CloudberryDB | 第3期 | 解析器原理
CloudberryDB基于PostgreSQL,这块原理和PG一样,都是利用flex和yacc进行词法解析和语法解析生成语法树,再经语义分析生成逻辑执行计划,以供优化器进行优化生成最终的物理执行计划。
1、词法分析
词法分析主要识别一个SQL中的关键字、标识符、操作符、常量和终结符,划分成多个不同的token。
名字 | 词性 | 说明 |
关键字 | keyword | SELECT/FROM/WHERE等对大小写不敏感 |
标识符 | IDENT | 用户自己定义的名字、常量名、变量名、过程名等,若无括号包着,则对大小写不敏感 |
操作符 | operator | 操作符,如果是/*和--会识别为注释 |
常量 | ICONST/FCONST/SCONST/BCONST/XCONST | 包括数值型常量、字符串常量、位串常量等 |
CloudberryDB在kwlist.h中定义了大量的关键字,按照字母顺序排序,查找时方便使用二分查找法进行查找,比如下面代码片段:

词法结构于规则由scan.l文件定义,和其他.l文件类似,大致分为三部分:
看下scan.l的具体结构:
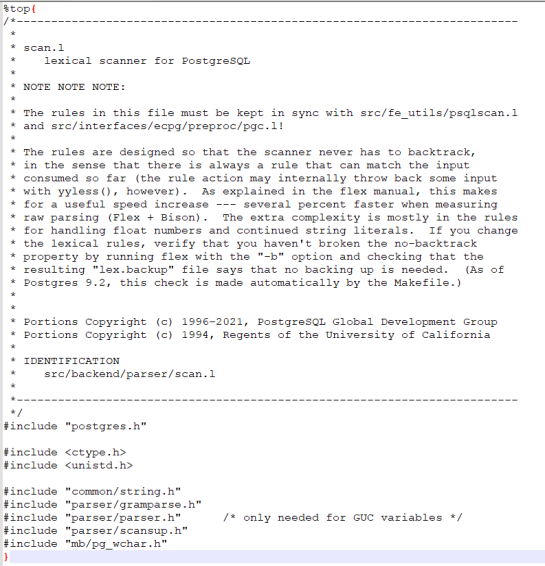
1)%top{}:头文件的顶上注释,包括一些头文件等
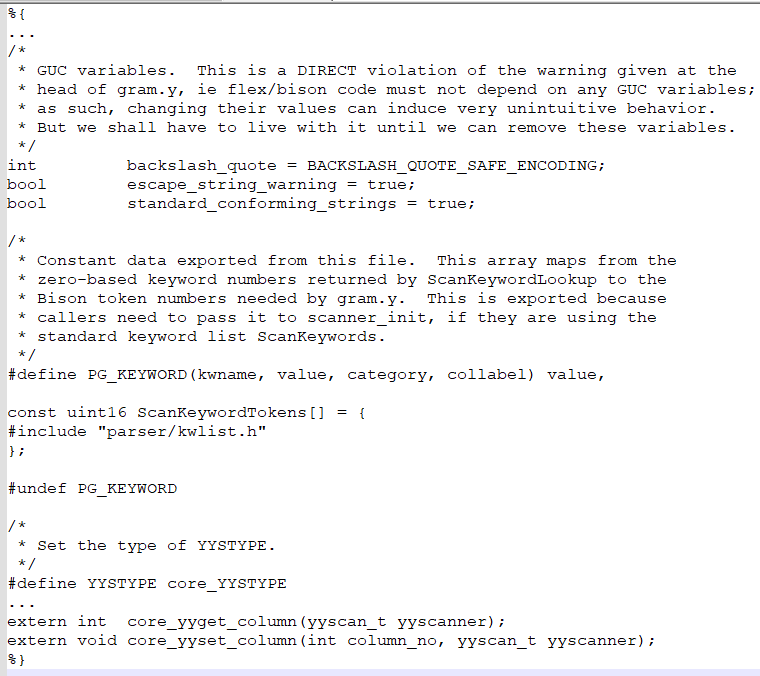
2)%{ %}:宏定义和一些函数声明:
3)option部分是flex支持的一些参数,比如%option prefix="core_yy" 通过加入前缀,可以将原来的yylex等函数 变成core_yylex.这样可以在一个程序中建立多个词法分析器。用来分析不同的输入流:
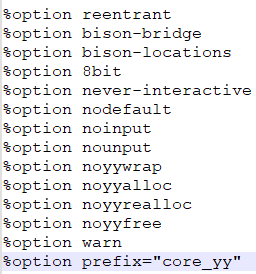
4)下面就是定义的一些规则:利用正则表达式进行匹配
下面是定义的操作符:operator,由多个op_chars组成,op_chars由[]中任意一个符号
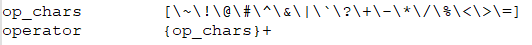
还需要在scan.l中对操作符进行更加明确的检查:

5)在operator定义的过程中可以看到,有一些以yy开头的变量和函数,他们是Lex工具的内置变量和函数:
yytext:变量,匹配的字符串
yyleng:变量,匹配的字符串的长度
yyval:变量,与标记相对应的值
yylex:函数,调用扫描器,返回token
yyless:函数,将yytext的前n个以外的字符,重新放回输入流匹配
yymore:函数,将下此分析的结果词汇接在当前yytext的后面
yywrap:函数,返回1表示扫描完后结束程序,否则返回0
在编译的过程中,scan.l会被编译成scan.c文件,从而编译成scan.o作为词法解析器。
2、语法分析
依据bison进行语法解析。语法文件为gram.y,编译过程中生成gram.c和gram.h,最终编译成gram.o作为语法解析器。gram.y的整体结构和scan.l类似都是分为定义段、规则段和代码段。Bison的工作原理主要两个堆栈和shift(移入)、reduce(规约)来完成,一个堆栈负责处理符号,包括终结符和非终结符(下文介绍这两个标识符怎么定义)。另一个堆栈是处理与之一一对应的值堆栈。这里几个概念需要理解:
1)终结符:终结符不能再进行推导,是不可拆分的最小单元
2)非终结符:一个可拆分元素
3)移进:当语法分析器读到的记号没办法结束一条规则时,将该记号压入内部堆栈
4)归约:当压入堆栈的语法符号可以组成规则的右部时,弹出所有右部符号,把对应的左部符号入栈。归约后会执行规则关联的代码。
2.1 认识gram.y:定义段
1、%{ ... %}中的代码会被原样拷贝到生成的gram.c中,里面包括头文件、结构体定义和函数声明等
2、%pure-parser:声明这个语法分析器是纯语法分析器,可以实现可冲入。同时需要下面配合使用,即为了调用纯词法分析器flex,需要scanner实例,即需要传入这个参数.通过定义%parse-param 即可给yyparse()函数传入参数。定义%lex-param.即可把parse-param中定义的参数传递给yylex.:
%parse-param {core_yyscan_t yyscanner}
%lex-param {core_yyscan_t yyscanner}
3、%expect 0,意思是不希望有冲突
4、%name-prefix="base_yy"代表生成的函数和变量名从yy变成base_yy,同flex,为了在一个产品里使用多个语法分析器,分析不同的数据类
5、%locations声明使用位置信息
6、%union{}定义yylval类型,在flex通过yylval返回匹配的值
7、%type<union中的变量名>,比如%type<node>定义非终结符和union中变量的绑定。在规则段中“:”左边是非终结符,右边是终结符和非终结符。Bison中每个符号(终结符和非终结符)都有一个值与之对应,默认是一个整数值,为了扩展,可以定义union类型。$$代表非终结符的值,这里的意思是将$$和union中某一个变量绑定。
8、%token<union中的变量名>终结符,比如%token<keyword>是指一个关键字。定义终结符和union中变量的绑定。可以在flex中之间通过yylval->(union中变量名)返回匹配值
9、%nonassoc symbol,比如%nonassoc SET,用于定义优先级。同%prec联合使用可以定义某个表达式的优先级,例如:

10、%left表示操作符左匹配,例如%left AND,A AND B AND C,表示(A AND B)AND C
11、%right表示操作符右匹配
12、优先级通过由低到高,例如

2.2 认识gram.y:规则段
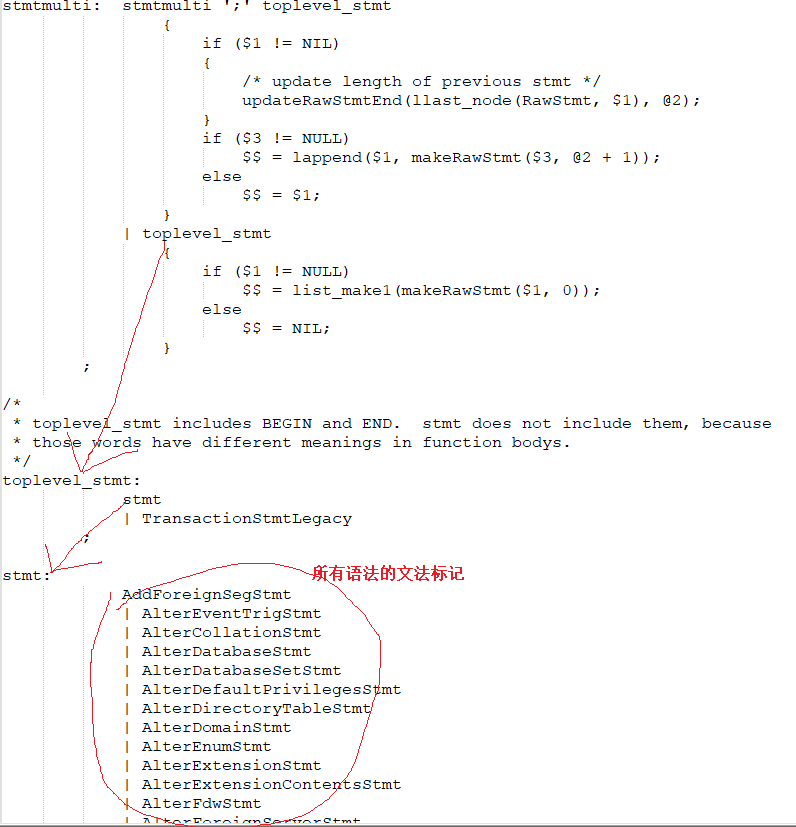
1、规则段的右边表示非终结符,如下图,冒号左边stmtmulti是一个非终结符,可以根据下文的stmtmulti的文法进一步递归,$1表示冒号右边第一个变量,即stmtmulti;使用$$便是parse_toplevel,也就是它的返回值。stmtmulti后面的{}表示匹配stmtulti后需要做的动作,即一系列内容归约成stmtmulti后,对应需要做的动作。括号后面的“;”表示该规则的结束符

2、通过@来获取终结符在规则中的位置信息. 例如:上面的规则中@2,代表的是’;’对应的位置信息。这个位置信息是flex设置的

3、如上入,|表示或的关系
4、如1步骤所示,解析器文法规则入口parse_toplevel,然后如下图所示,到stmt可以找到匹配的哪些文法:下图中可以看到它包括所有SQL语句