




引言
背景
在现代数据密集型应用中,查询性能是数据库优化的关键。特别是在 **梧桐数据库(WuTongDB)**中,作为一个分布式云原生分析型数据库,它的存算分离架构、高效的向量化计算引擎,以及强大的并行处理能力,为大规模数据的高效查询提供了极大的支持。然而,即使如此强大的数据库,在面对复杂的多表关联、子查询等场景时,性能优化仍然至关重要。
目标
本文将通过多个实际案例,结合 梧桐数据库 的查询优化工具,展示如何通过合理的索引设计、查询重写、统计信息更新等方式,优化 SQL 查询性能。我们将从常见的性能问题入手,逐步引导您掌握梧桐数据库优化技巧。
案例一:多表关联查询性能优化
问题描述
我们通过一个典型的多表关联查询来说明性能问题:
select
n_name,
sum(l_extendedprice*(1-l_discount)) as revenue
from customer,orders,lineitem,supplier,nation,region k,
region a,region b,region c,region d,region e,region f,region g,region h,region i,region j
where c_custkey = o_custkey
and l_orderkey = o_orderkey
and l_suppkey = s_suppkey
and c_nationkey = s_nationkey
and s_nationkey = n_nationkey
and n_regionkey = k.r_regionkey
and n_regionkey = a.r_regionkey
and n_regionkey = b.r_regionkey
and n_regionkey = c.r_regionkey
and n_regionkey = d.r_regionkey
and n_regionkey = e.r_regionkey
and n_regionkey = f.r_regionkey
and n_regionkey = g.r_regionkey
and n_regionkey = h.r_regionkey
and n_regionkey = i.r_regionkey
and n_regionkey = j.r_regionkey and a.r_name='AMERICA' and o_orderdate >= date '1997-01-01'
and o_orderdate < date'1998-01-01'+ interval'1 year'
group by
n_name order by
revenue desc;
我们先在梧桐数据库里实际运行下上面的代码,看看效率如何,如下图所示:
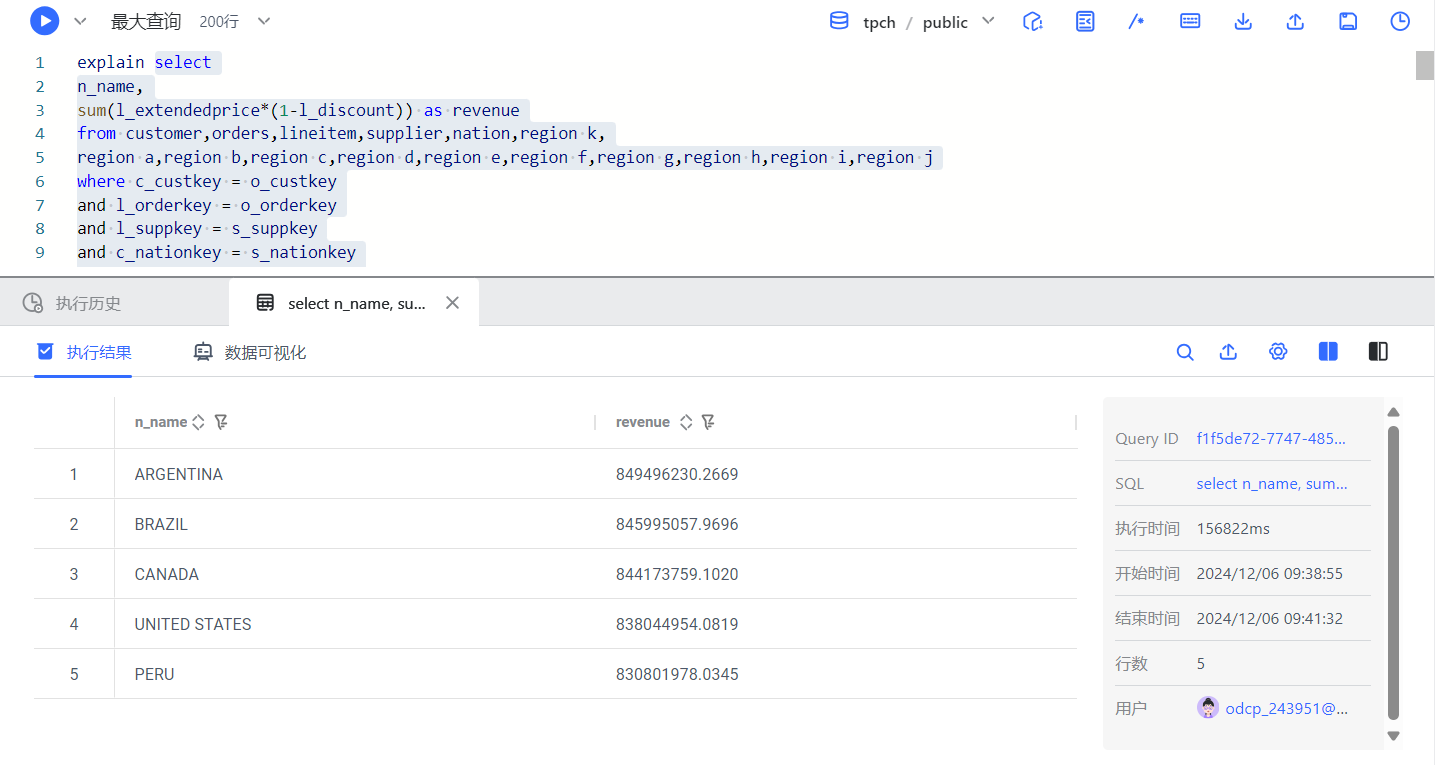
运行查询耗时:156822ms,即 156.822秒,约为 2 分 36.822 秒
发现的问题
上面的 SQL 查询语句耗时 2 分钟以上,明显查询性能低下,导致浪费资源,分析其原因,大概有下面几类:
1、存在多余的 region 表关联
查询中多次将 n_regionkey 与 region k, region a, region b,...进行关联。实际上,n_regionkey 只需要与一个 region 表关联即可。如果需要筛选 AMERICA 的数据,只需保留一张 region 表即可,大量的重复关联会浪费资源。
优化建议:
删除不必要的表关联,保留单一的 region 表:
AND n_regionkey = k.r_regionkey AND k.r_name = 'AMERICA'
2、使用 + interval '1 year' 的问题
o_orderdate < date '1998-01-01' + interval '1 year' 中的计算可以提前完成,避免查询时逐行计算,从而节省时间提升效率。可以将日期范围明确写出。
优化建议:
替换动态计算为明确的日期范围:
AND o_orderdate < DATE '1999-01-01'
3、隐式关联写法的潜在问题
在原题语句中,表之间的关系是通过 WHERE 条件进行定义的,如下:
WHERE c_custkey = o_custkey AND l_orderkey = o_orderkey AND l_suppkey = s_suppkey
这种写法被称为 隐式连接。表之间的关联是通过 WHERE 子句实现的,而不是使用现代的 JOIN 关键字。
缺点:
-
可读性差:
- 隐式连接的逻辑依赖于
WHERE子句,如果表之间的关系较多,会导致语句难以阅读和维护。
- 隐式连接的逻辑依赖于
-
可能导致意外的笛卡尔积:
- 如果不小心遗漏了某些条件,可能会导致不必要的笛卡尔积,从而大幅降低性能。
-
优化器的优化效果较差:
- 现代
SQL优化器在处理显式JOIN时,能够更清楚地理解表之间的关系,生成更高效的查询计划。
- 现代
优化建议:采用显式连接
在这里我们采用显式连接方法, 显式 JOIN 是现代 SQL 的标准语法,能够提升查询的可读性和优化器的效率,如下:
FROM customer JOIN orders ON c_custkey = o_custkey JOIN lineitem ON l_orderkey = o_orderkey JOIN supplier ON l_suppkey = s_suppkey
显式连接的优点:
-
提高可读性:
- 通过
JOIN明确地表达表之间的关系,方便开发者理解查询的逻辑。
- 通过
-
降低出错的可能性:
- 显式连接强制指定表之间的关联条件,减少了意外生成笛卡尔积的风险。
-
更好的优化计划:
- 优化器可以清楚地了解哪些是连接条件,哪些是过滤条件,从而生成更高效的查询计划。
4、复杂的 GROUP BY 和 ORDER BY 操作
原题里的 GROUP BY n_name 和 ORDER BY revenue DESC 会对整个结果集进行排序和分组,这对大数据量表会导致性能瓶颈。
优化建议:
-
减少结果集数据量:
- 提前筛选
o_orderdate和r_name的范围,减少数据规模。
- 提前筛选
-
分步执行:
- 先将筛选后的数据存入临时表,再执行
GROUP BY和ORDER BY操作。
- 先将筛选后的数据存入临时表,再执行
-
缺少索引
查询中涉及多个表的 JOIN 和过滤条件,优化器需要高效定位数据。如果关联字段(如 c_custkey, o_orderkey, l_orderkey 等)没有索引,会导致全表扫描。
优化建议:
为以下字段创建索引:
CREATE INDEX idx_customer_custkey ON customer(c_custkey);
CREATE INDEX idx_orders_orderkey ON orders(o_orderkey);
CREATE INDEX idx_lineitem_orderkey ON lineitem(l_orderkey);
CREATE INDEX idx_supplier_suppkey ON supplier(s_suppkey);
CREATE INDEX idx_nation_nationkey ON nation(n_nationkey);
CREATE INDEX idx_region_regionkey ON region(r_regionkey);
CREATE INDEX idx_region_name ON region(r_name);
CREATE INDEX idx_orders_orderdate ON orders(o_orderdate);
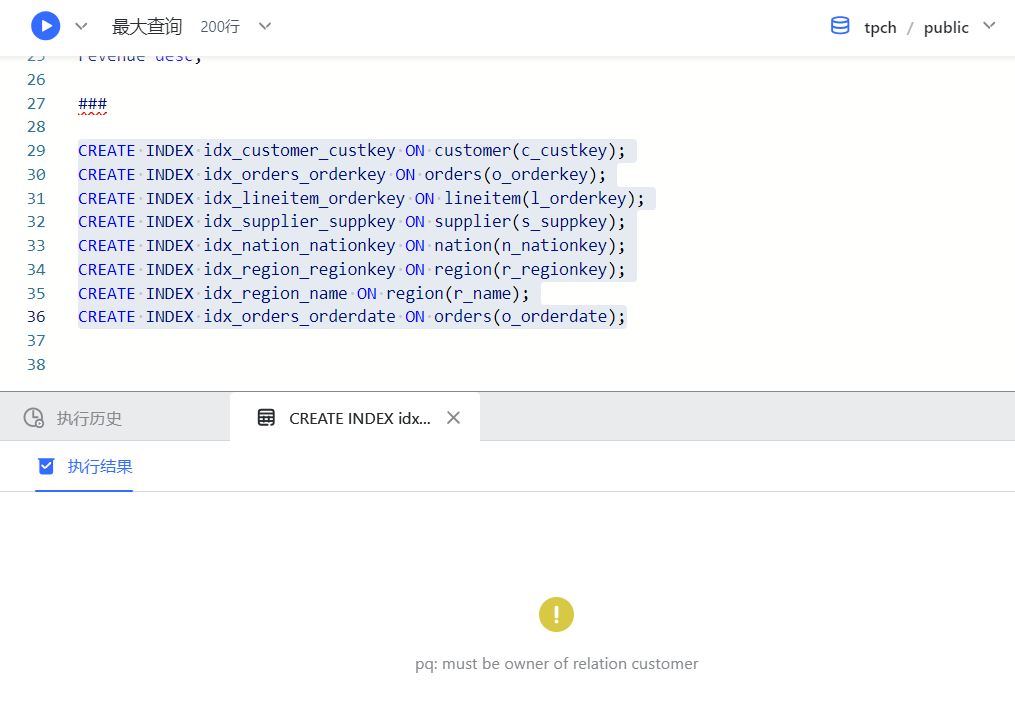
特别注意:以上语句我在执行时,提示我的权限有问题,没执行成功,如下图所示:不过不影响优化分析的思路
优化后的查询语句
SELECT
n_name,
SUM(l_extendedprice * (1 - l_discount)) AS revenue
FROM
customer
JOIN orders ON c_custkey = o_custkey
JOIN lineitem ON l_orderkey = o_orderkey
JOIN supplier ON l_suppkey = s_suppkey
JOIN nation ON c_nationkey = n_nationkey
JOIN region k ON n_regionkey = k.r_regionkey
WHERE
k.r_name = 'AMERICA'
AND o_orderdate >= DATE '1997-01-01'
AND o_orderdate < DATE '1999-01-01'
GROUP BY
n_name
ORDER BY
revenue DESC;
优化结果结比
优化后,可以显著降低执行计划的复杂性,减少数据扫描量和计算量。具体效果见下面的优化前后结果与实测图:
| 优化前查询耗时(毫秒) | 优化后查询耗时(毫秒) | 耗时缩小比例 |
|---|---|---|
| 156822 | 3789 | 4138.88% |
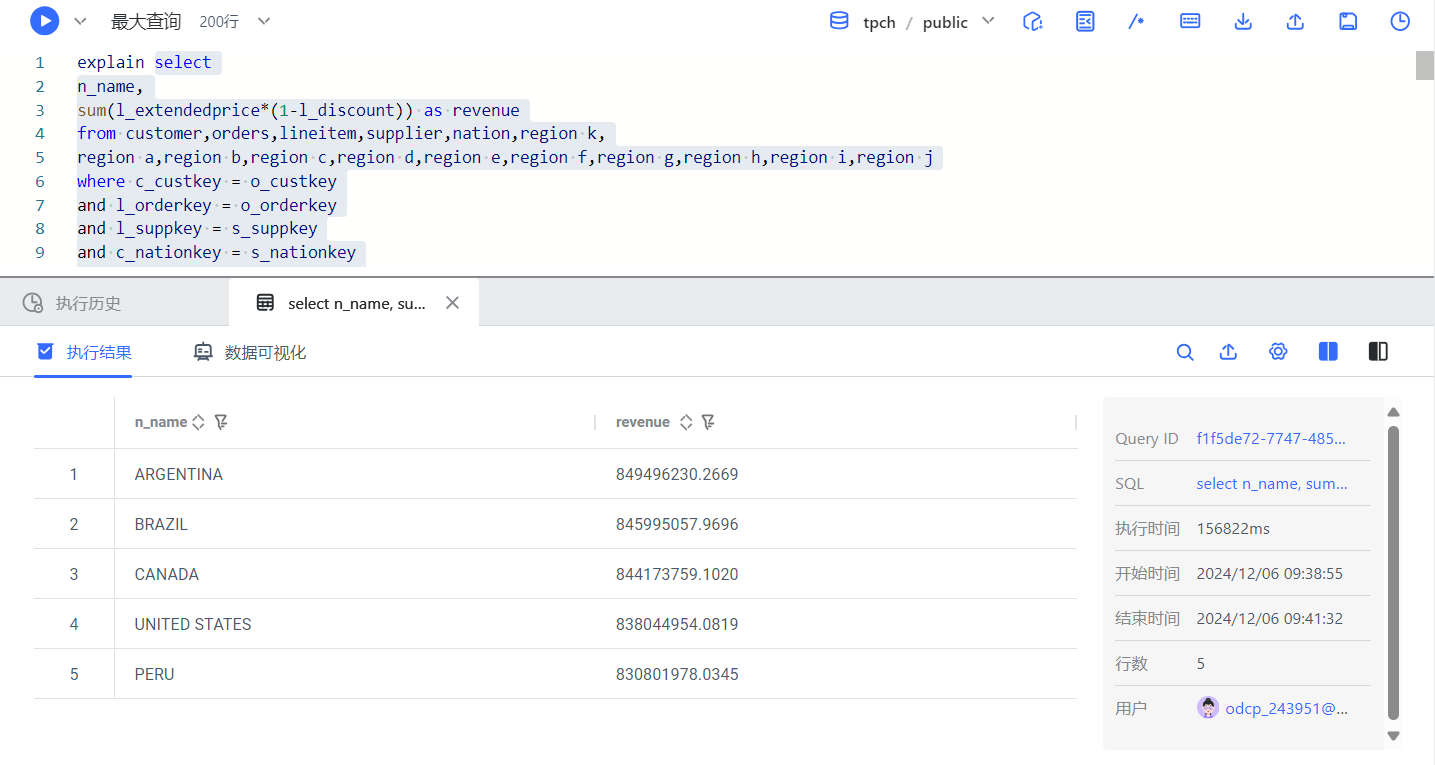
-
优化前执行结果
查询耗时:156822ms,即 156.822秒,约为 2 分 36.822 秒*
-
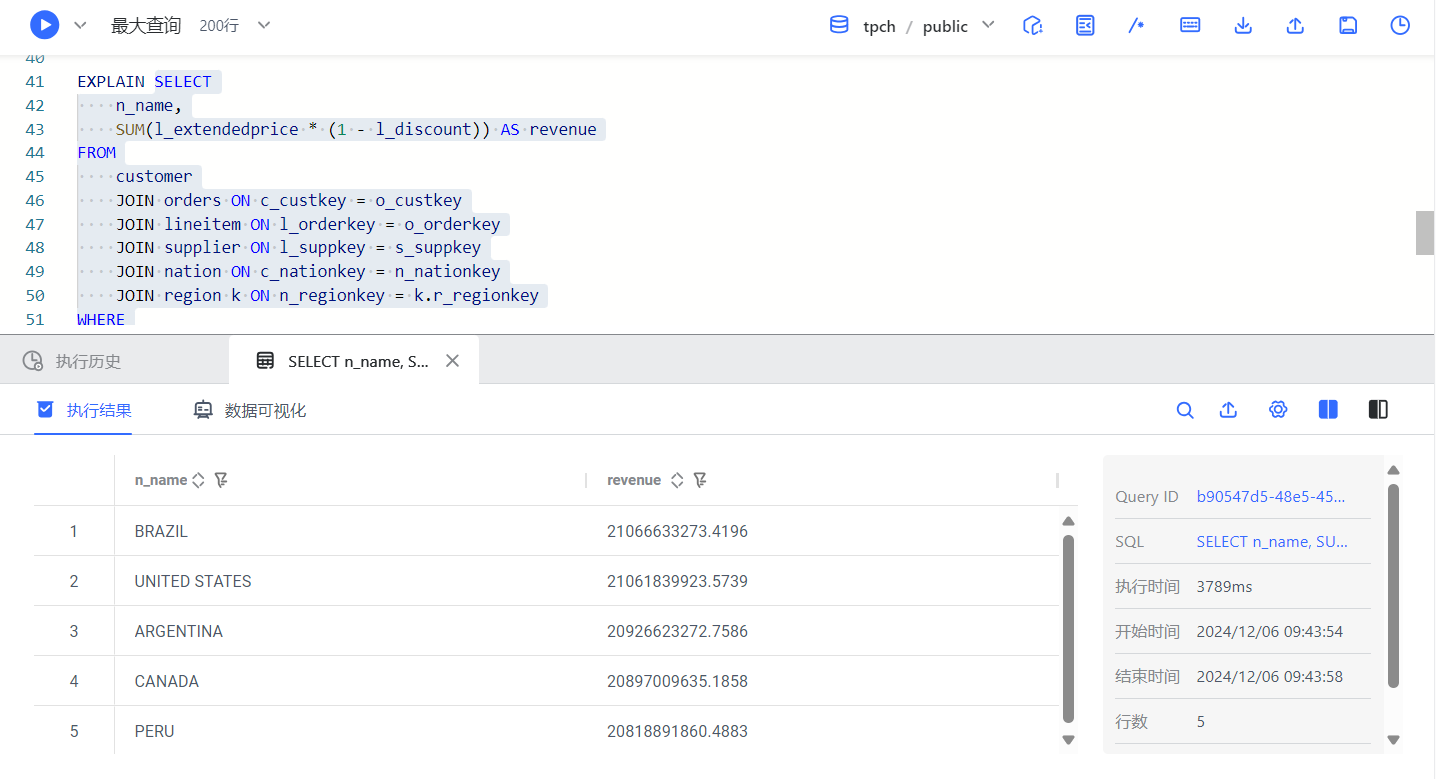
优化后执行结果
查询耗时:3789ms,即 3.789 秒*
知识点总结
- **合理的关联:**通过消除冗余关联、显式连接、减少动态计算和优化索引,显著提升查询性能。
- **显式连接:**使用显式连接和合适的索引,帮助优化器生成高效的查询计划。
- **定期更新统计信息:**以确保优化器在生成查询计划时能够做出准确的决策。
案例二:子查询性能优化
问题描述
SELECT COUNT(*)
FROM customer a
WHERE (c_custkey, c_nationkey) NOT IN (
SELECT o_custkey, o_orderkey
FROM orders
);
发现的问题
NOT IN的低效:NOT IN需要生成完整的子查询结果集,并逐行比较,效率较低。- 空值问题:如果
orders表中的o_custkey或o_orderkey存在NULL,会导致NOT IN查询结果为空。
优化方案
-
替换
NOT IN为NOT EXISTS:SELECT COUNT(*) FROM customer a WHERE NOT EXISTS ( SELECT 1 FROM orders b WHERE a.c_custkey = b.o_custkey AND a.c_nationkey = b.o_orderkey ); -
添加索引:
CREATE INDEX idx_orders_cust_order ON orders(o_custkey, o_orderkey);
知识点总结
- 子查询优化:使用
NOT EXISTS替代NOT IN可以提高查询性能。 - 索引优化:为子查询和主查询的连接字段创建索引,提高查找效率。
案例三:聚合查询的性能优化
问题描述
SELECT
l_shipmode,
SUM(CASE WHEN l_commitdate < l_receiptdate THEN 1 ELSE 0 END) AS shipped,
SUM(CASE WHEN l_commitdate >= l_receiptdate THEN 1 ELSE 0 END) AS delayed
FROM lineitem
GROUP BY l_shipmode;
发现的问题
- 无分区导致全表扫描:对
lineitem表没有分区,导致扫描了所有记录。 - 无索引导致聚合成本高:未对
l_commitdate和l_receiptdate创建索引。
优化方案
-
按日期分区表:
CREATE TABLE lineitem_partitioned PARTITION BY RANGE (l_shipdate) ( PARTITION p1997 VALUES LESS THAN ('1998-01-01'), PARTITION p1998 VALUES LESS THAN ('1999-01-01') ); -
创建索引:
CREATE INDEX idx_lineitem_commit_receipt ON lineitem(l_commitdate, l_receiptdate);
知识点总结
- 分区表的使用:分区减少扫描数据量,提高查询效率,尤其在大表场景下。
- 索引设计:对于聚合查询,涉及的字段应尽量加索引,以加速计算。
案例四:排序与分页的优化
问题描述
SELECT *
FROM orders
WHERE o_orderdate >= '1997-01-01'
ORDER BY o_orderdate DESC
LIMIT 10;
发现的问题
- 排序操作耗时:没有索引,导致全表排序。
- 扫描无效数据:未提前裁剪查询范围。
优化方案
-
创建索引:
CREATE INDEX idx_orders_orderdate_desc ON orders(o_orderdate DESC); -
利用索引加速排序:
EXPLAIN ANALYZE SELECT * FROM orders WHERE o_orderdate >= '1997-01-01' ORDER BY o_orderdate DESC LIMIT 10;
知识点总结
- 索引排序:通过有序索引减少排序开销。
- LIMIT 优化:配合索引直接读取目标数据,避免全表扫描。
在梧桐数据库中进行参数调优
参数调优内容
-- 内存相关
SET work_mem = '128MB';
SET maintenance_work_mem = '512MB';
-- 并行查询
SET max_parallel_workers_per_gather = 4;
SET gp_segments_for_planner = 8;
-- 优化器
SET join_collapse_limit = 16;
SET from_collapse_limit = 16;
SET enable_hashjoin = ON;
SET enable_mergejoin = ON;
SET enable_seqscan = OFF;
-- 缓存与统计信息
SET effective_cache_size = '16GB';
SET default_statistics_target = 500;
-- 更新统计信息
ANALYZE customer;
ANALYZE orders;
ANALYZE lineitem;
参数调优解析
-
增大工作内存:work_mem
问题:排序、哈希表等操作可能消耗较多内存,默认的 work_mem(如 4MB)可能不足,导致使用临时文件。
解决:增加 work_mem,以支持更高效的内存排序和哈希操作。
SET work_mem = '128MB'; -
提高 join 展开数量: join_collapse_limit
问题:默认情况下,数据库会限制查询计划的多表 JOIN 展开(默认值为 8)。
解决:提高 join_collapse_limit 以支持更多表的 JOIN 优化。
SET join_collapse_limit = 16; -
调整有效缓存大小:effective_cache_size
问题:默认的 effective_cache_size 配置可能过低,导致优化器误判索引成本。
解决:设置合理值,例如系统总内存的 50-75%:
SET effective_cache_size = '4GB'; -
更新统计信息
问题:如果统计信息过时,优化器可能无法正确估算数据量和分布。
解决:手动更新表的统计信息:
ANALYZE; -
enable_hashjoin
作用:启用或禁用 Hash Join 策略。
优化建议:针对大表关联,强制启用 Hash Join。
示例:
SET enable_hashjoin = ON; -
enable_mergejoin
作用:启用或禁用 Merge Join 策略。
优化建议:针对排序较好的数据,启用 Merge Join 以减少内存使用。
示例:
SET enable_mergejoin = ON; -
from_collapse_limit
作用:控制子查询折叠的最大表数量。
优化建议:提高限制值,允许优化器将多个子查询合并为一个主查询。
示例:
SET from_collapse_limit = 16; -
optimizer
作用:启用基于成本的优化器。
优化建议:确保启用优化器以生成高效的查询计划。
示例:
SET optimizer = ON; -
effective_cache_size
作用:提示优化器操作系统缓存的能力。
优化建议:设置为物理内存的 50%-75%,提高索引使用效率。
示例:
SET effective_cache_size = '16GB'; -- 假设系统总内存为 32GB -
default_statistics_target
作用:控制统计信息的采样精度,影响优化器的行数估算。
优化建议:提高该值以生成更准确的统计信息。
示例:
SET default_statistics_target = 500; -
分析查询计划
使用 JSON 格式的查询计划进行分析,便于捕获瓶颈节点。
EXPLAIN (FORMAT JSON) SELECT ...; -
强制计划生成策略
针对特定场景,可以强制使用索引扫描或特定的 JOIN 策略:
SET enable_seqscan = OFF; -- 禁用全表扫描 -
索引使用检查
确保查询计划中关键字段使用了索引:
CREATE INDEX idx_orders_orderdate ON orders(o_orderdate); CREATE INDEX idx_customer_custkey ON customer(c_custkey);
知识点总结与实践方法
通过多表查询、子查询、聚合查询等实际场景的优化,展示了如何在梧桐数据库中实现高效查询。
强调了 索引、JOIN 策略、统计信息、分区表 等核心概念,并通过梧桐数据库提供的优化工具有效提升查询性能。
- 索引设计:为常用过滤和连接字段创建索引。
- JOIN 策略:根据数据量和查询模式选择合适的连接策略(如
Hash Join或Merge Join)。 - 分区表和分布式优化:适用于大数据场景,分区表和数据分布策略显著提高查询性能。
- 统计信息的更新与维护:保持统计信息最新是优化查询性能的前提。
附录:
EXPLAIN 命令解析:
1)什么是 EXPLAIN 命令?
EXPLAIN 命令是**梧桐数据库(WuTong)**提供的用于显示数据库执行某个查询时生成的执行计划。执行计划告诉你数据库是如何执行这条 SQL 语句的,包含了查询使用的操作(如扫描、连接、排序等)、每个操作的成本、执行顺序以及其他详细信息。
通过查看查询计划,我们可以了解:
- 查询是如何从数据库中获取数据的。
- 每个操作的开销成本。
- 是否有不必要的全表扫描(
Seq Scan)或低效的连接方式(Nested Loop)。
2)EXPLAIN 输出的主要内容
运行 EXPLAIN 命令后,会得到一个查询计划的输出。输出通常包含以下几部分内容:
-
查询节点(Node Type)
每个查询操作(例如扫描、连接、排序等)被称为一个 “节点”(Node)。常见的节点类型包括:
-
Seq Scan:顺序扫描,全表扫描。
-
Index Scan:索引扫描,数据库通过索引访问表中的数据。
-
Bitmap Index Scan:位图索引扫描,一种高效的索引扫描方法。
-
Hash Join:哈希连接,适用于大表连接。
-
Nested Loop Join:嵌套循环连接,较为低效,适用于较小的数据集。
-
Sort:排序操作,按照指定的字段对数据进行排序。
-
-
启动成本(Startup Cost)
每个节点的启动成本表示执行该节点操作前需要消耗的资源。通常,启动成本较低的节点意味着操作需要的资源较少。启动成本反映了这个节点在查询执行开始时的准备工作。
-
总成本(Total Cost)
总成本是指从当前节点开始执行到查询完成的所有成本的累计。它包括了当前节点的启动成本和所有子节点(如扫描、连接等)的成本。
-
行数(Rows)
每个节点预计会处理的行数。这个数字由优化器根据统计信息估算得到,帮助你了解操作的规模。如果这个数字偏高,说明查询可能会处理大量数据。
-
宽度(Width)
指的是每一行数据的大小,单位是字节。它告诉我们每个操作涉及的每行数据的大小。
-
子节点(Subplans)
如果某个节点需要执行子查询或嵌套的操作,它将会有子节点,这些子节点表示它执行的具体步骤。例如,子查询或者联接条件的额外计算。
EXPLAIN ANALYZE 命令解析:
1)EXPLAIN ANALYZE 的功能概述
EXPLAIN ANALYZE 是**梧桐数据库(WuTong)**中的一个强大命令、及一个 分析性工具,用于评估查询的实际性能,而不仅仅是优化器的估算。它结合了查询计划的估算和实际执行数据,用来深入了解 SQL 查询的执行细节。这是诊断和优化查询性能的核心工具。
EXPLAIN仅展示查询计划,描述数据库如何执行查询。EXPLAIN ANALYZE在此基础上,不仅展示查询计划,还执行查询并记录 实际的执行时间、返回的行数、扫描的行数、每个操作的耗时 等详细信息。
执行时,返回的结果包含以下内容:
- 执行时间(Actual Time):显示查询的实际执行时间。
- 行数(Rows):实际扫描和处理的行数。
- 计划成本(Cost):优化器估算的操作成本。
- 节点类型(Node Type):查询执行时的操作类型,如
Seq Scan、Index Scan、Nested Loop等。
2)EXPLAIN ANALYZE 输出解读
假设我们执行以下查询,并得到以下 EXPLAIN ANALYZE 输出:
EXPLAIN ANALYZE SELECT * FROM customers WHERE age > 30;
示例输出
Seq Scan on customers (cost=0.00..35.50 rows=10 width=8) (actual time=0.012..0.020 rows=5 loops=1) Filter: (age > 30) Rows Removed by Filter: 10 Planning Time: 0.066 ms Execution Time: 0.043 ms
各字段解读
Seq Scan on customers:表明查询使用了顺序扫描(Seq Scan),即没有使用索引。查询遍历整个customers表来查找符合条件的行。- 优化建议:如果该字段频繁用于查询,可以考虑在
age字段上创建索引,从而避免全表扫描。
- 优化建议:如果该字段频繁用于查询,可以考虑在
(cost=0.00..35.50 rows=10 width=8):cost=0.00..35.50:优化器估算的成本范围。0.00是操作的启动成本,35.50是执行整个操作的总成本。这个数字不是实际的时间,而是数据库根据表的大小、索引、统计信息等因素估算的。rows=10:优化器估算该查询会返回 10 行数据。width=8:每一行的字节数,表示返回的数据行大小。
(actual time=0.012..0.020 rows=5 loops=1):actual time=0.012..0.020:表示实际执行该操作的时间。0.012是从操作开始到获取第一个结果的时间,0.020是获取所有结果所花费的总时间。rows=5:查询实际返回了 5 行数据(与优化器的估算相比)。loops=1:该操作执行了 1 次。
Filter: (age > 30):表示应用的过滤条件age > 30。Rows Removed by Filter: 10:表示在查询过程中,优化器过滤掉了 10 行数据,这些行不符合age > 30的条件。Planning Time: 0.066 ms:查询计划生成的时间。它指的是优化器用来生成查询计划的时间。较短的计划时间通常表明查询较为简单。Execution Time: 0.043 ms:查询的总执行时间。表示从查询开始到查询完全执行并返回结果的时间。这个时间越短,查询的效率越高。
3)EXPLAIN 和 EXPLAIN ANALYZE 的区别
| 特性 | EXPLAIN |
EXPLAIN ANALYZE |
|---|---|---|
| 执行查询 | 不执行查询,只显示查询计划 | 执行查询并返回实际执行时间、行数等数据 |
| 输出内容 | 查询计划(操作类型、估算成本、预计行数) | 查询计划 + 实际执行时间、扫描的行数等数据 |
| 执行时间 | 非常快速,只有查询计划 | 需要实际执行查询,执行时间较长 |
| 适用场景 | 查看查询计划、了解查询执行步骤 | 详细分析查询性能,查看实际执行的瓶颈 |
| 用例 | 评估查询的执行路径,优化查询逻辑 | 分析查询执行的实际表现,确认优化效果 |
| 结果是否受实际数据影响 | 只受表的估算和统计信息影响 | 受实际数据、表大小、系统负载等因素影响 |
