




最近几周,随着 DeepSeek 及其系列开放权重大模型(例如 V3 、R1-distill 系列等)的发布,国内外的人工智能技术正迎来一场前所未有的变局。DeepSeek 的模型不仅在性能上可媲美 GPT-4o 和 OpenAI 的 o1 模型,而且采用了宽松的 MIT 开源许可,使得模型权重完全开放,便于大家深入研究与二次开发。悦数 Gen AI 团队在公开透明的科研实践中,也正是借助这一波开源浪潮,实现了技术的跨越式进步,进而推动了我们的产品悦数 Graph RAG AI 开发平台的落地与商业化应用。
DeepSeek 开放权重模型的优势
开放与透明
DeepSeek 的 R1、R1-distill 等模型均采用宽松许可发布,用户可自由下载、使用、修改与再分发,极大地促进了科研合作与技术分享。
性能卓越
目前,DeepSeek 的 V3 模型和 R1 模型在数学、代码、逻辑推理等任务上达到了与 GPT-4o、OpenAI o1 相当的水平,而 R1 模型更以其强大的链式推理(chain-of-thought)能力脱颖而出,能在生成阶段准确捕捉关键信息,实现“针尖对麦芒”的精准输出。
成本优势
DeepSeek V3 的训练成本是百万美元级别,与对标的巨头团队的工作相比成本有数量级的优势,而且,DeepSeek 的 2C 托管服务免费向所有终端用户开放,成为首个“超级智能”且具备网络搜索能力的模型,迅速走红。
悦数 Graph RAG AI 开发平台
如何借力 DeepSeek 模型与公开技术
在传统大语言模型(LLM)或 o1 类模型的基础上,单靠海量文本训练固然能解决一般性语言生成任务,但在需要集成成千上万领域知识、解读海量文档并进行深度推理的场景下,往往力不从心。悦数 Graph RAG AI 开发平台正是基于这样的痛点应运而生。
整合海量领域知识
悦数 Graph RAG AI 开发平台能够将数千份领域文档、章节、图片、表格等多样化数据构建成多频谱的图状结构蒸馏“知识图谱”,并通过图算法实现深度关联、检索和推理。借助 DeepSeek 的 R1 模型,我们得以在公开透明的科研环境下,对这一复杂流程进行反复优化。
降低技术门槛,普惠自服务应用
悦数 Graph RAG AI 开发平台平台致力于将复杂的知识整合与推理工作封装成用户友好的应用,无论是技术专家还是普通用户,都能轻松上传、整合自有知识,并借助内置的 meta agent 进行智能决策,而无需编写繁琐的流程脚本或提示语。
开放式科研,成果共享
我们坚持公开透明的研究理念,将悦数 Graph RAG AI 开发平台的研发过程、模型微调、实验结果等全部开源,与业界同行共享我们的探索成果,推动整个 AI 生态的繁荣与进步。

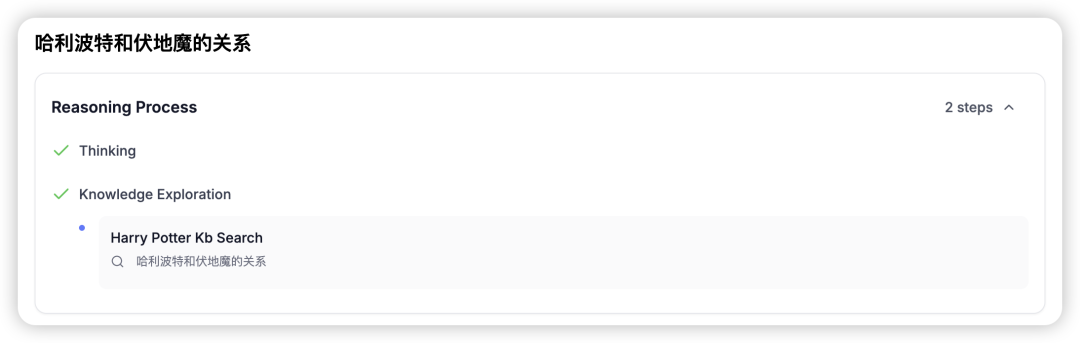
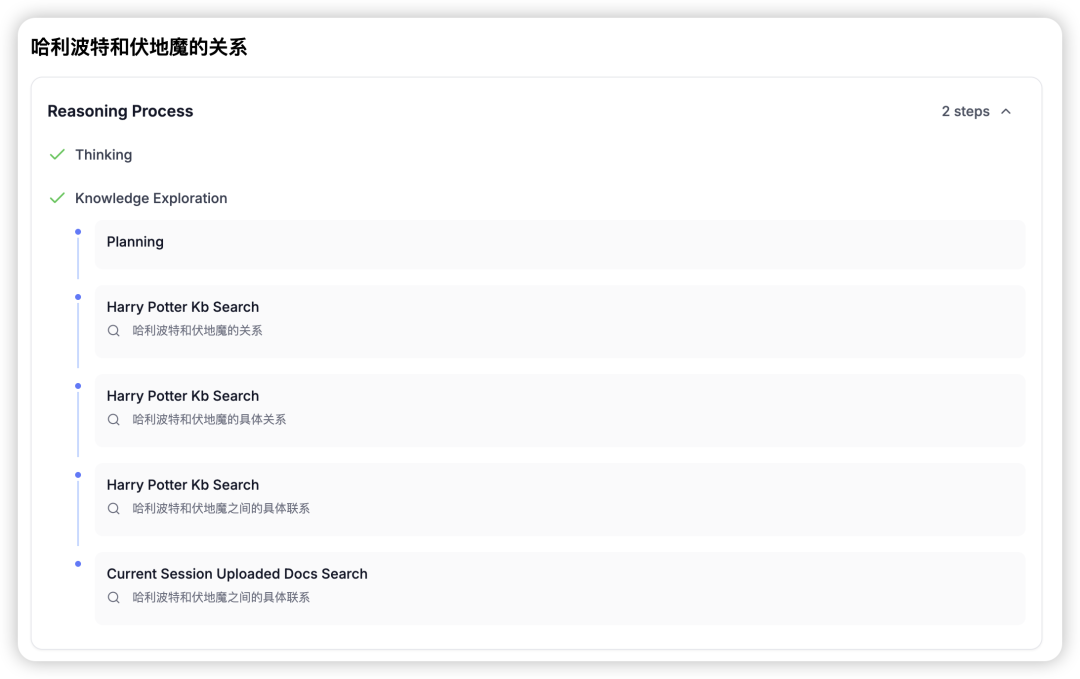
悦数 Graph RAG AI 开发平台图探索界面
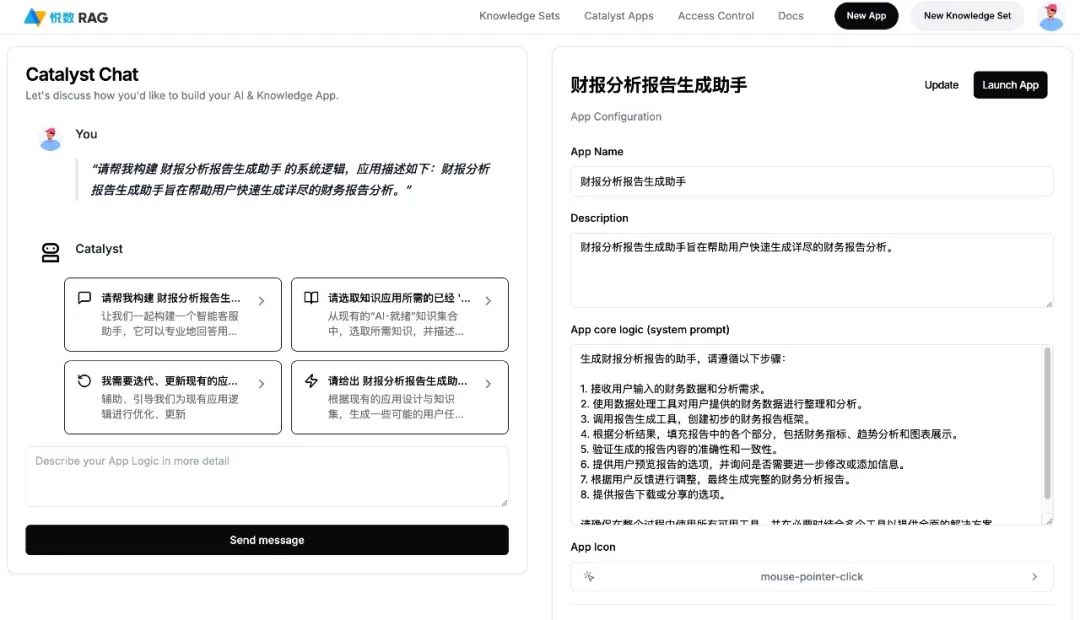
悦数 Graph RAG AI 开发平台
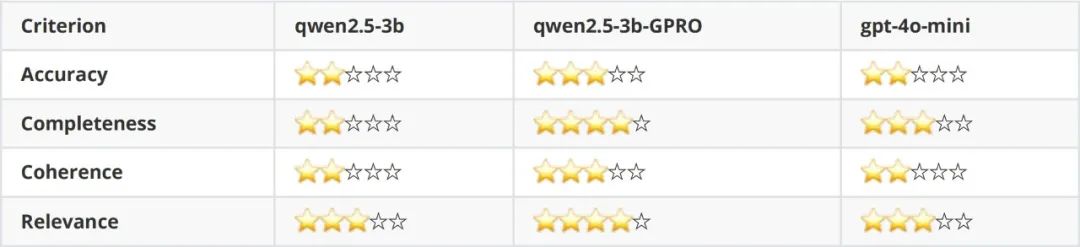
典型应用场景
结语
通过借助 DeepSeek 的开放权重模型,我们在悦数 Graph RAG AI 开发平台的研发中获得了前所未有的技术优势。无论是在增强推理、生成精准回答,还是在降低系统构建门槛方面,R1 模型都为我们带来了革命性的突破。我们将继续坚持公开透明的科研模式,与全球同行共享我们的探索成果,共同推动 AI 生态的繁荣与进步。
欢迎大家关注并试用我们的悦数 Graph RAG AI 开发平台产品,点击阅读原文即可申请试用和在线演示,也期待在评论区听到你们的宝贵意见与建议!
联系我们丨杭州悦数科技有限公司
咨询邮箱:contact@yueshu.com.cn
咨询热线:(+86)0571-58009980
(工作日 09:30-18:30)
< PAST · 相关阅读 >



点击「阅读原文」,联系我们




