




写在前面的话
查看hive建表语句
CREATE TABLE `ods.log_info`(log_id string,log_type string,original_msg string,create_time bigint,update_time bigint)PARTITIONED BY (`d_date` string COMMENT '快照日',`pid` string COMMENT '渠道号')ROW FORMAT SERDE'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat复制
查看MapredParquetInputFormat类
protected MapredParquetInputFormat(final ParquetInputFormat<ArrayWritable> inputFormat) {this.realInput = inputFormat;vectorizedSelf = new VectorizedParquetInputFormat(inputFormat);}复制
查看ParquetInputFormat 类(getSplits 方法)
public static boolean isTaskSideMetaData(Configuration configuration) {return configuration.getBoolean("parquet.task.side.metadata", Boolean.TRUE);}复制
public List<InputSplit> getSplits(JobContext jobContext) throws IOException {Configuration configuration = ContextUtil.getConfiguration(jobContext);List<InputSplit> splits = new ArrayList();if (!isTaskSideMetaData(configuration)) { // configuration.getBoolean("parquet.task.side.metadata", Boolean.TRUE); 默认返回为Truesplits.addAll(this.getSplits(configuration, this.getFooters(jobContext)));return splits;} else {Iterator i$ = super.getSplits(jobContext).iterator(); // 调用父类的 getSplits 返回的是List<InputSplit> 这里取的是List<InputSplit> 的迭代器while(i$.hasNext()) {InputSplit split = (InputSplit)i$.next();Preconditions.checkArgument(split instanceof FileSplit, "Cannot wrap non-FileSplit: " + split);splits.add(ParquetInputSplit.from((FileSplit)split));}return splits;}}复制
public class ParquetInputFormat<T> extends FileInputFormat<Void, T>复制
进入父类FileInputFormat查看(getSplits)
获取切片最小 minSize
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));复制
protected long getFormatMinSplitSize() {return 1;}复制
public static final String SPLIT_MINSIZE ="mapreduce.input.fileinputformat.split.minsize";public static long getMinSplitSize(JobContext job) {return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L);}复制
计算切片最大maxSize
long maxSize = getMaxSplitSize(job);复制
public static final String SPLIT_MAXSIZE ="mapreduce.input.fileinputformat.split.maxsize";public static long getMaxSplitSize(JobContext context) {return context.getConfiguration().getLong(SPLIT_MAXSIZE,Long.MAX_VALUE);}复制
找出该路径下的所有文件 listStatus(job)
循环获取该目录下的文件大小
判断文件是否可切 isSplitable(job, path)、
protected boolean isSplitable(JobContext context, Path filename) {return true; // 默认可切}复制
计算切片大小
long splitSize = computeSplitSize(blockSize, minSize, maxSize);复制
computeSplitSize方法
protected long computeSplitSize(long blockSize, long minSize,long maxSize) {return Math.max(minSize, Math.min(maxSize, blockSize));}复制
public List<InputSplit> getSplits(JobContext job) throws IOException {StopWatch sw = new StopWatch().start();// 计算最小值long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));// 计算最大值long maxSize = getMaxSplitSize(job);// generate splitsList<InputSplit> splits = new ArrayList<InputSplit>();// 获取所有的文件会过滤掉以.和_开头的文件List<FileStatus> files = listStatus(job);//循环该目录下的所有文件for (FileStatus file: files) {// 处理文件信息Path path = file.getPath();long length = file.getLen();if (length != 0) {BlockLocation[] blkLocations;if (file instanceof LocatedFileStatus) {blkLocations = ((LocatedFileStatus) file).getBlockLocations();} else {FileSystem fs = path.getFileSystem(job.getConfiguration());blkLocations = fs.getFileBlockLocations(file, 0, length);}// 判断文件是否可切 默认值 返回Trueif (isSplitable(job, path)) {long blockSize = file.getBlockSize();// 计算切片大小 Math.max(minSize, Math.min(maxSize, blockSize));long splitSize = computeSplitSize(blockSize, minSize, maxSize);long bytesRemaining = length;// private static final double SPLIT_SLOP = 1.1; // 10% slop// 当文件大小/ splitSize >1.1时对改文件进行循环切片while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);splits.add(makeSplit(path, length-bytesRemaining, splitSize,blkLocations[blkIndex].getHosts(),blkLocations[blkIndex].getCachedHosts()));bytesRemaining -= splitSize;}// 剩下的都是一块if (bytesRemaining != 0) {int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,blkLocations[blkIndex].getHosts(),blkLocations[blkIndex].getCachedHosts()));}} else { // not splitablesplits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),blkLocations[0].getCachedHosts()));}} else { //不可切d额时候直接整个加入//Create empty hosts array for zero length filessplits.add(makeSplit(path, 0, length, new String[0]));}}// Save the number of input files for metrics/loadgenjob.getConfiguration().setLong(NUM_INPUT_FILES, files.size()); // 设置输入的文件个数//public static final String NUM_INPUT_FILES = "mapreduce.input.fileinputformat.numinputfiles";sw.stop();if (LOG.isDebugEnabled()) {LOG.debug("Total # of splits generated by getSplits: " + splits.size()+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));}return splits; // 返回所有的切片信息}复制
核心代码
计算最小值
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));//由参数mapreduce.input.fileinputformat.split.minsize控制复制
计算最大值
long maxSize = getMaxSplitSize(job);//由参数mapreduce.input.fileinputformat.split.maxsize 控制复制
计算splitSize
Math.max(minSize, Math.min(maxSize, blockSize));复制
HDFS集群默认块大小 blockSize(这里是256M)
结论
增大Map阶段的分区数
set mapreduce.input.fileinputformat.split.maxsize=128000000;复制
减少Map计算的分区数
set mapreduce.input.fileinputformat.split.maxsize=512000000复制
测试
测试SQL:
set hive.support.quoted.identifiers=None;set spark.app.name="ods.log_info"insert overwrite table ods.log_info_temp partition(d_date= '2021-02-21',pid)select `(is_settled)?+.+`from ods.log_infowhere 1 > 0复制
结果如下:
set mapreduce.input.fileinputformat.split.maxsize=128000000;task个数为65复制
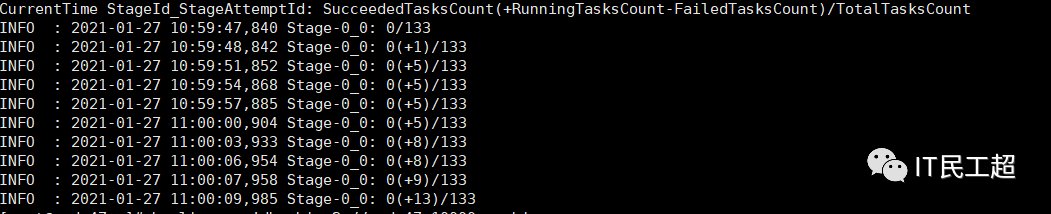
set mapreduce.input.fileinputformat.split.maxsize=256000000;task个数为65复制

set mapreduce.input.fileinputformat.split.maxsize=512000000;task个数为34复制


扫描二维码获取
更多精彩
IT民工超

点个在看你最好看
文章转载自趣说大数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025年4月中国数据库流行度排行榜:OB高分复登顶,崖山稳驭撼十强
墨天轮编辑部
1963次阅读
2025-04-09 15:33:27
2025年3月国产数据库大事记
墨天轮编辑部
893次阅读
2025-04-03 15:21:16
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
615次阅读
2025-04-10 15:35:48
征文大赛 |「码」上数据库—— KWDB 2025 创作者计划启动
KaiwuDB
506次阅读
2025-04-01 20:42:12
数据库,没有关税却有壁垒
多明戈教你玩狼人杀
496次阅读
2025-04-11 09:38:42
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
476次阅读
2025-04-14 09:40:20
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
431次阅读
2025-04-27 16:53:22
最近我为什么不写评论国产数据库的文章了
白鳝的洞穴
422次阅读
2025-04-07 09:44:54
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
374次阅读
2025-04-17 17:02:24
天津市政府数据库框采结果公布,7家数据库产品入选!
通讯员
368次阅读
2025-04-10 12:32:35
