




一、结缘duckdb
这篇文章的重点是pg_duckdb这个插件,但是在聊这个插件的具体内容之前,我想先简单聊聊duckdb,对此不感兴趣的同学可以直接跳过前两节,直接阅读第三节,前两节不会影响到后续的正常阅读。
最早我是从我老乡(德哥digoal)那里知道有这麽一款数据库叫做duckdb,当时也没仔细去研究,只知道它非常的小巧、使用也简单方便而且性能十分强劲。
虽然当时我没仔细去研究过,但是我背后的大佬(我师父大章总)对duckdb还是挺感兴趣的,然后他就尝试着写了个小demo,尝试着将PostgreSQL跑的很费劲的SQL下推至duckdb中执行。
后来德哥和唰唰哥在杭州举办技术沙龙的时候,邀请到了李红艳老师(duckdb_fdw项目作者)作为演讲嘉宾,也邀请了我师父作为演讲嘉宾(虽然后面我主动要求让我讲的)。
在活动开始前,吃午饭的时候,他们几位技术大咖搁那聊的那叫一个热火朝天,聊的也都是关于duckdb的内容,我就在旁边打哈哈。
因此认识了李红艳老师,后面听了李红艳老师关于duckdb和duckdb_fdw的演讲内容,又加深了我对duckdb的了解。
其实如果我印象中没记错的话,德哥好像也是从李红艳老师那里了解到的duckdb。
出于duckdb在数据分析领域的表现非常亮眼,加上postgresql确实不擅长处理olap场景,更更更重要的是得益于二者的拓展能力非常强悍。
在德哥宣传duckdb的同时,一系列关于pg和duckdb二者的插件如雨后春笋般冒了出来。
这里我就不过多列举了,我印象中最深的除了李红艳老师的duckdb_fdw外,便是hydradatabase的pg_quack,这个项目也是今天的主角pg_duckdb的前身。
可能是看到了pg_quack这个项目的巨大潜力,后面Hydra和MotherDuck便联手开发pg_duckdb这个新的项目了,算是真正的官方下场了,
对于postgresql而言可以加强分析能力,对于duckdb而言可以获得一部分受众群体和人气,真正意义上的双赢~~~
关于duckdb为什么能如此之快,Hydra专门写了篇文章,可以阅读尝试阅读https://docs.hydra.so/products/analytics_engine
接下来该聊聊今天的主角pg_duckdb了。
二、相识pg_duckdb
和pg_duckdb的相识,大概是去年国庆左右,当时放假回老家,无意间看见了这个项目。想着在家反正闲着也是闲着,无聊不如找点事情做做,然后pg_duckdb还处于还没正式发布版本阶段,
看了看发现还有蛮多缺陷和待办事项的,比如说做做PostgreSQL不同版本的兼容或者改点小bug之类的,也能算是给PostgreSQL做点贡献什么的,就这样子顺利成章的参与到pg_dudkdb的开源工作了。
后面回了杭州也是下班的时候瞅瞅或者放假的时候看看,当工作忙的时候先处理手头上工作的事情,所以实际上也没做太多的事。
主要是还是前面的那些大佬在干活(都是Hydra和MotherDuck的大佬或者是duckdb官方大佬),我就偶尔出来打打杂之类的(相对活跃在0.1.0-0.2.0版本)。
但是有意思的是,我还因为尝试着改pg_duckdb发现的bug,反过来改了一个PostgreSQL的一个小bug,是Tom Lane好多年前写的代码了,
虽然是一个非常非常小的点,但是这让我原本只是想给PostgreSQL做点贡献,变成真正给PostgreSQL做了点贡献。
回到pg_duckdb这个项目上来,也是过完年之后没怎么关注这块了,然后前些天刚好看见pg_duckdb发布了0.3.1版本。
发现变化还是挺多的,比如说以前0.3.0之前的版本的logo长这样子,算是临时logo
0.3.0之后官方真正认证了,获得了一个新的logo(是不是和duckdb的官方logo超级像),
并在duckdb的在线文档中也有了记录https://duckdb.org/docs/dev/repositories.html

除了logo和文档发生了好多的变化,在代码这块也改了好多东西,所以抽空花了点时间,大概几个小时,简单的梳理了一下,分享给大家。
三、pg_duckdb的源码安装和相关参数简单介绍
接下来介绍一下简单的源码安装。由于duckdb是作为pg_duckdb这个开源项目的子项目。
所以在编译安装pg_duckdb的时候,需要考虑到postgresql和duckdb的各自的安装要求。
这里要求的pg的版本是14-17,低于14的版本不受支持,pg_duckdb不支持13版本的原因
大概是因为13版本也马上快要不维护了,毕竟13版本出道是20年,pg的一个大版本大概5年的生命周期,时间也差不多了。
pg版本信息可以参考PostgreSQL: Versioning Policy。而duckdb的一些编译条件可以参考Building DuckDB from Source – DuckDB。
-- 在contrib目录拉取代码
git clone https://github.com/duckdb/pg_duckdb.git
-- 进入代码目录
cd pg_duckdb
-- 正常编译并测试 使用如下命令
make installcheck
-- 如果想编译DEBUG版本的pg_duckdb 使用下面的命令
make installcheck DUCKDB_BUILD=Debug
-- 然后在postgresql.conf中添加
shared_preload_libraries = 'pg_duckdb'
-- 重启
pg_ctl restart
-- 创建拓展
CREATE EXTENSION pg_duckdb;值得注意的debug版本和非debug版本性能还是存在蛮大的差距的,这一点后面我们可以简单测试看一下。
在真正运行测试,我们先来看看pg_duckdb提供的一些相关参数。
| duckdb.force_execution | Force queries to use DuckDB execution |
|---|---|
| duckdb.enable_external_access | Allow the DuckDB to access external state. |
| duckdb.allow_community_extensions | Disable installing community extensions |
| duckdb.allow_unsigned_extensions | Allow DuckDB to load extensions with invalid or missing signatures |
| duckdb.autoinstall_known_extensions | Whether known extensions are allowed to be automatically installed when a DuckDB query depends on them |
| duckdb.autoload_known_extensions | Whether known extensions are allowed to be automatically loaded when a DuckDB query depends on them |
| duckdb.max_memory | The maximum memory DuckDB can use (e.g., 1GB) |
| duckdb.memory_limit | The maximum memory DuckDB can use (e.g., 1GB), alias for duckdb.max_memory |
| duckdb.disabled_filesystems | Disable specific file systems preventing access (e.g., LocalFileSystem) |
| duckdb.threads | Maximum number of DuckDB threads per Postgres backend. |
| duckdb.worker_threads | Maximum number of DuckDB threads per Postgres backend, alias for duckdb.threads |
| duckdb.max_workers_per_postgres_scan | Maximum number of PostgreSQL workers used for a single Postgres scan |
| duckdb.postgres_role | Which postgres role should be allowed to use DuckDB execution, use the secrets and create |
| duckdb.motherduck_enabled" | If motherduck support should enabled. ‘auto’ means enabled if motherduck_token is set |
| duckdb.motherduck_token | The token to use for MotherDuck |
| duckdb.motherduck_postgres_database | Which database to enable MotherDuck support in |
| duckdb.motherduck_default_database | Which database in MotherDuck to designate as default (in place of my_db) |
| duckdb.motherduck_background_catalog_refresh_inactivity_timeout | When to stop syncing of the motherduck catalog when no activity has taken place |
这里大大小小差不多有十几二十个参数,这之间还包含一部分motherduck的参数,毕竟是人家开发的,带带货也很正常。
虽然这里这么多个参数,但是今天我们只需要了解一下第一个参数就好了,至于别的参数等诸位自己上手玩的时候,再去了解吧。
其实pg_duckdb的可玩性还是非常之高的,可以用它来访问各种对象存储,也支持多种数据文件格式,
但是作为一个数据库内核的开发者,我还是更在乎SQL能不能跑的更快更好,毕竟谁不喜欢又快又好呢?
当然更详细的使用还请参考duckdb/pg_duckdb: DuckDB-powered Postgres for high performance apps & analytics.项目的README更好。
回到参数这块,duckdb.force_execution这是个bool类型的参数,默认是off的状态,当我们将这个参数设置成on时,将会尝试将在DuckDB中执行当前输入的“SQL”。
当发现在DuckDB中无法执行时,会回退到PostgreSQL中执行,当我们设置成off时,就仅在PostgreSQL中执行了。
四、简单测试
通常而言,对于未经过优化单机的PostgreSQL,TPCDS的测试往往不尽如人意。
我们可以使用pg_duckdb代码目录下的scripts目录中的load-tpcds.sh脚本来生成TPCDS的相关测试数据。
至于怎么使用脚本,估计我就无需多言了,可以自己看一下,内容很少写的也很详细,这里就不占篇幅了。
接下来在我的本地的PostgreSQL中,尝试运行TPCDS 1GB的第一条查询,psql -o /dev/null将执行结果输出到/dev/null,丢弃掉数据。
在这里我们仅需要关注SQL的执行时间,结果如下:
[postgres@halo-centos8 16]$ psql -o /dev/null
psql (16.6)
Type "help" for help.
postgres=# \timing
Timing is on.
postgres=# WITH customer_total_return AS
(SELECT sr_customer_sk AS ctr_customer_sk,
sr_store_sk AS ctr_store_sk,
sum(sr_return_amt) AS ctr_total_return
FROM store_returns,
date_dim
WHERE sr_returned_date_sk = d_date_sk
AND d_year = 2000
GROUP BY sr_customer_sk,
sr_store_sk)
SELECT c_customer_id
FROM customer_total_return ctr1,
store,
customer
WHERE ctr1.ctr_total_return >
(SELECT avg(ctr_total_return)*1.2
FROM customer_total_return ctr2
WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk)
AND s_store_sk = ctr1.ctr_store_sk
AND s_state = 'TN'
AND ctr1.ctr_customer_sk = c_customer_sk
ORDER BY c_customer_id
LIMIT 100;
Time: 326299.052 ms (05:26.299)在经过了大概五分多钟的无聊等待之后 这条SQL终于是执行完了。在前面我们有提到pg_duckdb的debug版本和非debug版本存在较为明显的性能表现,
这里我们先用pg_duckdb的debug版本运行看一下同一条SQL的执行时间、
[postgres@halo-centos8 16]$ psql -o /dev/null
psql (16.6)
Type "help" for help.
postgres=# \timing
Timing is on.
postgres=# set duckdb.force_execution = on;
Time: 1.856 ms
postgres=# -- pg_duckdb的debug版本 在duckdb中执行tpcds q1
postgres=# WITH customer_total_return AS
(SELECT sr_customer_sk AS ctr_customer_sk,
sr_store_sk AS ctr_store_sk,
sum(sr_return_amt) AS ctr_total_return
FROM store_returns,
date_dim
WHERE sr_returned_date_sk = d_date_sk
AND d_year = 2000
GROUP BY sr_customer_sk,
sr_store_sk)
SELECT c_customer_id
FROM customer_total_return ctr1,
store,
customer
WHERE ctr1.ctr_total_return >
(SELECT avg(ctr_total_return)*1.2
FROM customer_total_return ctr2
WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk)
AND s_store_sk = ctr1.ctr_store_sk
AND s_state = 'TN'
AND ctr1.ctr_customer_sk = c_customer_sk
ORDER BY c_customer_id
LIMIT 100;
Time: 1462.435 ms (00:01.462)其实看到这也能很直观的感受到PostgreSQL和pg_duckdb这二者之间十分明显的性能差异了,虽然这还仅仅只是pg_duckdb的debug版本。
接下来让我们用pg_duckdb的非debug版本来运行看看,需要耗时多久。
[postgres@halo-centos8 pg_duckdb]$ psql -o /dev/null
psql (16.6)
Type "help" for help.
postgres=# \timing
Timing is on.
postgres=# set duckdb.force_execution = on;
Time: 3.851 ms
postgres=# -- 在duckdb中执行tpcds q1
postgres=# WITH customer_total_return AS
(SELECT sr_customer_sk AS ctr_customer_sk,
sr_store_sk AS ctr_store_sk,
sum(sr_return_amt) AS ctr_total_return
FROM store_returns,
date_dim
WHERE sr_returned_date_sk = d_date_sk
AND d_year = 2000
GROUP BY sr_customer_sk,
sr_store_sk)
SELECT c_customer_id
FROM customer_total_return ctr1,
store,
customer
WHERE ctr1.ctr_total_return >
(SELECT avg(ctr_total_return)*1.2
FROM customer_total_return ctr2
WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk)
AND s_store_sk = ctr1.ctr_store_sk
AND s_state = 'TN'
AND ctr1.ctr_customer_sk = c_customer_sk
ORDER BY c_customer_id
LIMIT 100;
Time: 204.338 ms对于TPCDS 1GB的query1 这同一条SQL大概得出如下表格数据,第二行是
PostgreSQL(未优化) | pg_duckdb(debug版本) | pg_duckdb |
|---|---|---|
326299.052 ms | 1462.435 ms | 204.338 ms |
| 1599(倍) | 7(倍) | 1(基数) |
这里其实有两个结论
一个就是对于一些较为复杂的查询或者一些复杂的场景,pg_duckdb能够帮助postgresql显著的提升查询性能,又快又好呀,家人们。
另一个结论就是如果您不需要深入理解pg_duckdb的完整实现或者调试这相关的代码,那么便不需要编译生成debug版本的pg_duckdb,因为这也会影响到查询的性能。
但是这里也存在这么一个问题,就是既然pg_duckdb的性能提升这么明显,那是不是所有的场景我都直接用pg_duckdb就行了?
要解答这个问题,那么我们就需要试着去了解pg_duckdb的一个大概的实现逻辑。
五、设计实现
由于pg_duckdb混杂着c语言风格的pg代码,同时存在着c++风格的duckdb代码,对于较少接触编程同学而言,直接带着大家去翻代码可能会有些痛苦。
所以这里我就直接说一下我自己的结论好了,后面再开展源码解读(大致脉络,讲细节是讲不完的),对源码不感兴趣的同学也可以直接跳过,看第六章最后的总结阶段也行。
当我们使用pg_duckdb(0.3.0及以上的版本)时,输入了一条SELECT的语句(pg_duckdb只支持SELECT、对于INSERT、UPDATE、DELETE其实由原生PG处理),
对于pg而言可能会执行至少两次甚至两次以上的SQL,且每次的SQL不一定一样。
对于duckdb而言,会执行两次Prepare和一次Execute。
可能有很多的人有疑问就是在于当输入一条SELECT语句时,pg执行一次很正常这能理解。但是这里说的两次及两次以上又是什么怎么回事?
先不急容我慢慢说来。我们先来看一下duckdb的两次Prepare和一次Execute。
其实两次Prepare都不需要经过论证,因为这早就作为一个性能问题被记录过了Don't plan twice for prepared statements。
但是为了说的更加清楚一些,我在这里将第一次Prepare的一个大概的调用堆栈列一下(需要注意的是duckdb所执行的SQL必然和pg正在执行的SQL是不完全一致的,而是经过转换了之后的语句),大概如下
DuckdbPlannerHook
DuckdbPlannerHook_Cpp
DuckdbPlanNode
CreatePlan
DuckdbPrepare在CreatePlan函数中 尝试将duckdb执行的parpare的结果进行类型转换,验证是否支持相关返回的结果,构造CustomScan为后续做准备,关于PG的CustomScan请参考Writing a Custom Scan Provider
CreatePlan(Query *query, bool throw_error) {
int elevel = throw_error ? ERROR : WARNING;
/*
* Prepare the query, se we can get the returned types and column names.
*/
duckdb::unique_ptr<duckdb::PreparedStatement> prepared_query = DuckdbPrepare(query);
if (prepared_query->HasError()) {
elog(elevel, "(PGDuckDB/CreatePlan) Prepared query returned an error: '%s", prepared_query->GetError().c_str());
return nullptr;
}
CustomScan *duckdb_node = makeNode(CustomScan);
auto &prepared_result_types = prepared_query->GetTypes();
for (size_t i = 0; i < prepared_result_types.size(); i++) {
auto &column = prepared_result_types[i];
Oid postgresColumnOid = pgduckdb::GetPostgresDuckDBType(column);
if (!OidIsValid(postgresColumnOid)) {
elog(elevel, "(PGDuckDB/CreatePlan) Cache lookup failed for type %u", postgresColumnOid);
return nullptr;
}
// 省略相关代码
return (Plan *)duckdb_node;
}再回到DuckdbPlanNode,让pg生成执行计划 做一些检查 最后将其替换成duckdb prepare的结果
DuckdbPlanNode(Query *parse, const char *query_string, int cursor_options, ParamListInfo bound_params,
bool throw_error) {
/* We need to check can we DuckDB create plan */
Plan *duckdb_plan = InvokeCPPFunc(CreatePlan, parse, throw_error);
CustomScan *custom_scan = castNode(CustomScan, duckdb_plan);
if (!duckdb_plan) {
return nullptr;
}
// 省略代码~~~
/*
* We let postgres generate a basic plan, but then completely overwrite the
* actual plan with our CustomScan node. This is useful to get the correct
* values for all the other many fields of the PLannedStmt.
*
* XXX: The primary reason we did this in the past is so that Postgres
* filled in permInfos and rtable correctly. Those are needed for postgres
* to do its permission checks on the used tables. We do these checks
* inside DuckDB as well, so that's not really necessary anymore. We still
* do this though to get all the other fields filled in correctly. Possibly
* we don't need to do this anymore.
* .........
*/
Query *copied_query = (Query *)copyObjectImpl(parse);
PlannedStmt *postgres_plan = standard_planner(copied_query, query_string, cursor_options, bound_params);
postgres_plan->planTree = duckdb_plan;
// 省略代码~~~
return postgres_plan;
}接下来来到pg的执行器阶段 但还仅仅是standard_ExecutorStart阶段 但是这个时候将会迎来duckdb的第二次prepare 调用堆栈如下
DuckdbExecutorStartHook
standard_ExecutorStart
InitPlan
ExecInitNode
ExecInitCustomScan
Duckdb_BeginCustomScan_Cpp
DuckdbPrepare而这一次的prepare的结果会被保留到至duckdb的Execute处理,我们这里就简单看一下Duckdb_BeginCustomScan_Cpp这个函数好了
Duckdb_BeginCustomScan_Cpp(CustomScanState *cscanstate, EState *estate, int /*eflags*/) {
DuckdbScanState *duckdb_scan_state = (DuckdbScanState *)cscanstate;
duckdb::unique_ptr<duckdb::PreparedStatement> prepared_query = DuckdbPrepare(duckdb_scan_state->query);
if (prepared_query->HasError()) {
throw duckdb::Exception(duckdb::ExceptionType::EXECUTOR,
"DuckDB re-planning failed: " + prepared_query->GetError());
}
duckdb_scan_state->duckdb_connection = pgduckdb::DuckDBManager::GetConnection();
duckdb_scan_state->prepared_statement = prepared_query.release(); // 需要注意的是此处保留了此次的prepare结果
duckdb_scan_state->params = estate->es_param_list_info;
duckdb_scan_state->is_executed = false;
duckdb_scan_state->fetch_next = true;
duckdb_scan_state->css.ss.ps.ps_ResultTupleDesc = duckdb_scan_state->css.ss.ss_ScanTupleSlot->tts_tupleDescriptor;
HOLD_CANCEL_INTERRUPTS();
}最后就来到duckdb的Execute处理了 依旧是PG的执行器阶段 但是这个时候就不再是standard_ExecutorStart了,而是standard_ExecutorRun,调用堆栈大概如下
PortalRun
PortalRunSelect
ExecutorRun
standard_ExecutorRun
ExecutePlan
ExecProcNode
ExecProcNodeFirst
ExecCustomScan
Duckdb_ExecCustomScan
Duckdb_ExecCustomScan_Cpp
ExecuteQuery让我们看一下ExecuteQuery的简化版本
ExecuteQuery(DuckdbScanState *state) {auto &prepared = *state->prepared_statement; // 此处和上面的Duckdb_BeginCustomScan_Cpp呼应 // 省略部分代码 关于绑定变量的处理 auto pending = prepared.PendingQuery(named_values, true); // 省略部分代码 state->query_results = pending->Execute(); state->column_count = state->query_results->ColumnCount(); state->is_executed = true; }
而当duckdb 完成Execute之后 便仅需要将duckdb运行出的结果转换成pg对应的类型的结果即可。
说到这,可能就有同学要问了,duckdb两次Prepare、一次Execute,大概就讲清楚了。
但是关于pg那一块,算来算去也还仅仅就执行了一次SQL呀,而且那个SQL就是用户写的SQL,
并且执行阶段还是通过执行CustomScan,也就是交由duckdb处理的,不是你之前所说的至少两次甚至两次之上呀!
我想说的是,在0.3.0之前的版本确实这样子就差不多了,但是,我是说但是。0.3.0之后的版本进行了很多修改,特别是关于数据这一块的。
从始至终数据都是存储在pg中的,duckdb想要执行的话,起码需要数据吧?那么duckdb是如何获取数据的呢?
这便是问题的关键,当然答案也很明显肯定就是pg_duckdb干的好事咯~
pg_duckdb重载了duckdb::TableCatalogEntry,当duckdb在进行Execute时,发现需要加载数据,而pg_duckdb刚好有实现了相关的函数接口,
便会去调用,等加载完数据之后,最后执行转换输出一条龙。所以让我们来看一下相关的函数接口
ConstructTableScanQuery
PostgresTableReader
PostgresScanFunction
InsertTupleIntoChunk
PostgresTableReaderCleanup这里面最好理解的算是PostgresTableReader 简化之后便是下面的样子了
PostgresTableReader::PostgresTableReader(const char *table_scan_query, bool count_tuples_only)
: parallel_executor_info(nullptr), parallel_worker_readers(nullptr), nreaders(0), next_parallel_reader(0),
entered_parallel_mode(false), cleaned_up(false) {
// 省略部分代码
List *raw_parsetree_list = PostgresFunctionGuard(pg_parse_query, table_scan_query);
List *query_list = PostgresFunctionGuard(pg_analyze_and_rewrite_fixedparams, raw_parsetree, table_scan_query, nullptr, 0, nullptr);
// 省略部分代码
PlannedStmt *planned_stmt = PostgresFunctionGuard(standard_planner, query, table_scan_query, 0, nullptr);
// 省略部分代码
PostgresFunctionGuard(ExecutorStart, table_scan_query_desc, 0);
table_scan_planstate = PostgresFunctionGuard(ExecInitNode, planned_stmt->planTree, table_scan_query_desc->estate, 0);
// 省略部分代码 关于并行进程 并行扫描
elog(DEBUG1, "(PGDuckDB/PostgresTableReader)\n\nQUERY: %s\nRUNNING: %s.\nEXECUTING: \n%s", table_scan_query,
!nreaders ? "IN PROCESS THREAD" : psprintf("ON %d PARALLEL WORKER(S)", nreaders),
ExplainScanPlan(table_scan_query_desc));
slot = PostgresFunctionGuard(ExecInitExtraTupleSlot, table_scan_query_desc->estate,
table_scan_planstate->ps_ResultTupleDesc, &TTSOpsMinimalTuple);
}可以看到的是 这是在运行table_scan_query这条SQL 获取它的slot数据 其实就是元组数据
而table_scan_query来自ConstructTableScanQuery,它会获取当前执行的SQL中所需要用到的每一个表,根据所需列以及过滤条件拼接一条新的SQL,供pg执行
PostgresScanGlobalState::ConstructTableScanQuery(const duckdb::TableFunctionInitInput &input) {
/* SELECT COUNT(*) FROM */
if (input.column_ids.size() == 1 && input.column_ids[0] == UINT64_MAX) {
scan_query << "SELECT COUNT(*) FROM " << pgduckdb::GenerateQualifiedRelationName(rel);
count_tuples_only = true;
return;
}
// 省略代码
scan_query << "SELECT ";
bool first = true;
for (auto const &attr_num : output_columns) {
if (!first) {
scan_query << ", ";
}
first = false;
auto attr = GetAttr(table_tuple_desc, attr_num - 1);
scan_query << pgduckdb::QuoteIdentifier(GetAttName(attr));
}
scan_query << " FROM " << GenerateQualifiedRelationName(rel);
// 省略代码
if (query_filters.size()) {
scan_query << " WHERE ";
scan_query << FilterJoin(query_filters, " AND ");
}
}pg执行后获取到的元组数据 将其转换成duckdb对应类型的数据 填充至duckdb的output vector中供后续计算,可以简单看一下InsertTupleIntoChunk函数 甚至给count(*)做了优化
InsertTupleIntoChunk(duckdb::DataChunk &output, PostgresScanLocalState &scan_local_state, TupleTableSlot *slot) {
auto scan_global_state = scan_local_state.global_state;
if (scan_global_state->count_tuples_only) {
/* COUNT(*) returned tuple will have only one value returned as first tuple element. */
scan_global_state->total_row_count += slot->tts_values[0];
scan_local_state.output_vector_size += slot->tts_values[0];
return;
}
/* Write tuple columns in output vector. */
for (int duckdb_output_index = 0; duckdb_output_index < slot->tts_tupleDescriptor->natts; duckdb_output_index++) {
auto &result = output.data[duckdb_output_index];
if (slot->tts_isnull[duckdb_output_index]) {
auto &array_mask = duckdb::FlatVector::Validity(result);
array_mask.SetInvalid(scan_local_state.output_vector_size);
} else {
auto attr = slot->tts_tupleDescriptor->attrs[duckdb_output_index];
if (attr.attlen == -1) {
bool should_free = false;
Datum detoasted_value = DetoastPostgresDatum(
reinterpret_cast<varlena *>(slot->tts_values[duckdb_output_index]), &should_free);
ConvertPostgresToDuckValue(attr.atttypid, detoasted_value, result, scan_local_state.output_vector_size);
if (should_free) {
duckdb_free(reinterpret_cast<void *>(detoasted_value));
}
} else {
ConvertPostgresToDuckValue(attr.atttypid, slot->tts_values[duckdb_output_index], result,
scan_local_state.output_vector_size);
}
}
}
scan_local_state.output_vector_size++;
scan_global_state->total_row_count++;
}所以这就是我所说的pg至少两次获两次以上的原因,且执行的SQL还不一样。
一个最简单的场景就是用户输入的查询语句中存在一张表,那么pg处理需要执行用户输入的查询语句外,还要执行那个表的拼接出来的SQL 用于给duckdb填充数据。
一个最简单的验证方式将日志等级调低 SET client_min_messages = 'debug1',
如下包含一个简单示例 select sum(a) from t1 以及一个相对复制的示例,用来观察
WITH customer_total_return AS
(SELECT sr_customer_sk AS ctr_customer_sk,
sr_store_sk AS ctr_store_sk,
sum(sr_return_amt) AS ctr_total_return
FROM store_returns,
date_dim
WHERE sr_returned_date_sk = d_date_sk
AND d_year = 2000
GROUP BY sr_customer_sk,
sr_store_sk)
SELECT c_customer_id
FROM customer_total_return ctr1,
store,
customer
WHERE ctr1.ctr_total_return >
(SELECT avg(ctr_total_return)*1.2
FROM customer_total_return ctr2
WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk)
AND s_store_sk = ctr1.ctr_store_sk
AND s_state = 'TN'
AND ctr1.ctr_customer_sk = c_customer_sk
ORDER BY c_customer_id
LIMIT 100;运行结果如下:
[postgres@halo-centos8 ~]$ psql -o /dev/null
psql (16.6)
Type "help" for help.
postgres=# set duckdb.force_execution = on;
postgres=# SET client_min_messages = 'debug1';
postgres=# select sum(a) from t1;
DEBUG: (PGDuckDB/PostgresTableReader)
QUERY: SELECT a FROM public.t1
RUNNING: ON 1 PARALLEL WORKER(S).
EXECUTING:
Parallel Seq Scan on t1
postgres=# WITH customer_total_return AS
(SELECT sr_customer_sk AS ctr_customer_sk,
sr_store_sk AS ctr_store_sk,
sum(sr_return_amt) AS ctr_total_return
FROM store_returns,
date_dim
WHERE sr_returned_date_sk = d_date_sk
AND d_year = 2000
GROUP BY sr_customer_sk,
sr_store_sk)
SELECT c_customer_id
FROM customer_total_return ctr1,
store,
customer
WHERE ctr1.ctr_total_return >
(SELECT avg(ctr_total_return)*1.2
FROM customer_total_return ctr2
WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk)
AND s_store_sk = ctr1.ctr_store_sk
AND s_state = 'TN'
AND ctr1.ctr_customer_sk = c_customer_sk
ORDER BY c_customer_id
LIMIT 100;
DEBUG: (PGDuckDB/PostgresTableReader)
QUERY: SELECT s_store_sk, s_state FROM tpcds1.store WHERE s_state='TN'
RUNNING: ON 1 PARALLEL WORKER(S).
EXECUTING:
Parallel Seq Scan on store
Filter: ((s_state)::text = 'TN'::text)
DEBUG: (PGDuckDB/PostgresTableReader)
QUERY: SELECT d_date_sk FROM tpcds1.date_dim WHERE d_year=2000
RUNNING: ON 1 PARALLEL WORKER(S).
EXECUTING:
Parallel Seq Scan on date_dim
Filter: (d_year = 2000)
DEBUG: (PGDuckDB/PostgresTableReader)
QUERY: SELECT sr_returned_date_sk, sr_customer_sk, sr_store_sk, sr_return_amt FROM tpcds1.store_returns WHERE (sr_returned_date_sk>=2451545 AND sr_returned_date_sk<=2451910)
RUNNING: ON 1 PARALLEL WORKER(S).
EXECUTING:
Parallel Seq Scan on store_returns
Filter: ((sr_returned_date_sk >= 2451545) AND (sr_returned_date_sk <= 2451910))
DEBUG: (PGDuckDB/PostgresTableReader)
QUERY: SELECT c_customer_sk, c_customer_id FROM tpcds1.customer WHERE (c_customer_sk>=6 AND c_customer_sk<=100000)
RUNNING: ON 2 PARALLEL WORKER(S).
EXECUTING:
Parallel Seq Scan on customer
Filter: ((c_customer_sk >= 6) AND (c_customer_sk <= 100000))t六、总结
让我们来尝试着总结一下。
6.1、各司其职
还是以复杂一些的TPCDS的第一条查询为例,看看PostgreSQL、DuckDB和pg_duckdb都做了些什么事情。
对于pg而言可能会执行至少两次或两次以上的SQL,且每次的SQL不一定一样(对于简单的count(*)而言 会执行相同的SQL,这是专门的优化),对于这里的场景pg总共需要执行5条SQL,如下图所示。

对于duckdb而言,执行两次Prepare和一次Execute,执行动作穿插在Postgresql的优化器和执行器阶段。
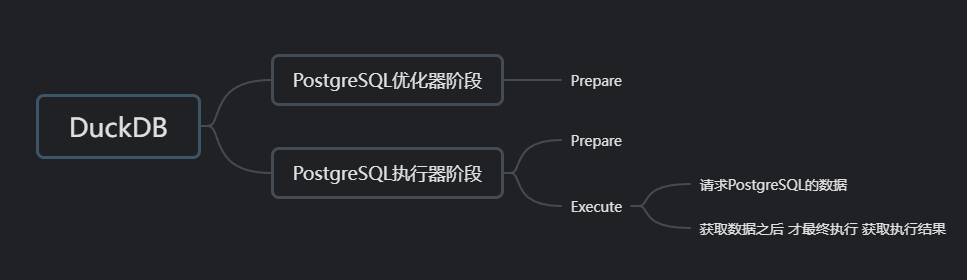
对于pg_duckdb而言就是要协调好这些调用,该转换的时候转换。

当然这中间还存在非常多的细节,在这里我只能说个大概,见谅见谅~
6.2、全场景适用?
回到第四节的问题,问题描述是既然pg_duckdb的性能提升这么明显,那是不是所有的场景我都直接用pg_duckdb就行了?
其实经过上面分析,相比大家心里都有了答案。由于实际的数据存储在pg内部,对于duckdb而言,它需要先向pg请求完数据,才能发挥它的计算能力。
所以只有当PostgreSQL实际处理SQL的时间 远超于将数据自动导入duckdb的时间,才能在这里面受益。
所以对于一些简单的SQL场景,使用pg_duckdb并不会加速,相反会变得更慢,对于简单场景的验证如下:
postgres=# \timing
Timing is on.
postgres=# select count(*) from t1;
count
-------
20003
(1 row)
Time: 4.489 ms
postgres=# -- 在pg中执行简单SQL
postgres=# select sum(a) from t1;
sum
-----------
100010003
(1 row)
Time: 3.045 ms
postgres=# set duckdb.force_execution = on;
SET
Time: 0.410 ms
postgres=# -- 使用pg_duckdb 在duckdb中执行简单SQL
postgres=# select sum(a) from t1;
sum
-----------
100010003
(1 row)
Time: 27.058 ms而pg_duckdb的适用场景,比方说跑跑批处理或者一些需要大量分析的复杂场景。
6.3、技术路线和fdw的优劣
这个点就很难评价了,因为二者是不同的技术路线,pg_duckdb走的是Custom Scan,算是一种不太常见的技术路线。我之前也看见过国外也有帖子吐槽过pg_duckdb的Custom Scan方案。
根据我上一篇文章对fdw的一个简单理解的话,可能在使用方式上,pg_duckdb这种比较方便,不需要做别的操作,设置一下参数就可以了。
对于fdw而言可能需要三板斧操作,CREATE SERVER 、CREATE USER MAPPING、CREATE FOREIGN TABLE等等之类的 。
但是对于简单场景的SQL而言,可能fdw的方式更加高效,毕竟不需要导数据,只需要将SQL下推就可以了。
对于复杂一些的场景而言,可能pg_duckdb的方式可能会更好一些,因为fdw的方式需要优化器介入,判断是否能将SQL转换下推至远端,可能对于复杂的关联而言,不一定能完整的将下推,
这个时候可能就会反向从远端拉取数据至pg中处理。除去Custom Scan之外,事实上pg_duckdb也实现了TAM(不过有限制只支持临时表使用),只是这里不好再过多的拓展。
七、声明
若文中存在错误或不当之处,敬请指出,以便我进行修正和完善。希望这篇文章能够帮助到各位。
文章转载请联系,谢谢合作
