




cluster.MeanShift是一种基于核密度估计,通过不断移动样本点到其局部密度最大点来发现数据簇的无监督学习聚类算法。
cluster.MiniBatchKMeans是 K-Means 算法的变体,利用小批量数据来更新聚类中心,以减少计算量并提高聚类速度。
cluster.AgglomerativeClustering是一种层次聚类算法,它从每个数据点作为一个单独的类开始,逐步合并相似的类以形成聚类层次结构。
cluster.SpectralClustering基于给定数据点的相似性矩阵构建图,利用图的谱性质,如拉普拉斯矩阵的特征值和特征向量来进行聚类。
cluster.DBSCAN是一种基于密度的空间聚类算法,能够发现任意形状的簇,将密度相连的数据点划分为一个聚类,并识别出噪声点。
cluster.HDBSCAN是 DBSCAN 的扩展,它通过基于层次密度的方法,能够更有效地处理密度变化较大的数据,并能发现不同密度下的聚类结构。
cluster.OPTICS也是一种基于密度的聚类算法,它为数据点生成一个排序,表示数据点的密度可达性,从而可以根据不同的密度阈值提取出不同的聚类结果。
cluster.AffinityPropagation通过数据点之间传递消息,根据数据点之间的相似度来寻找聚类中心,并将数据点分配到相应的聚类中。
cluster.Birch是一种基于树结构的聚类算法,它通过构建聚类特征树来对数据进行聚类,能够处理大规模数据并具有较好的可扩展性。
mixture.GaussianMixture是一种基于概率模型的聚类方法,假设数据是由多个高斯分布混合而成,通过估计每个高斯分布的参数来确定聚类。
# 导入库import pandas as pd # panda库import matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScaler # 标准化库from sklearn.cluster import KMeans # 导入sklearn聚类模块from sklearn.metrics import silhouette_score # 效果评估模块from sklearn.decomposition import PCAimport matplotlibfrom sklearn import cluster, datasets, mixturefrom sklearn.neighbors import kneighbors_graphimport timeimport warningsimport numpy as npfrom itertools import cycle, islice# 替换为你的文件路径data_path = r'E:\JetBrains\PythonProject\DeepLearning\provicedata.csv'df = pd.read_csv(data_path)# 选择特征列features = ['GDP', 'Primary industry', 'Primary industry','Primary industry','resident population','population growth rate','import and export','export value','import value','General budget revenue','General budget expenditure','Per capita disposable income','Per capita consumption expenditure','area'] # 替换为你的特征列名X = df[features]n_samples, n_features = X.shapeprint('样本数:%d , 特征数:%d' % (n_samples, n_features))# sklearn.cluster.KMeans(n_clusters=K)# 1. n_cluster:聚类个数(即K),默认值是8。# 2. init:初始化类中心的方法(即选择初始中心点的根据),默认“K-means++”,其他可选参数包括“random”。# 3. n_init:使用不同类中心运行的次数,默认值是10,即算法会初始化10次簇中心,然后返回最好的一次聚类结果。# 4. max_iter:单次运行KMeans算法的最大迭代次数,默认值是300。# 5. tol:浮点型,两次迭代之间簇内平方和下降的容忍阈值,默认为0.0001,如果两次迭代之间下降的值小于tol所设定的值,迭代就会停下。# 6. verbose:是否输出详细信息,参数类型为整型,默认值为0,1表示每隔一段时间打印一次日志信息。# 7. random_state:控制每次类中心随机初始化的随机种子,作用相当于能够锁定和复现同一次随机结果,默认为none,也可以随机设置数字。# 8. copy_x:在预先计算距离时,首先将数据居中在数值上更准确。如果 copy_x 为 True(默认),则不修改原始数据。# 如果为 False,则修改原始数据,并在函数返回之前放回,但通过减去再添加数据均值可能会引入小的数值差异。# 请注意,如果原始数据不是C-contiguous,即使copy_x 为False,也会进行复制。如果原始数据是稀疏的,但不是 CSR 格式,即使 copy_x 为 False,也会进行复制。# 9. algorithm:有三种参数可选:auto”, “full”, “elkan”,默认为auto。K-means 算法使用。# 经典的EM-style算法是“full”。通过使用三角不等式,“elkan” 变体对具有明确定义的集群的数据更有效。# 然而,由于分配了一个额外的形状数组(n_samples,n_clusters),它更加占用内存。# 数据归一化scaler = StandardScaler()scalerX = scaler.fit_transform(X)for i in range(2,5):# 1.components_ :特征空间中的主轴,表示数据中最大方差的方向。组件按排序 explained_variance_# 2.explained_variance_:它代表降维后的各主成分的方差值。方差值越大,则说明越是重要的主成分# 3.explained_variance_ratio_:它代表降维后的各主成分的方差值占总方差值的比例,这个比例越大,则越是重要的主成分# 4.singular_values_:每个特征的奇异值,奇异值等于n_components 低维空间中变量的2范数# 5.mean_:每个特征的均值# 6.n_components_:即是上面输入的参数值# 7.n_features_:训练数据中的特征数量# 8.n_samples_:训练数据中的样本数# 9.noise_variance_:等于X协方差矩阵的(min(n_features,n_samples)-n_components)个最小特征值的平均值pca = PCA(n_components=i)pcaX = pca.fit_transform(scalerX)print("For n_components={}, The PCA explained_variance_ratio_ is {}".format(i, pca.explained_variance_ratio_))# For n_components=2, The PCA explained_variance_ratio_ is [0.54113074 0.30908829]# For n_components=3, The PCA explained_variance_ratio_ is [0.54113074 0.30908829 0.06978044]# For n_components=4, The PCA explained_variance_ratio_ is [0.54113074 0.30908829 0.06978044 0.04070103]pca = PCA(n_components=2)pcaX = pca.fit_transform(scalerX)
这部分代码主要是各类聚类算法之前的参数定义工作。
# 导入库default_base = {"quantile": 0.3,"eps": 0.3,"damping": 0.9,"preference": -200,"n_neighbors": 3,"n_clusters": 3,"min_samples": 7,"xi": 0.05,"min_cluster_size": 0.1,"allow_single_cluster": True,"hdbscan_min_cluster_size": 15,"hdbscan_min_samples": 3,"random_state": 42,}params = default_base.copy()# estimate bandwidth for mean shiftbandwidth = cluster.estimate_bandwidth(pcaX, quantile=params["quantile"])# connectivity matrix for structured Wardconnectivity = kneighbors_graph(pcaX, n_neighbors=params["n_neighbors"], include_self=False)# make connectivity symmetricconnectivity = 0.5 * (connectivity + connectivity.T)# cluster.MeanShift是一种基于核密度估计,通过不断移动样本点到其局部密度最大点来发现数据簇的无监督学习聚类算法。# cluster.MiniBatchKMeans是 K-Means 算法的变体,利用小批量数据来更新聚类中心,以减少计算量并提高聚类速度。# cluster.AgglomerativeClustering是一种层次聚类算法,它从每个数据点作为一个单独的类开始,逐步合并相似的类以形成聚类层次结构。# cluster.SpectralClustering基于给定数据点的相似性矩阵构建图,利用图的谱性质,如拉普拉斯矩阵的特征值和特征向量来进行聚类。# cluster.DBSCAN是一种基于密度的空间聚类算法,能够发现任意形状的簇,将密度相连的数据点划分为一个聚类,并识别出噪声点。# cluster.HDBSCAN是 DBSCAN 的扩展,它通过基于层次密度的方法,能够更有效地处理密度变化较大的数据,并能发现不同密度下的聚类结构。# cluster.OPTICS也是一种基于密度的聚类算法,它为数据点生成一个排序,表示数据点的密度可达性,从而可以根据不同的密度阈值提取出不同的聚类结果。# cluster.AffinityPropagation通过数据点之间传递消息,根据数据点之间的相似度来寻找聚类中心,并将数据点分配到相应的聚类中。# cluster.Birch是一种基于树结构的聚类算法,它通过构建聚类特征树来对数据进行聚类,能够处理大规模数据并具有较好的可扩展性。# mixture.GaussianMixture是一种基于概率模型的聚类方法,假设数据是由多个高斯分布混合而成,通过估计每个高斯分布的参数来确定聚类。ms = cluster.MeanShift(bandwidth=bandwidth, bin_seeding=True)two_means = cluster.MiniBatchKMeans(n_clusters=params["n_clusters"],random_state=params["random_state"],)ward = cluster.AgglomerativeClustering(n_clusters=params["n_clusters"], linkage="ward", connectivity=connectivity)spectral = cluster.SpectralClustering(n_clusters=params["n_clusters"],eigen_solver="arpack",affinity="nearest_neighbors",random_state=params["random_state"],)dbscan = cluster.DBSCAN(eps=params["eps"])hdbscan = cluster.HDBSCAN(min_samples=params["hdbscan_min_samples"],min_cluster_size=params["hdbscan_min_cluster_size"],allow_single_cluster=params["allow_single_cluster"],)optics = cluster.OPTICS(min_samples=params["min_samples"],xi=params["xi"],min_cluster_size=params["min_cluster_size"],)affinity_propagation = cluster.AffinityPropagation(damping=params["damping"],preference=params["preference"],random_state=params["random_state"],)average_linkage = cluster.AgglomerativeClustering(linkage="average",metric="cityblock",n_clusters=params["n_clusters"],connectivity=connectivity,)birch = cluster.Birch(n_clusters=params["n_clusters"])gmm = mixture.GaussianMixture(n_components=params["n_clusters"],covariance_type="full",random_state=params["random_state"],)clustering_algorithms = (("MiniBatch\nKMeans", two_means),("Affinity\nPropagation", affinity_propagation),("MeanShift", ms),("Spectral\nClustering", spectral),("Ward", ward),("Agglomerative\nClustering", average_linkage),("DBSCAN", dbscan),("HDBSCAN", hdbscan),("OPTICS", optics),("BIRCH", birch),("Gaussian\nMixture", gmm),)
第三部分代码,根据聚类算法字典开始迭代,按照统计各类算法的整体时长、开展预测、将预测结果pandas数据列、可视化聚类结果等步骤执行。
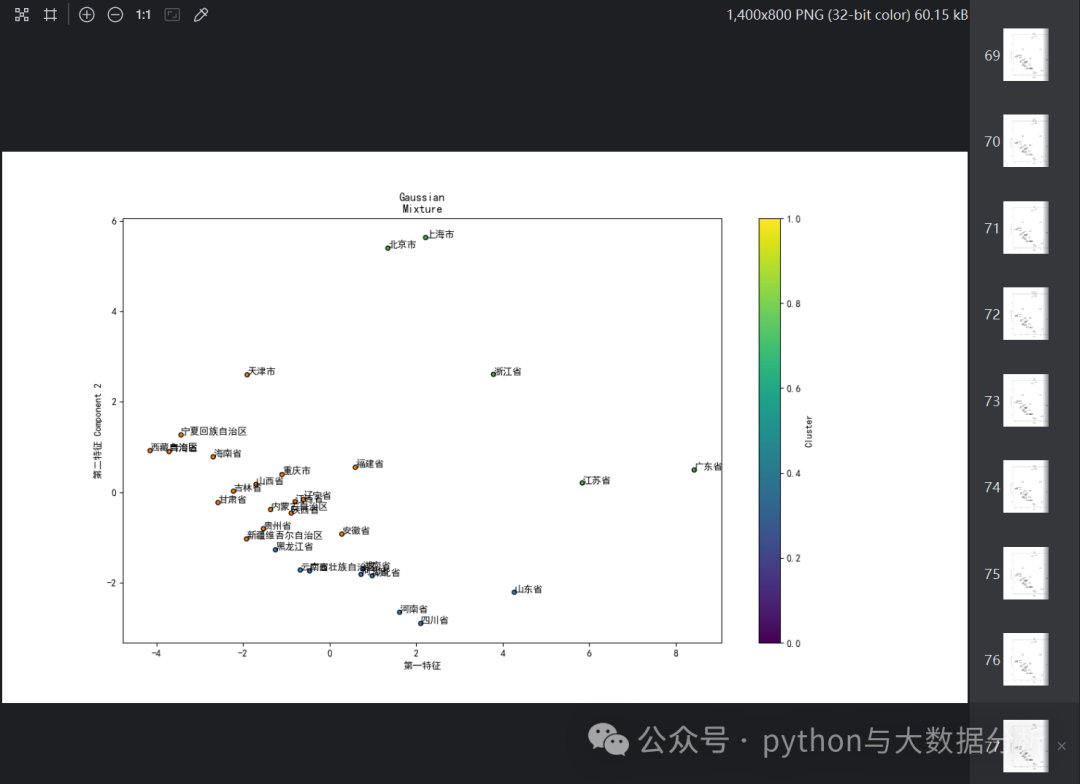
# 设置matplotlib正常显示中文和负号matplotlib.rcParams['font.family'] = 'SimHei' # 设置字体为黑体matplotlib.rcParams['axes.unicode_minus'] = False # 正确显示负号for name, algorithm in clustering_algorithms:t0 = time.time()# catch warnings related to kneighbors_graphwith warnings.catch_warnings():warnings.filterwarnings("ignore",message="the number of connected components of the "+ "connectivity matrix is [0-9]{1,2}"+ " > 1. Completing it to avoid stopping the tree early.",category=UserWarning,)warnings.filterwarnings("ignore",message="Graph is not fully connected, spectral embedding"+ " may not work as expected.",category=UserWarning,)algorithm.fit(pcaX)t1 = time.time()if hasattr(algorithm, "labels_"):y_pred = algorithm.labels_.astype(int)else:y_pred = algorithm.predict(pcaX)# 合并数据和特征kmeans_labels = pd.DataFrame(y_pred, columns=[name])df = df.join(kmeans_labels)colors = np.array(list(islice(cycle(["#377eb8","#ff7f00","#4daf4a","#f781bf","#a65628","#984ea3","#999999","#e41a1c","#dede00",]),int(max(y_pred) + 1),)))# add black color for outliers (if any)colors = np.append(colors, ["#000000"])plt.figure(figsize=(14, 8))plt.scatter(pcaX[:, 0], pcaX[:, 1], s=20, color=colors[y_pred] , marker='o', edgecolor='k',)for i, txt in enumerate(df['city']):plt.text(pcaX[:, 0][i], pcaX[:, 1][i], txt)plt.xlabel('第一特征')plt.ylabel('第二特征 Component 2')plt.colorbar(label='Cluster') # 显示颜色条表示不同的聚类中心plt.show()df.to_csv('provicedatav5.csv', index=False, header=True, encoding='utf-8')
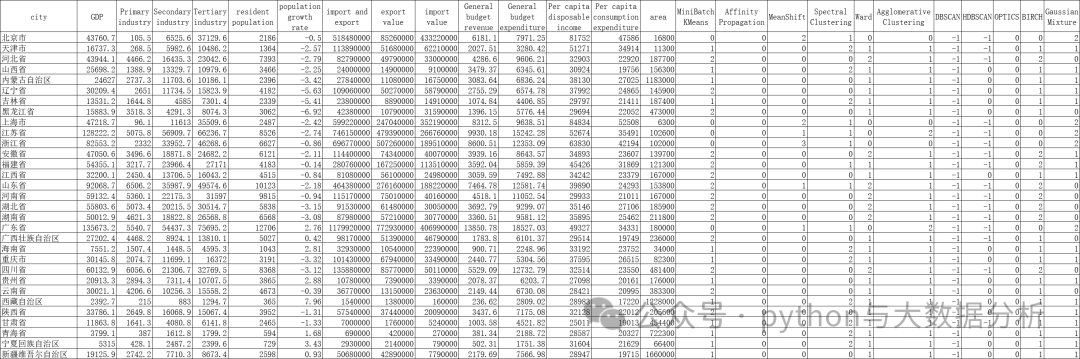
接下来是生成的结果文件情况,大家可以看到多出十一列,即各算法的预测结果,当然并不是每个预测结果都有实际意义。

文章转载自追梦IT人,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
