





本文字数:13618;估计阅读时间:35 分钟

Meetup活动
ClickHouse Shanghai User Group第2届 Meetup 火热报名中,详见文末海报!

在本文中,我们宣布开源 kubenetmon——这是我们用于监控 ClickHouse Cloud 数据传输的工具。项目地址:GitHub https://github.com/ClickHouse/kubenetmon。
云计算为软件团队提供了诸多优势,例如现成的基础设施组件、无限的可扩展性、高性价比等。在云成本规划中,许多企业都会精打细算计算和存储资源的使用。然而,云账单中排名第三的开销项——网络——却往往被忽视。这在很大程度上是因为网络的计量和理解难度较大。
我们在 ClickHouse Cloud 也遇到了类似的问题。我们的服务运行在 AWS、GCP 和 Azure 三大云平台上,并在每个平台的多个区域部署,使得基础设施覆盖数十个区域,这还不包括我们的测试和开发环境。每个区域通常包含多个 Kubernetes 集群。
要理解这样一个复杂系统的网络行为,挑战不小。与此同时,数据传输费用的计算也更加复杂。
云提供商通常会对以下数据传输项收费:
NAT 网关; 负载均衡器; 跨可用区流量; 出站流量 (Egress):费用取决于数据的源区域和目标区域; 入站流量 (Ingress):费用同样取决于数据进入的区域及其来源。
为了解决这一难题,我们开发了 kubenetmon,接下来的文章将详细介绍我们的方案。

在定义数据传输可见性的目标时,我们确定了三个核心方向:
1. 取证 (Forensics)
我们希望记录 L3/L4 级别的每个连接,并将其作为时间序列数据存储,以覆盖整个连接的生命周期。这样,我们可以分析即使是长时间运行的连接,其吞吐量如何随时间变化。例如,与其仅仅知道某个连接的起始时间、持续时长和总数据量,我们更希望获取更精细的数据传输速率(例如每分钟的带宽记录)。这些信息可以帮助我们回答:该连接在不同时间段的表现如何?
2. 归因 (Attribution)
我们的基础设施采用多租户架构,多个客户的工作负载运行在同一套硬件上。因此,要准确分析数据传输情况,我们需要知道连接属于哪个工作负载,以及该工作负载所在的可用区和 Pod。如果连接的一端在我们的基础设施之外,我们也希望尽可能收集相关信息,例如它是否位于同一云服务商、同一区域等。这些信息可以帮助我们回答:哪个工作负载建立了该连接?它的远程端点是什么?
3. 计量 (Metering)
对于某些高成本的数据传输场景(如公网出站流量),我们希望能够对其进行精确计量,并按工作负载进行归类。因此,我们需要建立一个长期存储系统,以按工作负载和数据传输的业务类别,汇总和追踪数据使用情况。这些信息可以帮助我们回答:特定的数据传输费用类别的使用趋势如何变化?哪些内部或客户使用模式的变化导致了趋势波动?
尽管网络监控有许多可扩展的方向,但我们认为,这些目标精准反映了我们的核心挑战。例如,在某些情况下,分析应用层协议(如 DNS 或 HTTP)或跟踪特定连接的 TCP 重传率可能会有帮助,但这些并不在我们的核心关注范围内。我们专注于 L3/L4 级别的连接记录、工作负载归因和数据传输计量。
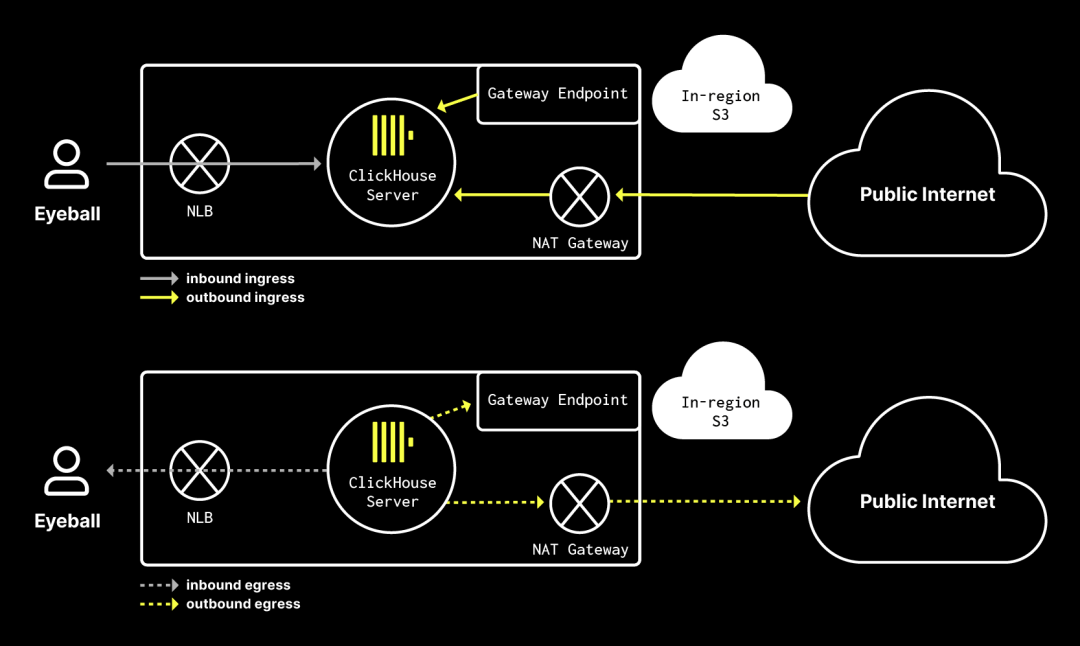
我们云环境中的主要流量路径示意图。该示意图未包含 ClickHouse 服务器副本之间、服务器与 Keeper 之间,以及其他运行的工作负载之间的东西向(East-West)流量。
我们相信,我们的需求并非独特,因此我们深入研究了现有的数据采集解决方案。这些需求本身并不算复杂,因此我们原本以为应该有许多成熟的解决方案可以直接满足要求。然而,我们惊讶地发现,没有一个选项能完全符合我们的需求!
接下来,我们介绍所考虑的方案以及选择过程。
Cilium CNI
我们在 ClickHouse Cloud 中使用了 Cilium,它不仅具备强大的网络功能,还通过 Cilium Hubble 提供了先进的可观测性。然而,我们发现,Cilium Hubble 在数据采集方面有一定的局限性——它要么提供缺乏上下文的流量数据,要么提供带有丰富上下文但缺少流量信息的连接数据。例如,Cilium 提供的 forward_bytes 和 forward_count 指标可以提供流量信息,但缺乏连接端点的数据;另一方面,Cilium 也能提供详细的连接信息,但相关指标并不包含流量数据,而是仅能统计流量发生的次数(Flow Count),但 Cilium 语境下的“Flow”并不表示带宽,而是基于 TCP 标志位或时间间隔进行计数。
事实上,包括我们在内的许多人都对此感到惊讶。Cilium 的技术实现使得这一问题难以解决,我们推荐阅读 Cilium GitHub 相关 Issue 以了解详细讨论:https://github.com/cilium/cilium/issues/32193。
CSP 流日志 (CSP Flow Logs)
云服务商提供了数据传输跟踪能力,但这些功能本身成本较高。此外,各云服务商的功能差异较大,在 AWS 和 Azure 上,我们发现难以在流日志中添加 Kubernetes 工作负载标签。此外,我们的计量架构不得不针对不同云商进行定制,而无法采用统一的数据收集方案。
成本计量方案 (Cost-Metering Solutions)
市面上已有许多 FinOps 相关工具,例如 OpenCost,但这些工具侧重于成本管理,对单个连接的行为分析能力较弱。
在 ClickHouse 中实现 (Do it in ClickHouse!)
当然,我们也考虑过在 ClickHouse 应用程序中实现一些简单的用户空间功能,用以追踪与 ClickHouse 的连接情况。ClickHouse 本身已经有很多系统表,收集了各种有用的信息;例如,ClickHouse 在 system.metrics 中已经收集了一些网络相关的信息,包括 TCPConnection、NetworkReceive、NetworkSend 等等。更重要的是,在 ClickHouse Cloud 中,我们已经有一个系统,可以持续抓取并导出客户实例中的匿名化系统表数据,称为 SysEx,因此数据传输记录的导出可以开箱即用。
不过,这种方法也存在一些挑战。首先,根据定义,我们无法看到非 ClickHouse 工作负载之间的流量,而这种工作负载越来越多。其次,在用户空间应用程序中系统性地追踪 L3/L4 层的所有网络流量是复杂的,容易导致代码过于冗长,因为入站和出站请求通常是在更高层次实现的,并且分布在代码库的各个部分。最后,这种方法也无法为我们任务中的归因部分提供合适的实现位置,而这部分显然不应该放在 ClickHouse 的代码库中。
基于 eBPF 的非 Cilium 解决方案
我们还考虑了一些 Cilium 之外的 eBPF 工具,例如 Retina。Retina 专为云环境中的网络可观测性设计,并已被集成到 Azure 的部分高级产品中。得益于 eBPF,这类方案几乎可以访问所有网络数据。此外,它们已经具备将连接信息与工作负载标签关联的能力,这正是我们所需要的。例如,我们还考虑了复用 Datadog system-probe agent 的开源组件。
然而,我们最终决定不采用这一方案,主要是因为不同供应商的 eBPF 负载可能会产生互操作性问题,而我们无法确保它们能够正确配合使用。需要注意的是,我们已经在使用基于 eBPF 的 Cilium,并且在 GKE 上依赖基于 Cilium 的 dataplane v2。如果多个由不同团队开发的 eBPF 组件出现兼容性问题,可能带来较大的影响范围。因此,我们希望将数据传输路径上的 eBPF 负载限制在 Cilium 相关的工作负载之内。此外,正确测试和集成这些方案所需的工作量可能比直接解决问题本身还要大。
另一个潜在问题是 Prometheus,它是当前主流的指标存储工具(并且确实非常强大!)。然而,连接信息越丰富,数据的基数(cardinality)也会越高,而 Prometheus 处理高基数数据的成本极其高昂。因此,我们希望尽量避免使用基于指标的模型。
在权衡所有方案后,我们决定开发一套内部解决方案,并尽量保持简单。为此,我们需要回答三个核心问题:
3. 如何存储这些连接记录?
如何采集连接数据?
我们的答案是:conntrack!标准的 Linux 网络栈会跟踪系统处理的所有连接状态,并通过 conntrack 表对外提供这些信息。conntrack 是 Linux netfilter 框架中的核心组件,具备完善的 API,并且在 Go 和 Rust 生态中已有成熟的库支持。
那么,conntrack(即连接跟踪表)中的数据长什么样呢?以下是一个示例:
# conntrack -Ltcp 6 35 TIME_WAIT src=10.1.1.42 dst=10.1.2.228 sport=41442 dport=5555 src=10.1.2.228 dst=10.1.1.42 sport=5555 dport=41442 [ASSURED] mark=0 use=1tcp 6 431999 ESTABLISHED src=10.1.0.27 dst=10.1.131.55 sport=37670 dport=10249 src=10.1.131.55 dst=10.1.0.27 sport=10249 dport=37670 [ASSURED] mark=0 use=1
我们可以从 conntrack 表中获取连接的协议、端点 IP 和端口、当前连接状态等信息。但这些数据并未包含数据传输量的信息。不过,只要我们在 netfilter 中启用流量统计功能,就可以获取每个连接的字节数和数据包计数(分别统计双向流量)。
# echo "1" > proc/sys/net/netfilter/nf_conntrack_acct# conntrack -Ltcp 6 35 TIME_WAIT src=10.1.1.42 dst=10.1.2.228 sport=41442 dport=5555 packets=334368 bytes=106591692 src=10.1.2.228 dst=10.1.1.42 sport=5555 dport=41442 packets=280371 bytes=692287110 [ASSURED] mark=0 use=1tcp 6 431999 ESTABLISHED src=10.1.0.27 dst=10.1.131.55 sport=37670 dport=10249 packets=20 bytes=21564 src=10.1.131.55 dst=10.1.0.27 sport=10249 dport=37670 packets=11 bytes=2011 [ASSURED] mark=0 use=1
conntrack 可能存在一定风险,这是众所周知的,尤其是在表项溢出的情况下。例如,Cloudflare 和 Tigera 都曾发表博客文章讨论这一问题。虽然这点需要考虑,但并未影响我们对本项目的规划。因为 conntrack 早已在我们的基础设施中使用,本项目并非首次启用它。此外,我们的基础设施由多个 Kubernetes 集群组成,每个集群承担不同的角色。其中,每台机器连接密度最高的“代理(proxy)”集群并不是我们的主要监控目标。我们更关注的是运行客户工作负载的集群中的数据传输情况,因此选择在这些集群中依赖 conntrack。由于这些集群的节点相对分散,因此 conntrack 表几乎不会填满。
开启流量统计功能对内核的额外计算负担极小,对性能影响可以忽略不计。同时,计数器本身占用 8 字节,已足够应对需求。
综合来看,我们的方案是在已启用 conntrack 的客户工作负载集群中开启流量统计功能,并定期采集 conntrack 表的数据进行流量监控。这种方式可能会漏掉短暂存活的连接或刚刚关闭的连接的“尾端”数据。虽然可以调整 conntrack 在连接关闭后保留状态的时间,但我们认为这部分数据的缺失影响不大。在采集 conntrack 数据时,我们通过 conntrack API 提供的特殊设置,让内核在抓取数据时原子性地将计数器清零(这一操作是安全的,因为没有其他系统依赖该信息)。这样,我们可以确保采集到的数据是增量数据,而非累计数据,准确反映了抓取周期内的吞吐量。
尽管云计算提供了高度抽象的环境,但归根结底,我们依然可以依赖底层的 Linux 网络机制!
如何识别连接对应的端点?
假设我们现在已经有一个守护进程(daemon),能够每隔几秒抓取一次 conntrack 数据。那么,接下来的问题是什么?我们已经获取了端点的 IP、端口、字节数和数据包计数,但这些信息本身并不足够。我们还需要解决连接归属的问题。
为此,我们在守护进程中实现了标记(labeling)逻辑,并将其命名为 kubenetmon。这项任务的核心逻辑其实很简单:每次抓取 conntrack 数据时,我们查询 Kubernetes API,找到特定 IP 所属的 Pod,并提取相关信息。事实上,这一实现过程确实很顺利——我们快速完成了一个原型,并验证了其可行性。正如我们的开源项目所示,我们确实做了一些额外的工作,比如识别连接方向和处理 NAT 相关问题,但整体上,它的表现符合预期。此外,我们还支持对集群外部端点的标记,例如,我们追踪 AWS 服务的 IP 范围,这使我们能够识别远端是否属于 AWS,并确定其所在的区域。这样,我们就能区分跨区域与同一区域的流量。
然而,原型的性能表现并不理想。它占用了大量内存,更严重的是,它给 Kubernetes API 带来了较大的负载。为了解决这个问题,我们决定改用 Kubernetes informer,而不是每次查询都直接访问 Kubernetes API。informer 允许我们监听 Kubernetes 事件,并在本地维护集群状态映射。这样,每当需要为某个连接添加标签时,我们可以直接使用本地缓存,而不必反复查询 API。
尽管 informer 机制降低了 API 负载,但内存占用问题仍然存在,甚至在迁移到 informer 模型后变得更严重了。原因很简单——我们需要在内存中维护更多的状态。很快,我们意识到,每个节点上运行的守护进程无法跟踪整个集群的状态,尤其是在大规模集群中。
为了解决这个问题,我们将 kubenetmon 拆分为两个组件:kubenetmon-agent 和 kubenetmon-server。其中,kubenetmon-agent 负责定期抓取 conntrack 数据,并通过 gRPC 将记录发送给 kubenetmon-server。kubenetmon-server 负责处理所有连接标记逻辑,并结合 Kubernetes 元数据进行归类。由于 kubenetmon-server 本身是无状态的(不需要在重启后保留任何信息),我们可以轻松扩展它的副本,以满足更高的吞吐需求。
这种基于 informer 机制和星型架构(hub-and-spoke architecture)的优化方案,让我们对最终结果感到满意。kubenetmon-agent 的内存占用通常保持在 5-20 MB 之间。
至此,最后的任务就是构建存储方案,以保存所有收集到的连接信息。
如何存储连接记录?
幸运的是,我们很快就确定了数据的最终存储方案——ClickHouse。ClickHouse 以其卓越的高基数数据处理能力而闻名,这使我们毫不担心大量连接属性数据会对查询性能造成影响。无论是查询还是分析,我们都可以灵活地处理这些数据,而无需顾虑性能瓶颈。
此外,我们已经在各个环境中运行了 ClickHouse 集群,用于收集系统的度量指标、日志以及其他相关数据。这些集群在内部被称为 LogHouses。
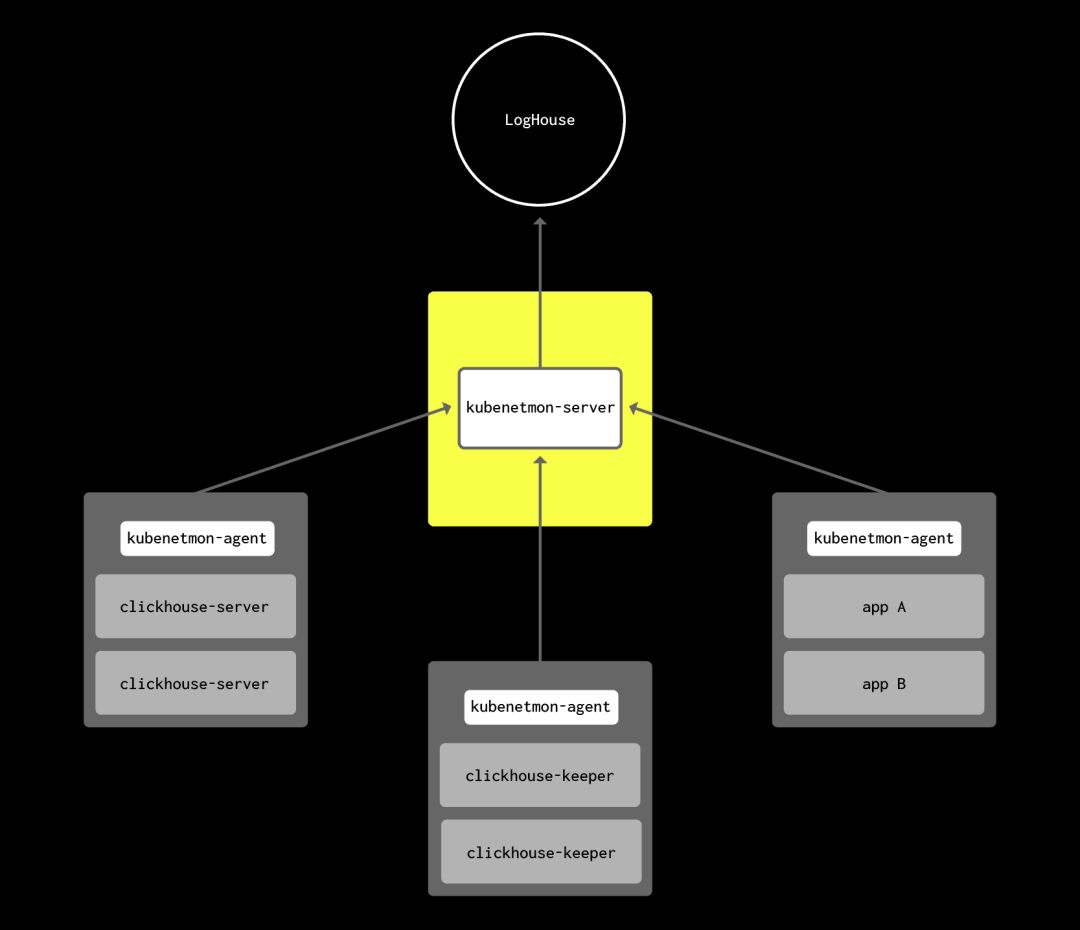
kubenetmon 结构示意图。kubenetmon-agent 作为一个轻量级的 DaemonSet 运行在每个节点上,定期抓取 conntrack 数据,并通过 gRPC 将数据传输到 kubenetmon-server。kubenetmon-server 结合 Kubernetes 集群元数据对数据进行标注,并批量推送到 LogHouse,我们的内部 ClickHouse 分析集群。
下面是我们在 LogHouse 中创建的网络数据表的定义:
CREATE TABLE default.network_flows_0(`date` Date CODEC(Delta(2), ZSTD(1)),`intervalStartTime` DateTime CODEC(Delta(4), ZSTD(1)),`intervalSeconds` UInt16 CODEC(Delta(2), ZSTD(1)),`environment` LowCardinality(String) CODEC(ZSTD(1)),`proto` LowCardinality(String) CODEC(ZSTD(1)),`connectionClass` LowCardinality(String) CODEC(ZSTD(1)),`connectionFlags` Map(LowCardinality(String), Bool) CODEC(ZSTD(1)),`direction` Enum('out' = 1, 'in' = 2) CODEC(ZSTD(1)),`localCloud` LowCardinality(String) CODEC(ZSTD(1)),`localRegion` LowCardinality(String) CODEC(ZSTD(1)),`localCluster` LowCardinality(String) CODEC(ZSTD(1)),`localCell` LowCardinality(String) CODEC(ZSTD(1)),`localAvailabilityZone` LowCardinality(String) CODEC(ZSTD(1)),`localNode` String CODEC(ZSTD(1)),`localInstanceID` String CODEC(ZSTD(1)),`localNamespace` LowCardinality(String) CODEC(ZSTD(1)),`localPod` String CODEC(ZSTD(1)),`localIPv4` IPv4 CODEC(Delta(4), ZSTD(1)),`localPort` UInt16 CODEC(Delta(2), ZSTD(1)),`localApp` String CODEC(ZSTD(1)),`remoteCloud` LowCardinality(String) CODEC(ZSTD(1)),`remoteRegion` LowCardinality(String) CODEC(ZSTD(1)),`remoteCluster` LowCardinality(String) CODEC(ZSTD(1)),`remoteCell` LowCardinality(String) CODEC(ZSTD(1)),`remoteAvailabilityZone` LowCardinality(String) CODEC(ZSTD(1)),`remoteNode` String CODEC(ZSTD(1)),`remoteInstanceID` String CODEC(ZSTD(1)),`remoteNamespace` LowCardinality(String) CODEC(ZSTD(1)),`remotePod` String CODEC(ZSTD(1)),`remoteIPv4` IPv4 CODEC(Delta(4), ZSTD(1)),`remotePort` UInt16 CODEC(Delta(2), ZSTD(1)),`remoteApp` String CODEC(ZSTD(1)),`remoteCloudService` LowCardinality(String) CODEC(ZSTD(1)),`bytes` UInt64 CODEC(Delta(8), ZSTD(1)),`packets` UInt64 CODEC(Delta(8), ZSTD(1)))ENGINE = SummingMergeTree((bytes, packets))PARTITION BY datePRIMARY KEY (date, intervalStartTime, direction, proto, localApp, remoteApp, localPod, remotePod)ORDER BY (date, intervalStartTime, direction, proto, localApp, remoteApp, localPod, remotePod, intervalSeconds, environment, connectionClass, connectionFlags, localCloud, localRegion, localCluster, localCell, localAvailabilityZone, localNode, localInstanceID, localNamespace, localIPv4, localPort, remoteCloud, remoteRegion, remoteCluster, remoteCell, remoteAvailabilityZone, remoteNode, remoteInstanceID, remoteNamespace, remoteIPv4, remotePort, remoteCloudService)TTL intervalStartTime + toIntervalDay(90)SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1
那么,我们如何利用这张表?例如,如果我们想要分析 ClickHouse 服务器向外部目的地址发起的出站(egress)连接,可以执行如下查询:
SELECT intervalStartTime, sum(bytes)FROM loghouse.network_flows_0WHERE direction = 'out' AND localApp = 'clickhouse-server' AND connectionClass != 'INTRA_VPC'GROUP BY intervalStartTimeORDER BY intervalStartTime DESC
在表设计和数据插入过程中,我们发现了一些值得注意的优化点:
SummingMergeTree 表。我们之前提到,每次抓取 conntrack 数据时,都会重置计数器。假设每 5 秒抓取一次,并希望按分钟计算吞吐量,该如何实现? 一种方式是直接将数据存入 MergeTree 表,并在查询时进行聚合。但我们利用了 ClickHouse 的 SummingMergeTree,它可以自动按所有其他键的唯一值组合聚合 bytes 和 packets,大幅减少查询计算量。由于 intervalStartTime 始终等于 toStartOfMinute(timestamp),这确保了数据以分钟为单位进行统计。如果需要更长时间的聚合窗口,可以将 intervalStartTime 设为 toStartOfFiveMinutes(timestamp),并将 intervalSeconds 设为 300,实现 5 分钟的聚合粒度。
主键与排序键优化。在 ClickHouse 中,默认情况下,主键和排序键是相同的。但 SummingMergeTree 要求所有用于分组计算的列都必须包含在排序键中,而主键一旦定义就无法更改。为确保未来可以灵活添加新列,我们将二者独立定义:排序键包含所有字段(除了 bytes 和 packets),而主键始终是排序键的前缀。在排序键的顺序上,通常优先放置基数较低的列,同时确保常用的查询条件列优先排列,以优化查询性能。
异步插入与批处理优化。在 kubenetmon-server 中,我们采用批量插入策略,数据会在满足一定时间或大小条件时进行刷新。(有趣的是,我们最初曾遇到一个 bug:如果没有新数据到达,批次的超时机制不会触发,导致某些低流量环境未能及时写入数据。)为了提高插入效率,我们使用 异步插入(async inserts),让 ClickHouse 进一步批量处理数据,减少磁盘 I/O。同时,我们启用了 wait_for_async_insert 选项,确保数据不会丢失。此外,为避免单个插入线程阻塞,我们运行多个并发的 “worker” 线程,每个线程独立积累批次并进行插入。
去重机制(Deduplication)。虽然极少发生,但在某些情况下,后续抓取的批次可能会重复,比如某些连接在多个时间段内传输了相同的数据。由于 intervalStartTime 是按分钟对齐的,ClickHouse 可能会误认为这些批次是重复数据。为了确保所有数据都能被正确存储,我们在每次插入时都会设置 insert_deduplication_token,并赋予一个随机的 UUID,确保 ClickHouse 识别每个批次为独立数据,不进行去重处理。
我们已经成功落地这个方案!在某些环境下,每分钟会记录数百万条连接监测数据。虽然数据量看起来庞大,但 ClickHouse 的压缩能力非常出色,能够快速检索数据。此外,我们在表中配置了 TTL,确保数据自动保留 90 天。来看一下我们在某个区域的数据存储情况:
SELECTformatReadableQuantity(sum(rows)),formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,sum(data_compressed_bytes) sum(data_uncompressed_bytes) AS compression_ratioFROM system.partsWHERE (database = 'default') AND (`table` = 'network_flows_0') AND (active = 1);
Row 1:──────formatReadab⋯(sum(rows)): 399.05 billioncompressed_size: 2.66 TiBuncompressed_size: 86.69 TiBcompression_ratio: 0.0306292244205114521 row in set. Elapsed: 0.116 sec.
近 4000 亿行数据,原始大小 86.69 TiB,压缩后仅占 2.66 TiB,相当于压缩到原始体积的 3% 多一点。同时,我们还可以查看各个列的具体压缩情况:
SELECTname,data_compressed_bytes data_uncompressed_bytes AS compression_ratio,formatReadableSize(data_uncompressed_bytes) AS uncompressed_size,formatReadableSize(data_compressed_bytes) AS compressed_sizeFROM system.columnsWHERE (database = 'default') AND (`table` = 'network_flows_0')ORDER BY compression_ratio ASC;
┌─name───────────────────┬─uncompressed_size─┬─compressed_size─┬─pct───┐│ localApp │ 6.46 TiB │ 3.53 GiB │ 0.05 ││ remoteApp │ 1013.12 GiB │ 900.22 MiB │ 0.09 ││ proto │ 376.23 GiB │ 334.46 MiB │ 0.09 ││ localCloud │ 376.23 GiB │ 334.46 MiB │ 0.09 ││ remoteCell │ 376.23 GiB │ 334.46 MiB │ 0.09 ││ remoteClusterType │ 376.23 GiB │ 334.46 MiB │ 0.09 ││ localRegion │ 376.23 GiB │ 334.46 MiB │ 0.09 ││ environment │ 376.23 GiB │ 334.46 MiB │ 0.09 ││ localClusterType │ 376.23 GiB │ 334.46 MiB │ 0.09 ││ direction │ 376.23 GiB │ 338.19 MiB │ 0.09 ││ intervalSeconds │ 751.00 GiB │ 797.95 MiB │ 0.10 ││ date │ 751.00 GiB │ 809.68 MiB │ 0.11 ││ intervalStartTime │ 1.47 TiB │ 1.63 GiB │ 0.11 ││ remoteCloud │ 376.23 GiB │ 419.42 MiB │ 0.11 ││ remoteRegion │ 376.23 GiB │ 470.13 MiB │ 0.12 ││ localNamespace │ 5.51 TiB │ 10.88 GiB │ 0.19 ││ localInstanceID │ 12.91 TiB │ 27.82 GiB │ 0.21 ││ localPod │ 11.38 TiB │ 31.84 GiB │ 0.27 ││ localNode │ 10.63 TiB │ 36.97 GiB │ 0.34 ││ connectionClass │ 376.23 GiB │ 1.93 GiB │ 0.51 ││ localCell │ 376.23 GiB │ 2.59 GiB │ 0.69 ││ remoteCloudService │ 376.23 GiB │ 2.90 GiB │ 0.77 ││ connectionFlags │ 15.58 TiB │ 124.83 GiB │ 0.78 ││ localAvailabilityZone │ 376.23 GiB │ 5.26 GiB │ 1.40 ││ localIPv4 │ 1.47 TiB │ 21.26 GiB │ 1.42 ││ remoteAvailabilityZone │ 376.23 GiB │ 7.69 GiB │ 2.04 ││ remoteNamespace │ 920.65 GiB │ 19.25 GiB │ 2.09 ││ remoteNode │ 1.51 TiB │ 38.91 GiB │ 2.52 ││ remoteInstanceID │ 1.45 TiB │ 39.86 GiB │ 2.68 ││ remotePod │ 1.61 TiB │ 48.38 GiB │ 2.93 ││ remotePort │ 751.00 GiB │ 68.73 GiB │ 9.15 ││ packets │ 2.93 TiB │ 607.89 GiB │ 20.24 ││ localPort │ 751.00 GiB │ 189.61 GiB │ 25.25 ││ remoteIPv4 │ 1.47 TiB │ 429.64 GiB │ 28.60 ││ bytes │ 2.93 TiB │ 1.01 TiB │ 34.29 │└────────────────────────┴───────────────────┴─────────────────┴───────┘35 rows in set. Elapsed: 0.004 sec.
效果已经很不错了,不过如果进一步优化,或许还能提升性能。;)
这些数据帮助我们定位到一些极端异常情况,比如我们自己定期执行高成本的跨区域 S3 下载;识别基础设施中最活跃的跨可用区通信流量;以及评估工作负载所需的合理保证带宽。此外,我们还发现,每天有多个 TB 级别的 ClickHouse 备份被传输到其他云,导致出口流量费用极高。同时,我们也深入分析了通过“代理”表(如 MySQL Engine)从远程服务器拉取数据所带来的支持成本。
这是一个令人兴奋的项目。让我们惊讶的是,竟然找不到合适的工具来帮助我们更快地完成它。因此,我们决定将我们的成果开源——kubenetmon。你可以在我们的 GitHub 主页找到这个项目:https://github.com/ClickHouse/kubenetmon,并按照说明进行尝试。欢迎大家尝试、应用,或者从中获取灵感!
如果你有任何问题或反馈,请联系 ilya.andreev@clickhouse.com,或在 GitHub 项目中提交 issue。

好消息:ClickHouse Shanghai User Group第2届 Meetup 已经开放报名了,将于2025年03月01日在上海 阿里巴巴徐汇滨江园区X区3层X7-301龙门书院 举行,扫码免费报名

 注册ClickHouse中国社区大使,领取认证考试券
注册ClickHouse中国社区大使,领取认证考试券

ClickHouse社区大使计划正式启动,首批过审贡献者享原厂认证考试券!
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


