





本文字数:8411;估计阅读时间:22 分钟

Meetup活动
ClickHouse Shanghai User Group第2届 Meetup 将于本周六举办,火热报名中,详见文末海报!


回顾 2024 年,有一项技术始终引人注目:Apache Iceberg,更广义地说,是湖仓架构。这一趋势在多个行业动态中得到了印证,比如 Databricks 收购了 Tabular,AWS 在 Re:Invent 期间发布了 Amazon S3 Tables,GCP 投资优化 Iceberg 与 BigQuery/BigLake 的集成,以及 Snowflake 通过开发 Polaris 加强对 Iceberg 的支持。
这些动态让人们不禁思考:
你的数据湖和湖仓如何与 ClickHouse 集成?
在这个领域,ClickHouse 在 2025 年有哪些计划?
本篇博客将围绕这两个问题展开讨论,并结合我们在与用户合作过程中观察到的架构案例。同时,我们还会分享一些工程团队的实现细节,最后介绍 2025 年的发展规划!
如果你对数据湖、湖仓和 ClickHouse 感兴趣,并希望成为设计合作伙伴、提前体验我们即将推出的功能,或了解更多未来计划,请填写此表单【https://clickhouse.com/cloud/data-lakehouse-waitlist】,我们将尽快与你联系!
如果你查看 ClickHouse 代码仓库中最早的 pull request,就会发现它非常注重与外部系统的集成。随着时间的推移,ClickHouse 已经发展成连接数据湖与数据仓库的强大桥梁,兼容 60 多种输入和输出格式,并支持队列、数据库和对象存储。这种灵活性让用户既能享受数据湖的弹性,又能保持实时查询的高性能。
如今,大多数 ClickHouse 用户都在使用这种方式,其中 S3 是最常见的数据源,既可用于数据加载,也可用于临时查询。功能如 s3Cluster 以及最近推出的 S3Queue(同时支持 GCS 和 Azure)让这一集成更加流畅,使 ClickHouse 能够直接查询存储中的数据进行探索性分析,或高效摄取数据以支持高性能分析。
随着越来越多的企业和团队重新审视其数据湖和数据仓库战略,有些公司已经在使用 ClickHouse,而另一些则刚刚开始探索它与湖仓架构的契合点。
在数据湖和湖仓架构中,ClickHouse 主要用于以下三类场景:
从数据湖/湖仓加载数据到 ClickHouse 对数据湖/湖仓进行临时查询和联邦查询 高频查询数据湖/湖仓
从数据湖加载数据到 ClickHouse
如前所述,ClickHouse 最常用的集成功能之一是 s3Cluster 和 s3Queue 表函数,以及它们在 Google Cloud 和 Azure Blob Storage 上的对应版本。用户通常使用这些函数将数据加载到 ClickHouse,既支持一次性加载(s3Cluster),也支持增量加载(s3Queue)。ClickPipes 在 s3Cluster 的基础上扩展,提供从对象存储进行批量和增量加载的能力,并确保“恰好一次”(exactly-once)语义。
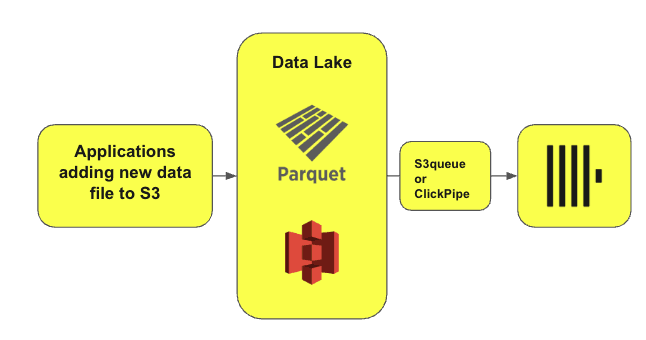
上图展示了一种常见的架构模式,广泛应用于需要增量写入数据的场景,例如日志分析和 Web 分析。
在这种架构下,ClickHouse 会持续从数据湖中加载数据,并存入 ClickHouse 表,以支持高效分析。ClickHouse 会定期查询 S3,检查是否有新数据。如果发现新文件,ClickHouse 会自动读取、加载,并将数据聚合到指定表中。
这一模式可以轻松扩展至 Iceberg、Delta,甚至 Hudi 等开源表格式。
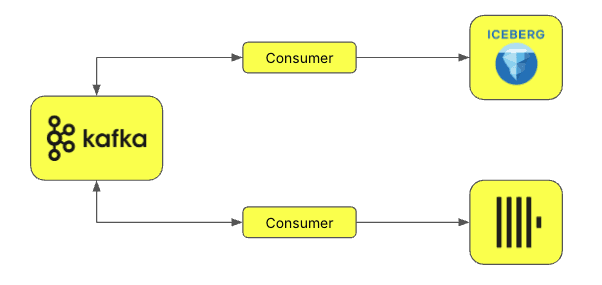
此外,还可以通过“双写”(double-write)方式,将数据湖中的部分数据加载到 ClickHouse。这种方法常见于企业数据平台的架构设计,目标是存储企业的大量数据,同时确保各团队能够无缝访问和使用数据。Iceberg 在这种场景下尤为适用。数据通常通过 Kafka 主题流转,多个消费者可同时将其写入 ClickHouse 和 Iceberg 表。这种方法特别适用于不可变数据(immutable data)和仅追加(append-only)场景,即数据一旦写入便不会更改。
使用 ClickHouse 进行临时查询和联邦查询(Ad-hoc & Federated Queries)
另一种常见模式是,用户已经在使用 ClickHouse,但偶尔需要查询 Iceberg 或 Delta 表,或者直接查询 S3 上的文件。如果这些数据的查询频率较低,那么直接加载到 ClickHouse 可能性价比不高。在这种情况下,ClickHouse 可以直接查询这些数据,从而有效替代 Athena 等工具。这可以通过 s3Cluster、icebergCluster 和 deltaLakeCluster 函数实现。尽管这些查询的性能无法与 ClickHouse 原生表相比(原生表通常能实现毫秒级响应),但由于查询频率较低,秒级的查询延迟通常可以接受。
例如,在某些合规性场景下,企业可能需要查询某个产品或用户的相关活动记录,并且查询时间范围可能长达数月。
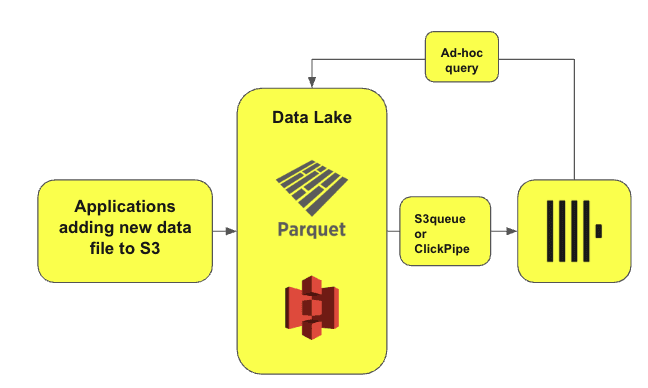
这些查询模式同样适用于 Iceberg、Delta Lake,甚至 Hudi 表。
从架构角度来看,ClickHouse 可以作为“热层”(hot layer),Iceberg 作为“冷层”(cold layer)。绝大多数查询都直接在 ClickHouse 上执行,而部分查询需要完全针对数据湖执行,或者与数据湖进行联邦查询(当数据分别存储在 ClickHouse 和数据湖中时)。
凭借 ClickHouse 的灵活性和强大的集成功能,联邦查询正变得越来越常见,与 Athena 的使用方式类似。
此外,ClickHouse 不仅支持文件和开源表格式,还可以查询多个数据源,并将查询结果进行关联分析。典型的联邦查询数据源包括:
PostgreSQL MySQL 数据湖(S3、GCS、Azure) ClickHouse 表 MongoDB
这种能力极大提升了灵活性,尤其适用于那些查询频率较低、不值得专门存储在 ClickHouse 这样的列式数据库中的数据集。
在某些场景下,用户需要用 MongoDB 和 PostgreSQL 中的数据对 ClickHouse 里的行数据进行关联和补充。例如,MongoDB 和 PostgreSQL 可以作为 ClickHouse 的字典(dictionary)数据源,为 ClickHouse 提供额外的数据扩展能力。
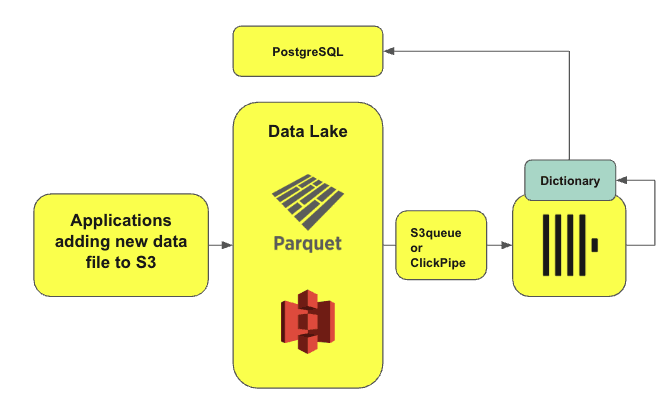
使用 ClickHouse 对数据湖/湖仓进行高频查询
为了更直观地说明这个场景,我们可以举个例子:某家金融服务或加密货币公司需要访问多个数据集进行研究。虽然这些数据集可以通过 API 或类似方式访问,但随着数据量增加和存储成本上升,更常见的做法是通过 Iceberg 或其他开源表格式共享数据。
你可以在 Allium 的集成页面上看到一个示例【https://docs.allium.so/integrations/overview】。
ClickHouse 提供 icebergCluster 和 deltaLakeCluster 等表函数,使用户可以方便地查询这些系统。不过,目前这种方法仍然有一些限制。
目前,原生格式仍然更快
首先,这种方法无法利用 ClickHouse 经过优化的内部存储格式,因此查询数据湖的性能通常比直接存储在 ClickHouse 中要慢。这种性能差距在支持开源表格式的数据库中较为常见,因为它们的内部存储与查询引擎通常经过深度优化。此外,既要负责数据摄取又要执行查询的数据库,相比纯查询引擎,需要面对更复杂的挑战。2025 年,我们计划缩小 ClickHouse 原生格式与开源标准之间的性能差距。
提升数据发现能力
另一个限制在于数据发现(data discovery)。虽然这一概念已经存在多年,但近年来,随着各类数据目录(catalog)的发展,不仅提升了数据发现与表集成能力,也加强了访问控制和用户权限管理。以往,ClickHouse 不能自动发现 catalog 管理的表,用户必须手动提供 Delta 或 Iceberg 表的 URL 进行查询。这对用户来说是一个常见的挑战。为了解决这个问题,我们最近增加了对 Iceberg REST catalog 的初步支持。
在上述三种使用场景中,高频查询数据湖/湖仓是最需要改进用户体验的部分。因此,我们投入了大量工程资源,以增强对 catalog 的支持。但这只是开始,我们预计未来几个月将推出更多新功能和优化支持。
以下是我们近期的工作进展,以及接下来几个月的重点方向。
Catalog 集成
尽管 ClickHouse 已经支持 Iceberg、Delta Lake 和 Hudi,并提供了专用表引擎,但查询这些数据时仍需手动指定表路径。正如前文提到的,最好的改进方式是集成数据目录(catalog)。我们的目标是让 ClickHouse 同时与数据目录和存储交互,以便自动解析表路径、无缝对接访问控制,并仅读取必要的数据。
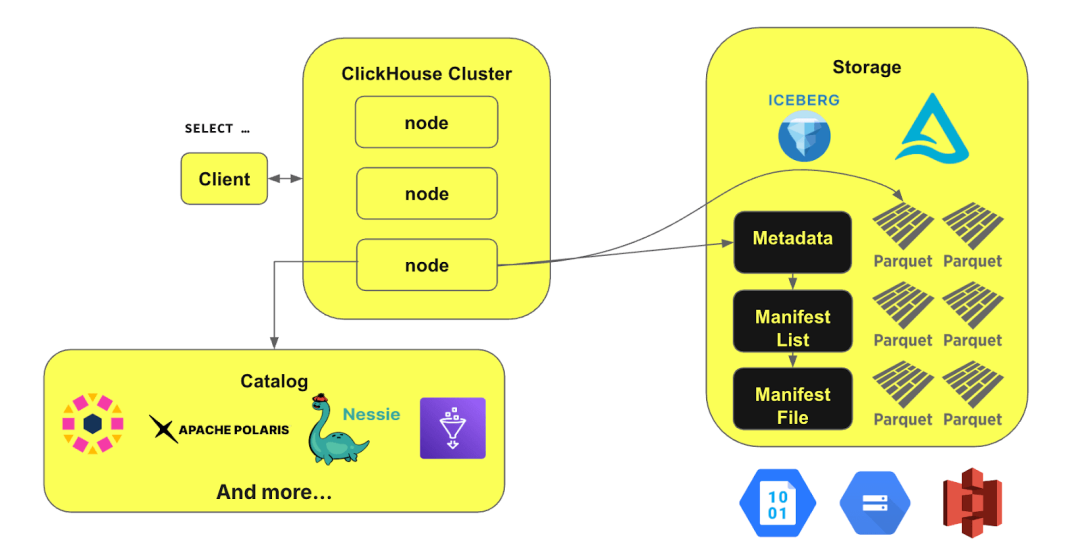
目前,我们仍处于开发的早期阶段,但已经能够通过 Polaris catalog 展示这一概念的实际应用:
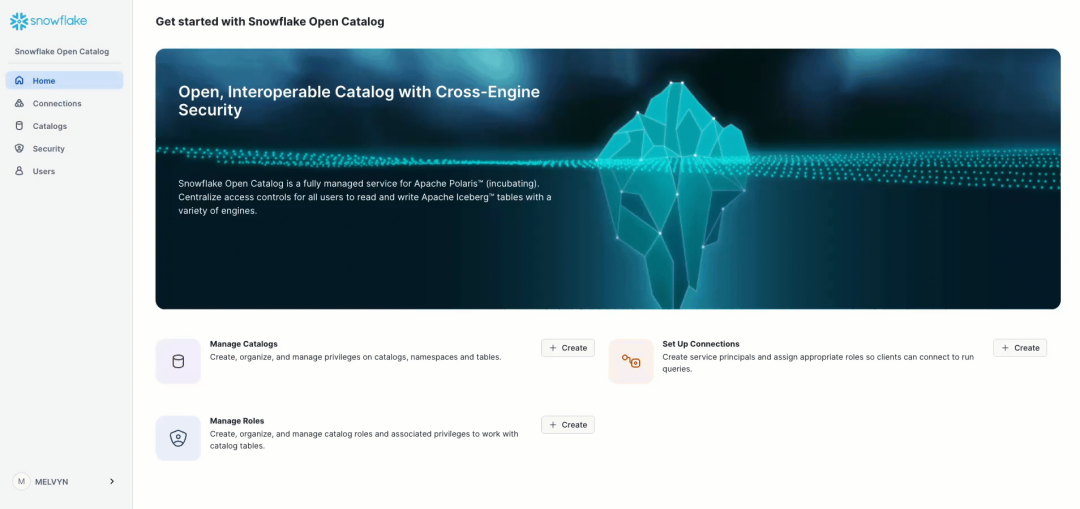
在上图示例中,一些表存储在 Snowflake 的 Iceberg 表中,而 Snowflake 提供了 Polaris 的托管服务。从 ClickHouse 24.12 版本开始,我们引入了对 Iceberg catalog 的支持,使用户能够在 ClickHouse 中直接集成 catalog 并查询其中的数据。现在,你可以通过 ClickHouse 直接查询 Snowflake 中由 Iceberg 管理的表!
以下是一个示例。在上方截图中,你可以看到 catalog 及其不同的命名空间。我们可以在 ClickHouse 中创建与 catalog 的连接:
CREATE DATABASE catalogENGINE = Iceberg('https://********************/polaris/api/catalog/v1')SETTINGS catalog_type = 'rest', catalog_credential = '*********************', warehouse= 'polarisch'Elapsed: 0.001 sec.
然后,你可以立即开始探索:
SHOW TABLES┌─────────────────────────────────────────┐│ name │├─────────────────────────────────────────┤1. │ benchmark.notpartitionedwikistats │2. │ core.alerts │3. │ core.logs │4. │ hits.dailypartitionned │5. │ hits.notpartitioned │6. │ product.roadmap │7. │ website.logs │└─────────────────────────────────────────┘7 rows in set. Elapsed: 2.449 sec.
检查表的 schema:
SHOW CREATE TABLE catalog.`product.roadmap`CREATE TABLE catalog.`product.roadmap`(`feature` Nullable(String),`team` Nullable(String),`owner` Nullable(String),`engineering_lead` Nullable(String))ENGINE = Iceberg('s3://paths/', 'user', '[HIDDEN]')1 row in set. Elapsed: 0.219 sec.
最重要的是,你可以直接在 ClickHouse 中查询数据:
SELECT *FROM `product.roadmap`WHERE feature ILIKE '%Lakehouse%'┌────────────┬──────────┬────────┬──────────────────┐│ feature │ team │ owner │ engineering_lead │├────────────┼──────────┼────────┼──────────────────┤│ Lakehouse │ Samurai │ Melvyn │ Sasha S. │└────────────┴──────────┴────────┴──────────────────┘1 row in set. Elapsed: 0.477 sec.
我们目前已支持 REST catalog,但这只是开始。接下来,我们还计划支持 Glue catalog,以及用于 Delta 表的 Unity catalog。
湖仓的集群查询能力
现有的 s3Cluster 函数已经可以用于查询数据湖,使集群能够在多个节点上分布式处理查询。然而,此前我们尚未支持 Iceberg、Hudi 或 Delta Lake 的此功能。在 ClickHouse 24.11 版本中,我们已经对此进行了优化。如果你还没来得及测试,以下是 3 节点集群的性能提升情况。
SELECT count(*) FROM icebergS3Cluster('my_cluster', 's3://path/', '****************', '****************') WHERE (project = 'en') AND (subproject = 'turing')┌──────────┐│ count(*) │├──────────┤│ 146 │└──────────┘1 row in set. Elapsed: 907.256 sec. Processed 95.97 billion rows, 2.53 TB (105.78 million rows/s., 2.79 GB/s.)Peak memory usage: 2.69 GiB.
在未优化和未压缩的表上,查询速度随集群节点数量的增加呈线性增长。
SELECT count(*) FROM iceberg('s3://path/', '****************', '****************') WHERE (project = 'en') AND (subproject = 'turing')┌─────────┐│ count(*)│├─────────┤│ 146 │└─────────┘1 row in set. Elapsed: 2595.390 sec. Processed 95.97 billion rows, 2.53 TB (36.98 million rows/s., 974.86 MB/s.)Peak memory usage: 2.78 GiB.
除了投入资源支持数据目录(catalog),我们也在积极改进对开放表格式的支持。
Iceberg
尽管 Iceberg 拥有成熟的生态系统,但遗憾的是,目前尚未有 C++ 版本的库。虽然这一情况可能很快会发生变化,但这也使得支持 Iceberg 规范中的某些最新功能(例如删除行的支持)变得困难。
在过去一年里,ClickHouse 在扩展 Iceberg 支持方面取得了显著进展,已实现多个功能,并且仍在持续开发,包括:
支持分区裁剪(partition pruning) 支持模式演进(schema evolution) 支持时间旅行(time travel)
在完成对 Iceberg v2 的支持后,我们计划进一步支持 v3 版本。
Delta Lake
我们当前的重点之一是增强 ClickHouse 对 Delta Lake 的支持,并已在积极推进相关工作。Delta Kernel 于 2023 年作为实验性功能首次发布,并预计很快将达到 GA(正式可用)阶段。Delta Kernel 目前有两个版本:Java Kernel 和 Rust Kernel。对于 ClickHouse,我们正在集成 Rust Kernel,以加速未来的 Delta Lake 开发。一旦 Kernel 支持对 Delta 表的写入,ClickHouse 也将能够提供完整的写入支持。
此外,我们可以基于 Iceberg 的开发经验来增强 Delta Lake 的支持。因此,许多 Iceberg 功能也将适用于 Delta Lake。类似于 Iceberg catalog,我们计划支持 Delta catalog(主要是 Unity catalog)。借助我们对 Iceberg catalog 的初步实现,扩展到 Delta catalog 预计会相对顺利。
每年,我们都会发布 ClickHouse 核心数据库的新路线图,2025 年也不例外。今年,我们的重点将围绕以下三个核心方向展开:
1. 提升数据湖/湖仓的临时查询和高频查询体验
扩展 Iceberg 和 Delta 的 catalog 集成 完善 Iceberg 和 Delta 的专属功能支持,包括变体类型(variant type)等复杂数据类型 引入元数据缓存层,以提高查询性能 改进 Parquet 读取器,以提升查询效率
这些优化将有助于用户更轻松地发现数据湖中的数据,并让 ClickHouse 具备更强的查询能力。此外,我们还计划改进 Parquet 格式的数据分布式查询执行。目前,查询任务的分发单元是文件级别,但由于文件大小不均,可能导致计算任务分配不均衡。因此,我们计划利用 Parquet 格式的特性,使查询任务的分配更加精细化。
2. 增强 ClickHouse 对数据湖/湖仓的支持能力
支持 Iceberg 和 Delta 的写入能力 支持数据合并(compaction)和 Liquid Clustering 引入外部物化视图(External Materialized Views),以提升查询效率
目前,ClickHouse 不能作为 Iceberg 的写入端,这存在一定局限性。然而,ClickHouse 在数据预处理领域被广泛应用,尤其是在其强大的物化视图支持方面。通过增加写入支持,我们可以利用 MergeTree 表引擎的经验,为 Iceberg 和 Delta 表实现高效的数据合并(compaction)。
3. ClickPipes 中的 Iceberg CDC 连接器:无缝地将 Iceberg 表复制到 ClickHouse 本地表,以支持面向客户的实时分析。
为了在数据湖表上实现毫秒级查询延迟,这项工作包括:
完整支持初始数据加载以及仅追加表(append-only tables)的变更数据捕获(Change Data Capture,CDC) 后续迭代将扩展支持 UPDATE 和 DELETE 操作的复制 在 ClickHouse Cloud 上提供全托管体验,并内置监控指标
此外,我们还将在云端推出一系列特定功能,以简化数据接入、提升数据访问体验,并优化云资源的使用。
随着这些新功能的开发推进,以及我们对开放表格式和湖仓架构的持续优化,我们将与社区保持密切合作,收集反馈并不断提升用户体验。
如果你希望成为设计合作伙伴,抢先体验这些新功能,或者想进一步了解我们的未来计划,请填写此表单【https://clickhouse.com/cloud/data-lakehouse-waitlist】,我们将尽快与你联系!
我们希望本文能帮助你了解 ClickHouse 在数据湖和湖仓中的多种应用场景,同时提供对我们未来发展方向的深入洞察。随着这一领域的技术不断成熟,我们相信 ClickHouse 将在未来成为数据湖生态的重要组成部分。如果你已经是 ClickHouse 和数据湖/湖仓的忠实用户,那么 2025 年即将推出的新功能一定会让你感到兴奋!
如果你有功能需求,或者希望为 ClickHouse 做出贡献,欢迎在 GitHub 或 Slack 上参与讨论,让你的声音被听见!

好消息:ClickHouse Shanghai User Group第2届 Meetup 倒计时2天,将于2025年03月01日在上海 阿里巴巴徐汇滨江园区X区3层X7-301龙门书院 举行,扫码免费报名

 注册ClickHouse中国社区大使,领取认证考试券
注册ClickHouse中国社区大使,领取认证考试券

ClickHouse社区大使计划正式启动,首批过审贡献者享原厂认证考试券!
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


