




国产大模型DeepSeek暴击全球算力股,英伟达股价狂泻17%,单日市值蒸发近6000亿美元,创下美股史上最大规模的单日市值蒸发纪录。
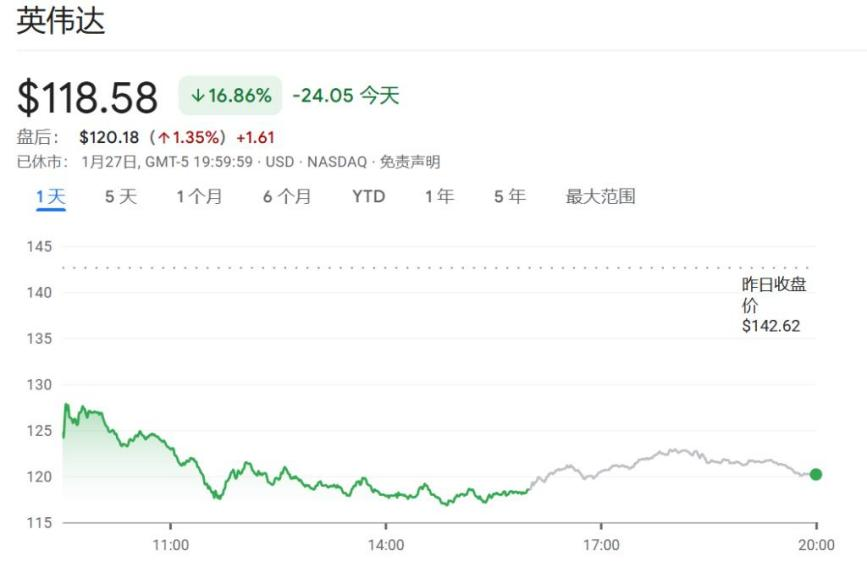
春节期间,国产大模型DeepSeek-R1横空出世,证明了用更低的成本、更少的算力需求,就可以实现世界一流的模型性能水平。DeepSeek R1模型仅花费约600万美元就完成了训练,约为美国和欧盟同类大语言模型成本的1/50。在某些方面,该模型比OpenAI的o1模型要好得多。更重要的是,R1的运营成本仅为OpenAI通常对计算密集型输出收取的费用的3%。
这意味着,过去在硅谷被视为“唯有斥巨资拼算力才可达顶尖”的大模型研发模式,可能并不是唯一解。
投资者猛然意识到,这种“降本增效”的技术路径或许会动摇硅谷多年构筑的 AI 护城河,引发对现有产业估值和商业逻辑的集体反思。
然而,DeepSeek是否让算力焦虑消失?
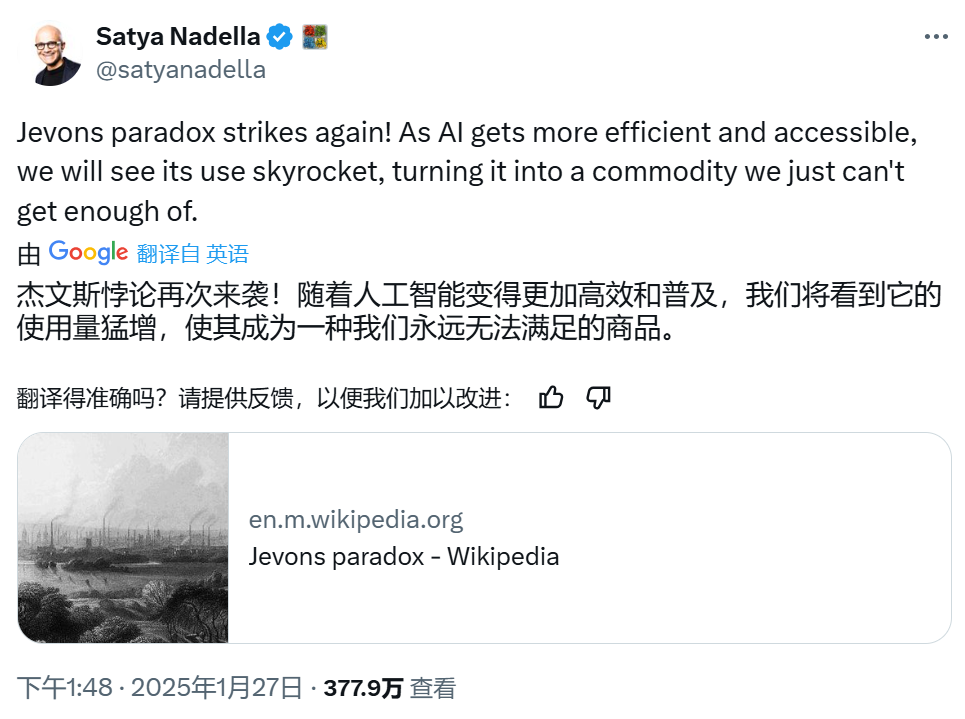
微软CEO纳拉德引用了160年前的经济学概念来解答了这个问题。
杰文斯悖论,由19世纪的英国经济学家威廉·斯坦利·杰文斯提出,主要讨论了技术进步(特别是能源效率的提升)对资源消耗和经济发展可能产生的非直观影响。
举一个非常简单的例子:随着汽车技术的不断提升,发动机的热效率不断提高,变得越来越省油,但由于效率提高使得用车成本降低,人们会买更多的车、开更远的路,最后反而使得石油的消耗量变大。
也就是说,技术进步提高了资源使用效率,效率提高降低了资源使用成本,成本下降刺激了资源需求的增长,需求增长可能超过效率提升带来的节约,最终导致资源总消耗增加。

对应地,AI 成本的急剧下降,可能刺激更多企业、机构部署大模型,从而整体算力需求不降反升。
因此,DeepSeek没能让算力焦虑消失。2025 年谷歌、微软、Meta和亚马逊四巨头都在算力上继续增加投入。
谷歌:2025年的资本开支目标为750亿美元,相比2024年增加了42%;
微软:2025财年(财年截至6月份)将在人工智能数据中心上投入800亿美元; Meta:2025年的资本开支预算是650亿美元,相较于2024年增长了66%; 亚马逊:2025年的资本开支将达到约1000-1050亿美元,比去年的830亿美元增加了24%。
亚马逊首席执行官Andy Jassy表示,推理成本的减少,不意味着总支出会下降,“ 实际情况并非如此,我们在云计算领域经历过类似情形 ”。
多家投行分析师,如Cantor Fitzgerald等,将这一理论应用到DeepSeek R1模型和人工智能领域的民主化趋势上。他们指出,随着人工智能技术的更加高效和易用,其使用将会激增,成为“我们永远无法满足的商品”,这与杰文斯悖论的观点相吻合。
天云数据认为:我们一方面需要深刻理解资源边际成本效应对新兴产业发展的巨大影响和推动;另一方面,相比担心算力过剩的问题,我们更应该关心的是在算力和效率都满足的情况下,有没有可以用来训练的优质数据。
要想连接数据算力优势,必须建设核心数据资产。
研究机构Epoch估计,机器学习可能会在2026年前耗尽所有“高质量语言数据”。产业应尽快推动算力基础设施从传统IDC向智能算力中心演进,实现从单一供给到多元异构协同的质的飞跃。
天云数据CEO雷涛2024年在接受北京日报采访时就表示:今天的数据不能满足明天的AI使用,明天的AI在自己生产数据资源。

去年特斯拉的发布会让我们看见数据飞轮的价值。数字经济时代,数据飞轮已成为关键生产要素乃至是最具战略意义的资产。精调里很多模型在SFT阶段更强调数据工程,而不是训练方法精确的小数据,一些顶级的模型仅用6K的数据来做精调,而且这些数据质量还会涉及到面向存储的数据标准规范。
这就是合成数据的概念。很多人认为合成数据是假数据、是虚拟的、空数据或者说是造出来的数据,但事实上,合成数据不是假数据,是已知的数据通过确定的逻辑生产出来的数据。
百模大站过后,为什么英伟达发布的大模型还可以挤到第一阵营?英伟达模型训练使用了98%的合成数据。无独有偶,特斯拉也是用合成数据获得具身机器人的智能。
硬件芯片所遵循的摩尔定律还是一个线性增长逻辑,但生成式合成数据遵循的却是幂律指数型增长,只有抓住数据工程的幂律才能超越硬件的发展速度。
