




按照OceanBase官网的描述,4.3.5 是面向 AP 场景第一个 LTS 版本。在 V4.3.4 的基础上,新版本继续完善产品能力,新增了对嵌套物化视图的支持,并完善了全文索引和向量索引功能。
从官方文档对嵌套物化视图的描述,之前版本中,只能支持面向表的物化视图,而从此版本之后,允许用户基于已有的物化视图的查询,继续创建新的物化视图,也就是我们俗称的嵌套物化视图。可能会有朋友疑惑,这个功能的意义在哪里。而实际上,该功能在实际应用中,是很有价值的。本文即将以总账系统作为场景,来做一个替换方案。
场景描述
按照专业描述,总账系统是企业财务管理系统的核心模块,它用于集中记录和汇总企业所有的财务交易和会计信息。在一个公司内,是必不可少的核心业务系统之一。因为其核心的原因,伴随公司业务规模的提升,总账系统无疑要面对很大的压力并且会出现性能瓶颈。
原架构:
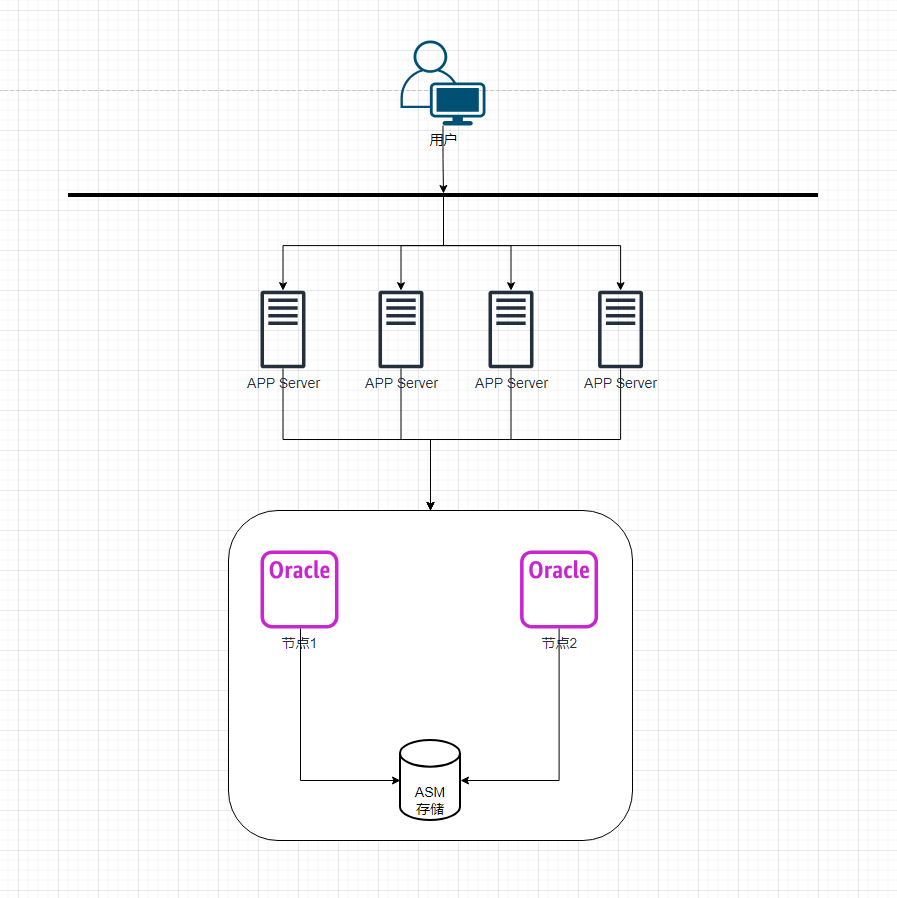
数据库服务器:64c/256GB共2台
数据库版本:Oracle RAC 11.2.0.4
应用服务器:16c/64GB共4台
两个核心业务:
- 业务1,记账。关联上千家实体的财务交易和会计信息。而上千家实体包含了商业综合体、影院、酒店、儿童娱乐、餐饮等多个类型。主要的业务高峰期在周末,周一到周四相对较少。
- 业务2,报表。门店粒度与全局,需要每个日、月、年提供报表,包含总金额、分类账目等等,其中日报表是第二个工作日,月报表是下个月第一周,全局报表第二年第一个月。
业务2,即报表部分,已经使用了Oracle的物化视图来计算各类会计科目和凭证,并且以日、月、总账三个维度创建了物化视图,并且定期刷新。
但是仍然存在如下问题:
- 随着各类实体数量的增长,日月总每个维度的数据量都越来越大,报表计算的时长不断增加。月度年度报表集中生成时,会出现数据库的性能瓶颈,同时也会有记账和报表资源征用的情况。
- 硬件扩容因为Oracle 11g RAC的特性,准备工作较多,周期较长。为了稳妥起见,曾经试图以离线方式进行。
解决思路
首先,我们来分析一下,原有的Oracle RAC架构下,几个问题的根源在哪里。
- 物化视图计算的时间越来越久,既有实体数量增加带来的数据量增多,同时还有就是所有业务都跑在一个实例下,资源存在争用。在月初或年初做上一个周期的集中报表计算时,就会占用一部分本来用于记账的系统资源,既有CPU或者内存,也有存储IO。
- 非Exadata版的Oracle采用的是行存,在面对大规模报表计算时,相比列存性能劣势明显,而使用Exadata可以解决该问题,但是成本会非常的高,可能超出了公司预算。
- Oracle RAC虽然官方宣传可以在线扩缩容,但是实际操作中,在岗的DBA没有在生产环境实操过,稳妥起见,都是以业务停机的方式增加节点。
所以,几个问题我们来尝试着用OceanBase解决。
问题1,资源争用的情况。这个问题实际上可以用多租户与zone绑定的特性来解决。我们设置两个租户,tenant1用来存放总账系统的所有基表,只负责所有的记账。tenant2用来存放所有的物化视图,而且两个租户跑在不同的zone上,彻底实现资源隔离。
问题2,在OceanBase 4.3.5里,物化视图可以支持行和列两种存储格式。当然,在这里,也不会完全都是用列存格式的物化视图,而是通过嵌套物化视图的方式,来分层解决问题,具体问题具体分析。目标是优化每一个层级的报表。
问题3,在线扩容。作为分布式数据库,OceanBase在线添加OBServer的模式来解决。需要注意的是,因为增加节点要带来存储的写入,刚添加完的OBServer需要一段时间完成数据同步。
除此之外,不同的zone,还可以使用不同性能的存储,一定程度上可以做到对成本的更精细管理和分配。
那么我来大致画一个架构图,在这里,我们先不考虑异地容灾的问题,有关异地容灾和高可用的设计,以及多地多活,争取再用一篇文章来展开,因为这里还涉及到一个问题,如何数据分片存放到不同地域的机房,方便各个实体按照不同地域机房来访问数据:
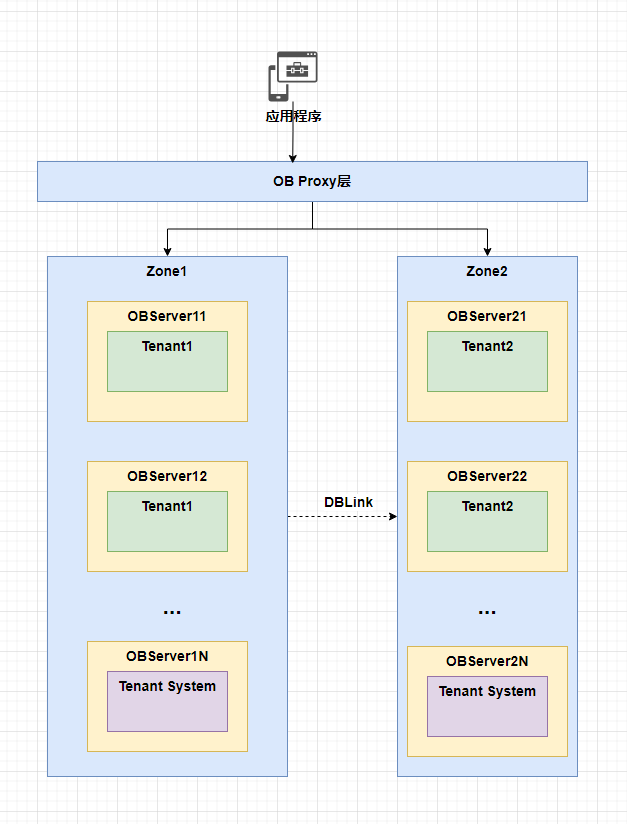
需要注意的是,这里虚线的DBLink只是一个示意,意思是Tenant2通过DBLink的方式从Tenant1单向同步数据。OBServer1开头的服务器,使用高性能的SSD或Nvme,OBServer2开头的服务器,可以选择相对一般的存储。
嵌套物化视图
接下来就是嵌套物化视图的使用,这也是整个架构要完成的最后一个重要任务。
在总账系统中,包含的基表种类繁多,既有科目表、凭证表、明细表、总账表、辅助核算表,以及最后生成报表的报表表,除了报表表,其他的类型表都是OLTP业务类型相关,实际更适合使用行存。其中复杂的会计计算以及勾稽关系,以我的财务知识储备是讲不明白的,为了方便大家理解,以及对嵌套物化视图的解决问题思路的讲解,我们引入一个总账表,字段表结构都是尽量简化。
CREATE TABLE ledger_entries (
entry_id BIGINT PRIMARY KEY,
store_id INT,
account_code VARCHAR(50),
amount DECIMAL(18,2),
entry_date DATE,
-- 其他字段...
PARTITION BY HASH(store_id) PARTITIONS 32;
);这里的分区数目,可以根据具体实体的数量调整,32只是一个例子。因为总账表每天面对高并发的写入,因此该表使用的存储引擎是行存。
而最早的报表表,要对总账表做聚合,它的DDL如下,通过复杂的会计计算,将各类会计数据写入,这张表在我们的新方案里将会被替换掉:
CREATE TABLE financial_reports_col (
report_period DATE,
store_id INT,
account_code VARCHAR(50),
total_amount DECIMAL(18,2),
-- 其他聚合指标...
PRIMARY KEY (report_period, store_id, account_code)
) ; -- 使用列式存储上面两张表都在Tenant1,接下来我们开始在Tenant2中建立物化视图。
第一层物化视图,实体-日粒度,用于统计每个门店每天的各类指标。因为涉及到较频繁的数据读写,因此使用的存储引擎是行存。
CREATE MATERIALIZED VIEW mv_daily_store_aggREFRESH FAST START WITH current_date NEXT current_date + INTERVAL '60' MINUTE
PARTITION BY HASH(store_id)
AS
SELECT
entry_date AS report_date,
store_id,
account_code,
SUM(amount) AS daily_total
FROM ledger_entries@dblink1
GROUP BY entry_date, store_id, account_code;考虑到日粒度需要每天频繁刷新,我们要给它更新增量的刷新策略,每个小时刷新一次
第二层物化视图,实体-月粒度,
CREATE MATERIALIZED VIEW mv_monthly_store_aggREFRESH COMPLETE START WITH current_date NEXT current_date + 1
COLUMN_FORMAT = COLUMNAR
AS
SELECT
DATE_TRUNC('MONTH', report_date) AS report_month,
store_id,
account_code,
SUM(daily_total) AS monthly_total
FROM mv_daily_store_agg
GROUP BY DATE_TRUNC('MONTH', report_date), store_id, account_code;第二层视图是每天从日粒度全量刷新到,因为写入频率不高,所以使用了列存,每天刷新一次。
第三层物化视图,总视图
CREATE MATERIALIZED VIEW mv_final_reportREFRESH COMPLETE START WITH current_date NEXT current_date + 1
COLUMN_FORMAT = COLUMNAR
AS
SELECT
report_month,
account_code,
SUM(monthly_total) AS total
FROM mv_monthly_store_agg
GROUP BY report_month, account_code;这一层依旧是列存,而且只从月度视图中获取数据,全量模式,每天刷新一次。
这样就可以通过查询三层视图,分别查询每个门店在日、月、总三个层级的视图。日粒度每天每个小时自动刷新,如果配置足够好,可以考虑放到更高的频率,比如10分钟等等。月粒度和总账,每天全量刷新。之所以这么做,是出于财务系统对数据一致性的严格考虑。如果说,仅仅是增量刷新,在某个实体或某一天出现数据不一致的情况,那么有可能出现月度数据和总账数据同样是脏数据,而且需要层层回溯的的场景。全量刷新如果出现上一层某一天或某个实体出现数据不准确,在完成日粒度刷新后,重新依次全量刷新月度和总账即可获得正确的数据。(这些都是一线财务人员教授的血泪教训)
总结
如果按照如上方案来替换原有的Oracle方案,那么优缺点分别如下。
优点:
1. 降低了硬件成本。依托列式存储带来的性能提升,无需采购昂贵的Exadata,以增加节点的方式,即可将物化视图的性能大幅提升。
2. 尽最大可能避免资源争用。因为通过不同的zone来跑不同的租户,不同租户之间硬件上完全隔离,尽最大可能避免了同一个实例下的资源争用。
3. 扩展性更好。OceanBase作为原生分布式,扩缩容的灵活性都很不错,如果后续因为实体总量的变化带来数据量的增加,可以通过增加OBServer的方式来扩展。
缺点:
1. 维护成本。从Exadata的双节点RAC,到OceanBase的多zone多租户多节点,需要维护的内容更多,而且三层物化视图,在追溯数据的时候,同样也需要一些时间和学习成本。
2. 锁争用。原有的架构仅仅涉及到从表中获取数据,而现在既有对基表的写入,又有物化视图的刷新,是否会带来锁争用,需要实际生产验证。
最后关于OceanBase的嵌套物化视图,我想说的是,这是个很不错的特性,结合行存列存的使用,实际上除了在我提及的场景下,数仓的分层也是一个很不错的场景。比如ODS层行存每天定时刷新,而往上的DWD和DWS,可以考虑使用列存,按照实际对数仓计算的要求,来选择增量刷新还是全量刷新,每一个视图根据需求来定制刷新规则,可以实现数仓流式更新和批量更新的两种场景。
如果时间来得及,我争取在下个月将这个架构剩下部分再用一篇文章展开描述,包含多地多活、异地容灾等要素。水平有限,如果有对OceanBase的理解不当或描述不当,还请及时指正。
