于M*N。
分块加载
分块加载原理:
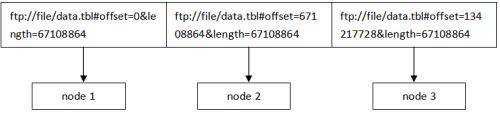
gcluster文件切分是用URL表示的多个逻辑块,交由多个data节点并行加载,文件服务器并不实际进行文件切分。
加载按行处理,data节点对分配给自己的逻辑块数据逐行进行加载,排除开头属于前一个节点的数据(第一个换行符前),以及读取结尾完整的数据行(直到下一节点的第一个换行符为止)。
加载数据量:
一次加载支持读取和处理的数据量大小与以下参数相关:
gbase_loader_buffer_count
说明:加载使用内存块数。data节点内部维护一个内存链表。
默认值:16
gbase_loader_line_length
说明:各内存块大小。data节点从数据源一次性读取4M大小的数据内容放到内存链表中进行后续处理。
默认值:4M
分块加载使用场景:
对于不同使用场景,可灵活调整分块加载配置:
对于加载节点少,加载任务的数据总量大的使用场景,gcluster将一次加载任务中的数据总量按加载节点数均分给各个加载节点并行执行,能大幅提升加载性能。
对于加载节点多,加载任务的数据总量小,避免对数据切块粒度太小降低加载性能,可通过以下参数调优:
gcluster_loader_min_chunk_size
说明:设置大文件切块的最小粒度,范围4M—128M,作用同加载SQL参数MIN_CHUNK_SIZE。
默认值:64M,即小于128M的文件不进行切分。
以下使用场景执行加载时不会对数据文件进行切分:
1. 加载语句带参数NOSPLIT会关闭分块并行;;
2. 加载语句有having lines separator或者format 5;
3. 加载的文件是.gz或者.snappy压缩文件,建议打包小文件。
关闭分块并行功能后,每个data节点处理1个文件,如下图示。