




DeepSeek横空出世,以较低的成本提供了行业领先的模型能力,震撼了全球AI市场。凭借强大的推理能力和宽松的开源可商用条件,DeepSeek迅速成为开发者和企业用户的热门选择。
然而,部署一个高性能的推理模型往往涉及繁琐的配置和优化,需要 Python 编码、容器、推理框架、机器学习等专业知识,这让不少人望而却步。
别担心!今天,我们就来介绍如何在 Oracle Cloud Infrastructure (OCI) 上申请 GPU 资源,并利用 Ollama 和 vLLM 高效部署 DeepSeek 模型,让你轻松构建低延迟、高吞吐的推理服务,真正体验大模型推理的“Aha moment”。
Ollama
Ollama 是一个轻量级、高效的、开源大模型运行框架,支持 macOS、Windows、Linux 以及 Docker 容器环境。它的核心优势在于简洁的安装方式、灵活的模型管理和高效的推理能力,使得开发者和个人使用者可以轻松调用和部署大模型。
在 OCI GPU 上运行 Ollama,可以充分发挥其硬件加速能力,实现更低的推理延迟和更高的吞吐量,满足个人及中小企业级部署的需求。
主要优势
简洁易用,快速部署:Ollama 的安装和使用流程非常简单,只需几条命令即可下载并运行大模型,支持命令行交互、API 调用和第三方应用集成,极大降低了大模型的部署门槛。
高性能支持:依托 OCI(Oracle Cloud Infrastructure)强大的计算资源,支持GPU加速。
灵活自动扩展:可根据需求轻松调整资源,适应不同规模的应用场景。
灵活的模型管理:通过 Ollama,用户可以轻松下载、加载和管理多个模型,包括 DeepSeek、Llama、Mistral 等流行模型,本地私有化部署,确保数据安全。
简单来说,Ollama 结合 OCI GPU,能够提供高效、低成本的大模型推理方案,适用于个人开发者、研究团队以及企业级应用场景。
vLLM
vLLM 起初由加州大学伯克利分校的 Sky Computing Lab 开发,现已发展成为一个社区驱动的项目,能够显著提高推理吞吐量和 GPU 资源利用率。它采用了 PagedAttention 技术,大幅优化 KV 缓存管理,减少显存占用,适用于服务器级 GPU 部署。
在 OCI GPU 上运行 vLLM,可以充分利用GPU的并行计算能力,提高推理效率,降低成本,特别适用于需要高吞吐、低延迟的推理任务。
主要优势
高效的 KV 缓存管理:传统推理引擎在处理长文本时,KV 缓存管理效率较低,容易导致显存碎片化,而 vLLM 采用 PagedAttention 机制,按页管理 KV 缓存,使得 GPU 显存利用率更高,支持更长的上下文窗口,提高推理吞吐量。
高吞吐量,适用于批量推理:vLLM 通过 连续批量推理(Continuous Batching),可以动态调整并行任务,充分利用 GPU 资源,避免计算资源闲置,从而提高吞吐量。
灵活的模型兼容性:vLLM 支持多种主流大语言模型(LLM),包括以下类型的主流模型(https://github.com/vllm-project/vllm):
Transformer-like LLMs (e.g., Llama)
Mixture-of-Expert LLMs (e.g., Mixtral, Deepseek-V2 and V3)
Embedding Models (e.g. E5-Mistral)
Multi-modal LLMs (e.g., LLaVA)
vLLM 通过 PagedAttention、高效批量推理、多 GPU 扩展等技术,大幅提升 LLM 的推理性能,特别适用于服务器 GPU 部署,它能够提供低延迟、高吞吐的推理能力,为企业级 AI 应用和大规模推理任务提供高效的解决方案。
创建GPU计算资源
OCI上创建GPU虚拟机通常有两种方式:
选择VM.GPU.A10.1 Shape:从“Console” → “Compute” → “Instances”,选择“Create instance”,在“Image and shape” 部分选择 “VM.GPU.A10.1”,Image可选择已集成NVIDIA驱动的或者选择自己需要的后续自己安装NVIDIA驱动和CUDA。
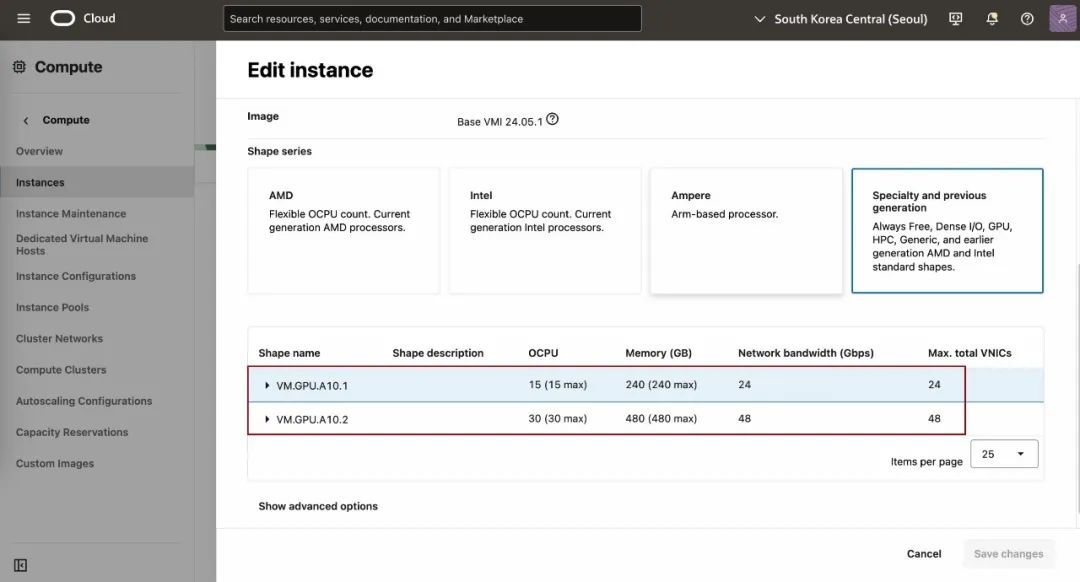
从Marketplace选择NVIDIA镜像:从“Console” → “Marketplace” 可输入 “NVIDIA” 进行筛选,选择合适的镜像然后 “Launch Instance”。
等待实例资源创建完成,选择合适的远程连接工具连接到实例。
安装、运行Ollama
在虚拟机上直接安装
在Linux上用户可以执行如下命令一键安装:
curl -fsSL https://ollama.com/install.sh | sh
安装完成后通过 ollama serve 启动 ollama 服务,可以通过执行 ollama -v 命令查看 ollama 版本信息,以验证是否安装成功。
在虚拟机上基于Docker安装
基于 Docker 可以使得 ollama 的安装、更新与启停管理更为便捷。
首先确保已安装了 docker,然后执行如下命令:
docker run --gpus=all -d -p 11434:11434 -v /data/ollama:/root/.ollama --name ollama ollama/ollama
接下来,我们可以使用 ollama 命令行下载和运行板型。可以通过官方网站(https://ollama.com/search)查看官方支持的模型。选择官方的 “deepseek-r1 7b” 作为示例,部署一个较小的模型进行快速验证。
运行命令
ollama run deepseek-r1
如果是docker安装,可以运行
docker exec –it ollama ollama run deepseek-r1
安装、运行vLLM
在虚拟机上直接安装
在Linux上用户可以执行如下命令安装,需要有conda环境(https://www.anaconda.com/download):
conda create -n vllm python=3.11 -yconda activate vllmpip install vllmpip install flash-attn --no-build-isolation
安装完成后通过执行 ollama -v 命令查看 ollama 版本信息,以验证是否安装成功。
开启DeepSeek之旅!
Ollama 与vLLM提供了一种简单而高效的方式,让开发者能够在本地或云端部署并运行大语言模型。通过轻量级的安装和简洁的使用方式,使得即便是资源有限的机器也能够运行高效的推理服务。而在部署了 DeepSeek-R1 模型之后,你可以通过 Open-WebUI 和 Dify 来快速体验这一强大的语言模型。接下来,我们将详细介绍如何使用这两种方式进行试用。
通过 Open-WebUI 使用 DeepSeek-R1
Open-WebUI(https://openwebui.com) 是一个基于 Web 的用户界面,旨在让用户通过浏览器与模型进行交互。它简单易用,适合任何想要快速试用 DeepSeek-R1 模型的人。
步骤:
1)启动 Open-WebUI:
在安装了 Docker 的机器上,你可以通过以下命令启动 Open-WebUI:
docker run -d -p 3000:8080 -v open-webui:/app/backend/data –e WEBUI_AUTH=false --name open-webui ghcr.io/open-webui/open-webui:main
这会启动 Web UI,并打开一个本地的3000端口,你可以通过浏览器访问这个地址。
在右上角的设置中可以设置刚才部署的Ollama或vLLM。
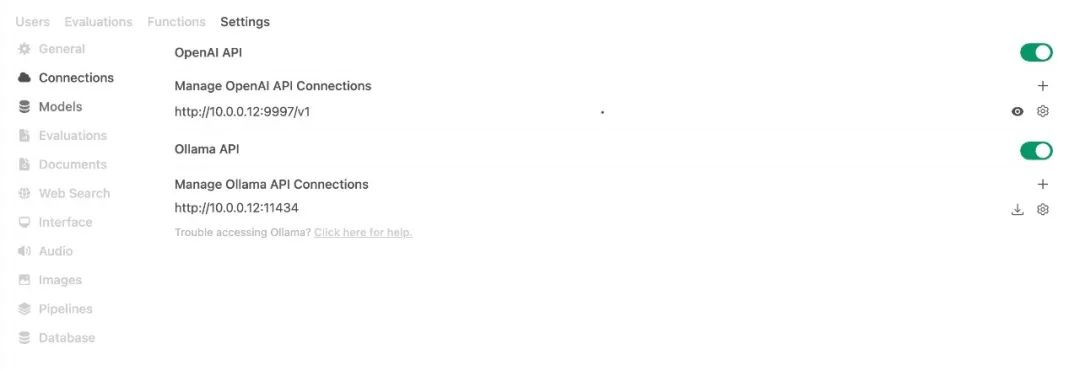
适用场景:
进行问答、文本生成、摘要提取等任务。
快速验证 DeepSeek-R1 在推理过程中的性能表现。
作为快速原型开发的基础,进行各种自然语言处理任务的探索。
通过 Dify 使用 DeepSeek-R1
Dify(https://dify.ai) 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
步骤:
1)创建 Dify 账号并登录:
访问 Dify 官网 注册并登录账号,或者在本地或云端部署社区版(可参考官方文档:https://docs.dify.ai/zh-hans)。
2)连接 Ollama:
在 Dify 控制台中,选择添加新的模型服务,并填写你在本地部署的DeepSeek模型,如,Ollama 服务地址(如 http://ip:11434)。
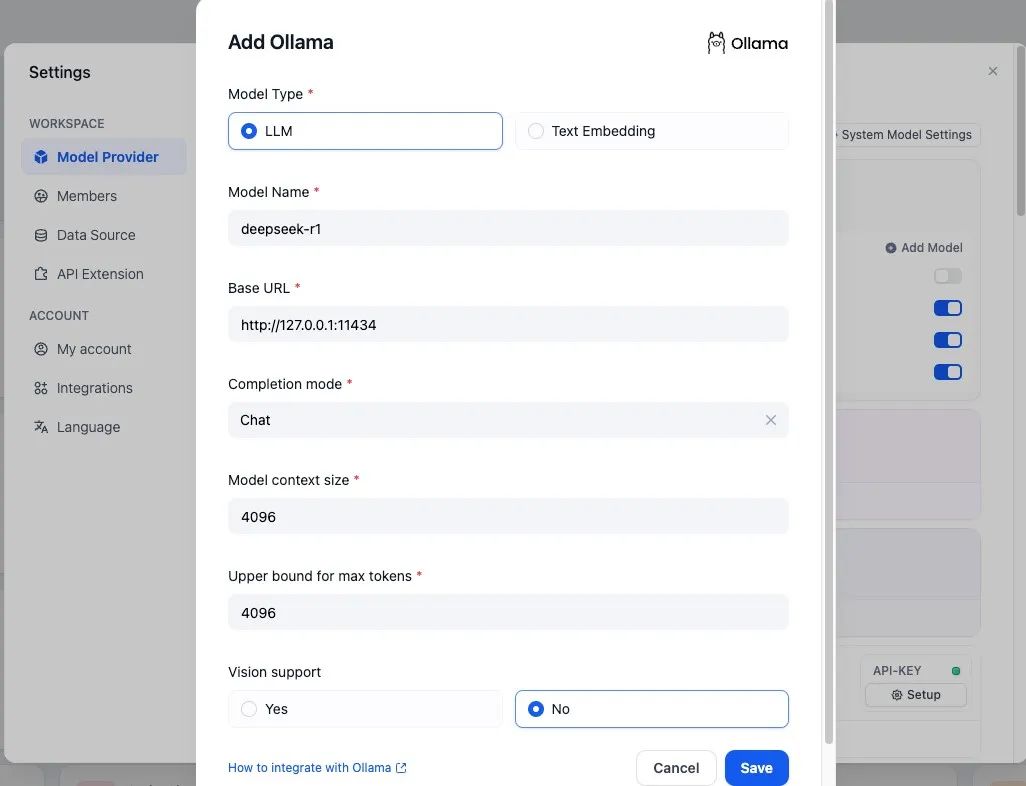
适用场景:
用于构建聊天机器人、自动化客服系统等。
适合快速集成到现有的 Web 应用、移动应用或产品中。
提供更丰富的 API 接口,可以用于大规模的自动化任务。
关于Dify更多与Oracle 23ai以及OCI Gen AI的集成使用请参考:https://github.com/tmuife/dify/blob/use_oracle/USE_ORACLE.mdhttps://github.com/tmuife/dify/blob/use_oracle/USE_ORACLE23AI.md
开始与 DeepSeek-R1 交互
在 Dify 的聊天界面或open-webui中,你可以像与人类对话一样与 DeepSeek-R1 进行对话。输入任何问题或任务,并等待模型响应。下面分别是基于 Dify和open-webui 部署的 DeepSeek-R1 模型构建的聊天机器人示例。可以看到 AI 在回答问题前进行详细思考和计划,使答案更加准确、全面。这一能力将极大提升企业 AI 应用的深度和广度。


避坑指南&优秀实践
1.安装flash-attn时出现nvcc版本错误?
需要更新nvcc版本到12及以上并设置环境变量。
2.vLLM部署模型后,如何连接?
vLLM是兼容openai的api格式,因此可以使用openai-api-compatible的形式访问。
3.模型推理速度很慢?
如果是使用了docker-compose.yaml文件运行在Docker中的Ollama,请检查是否将GPU资源绑定到容器上。
结语
Ollama 和 vLLM 都是非常优秀的大模型推理引擎,它们都很容易在 OCI GPU 上的部署。适合开发者和团队快速实现模型推理服务。通过优化推理流程、提高显存和计算资源的利用率,这些引擎在单卡 GPU 上的表现都相当出色,尤其是在低延迟和高并发场景下,能够满足大多数实验性和中小型生产环境的需求。
然而,尽管这些引擎能够在短时间内实现模型的快速部署,但对于企业级应用,尤其是高并发、大规模部署的场景,仍然需要更多的工作。首先,企业级应用需要更加完善的可扩展性 和高可用性,这意味着需要在多 GPU 方案、负载均衡、容器化部署和云端弹性扩展等方面做更多优化。其次,企业级部署往往涉及更严格的安全性和合规性要求,因此需要额外的工作来确保数据的隐私保护和访问控制。
编辑:赵靖宇
