






在数据库系统中,物化视图是一个关键概念。本文将聚焦于物化视图的定义、优势、最佳实践,以及在主流数据库中的实现方式。本篇文章是基础概念系列的第二篇,在第一篇文章中,我们介绍了变更数据捕获(CDC),它帮助系统高效感知数据变更。而物化视图则提供了一种缓存查询结果的方法,以减少计算开销。
由于物化视图建立在视图(view)的概念之上,我们首先来探讨什么是视图。

什么是视图
SELECT p.product_name, SUM(o.quantity) AS total_quantity
FROM products p
JOIN orders o ON p.product_id = o.product_id
GROUP BY p.product_name
ORDER BY total_quantity DESC
LIMIT 5;复制
第二天,Dan 出于好奇又运行了一次查询,接下来的几天他也重复执行了这条查询。他意识到这已成为日常任务。于是,他将查询语句保存在笔记应用中,以便随时调用。
与此同时,Dan 的同事 Debra 也在进行类似的分析,她编写的查询与 Dan 完全相同。
一天早上,Dan 和 Debra 在咖啡时间聊起这件事,发现他们一直在重复执行相同的查询。
这时,数据库管理员 Dave 加入了讨论。他建议,对于经常使用的查询,创建视图会更方便。
CREATE VIEW best_sellers_5 AS
SELECT p.product_name, SUM(o.quantity) AS total_quantity
FROM products p
JOIN orders o ON p.product_id = o.product_id
GROUP BY p.product_name
ORDER BY total_quantity DESC
LIMIT 5;复制
Dave 解释道,视图可以将查询逻辑永久存储在数据库中。现在,任何人需要查询畅销商品时,只需执行以下简单查询:
SELECT * FROM best_sellers_5;复制
这条 SELECT
语句会在后台执行原始复杂查询,并返回结果。
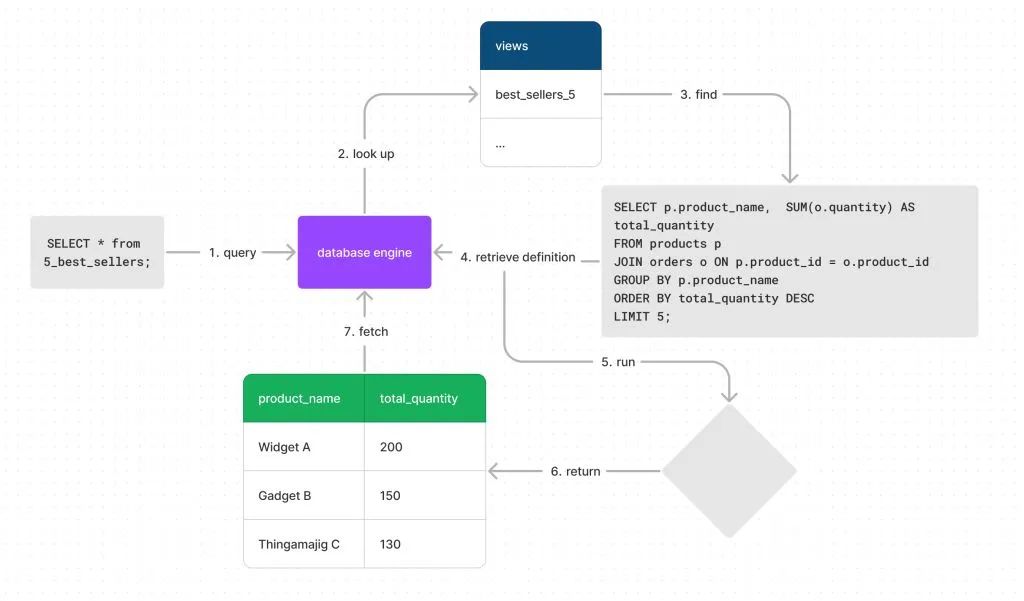
查询该视图时的流程进展|图源:RW
本质上,这与直接运行原始查询没有区别,但无需手动输入完整查询语句。
Dan 现在理解了视图的概念。他和 Debra 依赖 best_sellers_5 视图来获取前五畅销商品。然而,随着公司产品种类增多、销售量增长,他们发现查询结果的返回时间变长了,比如需要 5 分钟才能得到结果。他们将这个问题告诉了 Dave。
Dave 提议说:“为什么不创建物化视图 (Materialized View)呢?”

物化视图中的“物化”是什么意思?
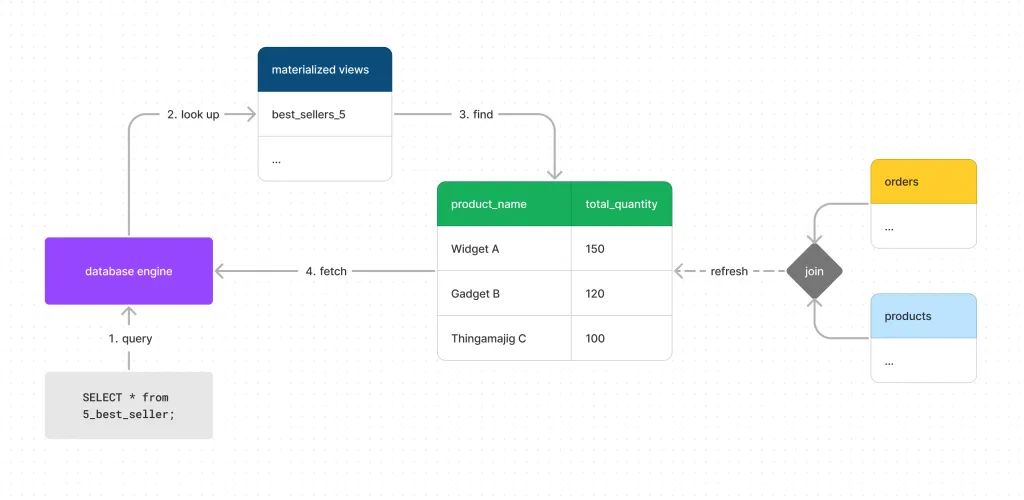
以 best_sellers_5 视图为例。“如果你创建一个同名的物化视图,那么实际上得到的是一个包含预计算结果的表。”
“查询物化视图时,数据库不会重新执行查询,而是直接返回存储在表中的计算结果。因此,查询速度会显著提高。”

查询 best_sellers_5 物化视图时的示意图|图源:RW
Dave 运行了查询,仅用了 5 秒钟就返回了结果,Dan 和 Debra 都对此印象深刻。
但 Debra 突然想到一个问题:“如果数据库只是从表中获取预计算的结果,那数据还是最新的吗?”
物化视图的结果有多新鲜?
Dave 解释道,这取决于物化视图的刷新机制。
物化视图的数据需要在底层表发生变化后进行刷新,而刷新频率决定了数据的新鲜度。
如果 products
表和 orders
表在昨天发生了变化,但物化视图没有刷新,那么查询得到的结果仍然是上次刷新时的内容(比如昨天的数据)。
物化视图的刷新机制|图源:RW
如果基础表每天更新一次,而物化视图每两天刷新一次,那么查询结果就可能滞后一天。
不同数据库的刷新机制不同,有些支持手动刷新,有些可以设置自动刷新。
Dan 和 Debra 想知道:
除了查询速度快,物化视图还有哪些优势? 物化视图是否适用于所有场景? 在使用物化视图时需要注意什么?
于是 Dave 耐心地整理了一份总结如下:
何时使用物化视图?
需要对大量数据重复执行相同的复杂查询。 需要较低的端到端查询延迟,但对最新数据的需求不高(适用于传统数据库,不包括流式数据库)。 存储空间充足。
何时不适合使用物化视图?
临时或不频繁查询,这时维护物化视图的成本可能大于收益。 存储空间受限。 数据更新频繁,物化视图需要频繁刷新,可能导致额外的开销和成本。但这并非绝对情况。如果使用增量计算和高效的存储方案,可以显著降低开销。例如,RisingWave 在物化视图的实现中就采用了增量计算优化。

使用物化视图可以显著提高复杂查询的性能,但这并不是唯一的优化手段。索引(Indexes)是另一种基础的数据库功能,能够大幅提高查询速度。了解索引和物化视图的不同,对于选择合适的优化策略至关重要。
索引:加速数据查找
类似书籍的索引,数据库里使用索引来存储表中特定列的排序副本,并指向完整的行。通过这种方式,数据库可以快速找到符合查询条件的行(例如,WHERE customer_id = 123
),无需扫描整个表。索引适用于以下场景:
根据特定列值快速查找少量数据。 经常进行点查找(例如查找单行数据)。 在表之间进行连接时,需要加速查询。 经常按照某列对数据进行排序。 需要确保某列或列组合的唯一性。
物化视图:预计算复杂查询
物化视图存储的是查询的预计算结果,这对涉及聚合、连接或对大数据集进行其他计算的复杂查询尤其有帮助。物化视图适用于以下场景:
涉及 GROUP BY
、SUM
、AVG
、COUNT
等聚合操作的复杂查询,并且查询频繁执行时。查询需要连接多个大型表。 有复杂计算或数据转换的需求。 需要创建数据的汇总版本进行报告。 需要减少重复执行昂贵查询操作的计算成本。
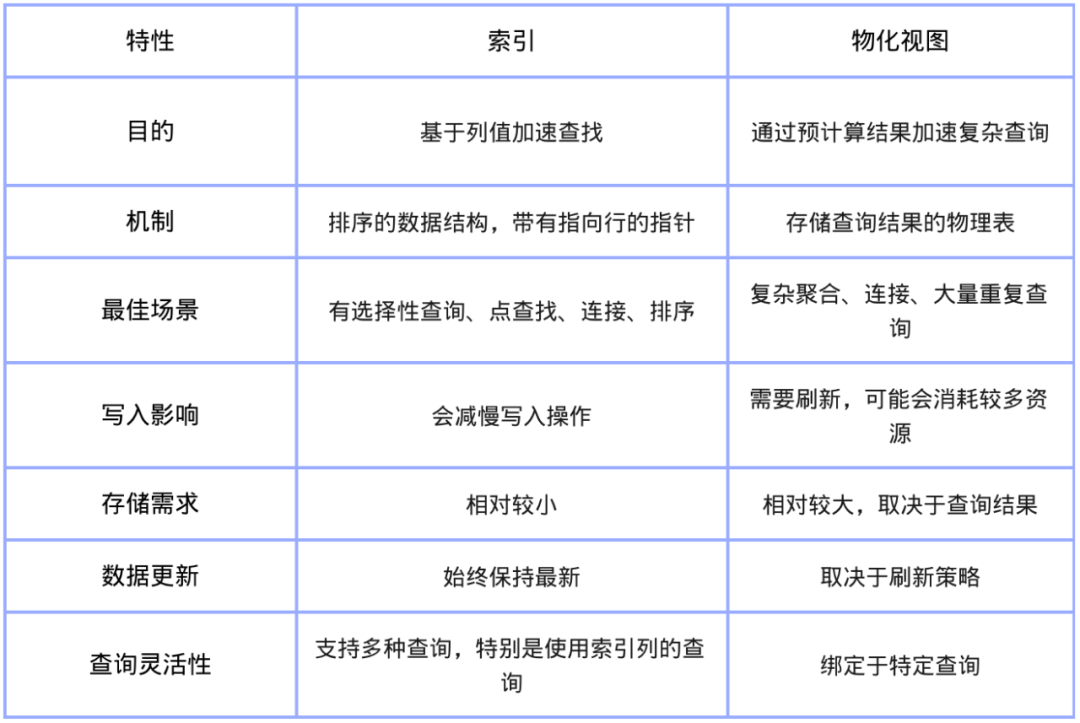
二者主要区别|图源:RW

主流数据库中 MV 支持情况
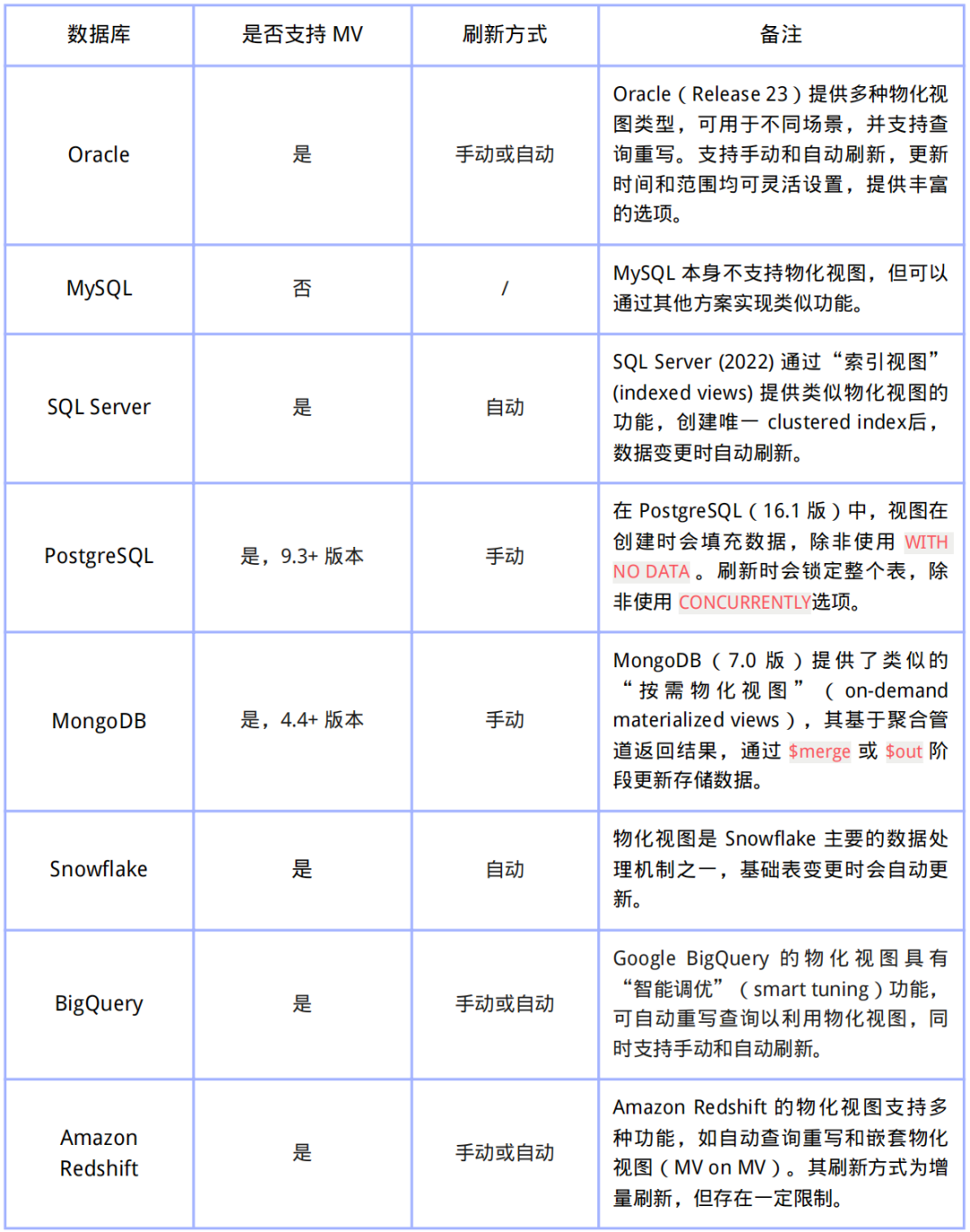

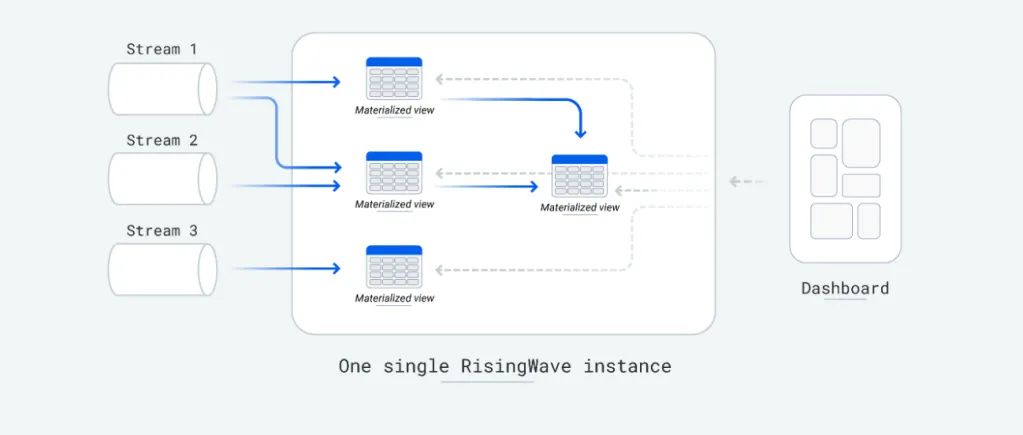
作为一款流式数据库,RisingWave 以独特的方式利用物化视图,为警告、监控、交易等对低延迟有严格要求的应用提供持续在线的数据分析和转换能力。
基于表和流的物化视图
在大多数数据库中,物化视图只能基于表创建,这意味着流数据必须先经过 ETL 处理并存入数据库。而在 RisingWave 中,物化视图既可以基于表创建,也可以直接基于 Streams(通过 source)创建。如果无需存储原始流数据,用户可以直接选取所需字段,执行转换,并仅存储处理后的结果。
自动刷新与增量计算
RisingWave 的物化视图无需按照预设间隔或手动刷新,而是在接收到新事件时自动刷新,并采用增量计算模式。物化视图创建后,RisingWave 引擎会实时监听新的相关数据,并仅对新增数据进行计算,因此计算开销极低。此外,RisingWave 提供快照读一致性(snapshot read consistency),确保在同一数据库中查询物化视图和表时,查询结果在表与物化视图之间保持一致。
物化视图上的物化视图
在数据分析中,某些指标往往是由其他指标派生而来的。在这种情况下,没有必要每次都从头计算派生指标。RisingWave 支持在现有物化视图的基础上构建新的物化视图,避免重复计算。
在流处理场景下,Kafka 通常用作不同数据处理逻辑之间的中间层。而 RisingWave 的 MV-on-MV(物化视图之上的物化视图)特性,可省去跨系统数据管道的复杂性,使数据转换逻辑更为流畅。
本文深入探讨了数据库中物化视图的概念,并与另一基础功能“索引”进行了对比,同时盘点了主流系统中 MV 的实现方式。最后,我们还分析了 RisingWave 如何支持实时物化视图,以及这一特性为用户带来的独特优势。
如果你对 RisingWave 的物化视图功能感兴趣,不妨点击阅读原文立即开始体验。
关于 RisingWave


技术内幕
👇 点击阅读原文,立即体验 RisingWave!
