




导读: 湖仓一体是将数据湖和数据仓库的优势相结合的数据管理系统。Apache Doris 结合自身特性,提出了【数据无界】和【湖仓无界】核心理念。上篇文章已介绍了 Apache Doris 湖仓一体完整方案,本文将聚焦典型应用场景,进一步深入,帮助读者更好地理解和应用 Apache Doris 湖仓一体。
在数据驱动决策的时代,湖仓一体架构以统一存储、统一计算、统一管理的创新形式,补齐了传统数据仓库和数据湖的短板,逐步成为企业大数据解决方案新的标准。
在上一篇文章中,全面介绍了湖仓一体演进历程以及 Apache Doris 湖仓一体解决方案,具体查阅:(上篇)从 0 到 1 构建湖仓体系, Apache Doris 湖仓一体解决方案全面解读。本文将进一步深入,聚焦于 湖仓分析加速、多源联邦分析、湖仓数据处理 这三个典型场景,分享 Apache Doris 湖仓一体方案的最佳实践。
通过这三个场景的实践,展示 Apache Doris 如何帮助企业快速响应业务需求,提升数据处理和分析的效率。同时,我们也将结合实际场景,提供详细的使用指南,帮助读者更好地理解和应用 Apache Doris 的湖仓一体方案。
湖仓分析加速场景
在该场景中,以 Apache Doris 作为计算引擎,对湖仓中数据进行查询分析加速。
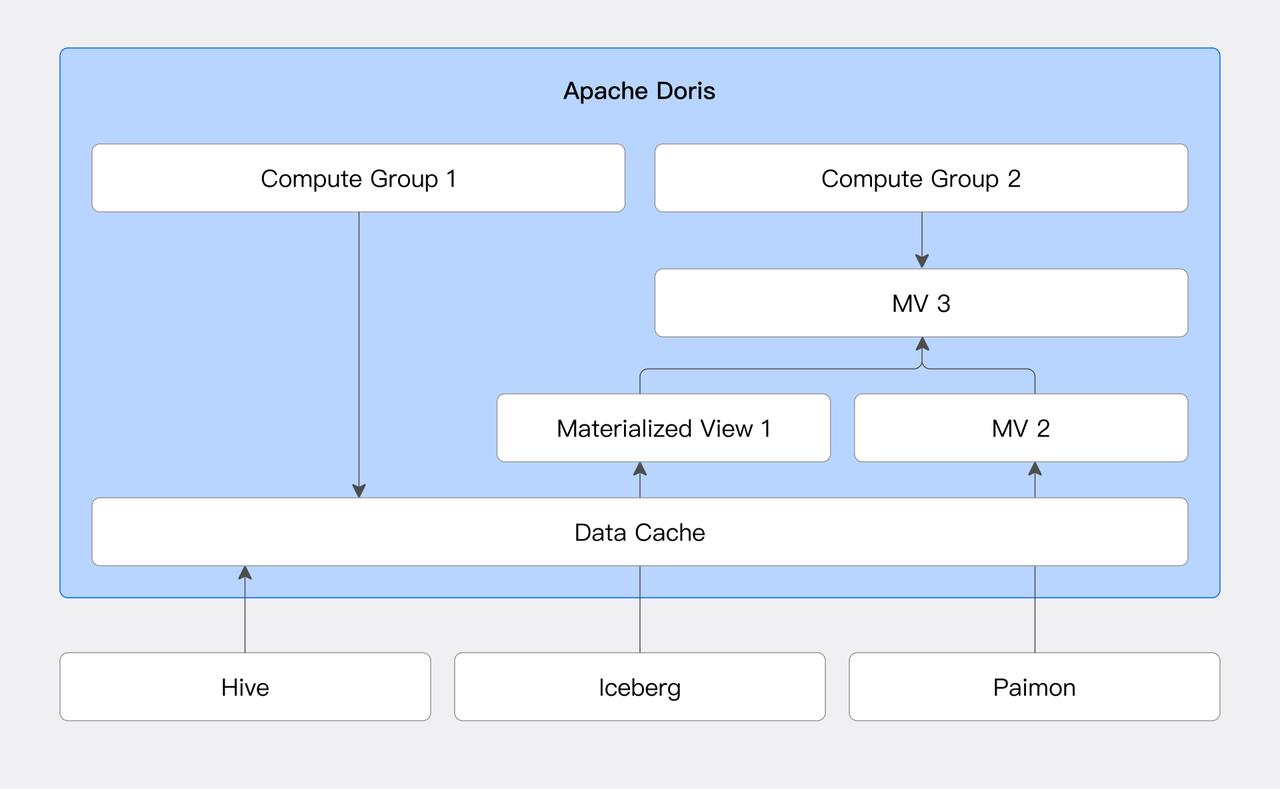
01 缓存加速
针对 Hive、Iceberg 等湖仓系统,用户可以配置本地磁盘缓存。本地磁盘缓存会自动将查询涉及的数据文件存储在本地缓存目录中,并使用 LRU 策略管理缓存的汰换。
1)在 BE 节点的配置文件 be.conf 中配置缓存目录,并重启 BE:
enable_file_cache=true; file_cache_path=[{"path": "/path/to/file_cache", "total_size":53687091200,"query_limit": 10737418240}]
2)开启缓存功能并查询数据:
SET enable_file_cache=true;
SELECT * FROM hive.tpcds1000.store_sales WHERE ss_sold_date_sk=2451676;
3)如命中缓存,则在查询的 Profile 中可以看到相应的指标:
- FileCache: 0ns - BytesScannedFromCache: 2.02 GB - BytesScannedFromRemote: 0.00 - BytesWriteIntoCache: 0.00 - LocalIOUseTimer: 2s723ms - NumLocalIOTotal: 444 - NumRemoteIOTotal: 0 - NumSkipCacheIOTotal: 0 - RemoteIOUseTimer: 0ns - WriteCacheIOUseTimer: 0ns
推荐使用 SSD 等高速存储介质作为缓存存储,以获得更好的热数据查询性能。
02 物化视图与透明改写
Doris 支持对外部数据源创建物化视图。物化视图根据 SQL 定义语句,预先将计算结果存储为 Doris 内表格式。同时,Doris 的查询优化器支持基于 SPJG(SELECT-PROJECT-JOIN-GROUP-BY)模式的透明改写算法。该算法能够分析 SQL 的结构信息,自动寻找合适的物化视图进行透明改写,并选择最优的物化视图来响应查询 SQL。
该功能通过减少运行时的计算量,可显著提升查询性能。同时可以在业务无感知的情况下,通过透明改写访问到物化视图中的数据。
如下,以 Hive 示例说明:
1)基于 Hive 创建 Catalog,使用 TPC-H 数据集
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.0.0.1:9083'
);
2)基于 Hive Catalog 创建物化视图
-- 物化视图只能在 internal 的 catalog 上创建, 切换到内部 catalog
switch internal;
create database hive_mv_db;
use hive_mv_db;
CREATE MATERIALIZED VIEW external_hive_mv
BUILD IMMEDIATE REFRESH AUTO ON MANUAL
DISTRIBUTED BY RANDOM BUCKETS 12
PROPERTIES ('replication_num' = '1')
AS
SELECT
n_name,
o_orderdate,
sum(l_extendedprice * (1 - l_discount)) AS revenue
FROM
hive.tpch1000.customer,
hive.tpch1000.orders,
hive.tpch1000.lineitem,
hive.tpch1000.supplier,
hive.tpch1000.nation,
hive.tpch1000.region
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
GROUP BY
n_name,
o_orderdate;
3)运行如下的查询,通过透明改写自动使用物化视图加速查询。
USE hive.tpch1000;
SELECT
n_name,
sum(l_extendedprice * (1 - l_discount)) AS revenue
FROM
customer,
orders,
lineitem,
supplier,
nation,
region
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
AND o_orderdate >= DATE '1994-01-01'
AND o_orderdate < DATE '1994-01-01' + INTERVAL '1' YEAR
GROUP BY
n_name
ORDER BY
revenue DESC;
使用注意:Doris 暂无法感知除 Hive 外的其他外表数据变更。当外表数据不一致时,使用物化视图可能出现数据不一致的情况。以下开关表示:参与透明改写的物化视图是否允许包含外表,默认false。如接受数据不一致或者通过定时刷新来保证外表数据一致性,可以将此开关设置成true。
-- 设置包含外表的物化视图是否可用于透明改写,默认不允许,如果可以接受数据不一致或者可以自行保证数据一致,
-- 可以开启
SET materialized_view_rewrite_enable_contain_external_table = true;
下表为命中物化视图前后的性能差异,使用透明改写之后,查询速度较之前提升约 93 倍。

多源联邦分析场景
Apache Doris 可以作为统一 SQL 查询引擎,连接不同数据源进行联邦分析,解决数据孤岛,挖掘数据价值。
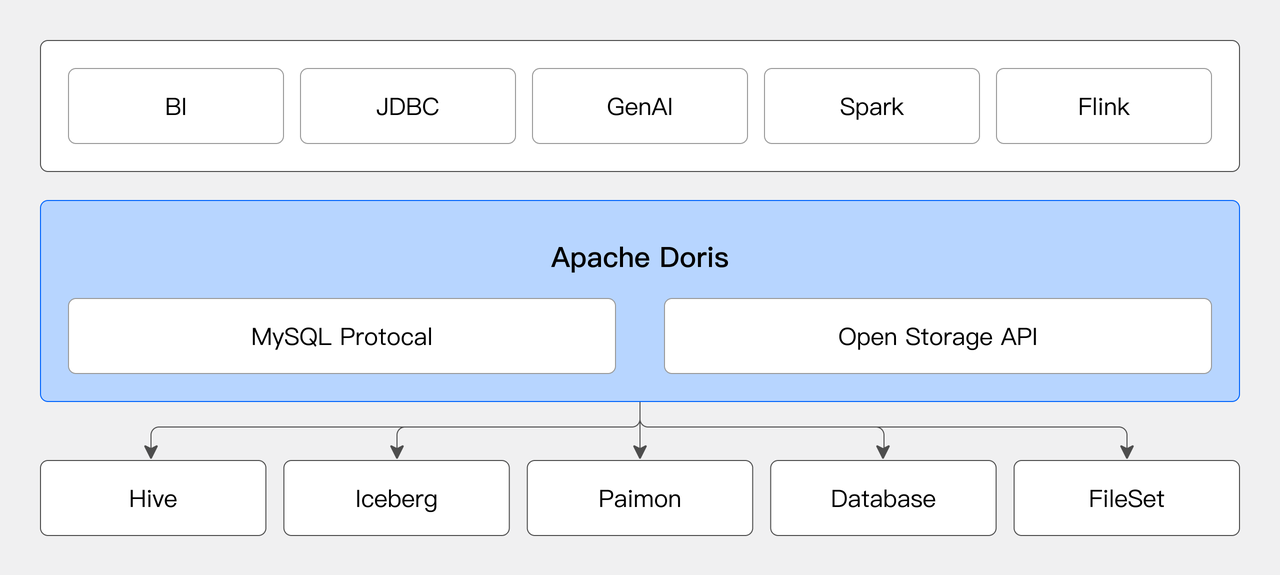
01 灵活连接数据源
用户可以在 Doris 中动态创建多个 Catalog 连接不同的数据源:
-- 创建 Hive Catalog
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.0.0.1:9083'
);
-- 创建 Iceberg Catalog
CREATE CATALOG iceberg PROPERTIES (
'type'='iceberg',
'iceberg.catalog.type' = 'hadoop',
'warehouse' = 'hdfs://hdfs_host:8020/user/iceberg/'
);
-- 创建 MySQL Catalog
CREATE CATALOG mysql PROPERTIES (
"type"="jdbc",
"user"="root",
"password"="pwd",
"jdbc_url" = "jdbc:mysql://example.net:3306",
"driver_url" = "mysql-connector-j-8.3.0.jar",
"driver_class" = "com.mysql.cj.jdbc.Driver"
)
切换到不同 Catalog 查看库表结构:
-- 切换到 Hive Catalog
SWITCH hive;
-- 查看数据库
show databases;
+-----------+
| Database |
+-----------+
| tpch1000 |
| tpcds1000 |
+-----------+
-- 查看表结构
DESC tpch1000_oss.lineitem;
+-----------------+--------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+--------+------+------+---------+-------+
| l_orderkey | bigint | Yes | true | NULL | |
| l_partkey | bigint | Yes | true | NULL | |
| l_suppkey | bigint | Yes | true | NULL | |
| l_linenumber | int | Yes | true | NULL | |
| l_quantity | double | Yes | true | NULL | |
| l_extendedprice | double | Yes | true | NULL | |
| l_discount | double | Yes | true | NULL | |
| l_tax | double | Yes | true | NULL | |
| l_returnflag | text | Yes | true | NULL | |
| l_linestatus | text | Yes | true | NULL | |
| l_shipdate | date | Yes | true | NULL | |
| l_commitdate | date | Yes | true | NULL | |
| l_receiptdate | date | Yes | true | NULL | |
| l_shipinstruct | text | Yes | true | NULL | |
| l_shipmode | text | Yes | true | NULL | |
| l_comment | text | Yes | true | NULL | |
+-----------------+--------+------+------+---------+-------+
02 多数据源关联查询
用户可以使用 SQL 语句对不同数据源中的数据进行任意关联查询:
SELECT
n_name,
SUM(l_extendedprice * (1 - l_discount)) AS revenue
FROM
hive.tpch1000.customer,
hive.tpch1000.orders,
iceberg.tpch1000.lineitem,
iceberg.tpch1000.supplier,
mysql.tpch1000.nation,
mysql.tpch1000.region
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
AND o_orderdate >= DATE '1994-01-01'
AND o_orderdate < DATE '1994-01-01' + INTERVAL '1' YEAR
GROUP BY
n_name
ORDER BY
revenue DESC;
湖仓数据处理场景
在该场景中,Apache Doris 作为数据处理引擎,对湖仓数据进行加工处理。
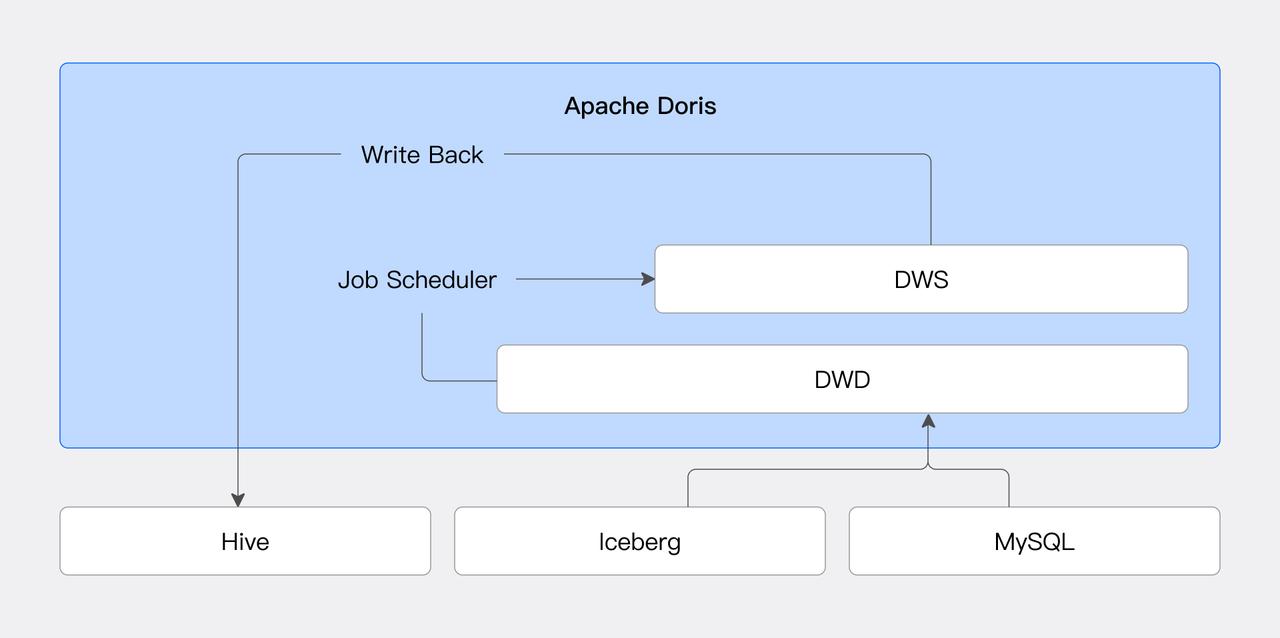
01 定时任务调度
在数据管理愈加精细化的需求背景下,定时调度在其中扮演着重要的角色。它通常被应用于以下场景:
- 定期数据更新,如周期性数据导入和 ETL 操作,减少人工干预,提高数据处理的效率和准确性。
- 结合 Catalog 实现外部数据源数据定期同步,确保多源数据高效、准确的整合到目标系统中,满足复杂的业务分析需求。
- 定期清理过期/无效数据,释放存储空间,避免过多过期/无效数据对系统性能产生影响。
Doris 通过引入 Job Scheduler 功能,可以实现高效灵活的任务调度,减少了对外部系统的依赖,也降低了系统故障的风险和运维成本。结合数据源连接器,用户可以实现外部数据的定期加工入库。
下面演示一个将 MySQL 数据定期同步到 Doris 中的基础示例。
1)首先,创建一张 Doris 表:
CREATE TABLE IF NOT EXISTS user_activity
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
2)创建 MySQL 数据源:
CREATE CATALOG activity PROPERTIES (
"type"="jdbc",
"user"="root",
"jdbc_url" = "jdbc:mysql://127.0.0.1:9734/user?useSSL=false",
"driver_url" = "mysql-connector-java-5.1.49.jar",
"driver_class" = "com.mysql.jdbc.Driver"
);
3)在2024-12-10 03:00:00 触发一次性全量导入:
CREATE JOB one_time_load_job
ON SCHEDULE
AT '2024-12-10 03:00:00'
DO
INSERT INTO user_activity FROM SELECT * FROM activity.user.activity;
4)每日同步增量数据:
CREATE JOB schedule_load
ON SCHEDULE EVERY 1 DAY
DO
INSERT INTO user_activity FROM SELECT * FROM activity.user.activity
WHERE create_time >= days_add(now(),-1);
02 数据分层加工
企业通常会使用数据湖存储原始数据,在此基础上进行数据分层加工,将不同层的数据开放给不同的业务需求方。Doris 的物化视图功能支持对外部数据源创建物化视图,并支持在基于物化视图再加工,降低了分层加工的系统复杂度,提升数据处理效率。
下面基于 Hive 表中的数据,通过 TPC-H 数据集说明物化视图在数据分层加工中的应用。
1)以分析每月各地区和国家的订单数量和利润为例,首先,创建 Hive 数据源:
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.0.0.1:9083'
);
2)构建 DWD 层(明细数据),处理订单明细宽表:
CREATE MATERIALIZED VIEW dwd_order_detail
BUILD IMMEDIATE REFRESH AUTO ON COMMIT
DISTRIBUTED BY RANDOM BUCKETS 16
PROPERTIES ('replication_num' = '1')
AS
select
o.o_orderkey,
o.o_custkey,
o.o_orderstatus,
o.o_totalprice,
o.o_orderdate,
c.c_name,
c.c_nationkey,
n.n_name as nation_name,
r.r_name as region_name,
l.l_partkey,
l.l_quantity,
l.l_extendedprice,
l.l_discount,
l.l_tax
from hive.tpch.orders o
join hive.tpch.customer c on o.o_custkey = c.c_custkey
join hive.tpch.nation n on c.c_nationkey = n.n_nationkey
join hive.tpch.region r on n.n_regionkey = r.r_regionkey
join hive.tpch.lineitem l on o.o_orderkey = l.l_orderkey;
3)基于 DWD 层的 dwd_order_detail,构建 DWS 层(汇总数据),进行每日订单汇总:
CREATE MATERIALIZED VIEW dws_daily_sales
BUILD IMMEDIATE REFRESH AUTO ON COMMIT
DISTRIBUTED BY RANDOM BUCKETS 16
PROPERTIES ('replication_num' = '1')
AS
select
date_trunc(o_orderdate, 'month') as month,
nation_name,
region_name,
bitmap_union(to_bitmap(o_orderkey)) as order_count,
sum(l_extendedprice * (1 - l_discount)) as net_revenue
from dwd_order_detail
group by
date_trunc(o_orderdate, 'month'),
nation_name,
region_name;
4)用户可以直接访问 DWS 层dws_daily_sales表中的汇总数据,进行快速数据分析:
SELECT
nation_name,
month,
bitmap_union_count(order_count),
sum(net_revenue) as revenue
FROM dws_daily_sales
GROUP BY nation_name, month;
03 数据写回
数据写回功能将 Doris 的湖仓数据处理能力形成闭环。在这之前,用户只能通过 Doris 进行湖仓数据的查询。如需要对湖仓数据进行写入等操作,则需要使用 Spark 等其他的计算引擎,这在一定程度上增加了架构的复杂性。
而数据写回功能的加入,使得用户可以直接通过 Doris 在外部数据源中创建数据库、表,并写入数据。当前支持 JDBC、Hive 和 Iceberg 三类数据源,后续会增加更多的数据源支持。下面通过一个简单的示例介绍数据写回功能。
1)首先,创建一个 Iceberg 数据源:
CREATE CATALOG iceberg PROPERTIES (
"type" = "iceberg",
"iceberg.catalog.type" = "hms",
"hive.metastore.uris" = "thrift://172.21.16.47:7004",
"warehouse" = "hdfs://172.21.16.47:4007/user/hive/warehouse/",
"fs.defaultFS" = "hdfs://172.21.16.47:4007"
);
2)在 Iceberg 创建库表:
SWITCH iceberg;
CREATE DATABASE ice_db;
CREATE TABLE ice_tbl (
`ts` DATETIME COMMENT 'ts',
`col1` INT COMMENT 'col2',
`col2` DECIMAL(9,4) COMMENT 'col6',
`col3` STRING COMMENT 'col7',
`pt1` STRING COMMENT 'pt1',
`pt2` STRING COMMENT 'pt2'
) ENGINE=iceberg
PARTITION BY LIST (DAY(ts), pt1, pt2) ()
PROPERTIES (
'write-format'='orc',
'compression-codec'='zlib'
);
3)将内表数据经过加工处理后,写入到 Iceberg 表:
INSERT INTO iceberg.ice_db.ice_tbl
SELECT * FROM
internal.db.fact_tbl f JOIN internal.db.dim_tbl d
ON f.id = d.id
AND f.dt > "2024-12-10";
结束语
以上就是对 Apache Doris 湖仓一体典型场景方案的介绍。从这两篇文章中可以看出,Apache Doris 凭借其多源异构数据的接入与整合能力、高性能的数据处理、现代化的部署架构、丰富的数据存储与管理能力以及开放性,完美诠释了“数据无界、湖仓无界”的理念,为企业提供了低成本、高弹性、强一致性的新一代数据基础。
我们欢迎您使用 Apache Doris,并期待您的反馈和建议!未来,Apache Doris 将继续发力,进一步完善和强化湖仓一体能力,持续赋能企业突破数据边界。
阅读推荐
