




副本虽然能够提高数据的可用性,降低丢失风险,但是每台服务器实际上必须容纳全量数据,对数据的横向扩容没有解决。
相关文章:高性价比OLAP列式数据库—Clickhouse(副本机制)
Distributed 表引擎本身不存储数据,有点类似于 MyCat 之于 MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
注意:ClickHouse 的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分片,避免降低查询性能以及操作集群的复杂性。
分片(Shard)
副本(Replica)
分布式表(Distributed Table)
分片机制的工作原理
数据写入流程
数据读取流程
故障恢复
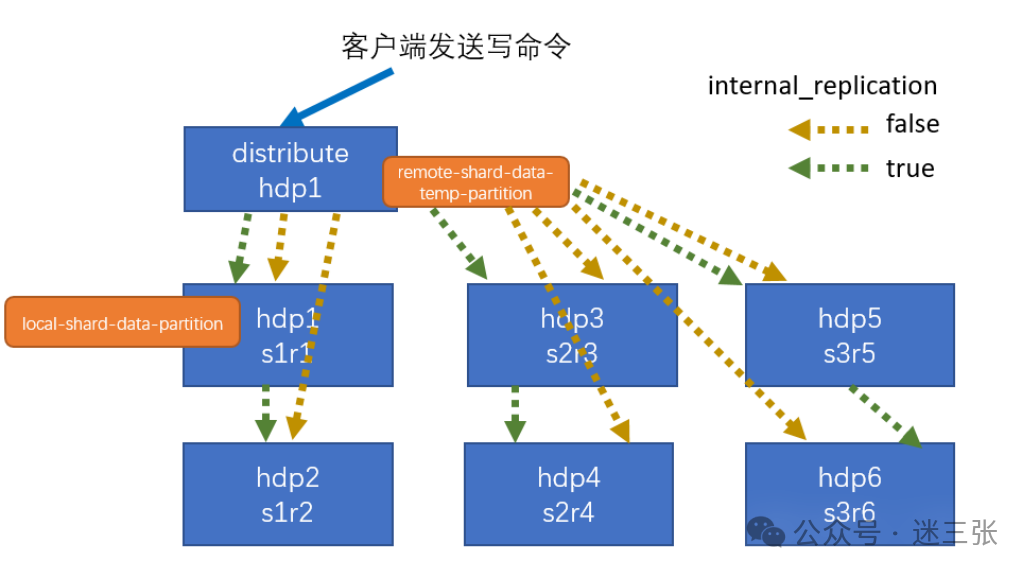
集群写入流程(3 分片 2 副本共 6 个节点)
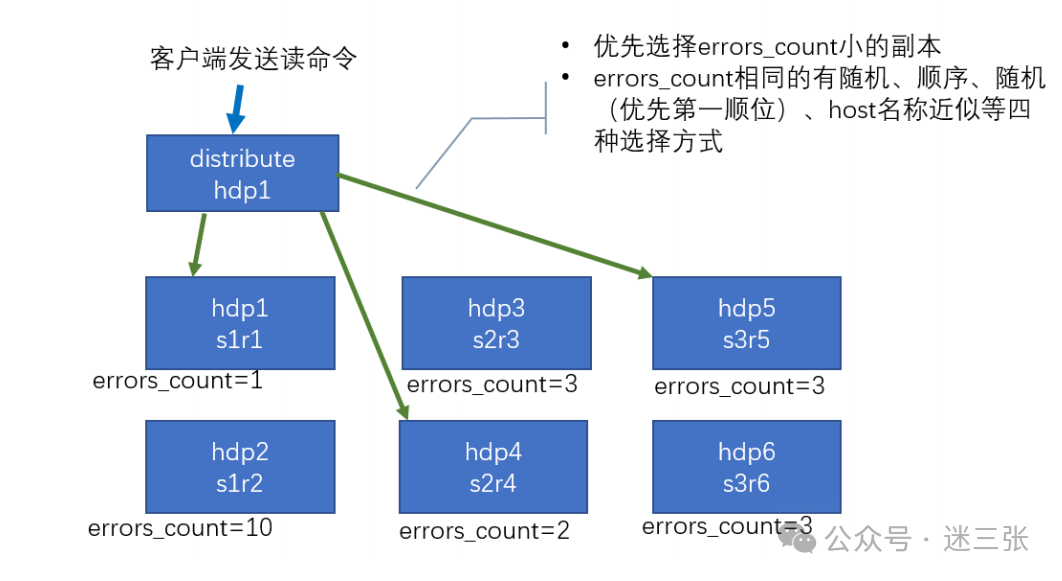
集群读取流程(3 分片 2 副本共 6 个节点)
配置分片机制
要启用 ClickHouse 的分片机制,需要在配置文件中定义分片和副本的拓扑结构,并创建分布式表。
1、创建本地表
每个分片上的数据存储在本地表中。以下是一个创建本地表的示例:
create table st_order_mt on cluster gmall_cluster (id UInt32,sku_id String,total_amount Decimal(16,2),create_time Datetime) engine=ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')partition by toYYYYMMDD(create_time)primary key (id)order by (id,sku_id);
2、创建分布式表
分布式表用于将查询路由到各个分片。以下是一个创建分布式表的示例:
create table st_order_mt_all2 on cluster gmall_cluster(id UInt32,sku_id String,total_amount Decimal(16,2),create_time Datetime)engine = Distributed(gmall_cluster,default, st_order_mt,hiveHash(sku_id));
参数说明:
my_cluster:集群名称,在配置文件中定义。
default:数据库名称。
st_order_mt:本地表名称。
rand():分片键,用于决定数据分配到哪个分片。
3、配置分片和副本
在 metrika.xml 文件中定义分片和副本的拓扑结构:
<yandex><remote_servers><my_cluster><shard><internal_replication>true</internal_replication><replica><host>node1</host><port>9000</port></replica><replica><host>node2</host><port>9000</port></replica></shard><shard><internal_replication>true</internal_replication><replica><host>node3</host><port>9000</port></replica><replica><host>node4</host><port>9000</port></replica></shard></my_cluster></remote_servers></yandex>
分片键的选择
分片键决定了数据如何分配到不同的分片。选择合适的分片键可以提高查询性能和数据分布的均匀性。常见分片键如下
rand()或
cityHash64(column))。
-- 使用哈希分片ENGINE = Distributed(my_cluster, default, my_table_local, cityHash64(id));-- 使用范围分片ENGINE = Distributed(my_cluster, default, my_table_local, toYYYYMM(timestamp));
监控分片状态
ClickHouse 提供了多种方式来监控分片的状态:
查看分片信息
可以通过 system.clusters 表查看分片的状态:
SELECT cluster, shard_num, replica_num, host_addressFROM system.clusters;
查看查询分布
可以通过 EXPLAIN
命令查看查询如何分发到各个分片:
EXPLAIN SELECT * FROM my_table_distributed WHERE id = 123;
查看数据分布
可以通过统计信息查看数据在各个分片上的分布:
SELECT shard, count() AS rowsFROM my_table_distributedGROUP BY shard;
常见问题及解决方法
数据分布不均
原因
分片键选择不当,导致某些分片的数据量远大于其他分片。
解决方法
选择更均匀的分片键(如哈希值)。
定期检查数据分布情况,调整分片策略。
查询性能下降
原因
分片之间的网络延迟较高。
某些分片负载过高,导致查询响应变慢。
解决方法
优化网络环境,减少节点之间的延迟。
在查询时指定优先使用的分片(如通过 load_balancing 参数)。
数据丢失
原因
某些分片长时间离线,导致数据无法同步。
解决方法
确保所有分片的可用性。
定期备份数据。
总结
ClickHouse 的分片机制通过将数据分布到多个物理节点上,实现了水平扩展和负载均衡。
分片和副本的结合可以提高系统的可靠性和查询性能。
通过合理的配置和监控,可以充分发挥分片机制的优势,支持大规模数据存储和高并发查询。
https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/sharedmergetree
clickhouse-数据分片机制参考官方地址
