




概述
VictoriaLogs 是一款新兴且具有潜力的日志管理工具,与 VictoriaMetrics 隶属于同一个开发团队。值得注意的是,VictoriaLogs 并非基于 VictoriaMetrics 构建,而是一个独立的项目。与其竞争对手相比,VictoriaLogs 的设计更加轻量化,最大的特点之一便是其架构和使用方式。VictoriaLogs 可以作为一个独立的日志管理系统使用,也可以作为类似于 grep
的命令行工具使用。在查询接口方面,它提出了一种新的查询语言——LogsQL
,这种语言通常采用 Pipe 的风格。
该项目相对较新,代码的大部分内容来自一个“初始”补丁[1]。目前,团队主要专注于存储(数据库)部分,类似于 VictoriaMetrics。在本文写作时,VictoriaLogs 支持两种日志可视化方式:Grafana 数据源插件[2](未在插件商店提供)和内建 UI。该项目预计将在 2025 年初支持集群模式。
有趣的是,VictoriaLogs 看起来是由社区贡献者提出的,最早可追溯到 2020 年 10 月的 GitHub 问题列表[3]。
本文基于 12 月 24 日的提交记录:e0b2c1c4f5b68070c8945c587e17d6e9415c48b5
进行分析。
代码行数
在深入分析之前,我们先来快速浏览一下代码仓库。VictoriaLogs 与 VictoriaMetrics 以及其他相关项目(如代理和告警服务)都被放在同一个主仓库中[4]。
以下是仓库代码行数的饼图示意:
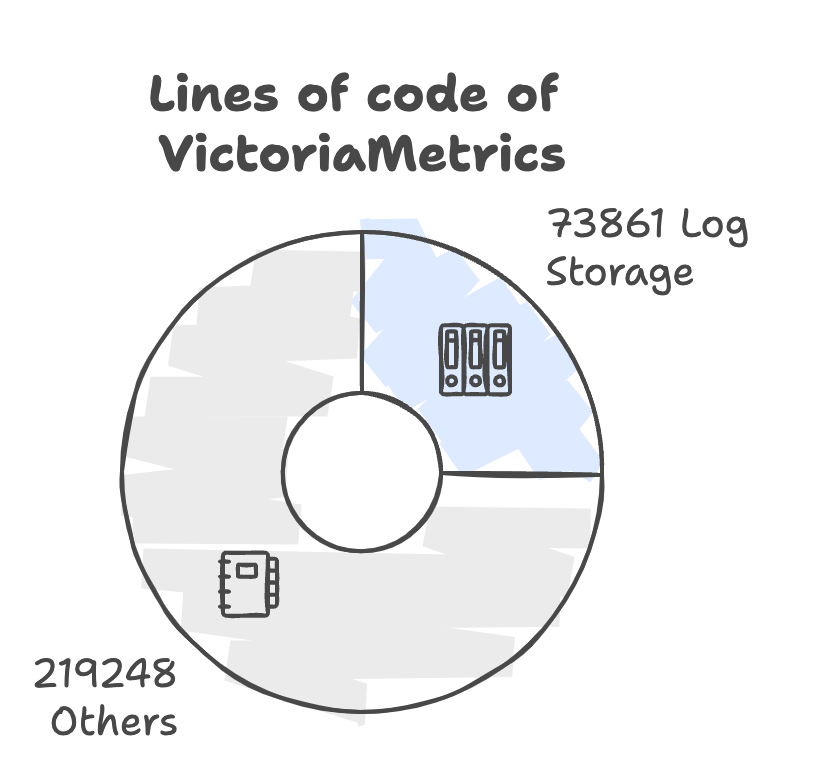
从图中可以看到,Logstorage 包约占据了项目的四分之一。需要说明的是,Logstorage 包并没有大量复用 VictoriaMetrics 的代码,虽然基础组件如 block
、indexdb
等都有所复制,但还是有一些细微差异。这表明该项目相对独立且简洁。
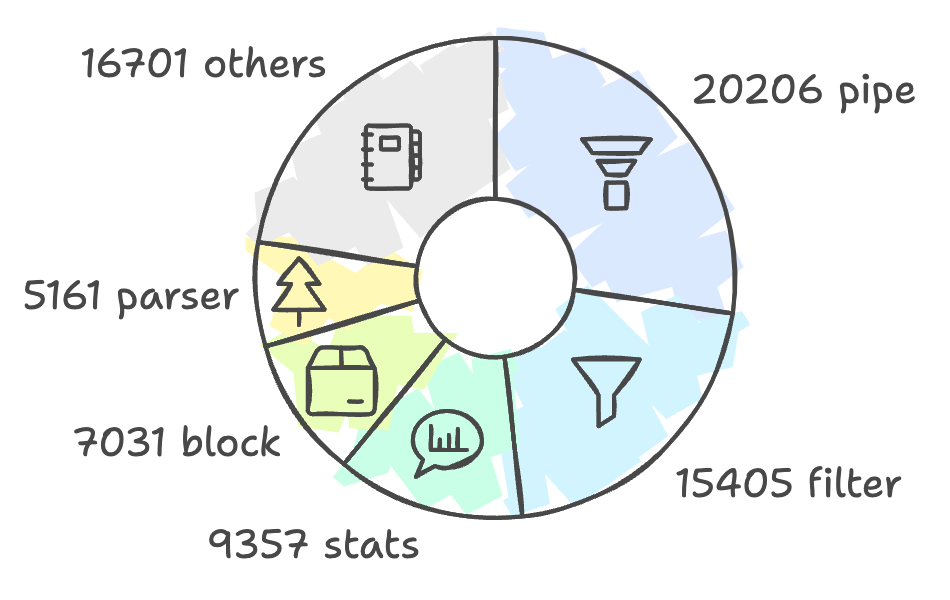
Logstorage 包是 VictoriaLogs 的核心实现部分,包括其查询语言、存储、索引等。上面的图表展示了 Logstorage 包的粗略结构,由几个关键组件组成:管道(pipe)、过滤器(filter)、统计(stats)、块(block)和解析器(parser)等,接下来我们将详细讲解这些组件。
有趣的是,整个项目以及 Logstorage 包中的测试代码大约占到了总代码量的一半。例如,在 Logstorage 中,总共有 73,861 行代码,其中 33,620 行是测试代码。
上述 2 个图表让我们大致了解了项目结构,接下来我们将深入探讨具体的代码实现。
关键概念
首先,我们来看看在 VictoriaLogs(下文将简称 Logstorage)中经常遇到的一些关键概念及其关系。这些概念有的对用户开放,有的则是内部实现:
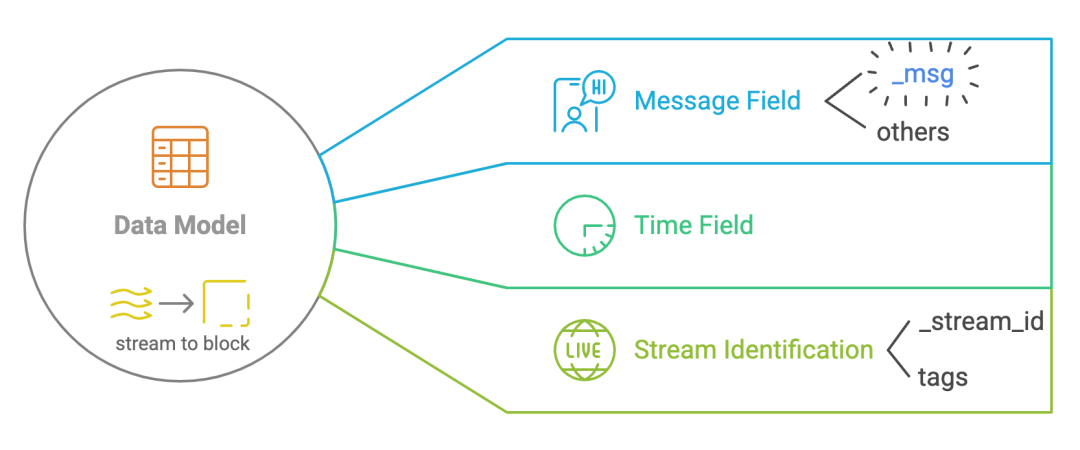
数据模型
Stream:日志数据的高层次表示(类似于数据流)。Stream 用来对日志条目进行逻辑分组。 Block:Stream 中的数据表示。一个 Stream 被划分成多个 Block,以提高存储和检索效率。 Field:日志条目中的字段,类似于数据表中的列。字段可以进一步分为“消息字段(Message Field)”、“时间字段(Time Field)”和“Stream 字段(Stream Field)”。
存储
Partition:数据按时间范围分区,每个分区代表一天( getPartitionForDay
)。这是数据(及其索引)组织的第一层级。DataDB:以块(block)的形式存储日志数据,类似于 LSM 树。 Part:包括 InMemoryPart
和DiskPart
。InMemoryPart
类似于 memtable,必要时会被刷新到DiskPart
。IndexDB:负责管理日志数据的索引,基于 mergeset
。
这些概念会在文件系统中有所体现,以下是 VictoriaLogs 数据目录的文件结构示例:
❯ ll -T victoria-logs-data
Size Name
- victoria-logs-data
0 ├── flock.lock
- └── partitions
- └── 20250113
- ├── datadb
- │ ├── 181A232DC5D34F7D
48M │ │ ├── bloom.bin0
48M │ │ ├── bloom.bin1
54 │ │ ├── column_names.bin
736k │ │ ├── columns_header.bin
78k │ │ ├── columns_header_index.bin
136k │ │ ├── index.bin
0 │ │ ├── message_bloom.bin
0 │ │ ├── message_values.bin
250 │ │ ├── metadata.json
110 │ │ ├── metaindex.bin
21M │ │ ├── timestamps.bin
110M │ │ ├── values.bin0
437M │ │ └── values.bin1
210 │ └── parts.json
- └── indexdb
- ├── 181A232DC5CDBAB4
52 │ ├── index.bin
26 │ ├── items.bin
8 │ ├── lens.bin
163 │ ├── metadata.json
51 │ └── metaindex.bin
20 └── parts.json复制
查询
Search:对 Logstorage 的查询称为“搜索”(search)。 Tokenizer:分词器(tokensize)用于将日志条目进行分词,以便高效的搜索和索引。 Filter:各种过滤器(filter,如时间范围、字符串匹配、正则表达式等)用于筛选日志条目。
这里可以提供一个具体的 LogsQL 查询示例,如下所示:
_time:5m log.level:error -app:(buggy_app OR foobar) | delete host, app | stats count() errors复制
Utilities
ChunkedAllocator:通过分块分配内存来减少开销。 Encoding:处理日志数据的编码和解码。 Hasher:提供日志条目的哈希函数。 Parser:解析(parser)日志条目和查询。
Storage
在存储部分,我们将介绍如何处理日志的接收请求,数据如何存储,以及如何维护相关结构。
Ingest(数据接收)
接收到的日志数据会被解析,以识别租户、流标签、时间戳等。日志数据的表示如下:
// LogRows holds a set of rows needed for Storage.MustAddRows
//
// LogRows must be obtained via GetLogRows()
type LogRows struct {
streamIDs []streamID
timestamps []int64
// Field is key-value pairs
rows [][]Field
// streamFields contains names for stream fields
streamFields map[string]struct{}
// ignoreFields contains names for log fields, which must be skipped during data ingestion
ignoreFields map[string]struct{}
// extraFields contains extra fields to add to all the logs at MustAdd().
extraFields []Field
// extraStreamFields contains extraFields, which must be treated as stream fields.
extraStreamFields []Field
// ...omitted
}复制
streamID
是流的唯一标识符,可以用在 indexdb 中定位流或根据用户进行过滤。streamID
是通过在 MustAdd
方法中对流标签和租户 ID 进行哈希生成的。从技术上讲,streamID
也可以在 VictoriaLogs 外生成。
日志行会被批量处理到一个不能被搜索的内存部分。每个 LogRows
会被转换为 inmemoryPart
。当批量处理的数据量足够大,或者经过一定时间后,会创建一个块并写入磁盘(mustWriteTo
)。blockStreamWriter
负责这一过程,此外还包括相关的索引结构(如 blockHeader
等)和布隆过滤器。
indexdb
会更新,来确保每个 streamID
在 indexdb
中都已注册(通过 mustRegisterStream
),以便后续查询能够定位到新的数据。
这些内存部分会定期合并并刷新到长期存储中,以便高效查询。这一过程由 datadb
完成。
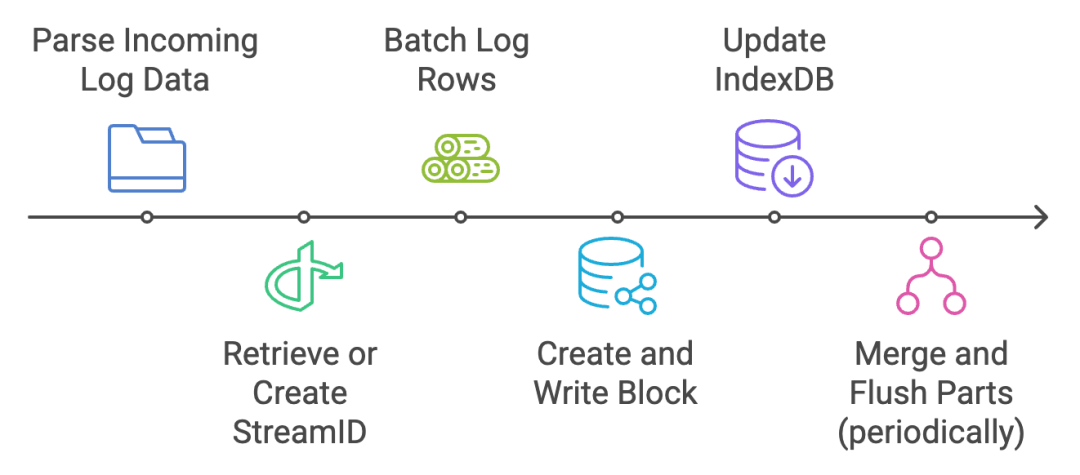
上面描述了处理数据接收请求的基本流程。在协议层面,VictoriaLogs 支持主流的协议,如 Grafana Loki、jsonline、Elasticsearch、OpenTelemetry、syslog 等。像 Fluent Bit、Logstash、Fluentd 和 Vector 这样的代理(日志收集器)可以将日志发送到 VictoriaLogs。
p.s. GreptimeDB 的日志引擎设计也是同样的考虑,希望尽量降低用户的迁移成本。(编者注)
存储:块(block)
block 是日志数据的物理抽象。存储中还有另一个类似的“block
”和“indexdb
”,但它们是不同的结构。比如,日志存储中的 block
用于存储字符串日志数据,而存储中的 indexdb
并没有“流”的概念。相关概念的层级关系如下:block <- part <- partition
。
关于 block
的一些基本信息,其中许多是从 part
继承的:
来自同一流(stream)的日志条目会被打包在同一个块中。 每个块(block)包含覆盖所有日志中唯一字段名称的列(横向分区)。 较小的块会在后台自动合并为更大的块。 超过大小限制的块会被拆分成多个更小的块。 分区:数据按时间范围分区。
一个 block
(内存中的表示)简单定义如下:
// block represents a block of log entries.
type block struct {
// timestamps contains timestamps for log entries.
timestamps []int64
// columns contains values for fields seen in log entries.
columns []column
// constColumns contains fields with constant values across all the block entries.
constColumns []Field
}复制
在生成一个块时,日志条目会被编码并存储在文件系统中。在这个过程中,会用一些“编码”操作:
数据会使用一些特定类型(整数、浮动、ipv4、时间戳)进行编码,这些类型会直接从日志内容中动态探测。 字符串编码类似于 Arrow 的 BytesArray
:使用一个数字数组记录长度,并使用一个字节数组存储字符串内容。通常的压缩方法(如 zstd)也会应用于序列化后的二进制数据。
其他结构,如布隆过滤器和索引,也会一同生成并存储在同一个目录中。
存储:IndexDB
VictoriaLogs 维护一个 LSM(合并集)用于存储流的元数据。它提供准确的点查询和基于流 ID 的过滤功能(类似时序数据库):
func (idb *indexdb) searchStreamIDs(tenantIDs []TenantID, sf *StreamFilter) []streamID {}复制
StreamFilter
是一个简单的过滤条件,用于标签(例如 _stream:{...}
)。
存储:缓存(Cache)
logstorage
维护了一个非常简单的缓存实现,用于存储 streamID,并支持 filterStream
进行快速访问。InMemoryParts
也可以视作缓存,但它更像是一个来自磁盘的数据缓冲区,我们这里不再深入讨论。
缓存结构是一个双缓冲的映射,定义如下:
type cache struct {
curr atomic.Pointer[sync.Map]
prev atomic.Pointer[sync.Map]
stopCh chan struct{}
wg sync.WaitGroup
}复制
curr
和prev
:指向缓存的原子指针(sync.Map
)。stopCh
和wg
:用于优雅地关闭缓存(是的,这个缓存不仅仅是一个“算法”)。
系统会定期清理缓存,以交换当前缓存和上一个缓存。清理方法就是简单地交换当前缓存和上一个缓存。我很想了解这种实现与传统的 LRU 缓存相比性能如何。我几乎可以断言它会更快,但我很好奇具体差距有多大。我记得有类似的实现[5],其目标是简洁性和性能。
在查询时,首先会尝试在当前缓存中查找,然后在上一个缓存中查找。如果缓存未命中,再查询 indexdb
。
这是系统中缓存的一小部分。系统中还有许多其他即时缓存,如块的元数据、布隆过滤器等,它们也只是简单的内存映射。
查询
从高层次来看,查询的功能可以分为过滤器(filter,用于定位想要查询日志的方式)和管道(pipe,用于转化或处理查询结果的方式)。
过滤器:过滤器是根据特定标准(例如时间范围、单词匹配、字段值等)缩小日志消息范围的构建块。过滤器包括时间过滤器、单词/短语/前缀过滤器、流过滤器、范围过滤器等。 管道:一旦过滤器选择了一些日志,管道便允许你转换或处理这些结果。例如: 按时间排序( _time
),将日志按时间顺序重新排序。限制返回前 N 条结果( limit <N>
)。计算( stats
)聚合指标,如统计日志的数量。
查询:过滤器(filter)
VictoriaLogs 提供了多种过滤机制,以便高效查询和筛选日志条目。
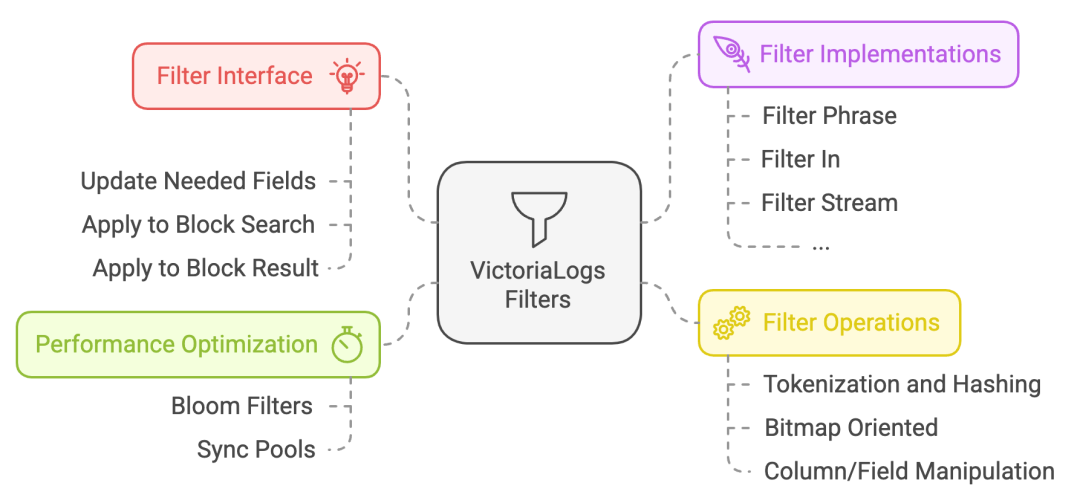
接口定义如下:
// filter must implement filtering for log entries.
type filter interface {
// String returns string representation of the filter
String() string
// udpdateNeededFields must update neededFields with fields needed for the filter
updateNeededFields(neededFields fieldsSet)
// applyToBlockSearch must update bm according to the filter applied to the given bs block
applyToBlockSearch(bs *blockSearch, bm *bitmap)
// applyToBlockResult must update bm according to the filter applied to the given br block
applyToBlockResult(br *blockResult, bm *bitmap)
}复制
applyToBlockSearch
和 applyToBlockResult
具有类似的逻辑。在查询时,首先通过 applyToBlockSearch
将过滤器应用于存储的数据,并生成初步的过滤结果。如果有管道(pipe)操作,则可能会根据实现调用 applyToBlockResult
进行后过滤。
过滤器的工作方式是——首先在块层面时使用布隆过滤器快速排除不匹配的块,然后检查每个块中的日志条目,并将结果设置为位图(bitmap),用于标识日志条目是否匹配。
查询:管道(pipe)
在 LogSQL 中,管道的使用方式示例如下:
_time:5m error | sort by (_time) desc | limit 10 | stats count()复制
管道的主要特点:
在经过所有过滤器之后运行(过滤器管道可以进行后过滤)。 执行时采用推送模式: 过滤器将结果“推送”到管道处理器,操作在块层面进行。 管道处理器将其中间结果“推送”到下一个管道。 结果由最终的收集器收集。 接口: pipe
和pipeProcessor
的接口非常简单,可以简化为某种函数指针。
在各种管道中,统计管道(stat
pipe
)是个例外,因为它相对复杂。它可以视为日志搜索的第三大核心概念。它是一种“UDAF”(用户自定义聚合函数),用于计算日志条目。常见的计算如 min()
、count()
、uniq()
(唯一值)或 quantile()
(分位数)等都是内置支持的。
管道和统计操作都容易扩展,而查询功能的主要部分在这些形式中实现。日志查询通常不需要像通用 SQL 那样复杂的计算或关系,因此这个框架能够很好地满足大部分需求。
其他部分
JSON
VictoriaLogs 会在数据摄取过程中通过系统化的扁平化过程自动将多层(嵌套)JSON 转换为单层 JSON[6]。 嵌套的字典通过使用 .
连接键(例如:host.os.version
)。数组、数字和布尔值将被转换为字符串。
对象池优化
type tokenizer struct {
m map[string]struct{}
}
func getTokenizer() *tokenizer {
v := tokenizerPool.Get()
if v == nil {
return &tokenizer{
m: make(map[string]struct{}),
}
}
return v.(*tokenizer)
}
func putTokenizer(t *tokenizer) {
t.reset()
tokenizerPool.Put(t)
}复制
Arena
arena
用于高效的内存分配,缓存对象以避免重复创建和销毁这些对象。在小的内存分配(如查询处理)中,arena
在 13 个管道处理器(总共 30 多个)和其他杂项结构(如读取器、中间结果、编解码器等)中被使用。
p.s. VictoriaLogs 作为日志管理领域的新锐力量值得关注,而 GreptimeDB 的目标则是创新性地整合日志、指标、链路追踪三大可观测数据,打造统一管理平台。通过可插拔引擎与多协议支持提升系统灵活性,并依托存算分离架构实现降本增效,兼具弹性扩展与跨云兼容双重优势。(编者注)
🔎 原文在这里:
https://blog.waynest.com/2025/01/victorialogs-source-reading/
参考
[1] https://github.com/VictoriaMetrics/VictoriaMetrics/commit/87b66db47da23cb9fe800ce16efa6bdac365f5a8
[2] https://github.com/VictoriaMetrics/victorialogs-datasource/
[3] https://github.com/VictoriaMetrics/VictoriaMetrics/issues/816
[4] https://github.com/VictoriaMetrics/VictoriaMetrics/
[5] https://github.com/waynexia/texn/blob/master/src/dropmap.rs
[6] https://docs.victoriametrics.com/victorialogs/keyconcepts/
[7] CTO’s overview slides about VL in 2023.05: https://www.slideshare.net/slideshow/victorialogs-previewpdf/257033587
[8] Repository: VictoriaMetrics’ main repository and the logstorage dir
[9] Key Concepts chapter from VictoriaLogs docs: https://docs.victoriametrics.com/victorialogs/keyconcepts/
[10] LogsQL reference: https://docs.victoriametrics.com/victorialogs/logsql/
❝关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
官网:https://greptime.cn/
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
往期精彩文章:
点击「阅读原文」,立即体验 GreptimeDB!




