




CloudberryDB | 第3期 | 解析器原理(2)
本文接上文,介绍词法解析逻辑的流程。
1、词法解析逻辑
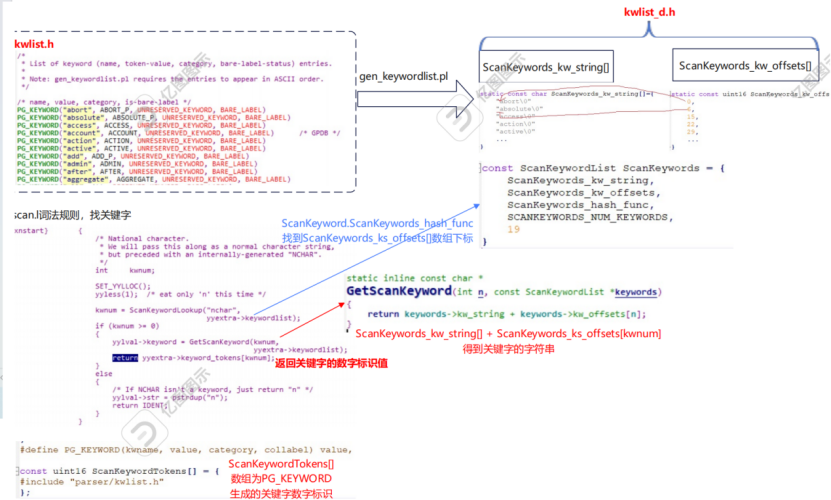
1)kwlist.h通过gen_keywordlist.pl脚本生成kwlist_d.h头文件,里面定义了ScanKeywords_kw_string[]、ScanKeywords_kw_offsets[]数组,并定义了ScanKeywords结构体。其中ScanKeywords_kw_string[]数组存放所有关键字的字符串、ScanKeywords_kw_offsets[]数组存放第i个关键字位于ScanKeywords_kw_string[]字符串的第i个字符位置
2)scan.l中定义了词法规则,从yytext中得到词法解析出的单词后,ScanKeywordlookup根据从hash表中找到关键字在ScanKeywords_kw_offsets[]数组的下标
3)然后GetScanKeyword得到关键字的字符串
4)最后返回ScankeywordTokens[]数组中关键字对应的数字标识值
此时词法解析得到一个关键字,就可以进入语法解析流程,从而找对应文法规则,做出响应动作。
2、语法解析逻辑
parsenodes.h中定义了一系列表达statement的结构体,通常以Stmt为后缀的名称,用来保存语法分析结果。以SELECT查询为例,对应的结构为:SelectStmt,即一个语法树的节点类型:
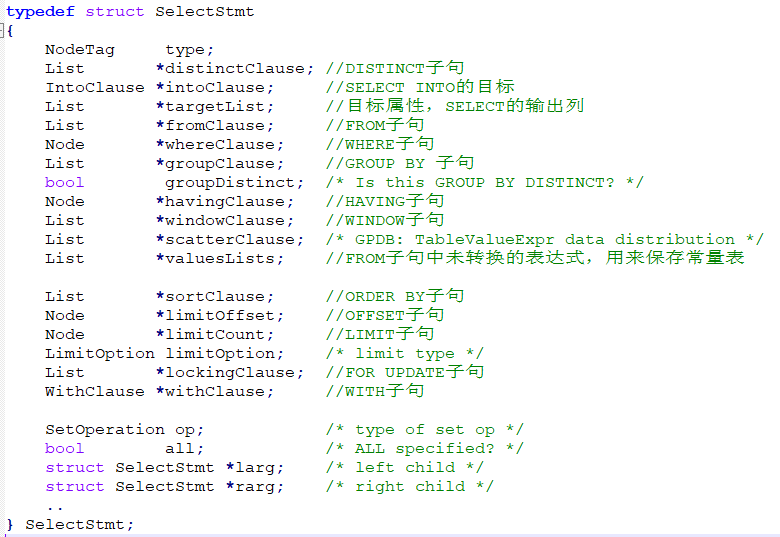
1)可以看到这个结构体就是一个多叉树,每个叶子节点都表达了SELECT语句中的一个语法结构,对应到gram.y中,会创建一个SelectStmt类型节点:
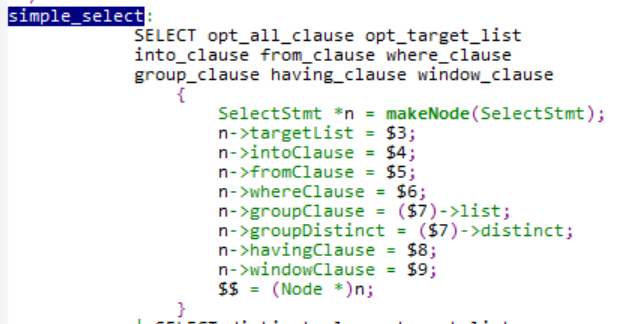
就一个简单SELECT来说,他的输出列文法对应的非终结符为opt_target_list,即SelectStmt的targetList结构,继续找到opt_target_list文法规则:

如果未匹配到target_list即为空时,之间返回NULL,也就是targetList指针为NULL,否则因为target_list为非终结符,需要继续递归找它的文法规则:target_list可以由多个target_el组成,匹配到target_el后会创建ResTarget结构,target_el可以为表达式、取别名的表达式和“*”等:


2)接着查看SELECT的FROM子句,即from_clause非终结符标识的文法规则
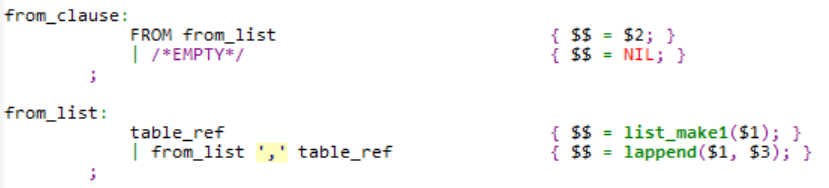
from_clause匹配后对应的文法规则由FROM关键字和from_list非终结符构成,而from_list又由一个或者多个table_ref构成。table_ref可以定义为关系表达式、取别名的关系表达式、函数、SELECT语句、表连接等形式:以关系表达式为例
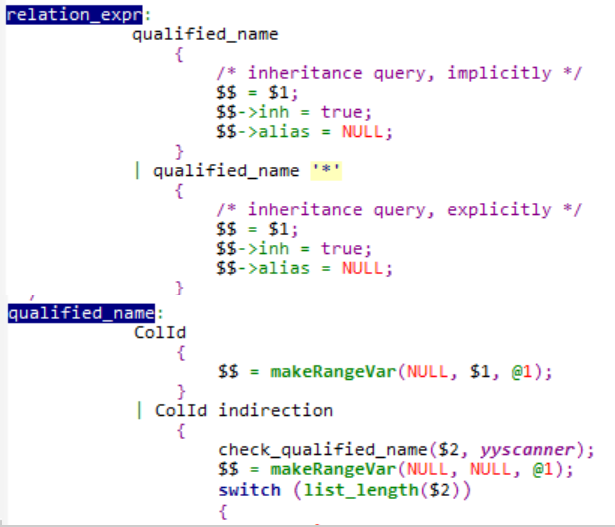
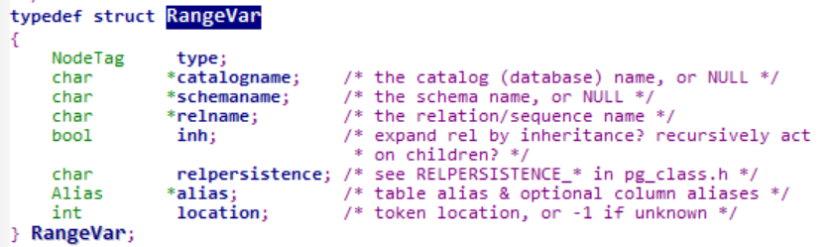
最终会捕获到ColId,创建一个RangeVar结构体,用来存储相关信息:表名、数据库名等等
3、词法、语法解析整体流程
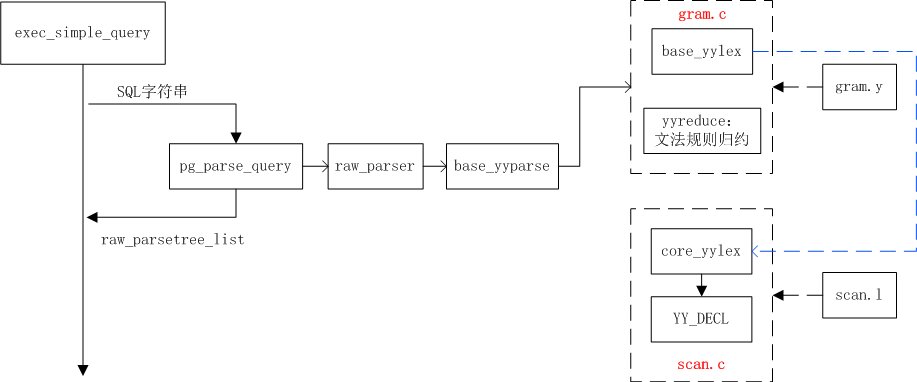
exec_simple_query向解析器接口pg_parse_query传入SQL字符串,然后调用raw_parser进行词法和语法解析,由base_yyparse进入gram.y语法规则文件生成的gram.c中,调用base_yylex进入词法解析模块,即scan.l生成的scan.c中进行词法解析,解析出关键字后,重新返回gram.c中,进行yyreduce等文法规则归约,最终匹配到非终结符后,针对对应的文法规则做一些事,比如SELECT,会创建SelectStmt语法树结构节点等,最后构建成一个语法树,然后封装成一个list结构即raw_parsetree_list返回给exec_simple_query函数,用于后面的语义分析、查询重写等步骤。该list的每一个ListCell都包含一个语法树。
