




摘要:本文来自阿里云高级开发工程师,Apache Flink Committer 阮航老师分享的阿里云基于 Flink CDC 的现代数据栈云上实践。主要分为以下四个内容:
基于 Flink CDC 的现代数据栈 CDC YAML 核心功能 CDC YAML 典型应用场景 Demo & 未来展望
基于 Flink CDC 的现代数据栈
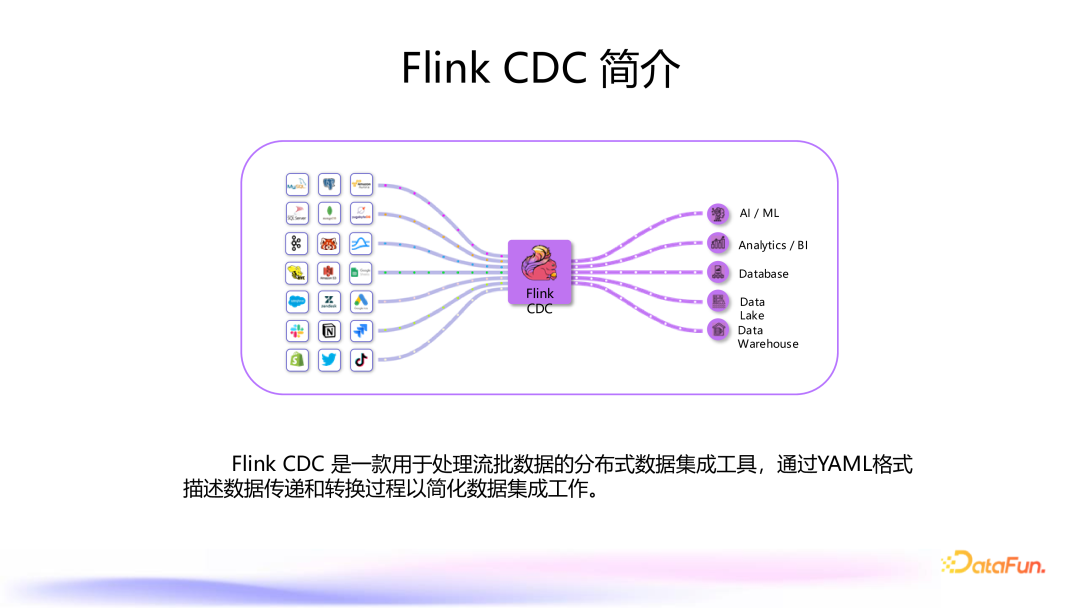
1. Flink CDC 简介
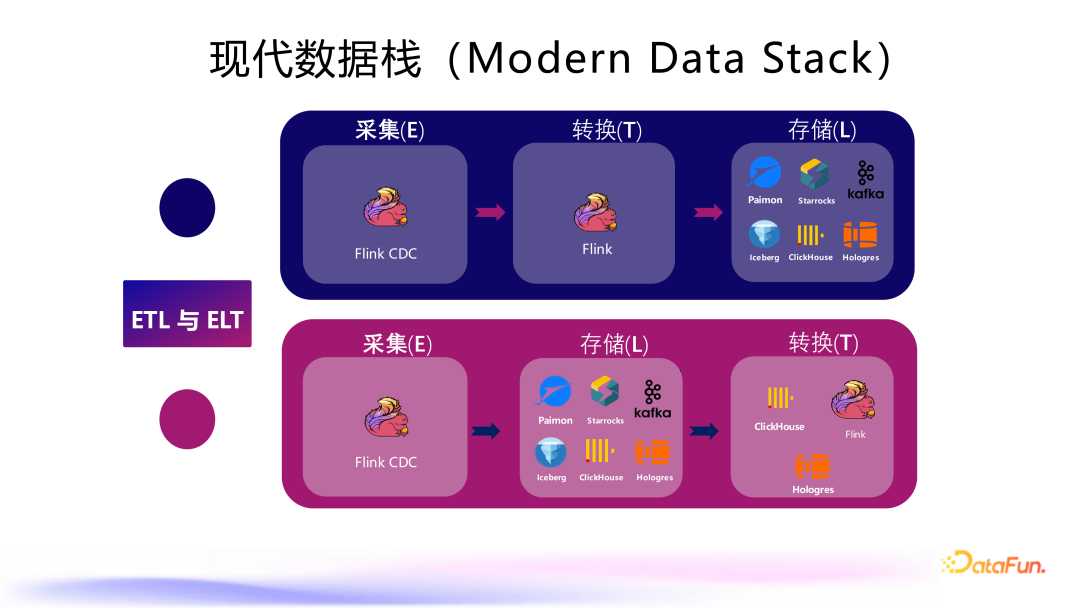
2. 现代数据栈概述
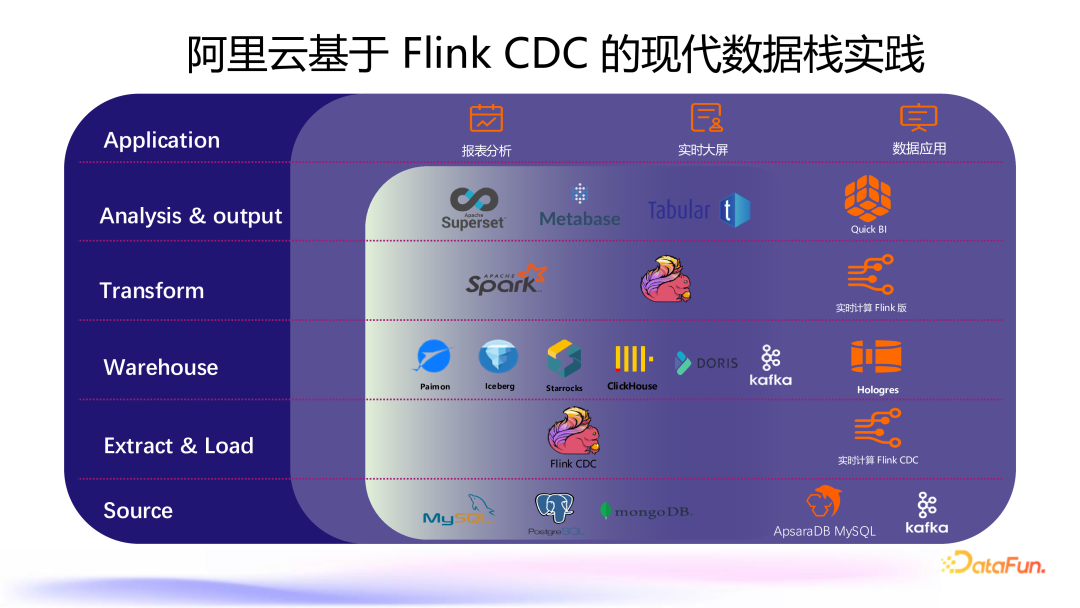
3. 阿里云基于 Flink CDC 的现代数据栈实践
Source 层:增加了基于日志的整库同步功能,如 MySQL binlog 到 Kafka 的日志同步。 Extract & Load 层:支持通过 Flink CDC 作业、DataStream 作业及 SQL 作业等多种方式收集数据。 Warehouse 层:除了常见的 Paimon、StarRocks 等数据库外,还集成了 Hologres 这样的高性能数据存储。 Transform 层:利用 Spark 或 Flink 作业实现数据转换,应用于报表分析、实时大屏展示等多种场景。
4. 实时计算 Flink 版集成 Flink CDC
支持 YAML 语言开发,预制常用模板:允许用户使用 YAML 格式快速配置和开发数据同步任务。且提供了多种常用模板,如 MySQL 到 Paimon 、MySQL 到 StarRocks 等,便于快速启动项目。 自动识别连接器依赖:自动处理 Flink 作业所需的上下游 Connector 依赖项,避免了用户在提交 Flink CDC 作业时需要自行管理这些依赖的问题,简化了作业部署流程。 丰富的监控指标:增加了额外的性能和状态监控指标,帮助用户更好地理解作业运行情况。

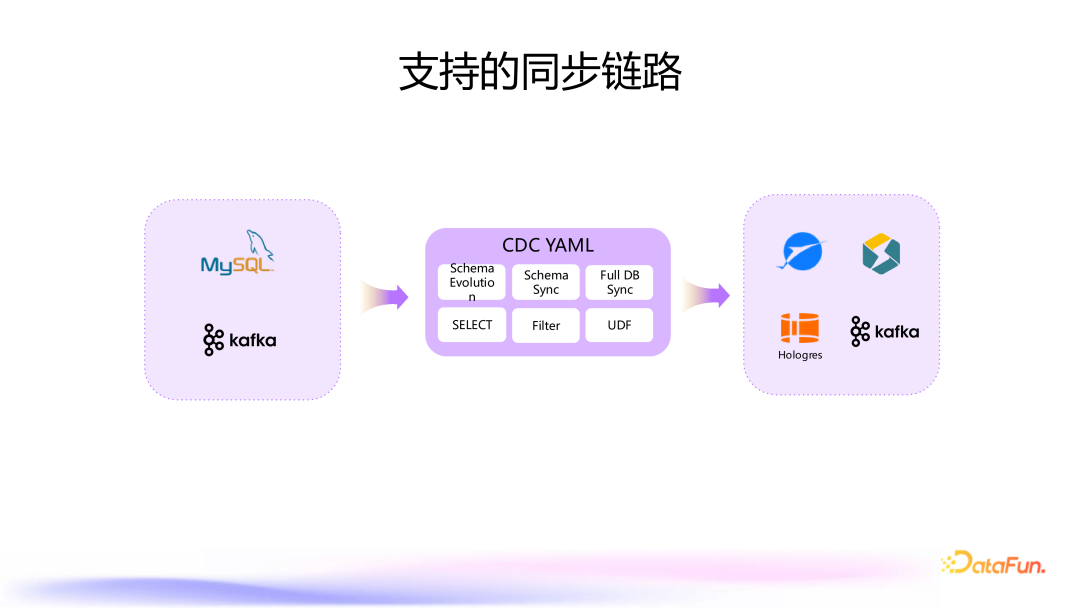
CDC YAML 核心功能
Source 端:MySQL 、Kafka Sink 端: 常见的数据仓库如 Paimon、StarRocks 和 Hologres。 支持了整库同步 Kafka。 原始 binlog 同步 Kafka 的解决方案。
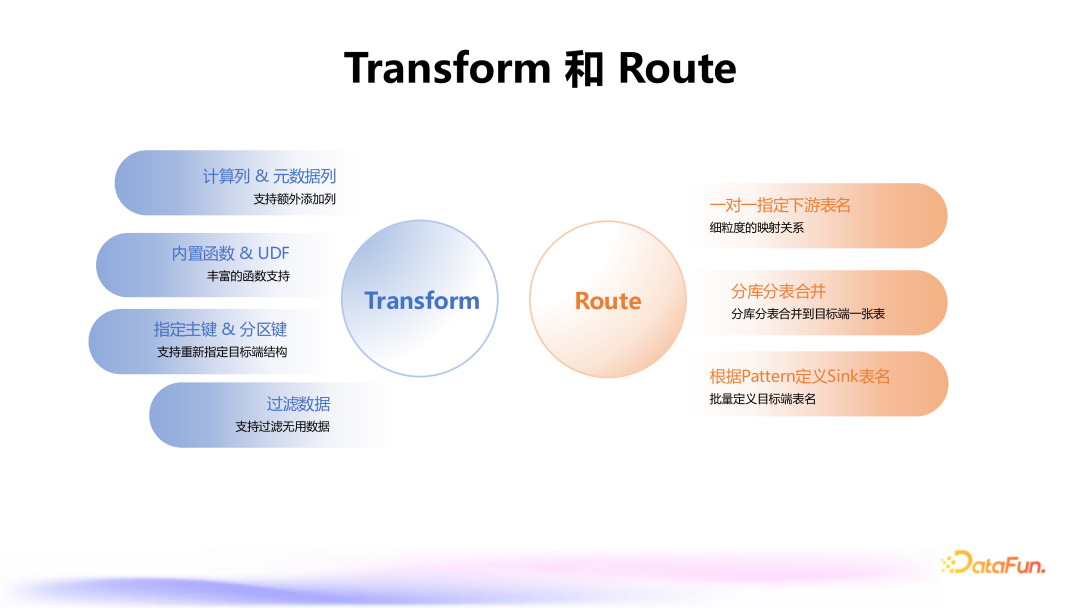
2. Transform 与 Route
Transform 模块: 支持常见的计算列和元数据列添加(如 DATABASE、TABLE 等)。 提供丰富的内置函数,并支持用户定义 UDF(自定义函数)进行复杂计算。 对 Flink ScalarFunction 函数进行了兼容,简化了开发过程。 支持指定分区键或主键等下游存储所需的特定信息,以及对数据进行过滤和列裁剪。 Route 模块: 指定源到目标的映射关系支持一对一指定下游表名。 指定源到目标的映射关系支持多对一的映射,常用于分库分表合并的场景。 提供模式(Pattern)功能,允许批量定义下游表名,方便管理和展示。
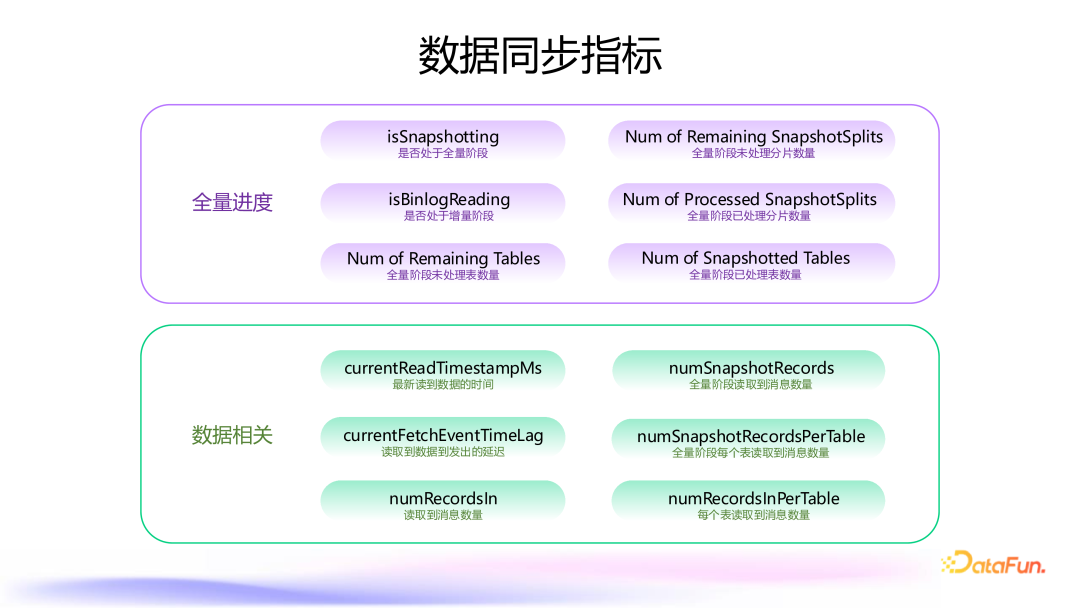
3. 监控指标
isSnapshoting:判断作业是否处于全量读取阶段。 isBinlogReading:判断作业是否处于增量读取阶段。 Num of Remaining Tables、Num of Snapshotted Tables :全量阶段未处理和已处理表数量。 Num of Remaining SnapshotSplits、Num of Processed SnapshotSplits :全量阶段未处理和已处理分片数量。
时间方面指标: currentReadTimestampMs:最新读取到的数据时间戳,帮助了解数据同步延迟。 currentFetchEventTimeLag:常见 LAG 指标,衡量数据从源到目标的延迟。 数据量指标: numRecordsln:读取过程中的总数据量。 numRecordslnPerTable:每个表读取到数据量。 numSnapshotRecords、numSnapshotRecordsPerTable:对全量阶段读取的数据进行统计,便于数据审计和验证数据完整性。
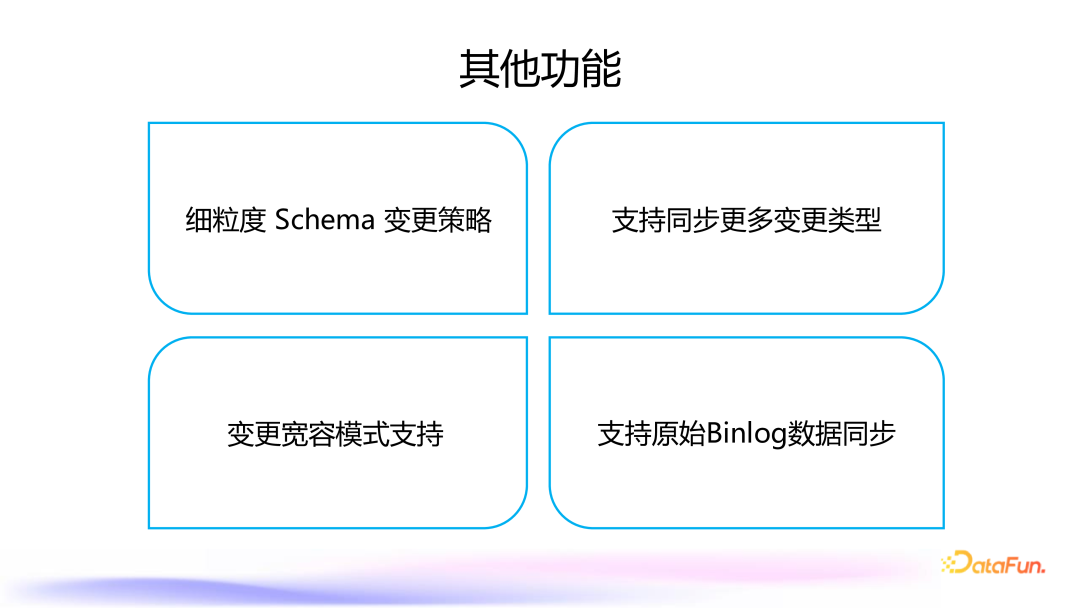
4. 其他功能
细粒度 Schema 变更策略:用户可以根据需求选择是否同步特定类型的变更操作(如 DELETE、DROP TABLE 等),避免不必要的数据操作影响下游系统。 支持同步更多变更类型:支持更多类型的变更,包括以前不被支持的操作(如 truncate table) 变更宽容模式支持 支持原始 Binlog 数据同步:支持将上游数据库的原始 Binlog Changelog 同步到下游系统,如 Kafka,以便于进一步处理。
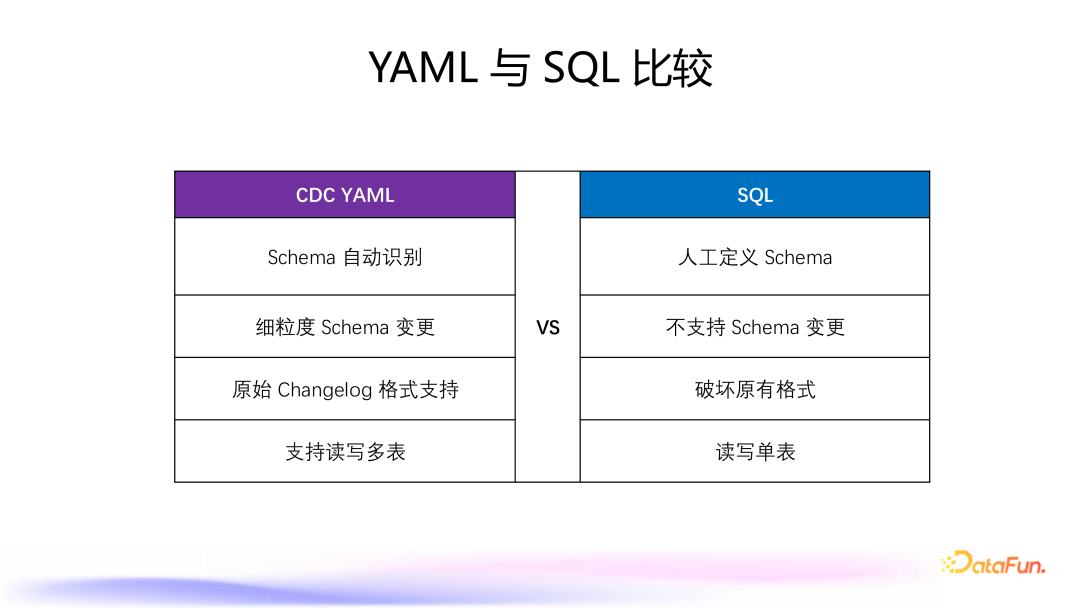
5. YAML 与 SQL 比较
Schema 自动识别: CDC YAML:用户无需手动定义 schema,系统通过数据中的消息或强 schema 自动查询并识别 schema。 SQL 作业:需要用户手动定义和管理 schema。 细颗粒度 Schema 变更: CDC YAML:默认支持 schema 变更的自动同步,并提供细粒度的变更控制,允许用户灵活配置哪些变更操作应被同步。 SQL 作业:通常不支持实时 schema 变更同步,需要额外处理机制来捕获和应用这些变更。 原始 ChangeLog 格式支持: CDC YAML:传递的数据格式包括 schema change event 和 data change event,能够原生支持原始 Changelog 的同步到下游。 SQL 作业:无法直接处理原始 Binlog Changelog。 CDC YAML 支持读写多表,SQL 仅支持读写单表
6. YAML 与 CTAS/CDAS 比较额外支持的功能
Schema 变更支持: YAML 支持上游表结构变更时立刻同步到下游,而 CTAS/CDAS 需要等待下一条数据写入才能触发结构变更。 原始 Changelog 变更支持: YAML 能够支持原始 Changelog 变更。 表名定义灵活性: YAML 允许灵活定义下游表名,可以针对每张表单独设置。 细粒度 Schema 变更: YAML 支持细粒度的 Schema 变更、裁剪列和过滤数据等功能。

7. YAML 与 DataStream 比较的优势
隐藏底层细节,开发简单: YAML 作业隐藏了底层实现细节,通过 YAML 文件进行配置,使得用户更容易理解和操作。 面向多种用户,YAML 格式易于学习理解: YAML 设计面向多用户,无需深入了解 Java 分布式系统或 Flink,降低了使用门槛。 便于复用已有作业: YAML 简化了开发流程,用户无需编写复杂的 DataStream 代码即可实现数据同步。

CDC YAML 典型应用场景
1. 整库同步
例如,在 app_db 数据库中有三张表,通过定义 source 和 sink,以及在 source 的 tables 部分使用正则表达式匹配所有表,可以实现整库同步。 当进入增量阶段时,例如在 orders 表中添加一个 amount 列,该结构变更也会同步到下游的数据库中。

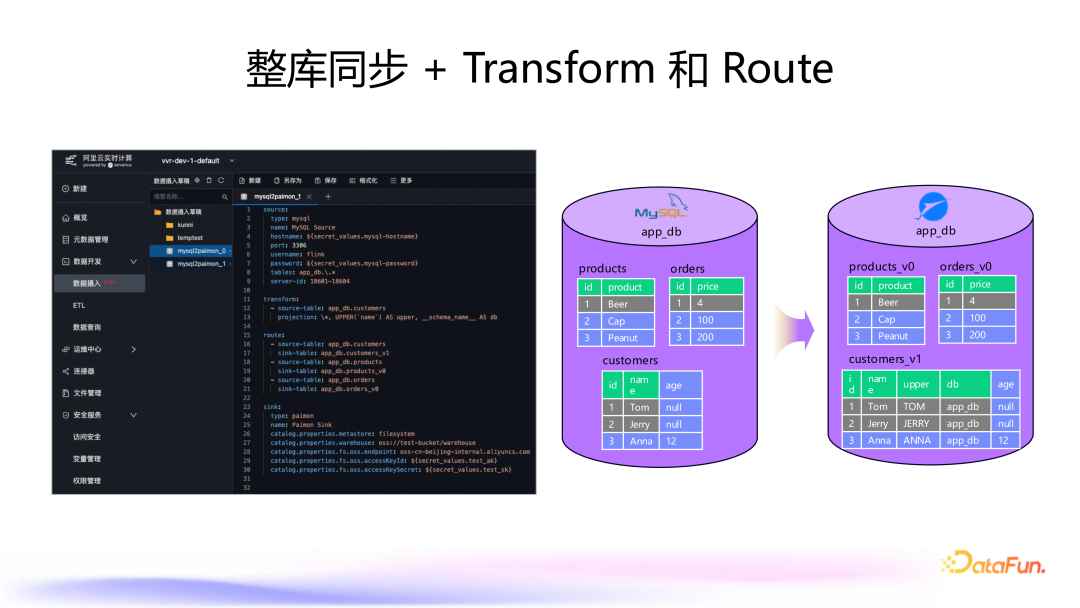
2. 整库同步 + Transform 和 Route
例如,可以在下游同步时为表名添加一个 version 后缀,通过 transform 模块实现这些操作。 使用 projection 定义数据转换规则,例如将所有列名同步到下游,并对 name 字段进行大写转换,添加 schema name 等元数据列。 这些操作可以在 schema 变更时自动同步,例如添加一个 age 列。
3. 分库分表同步
例如,将 app_db 中的多个版本的 customer 表合并到下游数据库中的一张 customer 表中。

4. 整库同步 + 宽容模式
在宽容模式下,可以将上游多种数据类型映射到下游的某个类型中,减少不必要的 schema 变更操作。

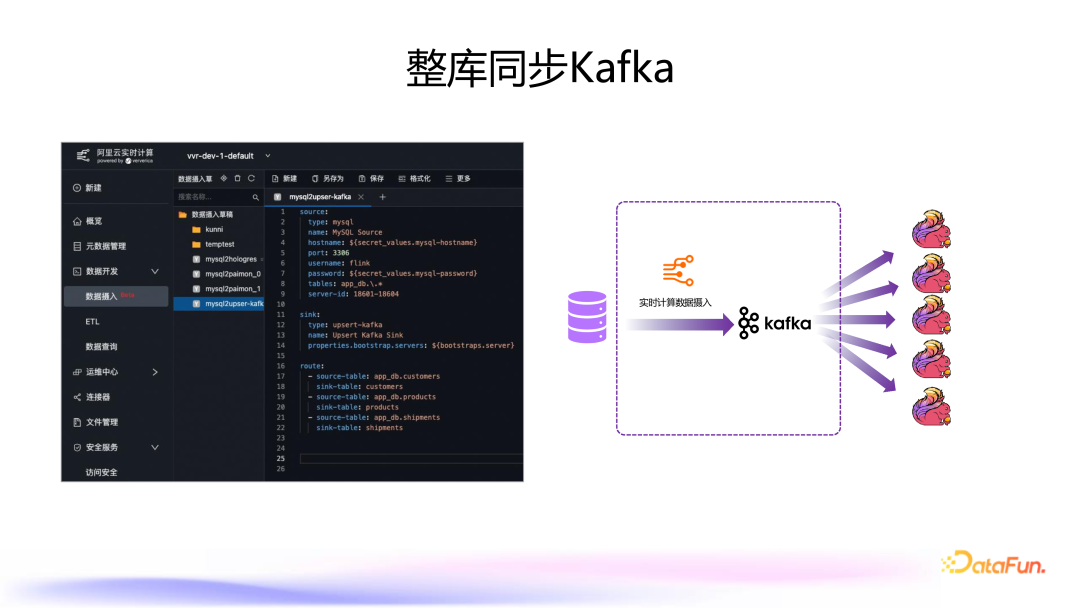
5. 整库同步到 Kafka
例如,将 app_db 中的三张表映射到下游的三个 Kafka topic 中。
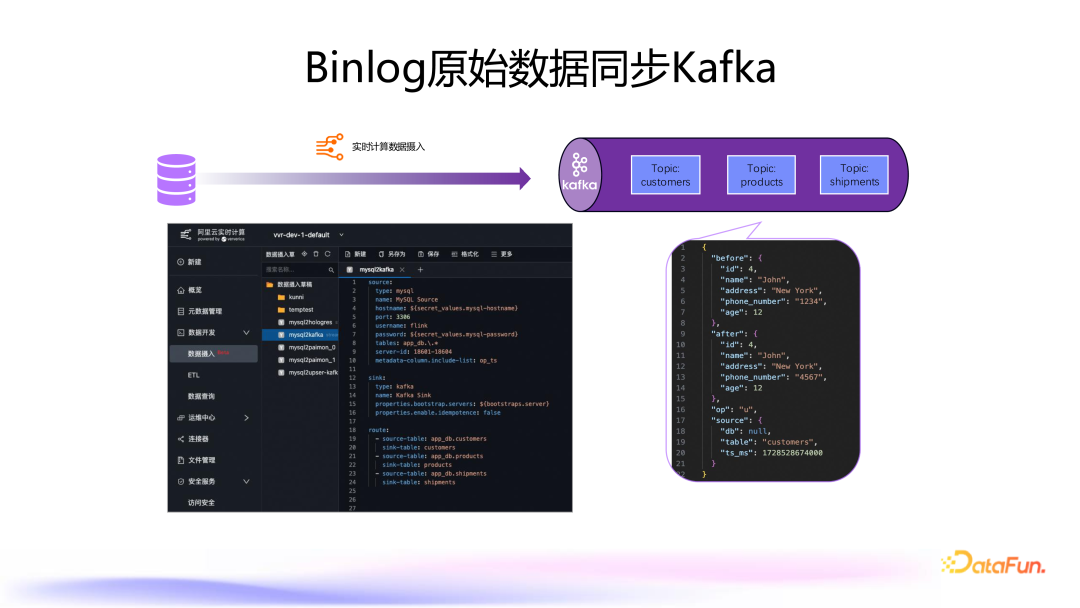
6. Binlog 原始数据同步 Kafka
支持将 MySQL 上游的 binlog 变更数据同步到 Kafka,用于 changelog 审计或数据回放。 支持 Debezium JSON 和 Canal JSON 两种常用的 changelog 格式。
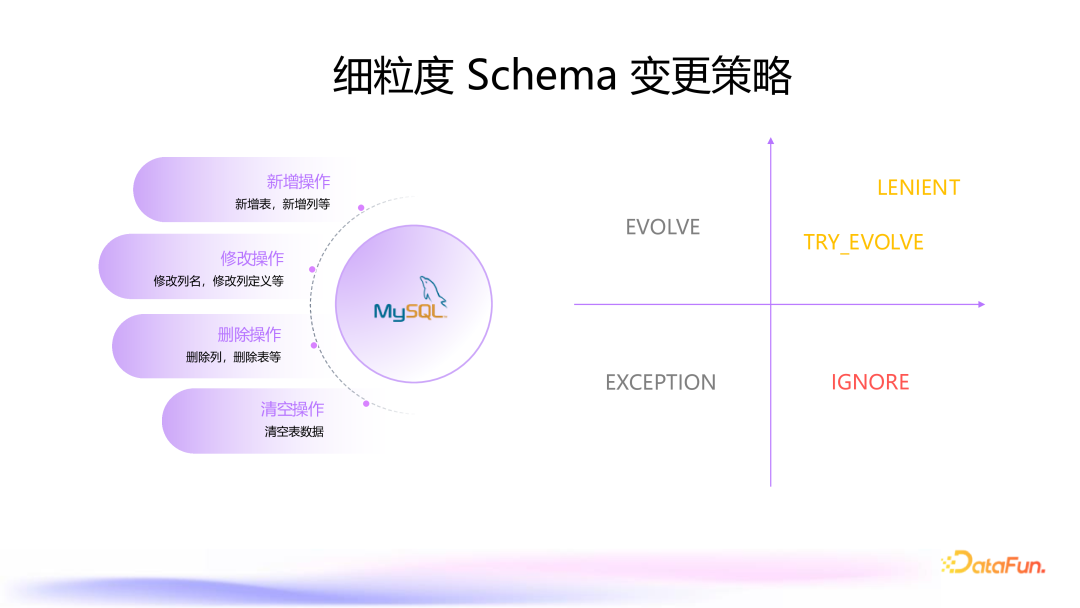
7. 细粒度变更策略控制
支持新增表、新增列、修改列名、修改列定义、删除列、删除表和清空表等操作。 提供细粒度的变更策略控制,用户可以灵活选择需要同步的变更类型。
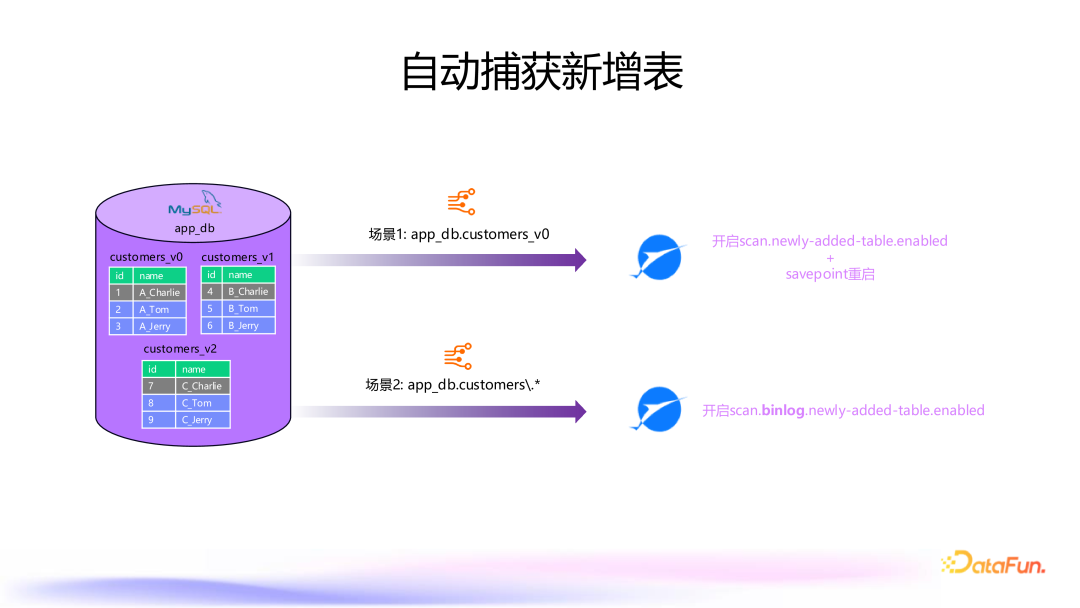
8. 自动捕获新增表
历史数据同步:通过开启 scan.newly-added-table.enabled 选项,并通过 savepoint 重启作业来读取新增表的历史数据。 增量数据同步:只需开启 scan.binlog.newly-added-table.enabled 选项,自动同步新增表的增量数据。
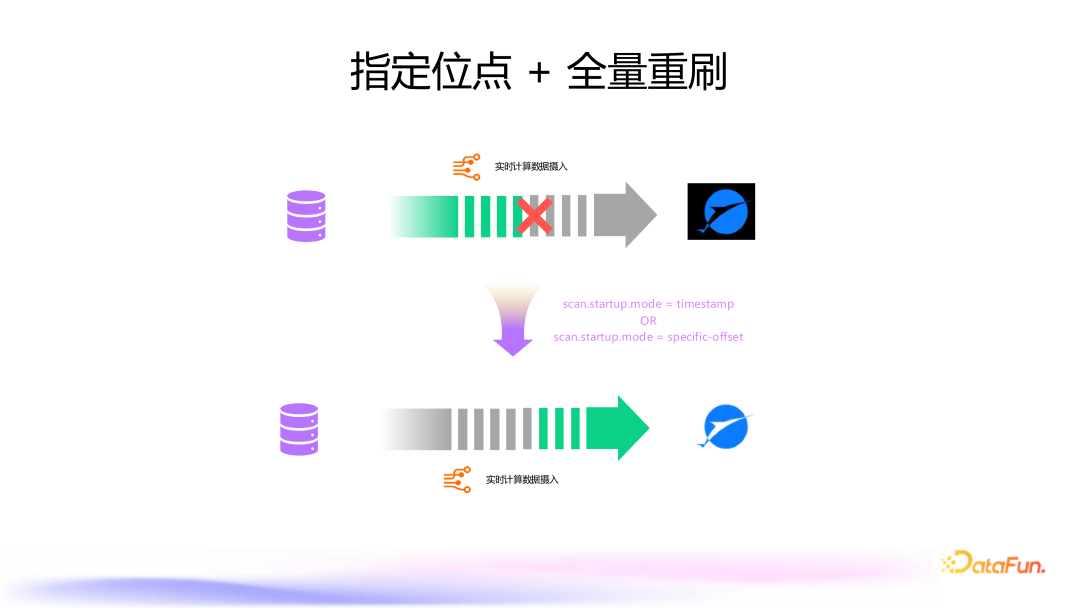
9. 指定位点 + 全量重刷
支持指定位点间隔全量重刷操作,解决数据同步过程中因上游 MySQL 版本不兼容或 binlog 配置问题导致的数据解析错误。 用户可以定义具体的 offset 或 timestamp,跳过错误数据,重新进行数据同步。
10. MySQL CDC 企业级性能优化
我们引入了一些优化参数,改进 Debezium 的相关参数,这些参数能够提升数据处理性能约 11%。
Binlog 存储了实例下所有数据库和表的数据,解析这些数据会耗费较多时间。因此,我们在解析引擎中配置了过滤机制,仅匹配和处理相关表的数据,从而提高效率。优化效果取决于需要过滤的数据量。
我们对解析 Binlog 的过程进行了并行化优化,这包括了解析和序列化两个阶段。这两个阶段是数据处理中的耗时部分,优化后能够分别提升性能 14% 到 42%。

Demo & 未来展望
1. Demo:整库同步 Paimon & 同步 Binlog 到 Kafka
通过配置两个整库同步作业,展示了如何使用数据收入工具进行数据同步。 为了便于观察 Schema 变更,我们将变更模式设置为 “evolve”,以便将 Schema 完整同步到下游。
作业启动后,提供了丰富的数据摄入指标,如“is_snapshoting”和“is_incremental_reading”,以监控全量和增量读取阶段。
展示了如何从上游数据库读取数据,并在下游数据库中执行插入、更新和删除操作。 通过直接在 Flink CDC 的 session 集群中运行作业,验证了数据的正常读取和同步。
整库同步 Paimon
同步 Binlog 到 Kafka
2. 未来规划

3. 文档链接

文档链接:
数据摄入 Beta 版:https://help.aliyun.com/zh/flink/user-guide/develop-a-yaml-draft?spm=a2c4g.11186623.help-menu-45029.d_2_2_3.53b92058TtBz1e&scm=20140722.H_2846225._.OR_help-V_1
开源 Flink CDC:https://nightlies.apache.org/flink/flink-cdc-docs-stable/
相比于传统数据集成流水线,Flink CDC 提供了全量和增量一体化同步的解决方案。对于一个同步任务,只需使用一个 Flink 作业即可将上游的全量数据和增量数据一致地同步到下游系统。此外, Flink CDC 使用了增量快照算法,无需任何额外配置即可实现全量和增量数据的无缝切换。
现推出“Flink CDC 挑战任务”参与挑战不仅可快速体验《基于 Flink CDC 打造企业级实时数据同步方案》,限时上传任务截图还可获得精美礼品。

扫描二维码或点击阅读原文即可跳转:Flink CDC 挑战任务。
https://developer.aliyun.com/topic/flinkcdc





 点击「阅读原文」跳转 Flink CDC 实时数据同步方案~
点击「阅读原文」跳转 Flink CDC 实时数据同步方案~