




创建一个hash分区表(暂时不考虑二级分区),可以使用自定义分区,也可以通过指定分区数。
通过自定义分区
CREATE TABLE sales_info_hash
(year CHAR(4) NOT NULL,
month CHAR(2) NOT NULL,
branch CHAR(4),
product CHAR(5),
quantity NUMBER DEFAULT 0 NOT NULL,
amount NUMBER(10,2) DEFAULT 0 NOT NULL,
salsperson CHAR(10))
PARTITION BY HASH(year)
(PARTITION p_sales_info_hash_1,
PARTITION p_sales_info_hash_2);通过分区数
CREATE TABLE sales_info_hash
(year CHAR(4) NOT NULL,
month CHAR(2) NOT NULL,
branch CHAR(4),
product CHAR(5),
quantity NUMBER DEFAULT 0 NOT NULL,
amount NUMBER(10,2) DEFAULT 0 NOT NULL,
salsperson CHAR(10))
PARTITION BY HASH(year)
PARTITIONS 4;在hash分区表创建完成之后,能否添加分区?如果能那么怎么添加?添加的时候数据是否会自动重分布?如果重分布那么对于现有的业务会有什么影响?
这些问题我们可以通过查询官方文档以及相关测试来获取答案。
能否添加分区?——能,使用alter table add 即可
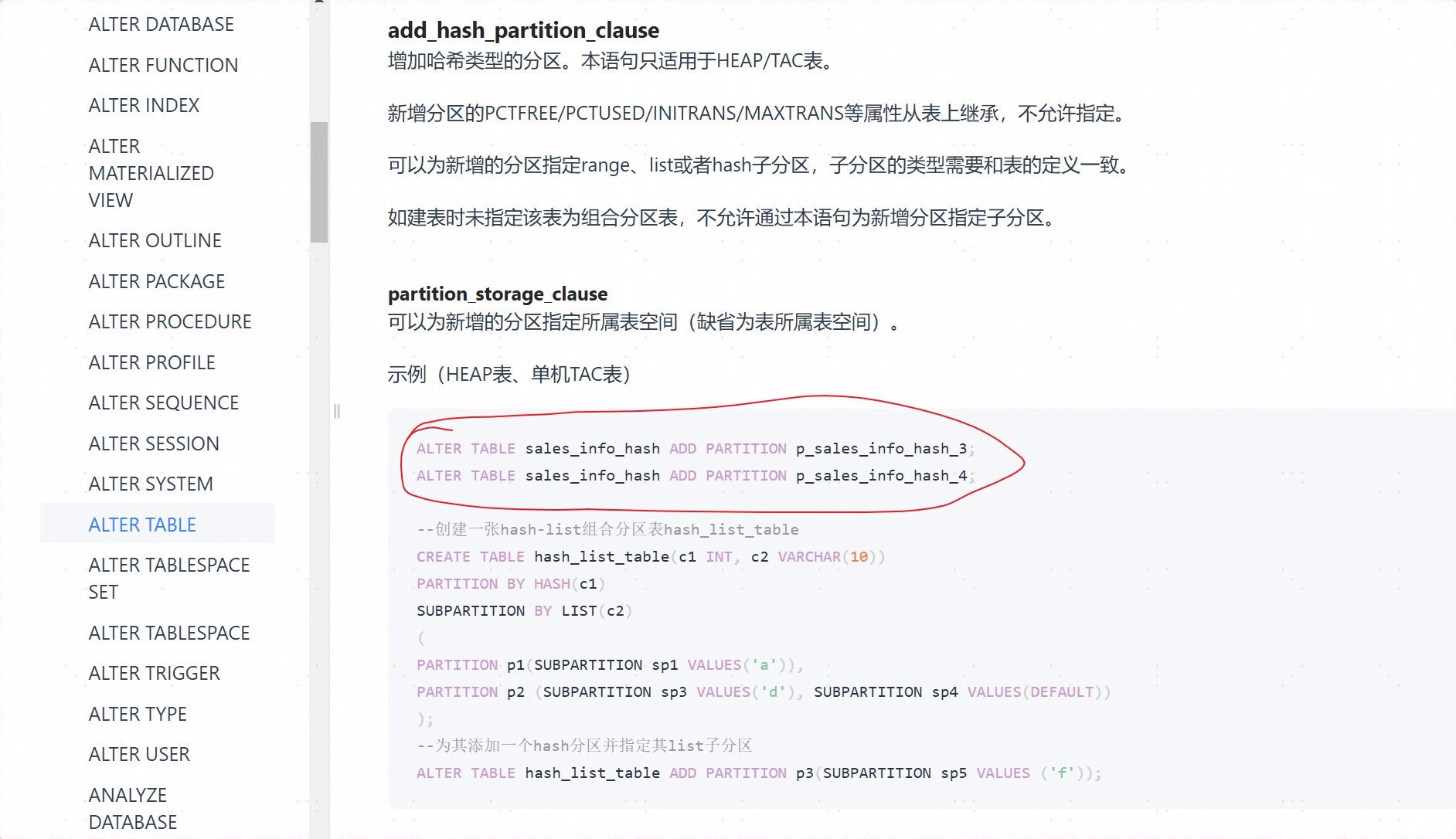
添加的时候数据是否会自动重分布?——会
CREATE TABLE hash_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY HASH (prod_id)
11 PARTITIONS 4;
Succeed.
SQL> select PARTITION_NAME,num_rows from user_tab_partitions where table_name ='HASH_SALES';
PARTITION_NAME NUM_ROWS
---------------------------------------------------------------- ---------------------
SYS_P12
SYS_P13
SYS_P14
SYS_P15
4 rows fetched.
-- 插入数据
INSERT INTO hash_sales (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold)
VALUES (101, 1001, TO_DATE('2023-10-01', 'YYYY-MM-DD'), 'A', 201, 2, 99.99);
1 row affected.
SQL>
INSERT INTO hash_sales (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold)
VALUES (102, 1002, TO_DATE('2023-10-02', 'YYYY-MM-DD'), 'B', 202, 1, 49.99);
1 row affected.
SQL>
INSERT INTO hash_sales (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold)
VALUES (103, 1003, TO_DATE('2023-10-03', 'YYYY-MM-DD'), 'C', 203, 3, 149.97);
1 row affected.
SQL>
INSERT INTO hash_sales (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold)
VALUES (104, 1004, TO_DATE('2023-10-04', 'YYYY-MM-DD'), 'A', 204, 5, 249.95);
1 row affected.
SQL>
INSERT INTO hash_sales (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold)
VALUES (105, 1005, TO_DATE('2023-10-05', 'YYYY-MM-DD'), 'B', 205, 2, 99.98);
1 row affected.
SQL>
INSERT INTO hash_sales (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold)
VALUES (106, 1006, TO_DATE('2023-10-06', 'YYYY-MM-DD'), 'C', 206, 1, 29.99);
1 row affected.
SQL>
INSERT INTO hash_sales (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold)
VALUES (107, 1007, TO_DATE('2023-10-07', 'YYYY-MM-DD'), 'A', 207, 4, 199.96);
1 row affected.
SQL>
INSERT INTO hash_sales (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold)
VALUES (108, 1008, TO_DATE('2023-10-08', 'YYYY-MM-DD'), 'B', 208, 3, 149.97);
1 row affected.
SQL>
INSERT INTO hash_sales (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold)
VALUES (109, 1009, TO_DATE('2023-10-09', 'YYYY-MM-DD'), 'C', 209, 2, 99.98);
1 row affected.
SQL>
INSERT INTO hash_sales (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold)
2 VALUES (110, 1010, TO_DATE('2023-10-10', 'YYYY-MM-DD'), 'A', 210, 1, 49.99);
1 row affected.
SQL>
SQL>
SQL> select PARTITION_NAME,num_rows from user_tab_partitions where table_name ='HASH_SALES';
PARTITION_NAME NUM_ROWS
---------------------------------------------------------------- ---------------------
SYS_P12
SYS_P13
SYS_P14
SYS_P15
4 rows fetched.
--收集统计信息SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS('SYS', 'HASH_SALES','', 0.2, FALSE, 'FOR ALL COLUMNS SIZE AUTO', 4, 'AUTO', TRUE);
PL/SQL Succeed.
SQL> select PARTITION_NAME,num_rows from user_tab_partitions where table_name ='HASH_SALES';
PARTITION_NAME NUM_ROWS
---------------------------------------------------------------- ---------------------
SYS_P12 2
SYS_P13 3
SYS_P14 2
SYS_P15 3
4 rows fetched.
--添加分区SQL> ALTER TABLE hash_sales ADD PARTITION p_hash_sales_3;
Succeed.
SQL> select PARTITION_NAME,num_rows from user_tab_partitions where table_name ='HASH_SALES';
PARTITION_NAME NUM_ROWS
---------------------------------------------------------------- ---------------------
SYS_P12 2
SYS_P13 3
SYS_P14 2
SYS_P15 3
P_HASH_SALES_3
5 rows fetched.
--收集统计信息SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS('SYS', 'HASH_SALES','', 0.2, FALSE, 'FOR ALL COLUMNS SIZE AUTO', 4, 'AUTO', TRUE);
PL/SQL Succeed.
--数据已经自动重新分布,SYS_P12原本有2条数据,现将1条重分布到新添加的分区P_HASH_SALES_3中了SQL> select PARTITION_NAME,num_rows from user_tab_partitions where table_name ='HASH_SALES';
PARTITION_NAME NUM_ROWS
---------------------------------------------------------------- ---------------------
SYS_P12 1
SYS_P13 3
SYS_P14 2
SYS_P15 3
P_HASH_SALES_3 1
5 rows fetched.
如果重分布那么对于现有的业务会有什么影响?——不会有影响,因为当表上有业务执行时,是不允许添加hash分区的。
模拟TPCC bencharmark 测试,添加分区,报错如下 YAS-02024;当业务执行完成,才能添加成功。
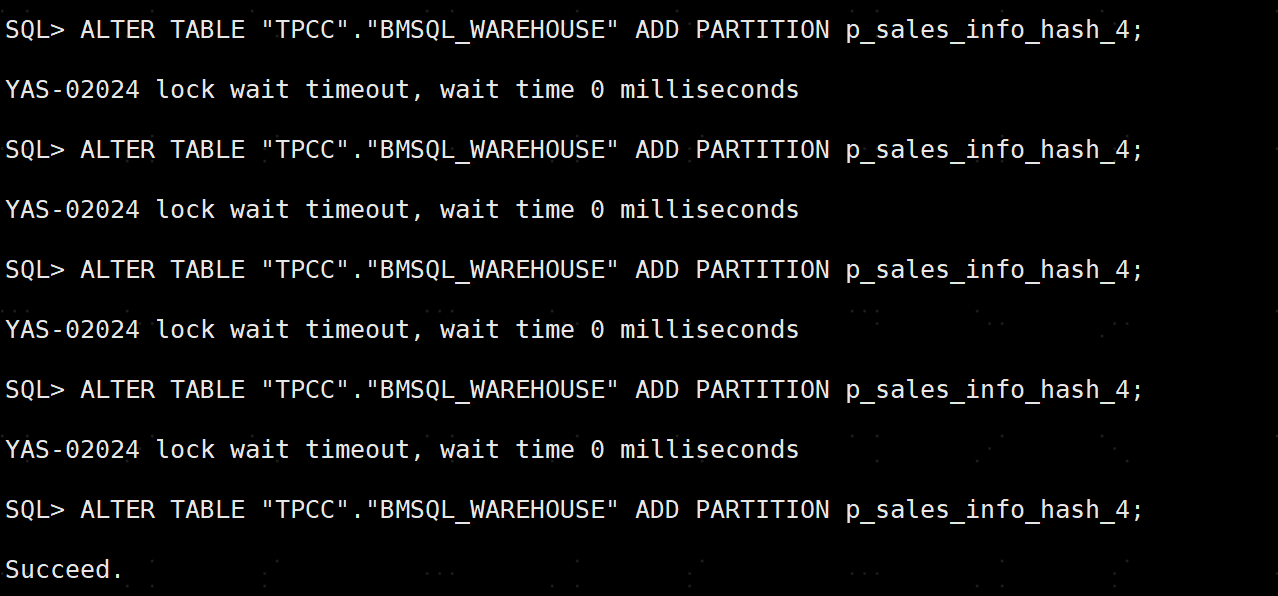
综上, hash分区表建议在规划阶段设计好分区的个数,不要随意变更分区个数;如果后期需要添加分区,需要协调业务,在该表无业务期间进行添加hash分区。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
