




自 OB V4 版本推出“单机分布式一体化”架构后,搞出一个新概念“日志流”,这个估计是 V4 版本里最难理解的一个概念,即使 OB V4 以前版本的用户也难免困惑。本文就分享一下我对这个设计的理解。
日志流虽然是新名词,但它要解决的问题却是数据库最基本的也是核心的问题,并不是什么新的问题。所以我先从数据库基本原理说起。
数据库事务日志
数据库是用来存储数据的,但并不是存储数据的唯一选项。在数据库诞生之前,文件也可以存储数据。只是现在大家之所以把数据放在数据库里而不是放在文件里有很多原因。其中之一是文件如果损坏了可能就打不开了,那数据就丢了。原因之二是也放不了太多的数据,数据太多的时候出故障的概率更大。当然还有其他更重要的原因就是数据库关系模型和SQL语言的成功。那些在这里倒不是重点。
文件是放在文件系统里,文件损坏的一类原因往往是文件系统损坏。如机器宕机重启,文件的内容还在文件系统的缓存里,忽然掉电一下子就没了。文件系统对此也有一些设计,比如说写元数据,写文件系统自己的日志。机器重启后文件系统可以自己扫描日志,做一些数据恢复逻辑。这个有一定作用但并不每次都有用。偶尔我们还是能发现文件损坏,这依赖文件系统的能力。数据库的文件大部分也在文件系统里(ORACLE 在 AIX 系统里数据文件用裸设备例外),数据库的数据非常重要,显然不能靠文件系统那点恢复能力。所以数据库在写数据文件之前还会同步写一份数据的修改日志,也就是 REDO 日志。这个技术叫 Write Ahead Logging
技术。可以说所有的关系数据库都有这个设计。ORACLE 叫 REDO 日志,PostgreSQL 叫 pg_log
,MySQL 叫 Innodb REDO
日志 和 Binary
日志,SQLServer 叫 ldf
文件。 这份事务日志对数据库非常重要,所以有些数据库备份还要备份这个日志。ORACLE 的归档日志就是对 REDO 日志的备份(然后 DBA 再二次备份归档日志),MySQL 的 Binary 日志也有归档设计。
传统数据库主备同步
事务日志的可靠性决定了数据库的可靠性。事务日志一般都是实时落盘(写到磁盘内而不是缓存到文件系统里。MySQL 的默认设置为什么不那么可靠就是因为它违背了这个原则)。但是如果磁盘损坏了,还是有可能导致事务日志也坏了,强制打开数据库可能会丢一点点数据。所以数据库还是有那么一点风险。应对这个风险的方法就是另外找一台服务器再做一个数据库的副本。所谓副本就是数据完全一致的。要保障副本数据一致就要用到数据同步技术。当新增了一个副本的时候,不妨把原来的数据称作为主副本,新的数据称为备副本。主备副本间数据同步就是保证备副本数据一致的技术。这个同步实际上并不是数据双写,而是同步主副本上的事务日志到备副本上并在备副本上应用这个日志。ORACLE 的 Dataguard
技术,SQLServer 的 Mirror
复制技术都是主备同步。他们的特点是整个数据库做主备同步,备库(也就是备副本)跟主库的数据只可能有延时不会有丢失。通俗一点说所有表都同步。MySQL 的主从复制也属于这一类技术,但是 MySQL 玩了一点花样,可以定制表的同步。此外 MySQL 的 Binary Log
里记录的是数据变化的 SQL或者数据行变化的SQL,这导致 MySQL 的备库有一定概率跟主库并不完全一致。灵活倒是灵活,可靠性就下降了。不过这里说的还是同步的粒度,ORACLE 最小粒度是数据库实例级别的同步(ORACLE 没有细分数据库的概念),SQLServer 最小粒度是数据库级别的同步。MySQL 最小是数据库级别的同步(只是可以设置哪些表同步或者不同步)。
数据同步还有个方向问题。ORACLE 和 SQLServer 的数据同步都是主备同步,是单向的。SQLServer 是实例里包含多个数据库,两个实例之间不同数据库的同步方向可以有不同方向。所以数据库级别是单向的,实例级别有可能是双向的。MySQL 最灵活,数据库级别都可以双向同步(也就是通常说的 Master-Master
同步。哪怕是同一个表都能够双向同步。同一个表双向同步最大的风险就是数据交叉覆盖,这个对业务是一个灾难。DBA 如果控制不了这种风险那还是别用双向同步。MySQL 双向同步的能力在特殊的场景下有很大作用。如阿里巴巴电商业务数据三地多中心单元化多活架构中就大量使用,那是因为业务能保证每个地区(单元)写入的数据互不冲突。比如说用户数据,每个淘宝用户读写数据时可能都被路由到不同的单元中心机房里的数据库。它做到了同一个表的同一记录写入点是单一的,表级别呈现的是多点写入能力。ORACLE 和 SQLServer 的主备库都没有这个能力。但是他们有自己的集群产品,数据读写也是可以多节点读写,只不过数据存储是同一份(共享存储)。这是另外一种解决方案。
多副本的副本
现在回到分布式数据库。所有分布式数据库都有两个共同点。一是数据存储使用分布式技术拆分,二是数据有多副本。前者数据拆分后会有多个分片。这里额外说一下副本概念和分片概念的区别,副本是 replica
,分片是partition
。MySQL 的分库分表方案中分表,对应这里的分片概念。ORACLE 的分区表的分区对应也是分片的概念。分片概念是属于分布式技术,本文不讨论分片概念,只是围绕副本概念解释。
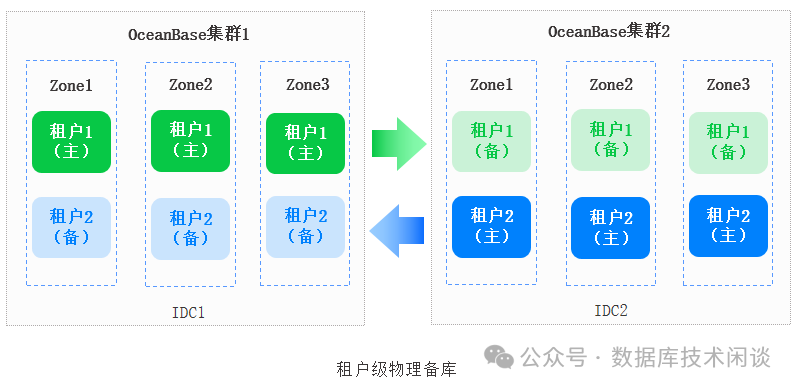
需要注意的是一般分布式数据库的多副本是放在一个集群范畴里的。ORACLE 的 Dataguard 部署的主备库通常不会称为一个集群,因为主库和备库可以独立运维,并且备库可以临时不可用。主备之间是松耦合的。而分布式数据库里的主备是放到一个集群里说。比如说 TiDB 集群数据默认有三副本(前提是 TiKV 三节点部署),OB 集群数据默认也有三副本(前提也是三节点部署)。整个 OB 集群里面不再分主备实例或主备库,没有这种概念。 但是 OB 集群里的数据会有主备副本的概念,这一般是讲述 OB 多副本原理的时候会说。 TiDB 也同理。 这里的问题就是这个副本到底对应了什么。这是理解日志流的第一个关键点。这个放到后面说。OB 从 V3 版本让人经常困惑的是 OB 在主集群里有多副本之外还搞出了一个备集群的概念,主备集群的关系就类似 ORACLE 主备库的关系。这个时候主备集群的同步就跟 ORACLE Dataguard 一样是整体的集群级别。由于分布式数据库规模可能非常庞大,OB 从 V4 版本开始把这个同步粒度 细化到租户级别,搞出了 主备租户的概念。主备租户可以在同一个集群,也可以在不同集群(更倾向于后者)。所以OB V4集群不再有主备之说,只有租户有主备之说。备租户只能读不可以写,类似 ORACLE Active Standby
。主备租户同步是单向同步,没有双向同步。备集群或备租户是客户容灾场景的需要(金融行业提出的)。TiDB 集群就没有备集群或备库的概念。OBV3 主备集群之间平时是松耦合的,是可以异构的(机器类型异构、机器资源异构)。到 OBV4后 主备租户之间也是松耦合,可以异构的。日志流概念的解释就是主租户内部的,备租户内的日志流不用关注,跟主租户同理吧。所以后面就不再讨论 OB 备集群或备租户。
OB 主备租户
OB 集群三节点部署的时候,OB 租户一般也选择三副本部署,即都有三个 Zone 。TiDB 没有租户概念,可以把 TiDB 的实例类比为 OB 的租户。OB 和 TiDB 的多副本都有个共同的特征就是只有一个主副本,其他全是备副本。并且总的副本数(包括主副本)尽可能是奇数。虽然偶数也行,只是意义不大,这是由 OB 和 Paxos 的多副本同步选举协议决定的,都属于多数派选举协议。OB 用的 MultiPaxos
,TiDB 用的是 MultiRaft
协议,这两个协议一个祖宗,都是 Paxos 协议,Raft 是 Paxos 的简化版。多副本同步的事情是自古就有,只是用协议概念提出来是分布式数据库讲的比较多。MySQL 的主从同步机制也可以称为协议,只是没有一个专门的名字,或者叫异步同步比较接近。MySQL 后来还搞出了半同步。ORACLE 主备同步有最大性能、最大保护、最大可用等等。之所以有这么多名堂都是为了尽可能保证备副本数据跟主副本一致。为什么不能单一的选择强制保证所有备副本数据跟主副本一致呢,那样岂不是最安全。是的。虽然安全,但是性能最差,扩展性也最差。异步同步或最大性能是最不安全的,但是性能最好。最大保护和半同步都属于只要有一个备副本跟主副本一致了就认为安全的,Paxos和Raft 多数派同步协议是认为半数以上副本成员数据一致了才是最安全的。可以简单的理解为理论上性能跟安全是反着来的。所以理论上同等规格同等测试场景下,OB 或 TiDB 的三副本架构下 OLTP 性能很难超过 MySQL 的一主两从的半同步协议下的性能。当然实际上还是有很多变数,取决于各个数据库的SQL、事务、存储引擎的工程实现能力和效果。为什么有些国产数据库厂商性能 PK 中改个配置就能性能很大提升呢,很可能改的就是这个同步设置(此外还有事务日志是否强制落盘)。
至此说清楚了多副本同步机制的原理,剩下就可以说这个副本的粒度了。
多副本同步的粒度
这个副本指向可大可小。在 OBV4 版本以前,副本最大可以是一个 ZONE 内所有数据。集群有三个 ZONE,那么就表示所有业务数据有三副本(前提是所有租户也沿用三副本)。副本最小可以是表的分区(即名词partition
)。OB 的分区表跟 ORACLE 和 MySQL 分区表是一一对应的。分区是比表还要细的粒度。普通表可以看成单分区,分区表就是多分区。每个分区只能在一个节点上,所以普通表(单分区)的理论风险是其容量可能会超出单机存储容量。这就是 OB 里超级大的表一定要做分区的其中一个原因。副本的粒度也代表了多副本同步的粒度,或者说数据同步的粒度。OBV4 版本以前可以针对 租户、表设置 PRIMARY_ZONE
,即设置主副本的位置。如果是租户级别设置,那么租户内所有表的 PRIMARY_ZONE
都沿用这个设置。一般设置为单个 Zone 的时候,就是所有业务表数据分区的主副本都在这个 Zone 的节点上,这个就跟传统主备库特征类似。但是 PRIMARY_ZONE
设置为两个或多个 Zone 的时候,就会有部分数据分区的主副本变换到其他 Zone 上。这种变换是分区粒度的主备副本角色切换,是 OB 高可用能力的微观体现。通俗一点说 OB 主备切换是分区粒度做的,可以很多分区一起切换。这个呈现给业务的感受就是 OB 故障切换的时候有些表先恢复有些表后恢复,而传统主备切换是同时恢复。OB 这种切换感受可能要 好很多。不过弊端也有。切换粒度太细太费 CPU 资源,RTO 可能在 10s~30s
左右(这个比传统主备切换分钟级别的 RTO 还是要好很多)。
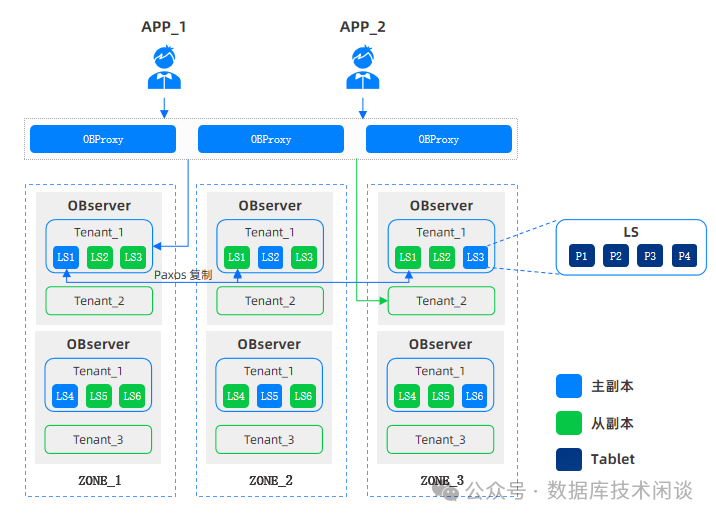
OBV4 版本的改进就是副本的概念还是不变,但是多副本同步的粒度变粗了,做成一批数据副本的同步集中管理。那这一批副本到底是多少数据呢,取决于租户的 PRIMARY_ZONE
设置。如果 PRIMARY_ZONE
设置为单个 ZONE
,那么这一批数据副本就指代全部业务数据。如果 PRIMARY_ZONE
设置为两个 ZONE
,那这一批数据副本可以简单理解为一部分数据。比如说租户数据分布在 ZONE1,ZONE2,ZONE3
,PRIMARY_ZONE
设置为 ZONE1,ZONE2;ZONE3
时,则一部分数据同步方向是 ZONE1->ZONE2, ZONE1->ZONE3
,另一部分数据同步方向是 ZONE2->ZONE1, ZONE2->ZONE3
。前面说过多副本同步实际上同步的是事务日志,OBV4 管理日志同步方向就是用日志流这个概念。日志流也可以有多副本,主副本到备副本的同步方向就是日志流的同步方向。数据分区的日志都会归属到日志流。一个日志流所辖的所有数据分区的同步方向都跟日志流的同步方向保持一致,以及日志流主副本所在的节点就是日志流所辖的所有数据分区的主副本所在的节点。
日志流
当租户PRIMARY_ZONE
设置的是单 Zone,那显然就只应该有一个日志流(有两个就是重复,目前看 OB 无意这个设计)。但是实际上用户真的看到了两个日志流并且方向还是一样的,那是因为 OB 专门把业务租户的 OB 元数据抽出来单独放一个日志流里进行管理,这个日志流 ID 是 1 ,而业务日志流 ID 是从 1001 开始。当租户PRIMARY_ZONE
设置的是多个 Zone 时,其用意也是数据主副本分散开,分散后自然就有多个同步方向了,那么就有了多个日志流。换句话说租户某个节点上只要有业务数据的主副本,那么上面必然有一个业务日志流的主副本,这样有多少个日志流就能算出来了。很多人困惑于官网里日志流数量计算方法,被上面文字计算逻辑搞晕,就是因为没有理解这点。日志流是为了管理数据多副本同步方向用的,在实现上是先要计算好日志流的数量然后再随机分片数据分区归属于这个日志流。这是代码实现逻辑,官网上那段解释恰好是代码逻辑,所以不便于用户初次理解。
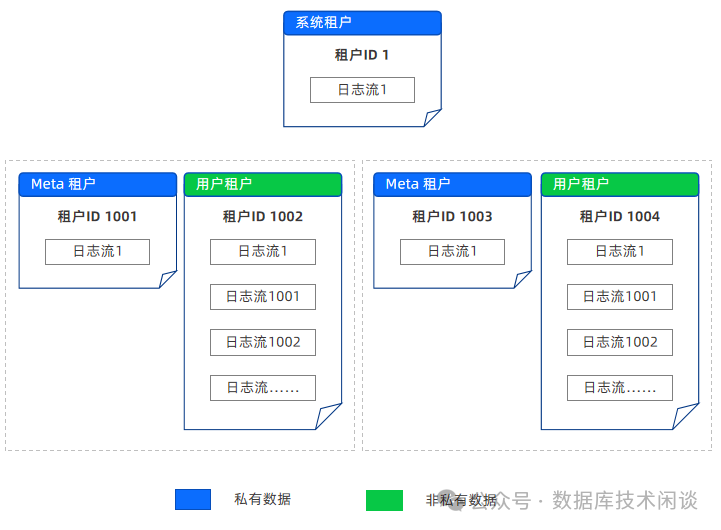
OB 还有一个特殊的业务场景,能加深对日志流的理解。OB 的复制表,其用意是为了避免表连接中出现跨节点的连接。一般基础配置表、静态表适合设置为复制表,这样在租户的每个节点上都会有这个表的副本。如果租户的拓扑是 2-2-2
,一共 6 个节点,那么复制表就有 6 个副本,其中 1 个主副本 5 个备副本,那么从主副本会有 5 个同步链路到备副本。这个同步协议叫全同步协议,所有副本都要同步成功(如果某个副本故障了,OB 会等待一段时间然后就超时退出,将故障副本提出了投票的群体。当然,如果后期故障副本恢复了,也是能自动请回桌面上)。复制表的同步显然跟前面的三副本多数派同步不一样,所以 OB 会单独配置一个日志流。
这个听起来又让日志流数量计算复杂一点。实际上运维人员根本不需要关心有多少个日志流。运维人员只要着眼于 PRIMARY_ZONE
的设置即可,或者着眼于你是否需要数据的读写入口分散到两个 ZONE 或者多个 ZONE 上。运维人员不需要关心哪些表归属于哪个日志流 就像不需要关心数据打散的时候哪些表的主副本在哪个节点上。因为分散位置是无法干预的,也不需要干预。如果要干预,只有一个特殊场景就是期望某些表的分区主副本能在一起,那就使用表分组技术。表分组不会改变日志流的数量,只会影响部分数据分区是否归属于同一个日志流。表分组的规则也很复杂,这是因为实际业务表的情形比较复杂(有些分区有些不分区,分区的表有些分区策略也不完全一致,分区还有一级分区二级分区的区别。这里面情况复杂的很)。
OB 论坛上还有个问题,单副本为什么要有日志流?其实也很好理解,多副本日志同步指的是事务日志在所有副本的同步和落盘,主副本所在节点的日志同步给自己是省了,落盘还是要做的。日志流是 OB 这个日志同步逻辑工程实现的设计,所以单副本依然会看到日志流。
总结
OK,到这里日志流就解释清楚了。简单总结一下将日志流理解为租户数据的日志同步方向管理的工程实现方案即可。日志流的数量不用去计算,运维只要运用好租户的PRIMARY_ZONE
、表分组和复制表技术即可。日志流是 OB V4 版本单机分布式一体化能力的关键,也是高可用 RTO 时间能缩短到 8s 左右的关键。个人观点,仅供参考,欢迎留言讨论。
更多阅读:
