




2月26号,在2025阿里云PolarDB开发者大会上,阿里云宣布PolarDB登顶全球数据库性能及性价比排行榜,这是继OceanBase和TDSQL之后,仅仅时隔一年半国产数据库再次刷新TPCC榜单。
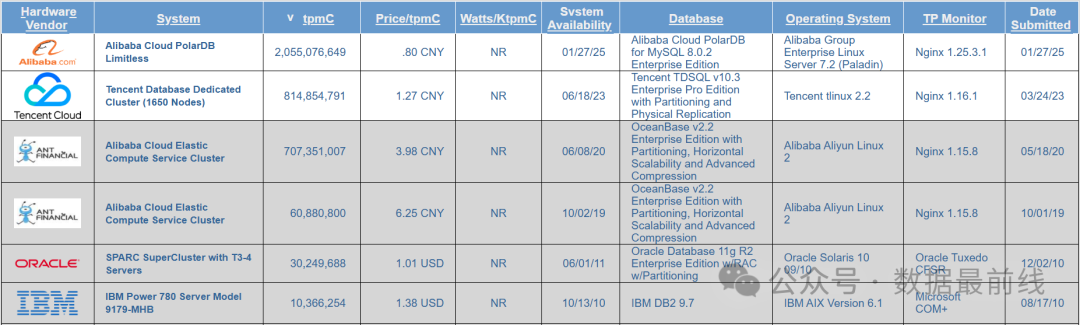
根据TPCC官网披露的数据,此次PolarDB提交的数据,tmpC达到20.55亿,为原纪录的2.5倍;而Price/tpmC则下降到人民币0.8元,比原纪录下降40%;压测系统使用了2340个节点,单台配置48vCPU/512GB内存,整体成本高达16亿人民币,比原纪录增加60%。从集群规模和整体成本上可以看出,打榜这个活,除了要技术先进之外还得雄厚的财力支撑,决不是一般的厂商能够玩得起的!
抛开经济实力不谈,我们今天重点探讨PolarDB采用了哪些技术,帮助其实现登顶榜首的目标。
整体架构
此次评测的系统使用的是阿里云PolarDB Limitless,内核采用MySQL 8.0.2的企业版本。传统云原生数据库通常采用主从的“一写多读”架构,读写节点的更新通过日志的方式传输到只读节点,只读节点通过回放日志更新数据。主从之间的数据同步是异步的,为了得到和主库一致的数据,只读节点上的应用需要容忍读取延时而导致的性能下降。
PolarDB Limitless采用的是“多写多读”架构,集群中所有的数据文件都存放在共享存储(PolarStore)中,每个读写节点通过分布式文件系统(PolarFileSystem)共享底层存储中的数据文件。每个数据库或对象的数据只能通过一个节点写入,没有分配数据库的节点不能进行读写操作。虽然数据存放在共享文件系统上,但每个数据库仍然是独立的,这和传统的MPP架构没有什么不同。因此PolarDB Limitless不支持跨 RW 节点的数据查询,如果一个查询SQL包含多个RW节点上的数据系统会报错。为了满足这类跨节点查询需求,可以在前端部署一个全局只读节点,读取所有 RW 节点上的数据,处理数据汇聚需求。
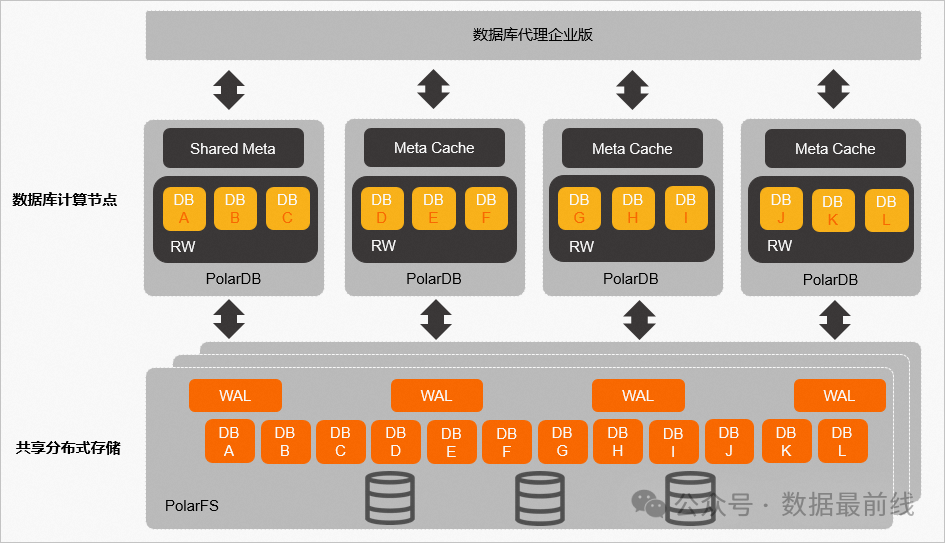
这种架构的好处是,RO 节点可以直接读取所有 RW 节点的数据,而不需要 RW 节点的日志同步,从而规避了需要等待日志同步而带来的性能下降。
Share-Everything架构是Oracle RAC等传统数据库所采用的性能,而分布式数据库通常以Share-Nothing为主。PolarDB Limitless是首个结合解耦共享内存与共享存储的多主云原生数据库,通过RDMA网络实现高效全局协同,这其中主要得益于三方面的改进。
事务融合机制
PolarDB Limitless使用TSO全局时钟保证事务的有序递增。为了有效管理集群中的事务信息,PolarDB Limitless采用去中心化的管理模式,每个节点向TSO申请时间戳记录到本地事务信息表TIT(Transaction Information Table),集群中的节点可以远程获取到其他节点的事务信息。不论是申请向TSO申请全局时间戳,还是获取其他节点的事务信息,都是通过单向的RDMA操作来完成的,既提升了数据的传输速度,也减少了计算节点的CPU开销。
同时还引入了线性Lamport时间戳获取机制,RO节点从RW节点获取时间戳后,可将其存储在本地。任何早于该时间戳到达RO节点的请求都可以直接使用本地存储的时间戳,而不用从RW节点获取新的时间戳。
缓存融合机制
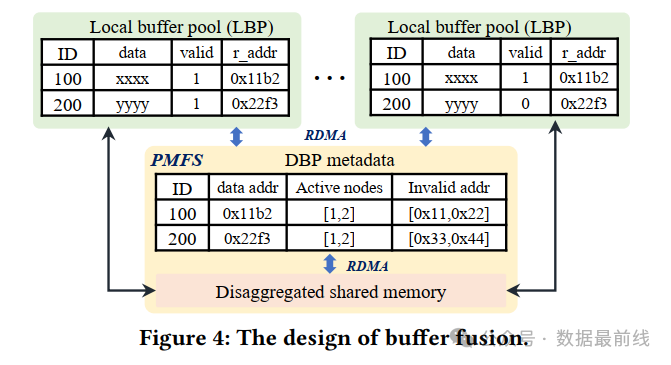
为了便于数据跨节点的快速移动,PolarDB Limitless 构建了**分布式缓冲池 (DBP),节点通过RDMA直接访问其他节点的修改数据,避免存储I/O开销。本地缓冲池 (LBP) 是 DBP 的子集,通过无效标记 (valid flag) ** 确保缓存一致性,实现高效数据传播。
锁融合机制
锁融合实现了页锁和行锁两种机制。
页锁类似于单节点数据库中的页面锁存器,确保对页面的原子访问和内部结构的一致性,保障物理数据一致性,支持跨节点并发访问,采用惰性释放策略减少RPC开销。
行锁遵循通常在许多数据库中使用的两阶段锁定协议,在节点之间保持事务一致性。嵌入事务ID至行数据,结合TIT检测锁冲突,仅需维护等待关系,减少消息传递。
写在最后
曾几何时,共享存储的数据库集群被认为是数据库领域的难点,Oracle RAC是这个领域的绝对王者。如今PolarDB凭借与RDMA技术的深度整合及共享内存的解耦,解决了多主数据库在高冲突场景下的性能瓶颈,在保证了分布式高扩展性、满足数据强一致性的同时,又消除了读写节点之间的延时,为云原生数据库提供了新范式。
