




PostgreSQL 流复制的速度非常快。它基于事务日志(WAL)和崩溃恢复机制。这项工作是主服务器为了安全运行必须处理的,因此对主服务器的额外开销几乎可以忽略不计。唯一的额外工作是将 WAL 推送到网络上,而不仅仅是写入磁盘。
在副本端,应用过程也非常轻量级,因为事务日志包含物理层的更改。当数据库系统接收到更新时,诸如查找行、为新版本定位空间、在索引中找到正确的位置插入新引用,以及在必要时拆分页面等任务,都由主服务器完成。这些工作被编码在事务日志流中,作为对特定页面的修改。回放过程只需要找到页面并重放修改,因此不需要“思考”。
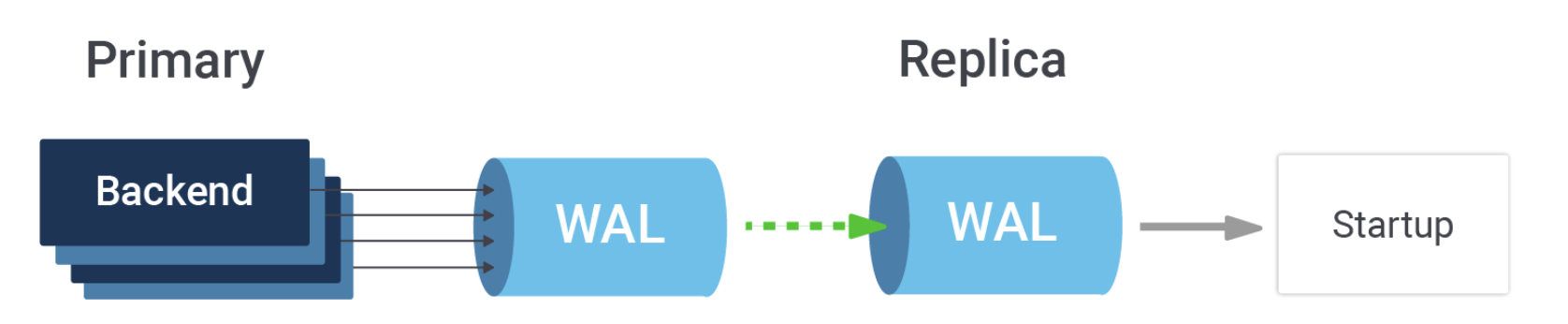
然而,这里存在一个问题。在主服务器端,事务日志的排序经过了高度优化。每个数据库后端都在本地内存中准备它们的事务日志记录,然后在 WAL 中为其预留空间,然后将其复制到共享内存缓冲区。空间预留是唯一顺序进行的操作,其他操作都可以并发进行。顺序部分只是在自旋锁下递增一个位置指针——这已经尽可能快了。因此,在主服务器端,我们有大量后端通过写入事务运行,将完成的工作编码为事务日志,并并行插入。在副本端,只有一个进程在应用所有这些工作。它的任务更简单,但在某种规模下,更多的工作线程可能会压倒它。
寻找极限
那么,复制会在哪里落后呢?正如数据库中的所有事情一样,答案是“视情况”。不同的工作负载有不同的特性。如果修改的页面工作集不适合缓存,回放过程就需要去获取它们。在检查点周期中,回放可以跳过第一次修改的读取,因为主服务器会在 WAL 中包含页面的副本(全页图像,或 FPI),以便从部分写入中恢复。如果在检查点周期中多次修改相同的页面,主服务器将生成大量小的 WAL 记录。如果每个周期只修改一次页面,由于 FPI 的存在,每个事务的 WAL 使用量可能会大两个数量级。
为了尝试量化交叉点,我进行了一次小测试。我初始化了一个 8GB 的 pgbench 数据库,它适合放入共享缓冲区,然后我设置了 WAL 归档并进行了备份。接下来,我运行了 30 分钟的 pgbench,将 synchronous_commit 设置为 off 以生成一些 WAL。在一个 24 线程的工作站上,这产生了 70GB 的 WAL,包含 6600 万次 pgbench 事务,平均速度为每秒 36.6k tps。最后,我配置 PostgreSQL 在备份上运行恢复。这个恢复能够在 372 秒内完成,即每秒 177k tps。
理论上,一个 120 线程的服务器,以尽可能快的速度运行更新——不等待提交写入磁盘——将能够超过其副本。请注意,这是使用 pgbench 完成的,pgbench 是一个臭名昭著的写入密集型和简单的基准测试。在一个更现实的工作负载中,交叉点会显著更高,因为主服务器上有更多的工作要做。这是有益的,因为我们不想接近那个点,否则操作集群就像走在悬崖边上。
推动极限
然而,我们可以在副本端引入并发吗?这是可能的,但仅限于一定程度。WAL 记录的排序隐式地编码了记录之间的依赖关系。以一个简单的例子来说,对同一个块的两次修改必须以它们生成的顺序应用,才能得到相同的结果。还有更复杂的依赖关系——事务提交不能在该事务的所有修改之前重放,索引指针不能在它指向的行被重放之前添加。如果我们忽略这些依赖关系,副本上运行的查询将看到不正确的结果,甚至可能会使数据库崩溃。
有帮助的是,这些依赖关系适用于实际的修改本身。应用过程中非必要的责任可以被剥离出来并行运行,让应用过程专注于修改本身。PostgreSQL 已经在这方面取得了一些改进。
从版本 15 开始,回放过程会在 WAL 流中向前看,解码引用的块号,尝试查找块,如果它缺失,则指示操作系统将其预取到页面缓存中。所有这些工作仍然作为启动过程的一部分进行,因此那里没有获得并行性。然而,预取命令确保在回放过程处理前一条记录时,任何必要的磁盘读取都会发生。并且更重要的是,可以同时有多个这样的读取操作。预读距离和同时进行的 I/O 数量可以通过 wal_decode_buffer_size 和 maintenance_io_concurrency 参数设置。
当期待已久的 PostgreSQL 异步 I/O 补丁落地时,我们可以更进一步,直接将读取操作发起到共享缓冲区,而不仅仅是预取到操作系统页面缓存中。
上述步骤有助于 I/O,尽管非常重要,但这并不是上面完全 CPU 绑定的重放基准测试中的问题。CPU 不再变得更快,因此如果我们想提高速度,我们需要减少工作量。那么,重放过程到底做了什么?为了理解这一点,我从该过程中捕获了一些 perf 配置文件并构建了一些火焰图。
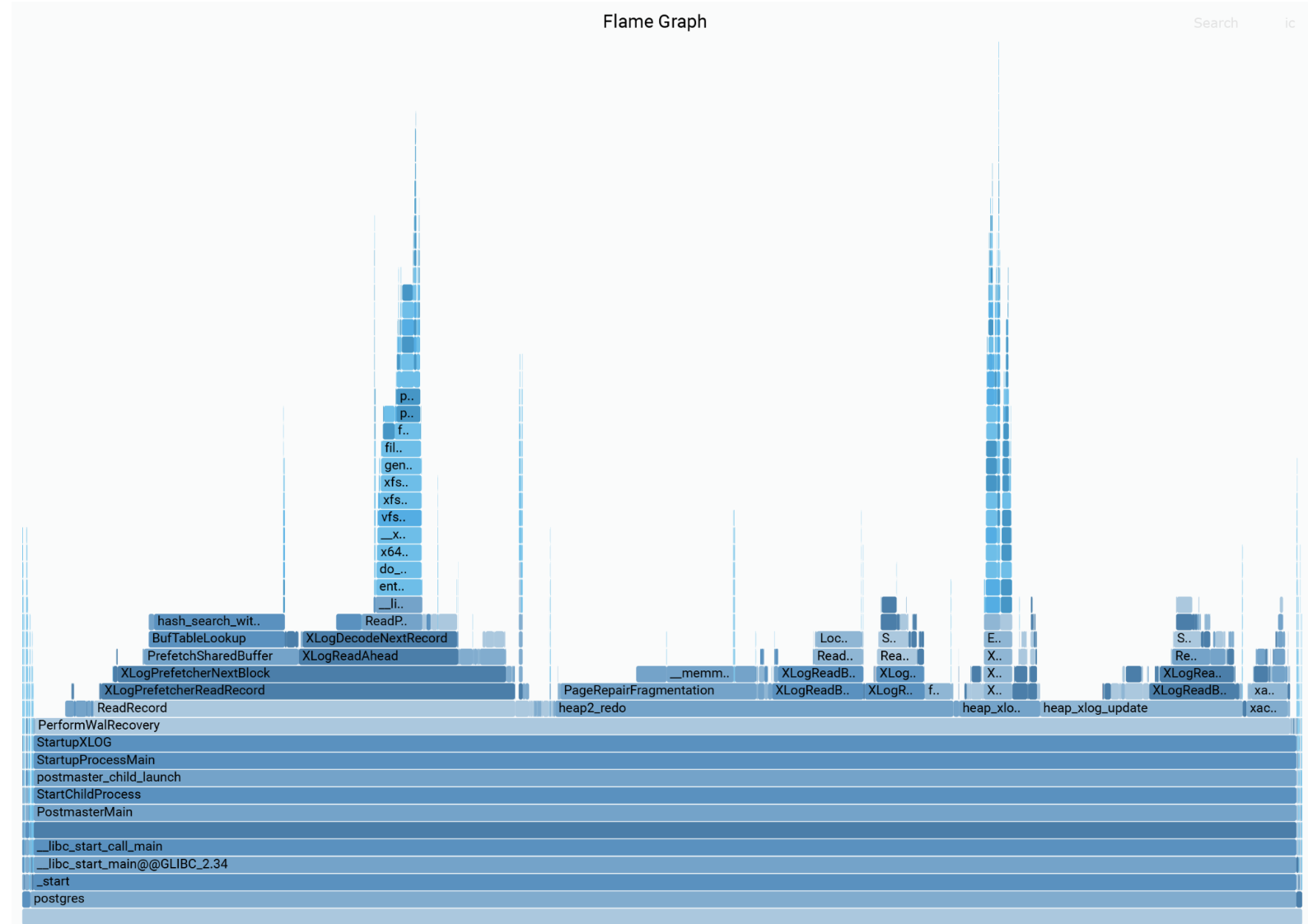
令人惊讶的是,被认为是实际重放工作的部分似乎是总工作量中的少数部分。最大的部分涉及读取 WAL 和解码其中的页面引用,然后在缓存中查找这些页面,并将它们固定,以防止它们在使用时被逐出。所有这些工作都可以与重放循环并行进行。例如,一个单独的预读进程可以处理这些任务,确保重放过程接收到一个队列,其中包含已关联缓存引用的事务日志记录,准备好应用。
如果我们做了所有这些,看起来我们可以将墙向前推几次。可能达到每秒 50 万次事务。在途中,肯定会有其他挑战。以这样的速度,两次清理之间的间隔将以分钟而不是天来衡量。但到了那时,我们已经达到了单个事务日志的极限,PostgreSQL 将需要开始采用分布式数据库的扩展技术。那是另一个话题了。
原文地址:https://www.cybertec-postgresql.com/en/end-of-the-road-for-postgresql-streaming-replication/
原文作者:Ants Aasma
