




作者介绍
黄靖东
YashanDB 资深研发工程师
01
前言
在数据库领域,高效的数据处理能力是开发者的必备技能。Group by分组操作的运用关系到SQL查询性能的优劣。面向不同的业务场景,会有不同的分组优化策略,本文旨在深度剖析各类复杂业务场景下,如何选择高效的Group by分组策略,帮助突破数据处理瓶颈,实现分组效率的快速提升。
02
分组的概念
Group by子句是对一个表达式或者多个表达式进行分组,并对分组数据进行聚集运算。Having子句是对分组之后的结果进行过滤。
常见的分组分类方式有两种,一种是按照功能分类,另一种是按照算法分类。
按照功能分类

1、只有聚集
select sum(a), sum(b) from test_table
执行上述语句时,所有的数据都视作一个整体,形成单一分组,这是分组的一个特例。
2、只有分组
select a, b from test_table group by a, b
依据指定的a,b字段,拆分后的每个小组内的数据在这两个字段上具有相同的值。
3、分组和聚集
select a, sum(b) from test_table group by a
先按照 a 字段对数据分组,然后针对每组内的 b 值进行求和聚合。
4、多分组聚集
1) Groupin Set
select a, b, sum(c) from test_table group by GROUPING SETS((a), (a, b), ())
执行上述语句,可以将多个Group by结果汇总到一起,相当于执行:
group by a, group by a, b , group by ()
2)Rollup
select a, b, sum(c) from test_table group by rollup(a, b)
执行上述语句,将按照特定的层级顺序对数据进行聚合,相当于依次执行:
group by (), group by a, group by a, b
3)Cube
select a, b, sum(c) from test_table group by cube(a, b)
执行上述语句,将会全面展开数据分组聚合可能性,相当于执行:
group by a, b, group by a, group by b, group by ()
按照算法分类
1、Hash分组
是指利用哈希函数为数据生成对应的哈希值,根据哈希值先找到Hash桶,然后遍历哈希桶的分组找到匹配的分组。在执行过程中,通过构建Hash Set结构来管理分组信息。
2、排序分组
本文仅指根据数据的有序性进行分组。
03
分组优化方式和适用场景
Hash分组
Hash分组执行时依赖Hash Set结构,分组的过程就是在Hash Set中查找分组上下文,当找不到分组上下文时,就可以插入新的分组上下文。分组上下文中存放着分组的所有聚集运算。Hash Set会根据分组key的hash值,分为多个桶,Hash冲突会增加桶内元素数量,因此Hash分组算法需要考虑hash冲突尽可能小。解决冲突对于分组的性能有很大的好处。
影响Hash冲突的主要因素有:
•Hash算法:选择Fnv,Crc等低冲突的算法可以保证冲突不会很大。
•Hash桶大小:桶大小也跟冲突有关,当桶越大,冲突的概率就越低。
适用场景:当分组数量比较小时,Hash分组性能会比较好。
排序分组
排序分组是利用数据的有序性来进行分组。按照场景有下面几种算法:
1、基于排序的分组
先进行数据排序,扫描有序数据进行分组。排序分组不需要所有的分组结束才有输出结果;且对比Hash分组,其所需要的内存资源要少些。
比如数据:1,3,2,3,1 经过排序后得到1,1,2,3,3
对这些有序数据,扫描到1后作为第一个分组,到第二个1,其已经存在对应的分组;扫描到2时,此时和1不是同一分组,此时可以结束分组1的计算,2作为一个新的分组;扫描到3时,此时3和2不是同一分组,结束分组2的计算,3作为新的分组;扫描到下面的3时,此时所有数据都结束,3分组也可以结束分组计算了。
适用场景:常用在数据的分组数比较多且内存资源非常紧张的场景。
2、基于索引的分组
借助已有的索引结构,直接按照索引顺序读取数据进行分组。这种分组跟基于排序分组的区别在于不需要增加额外的排序算子对数据进行排序。但是要求分组key是排序key的前缀子集。
适用场景:当分组key上已经建立了索引。
3、排序分组
是指在排序过程中,当分组的基数非常少时(通常为个位数),可以在排序过程中采用插入排序来进行分组。相比hash分组,其少了hash计算的开销,并且有效利用了数据的有序性,可以快速找到对应的分组。
适用场景:分组数只有个位数的场景,以最小的计算成本实现准确分组。
4、TopN分组
在对数据排序的过同时,仅保留N个需要的分组。
比如对数据(1,3,2,3)做Top2分组,数据按照升序排序,Top2就是取最小的2个分组。
扫描到1时,其成为一个分组;3进来后,也作为一个新的分组3,插入到1之后;2进入后,其比3小,得到新分组2;此时有三个分组了,只需要保留前两个分组1,2;再进来3之后,比2大,不需要建立新的组。最后得到1,2两个分组。
适用场景:分组之后需要对分组Key进行排序,且存在limit子句限制输出数量时,TopN分组能够精准满足需求,快速得到分组数据。例如:
select a, sum(b) from test_table group by a order by a limit 2;
分组列的优化
前面看到分组过程中,对于Hash分组会对分组Key进行算Hash,比较等操作,排序分组会根据分组key进行排序,会有比较多的比较运算。可以通过算法减少这些分组key的计算,达到优化分组的目的。
1、常量优化
例1:
select a from test_table group by a, 1;
如上述语句,当分组key中有常量1,1对分组结果没有影响,所以计划改写会把常量1去掉,等价于:
select a from test_table group by a
例2:
select a from test_table where b = 1 group by a, b;
由于有条件b=1,分组key中包含了b,相当于b是常量,不影响分组结果,可以从分组key中去掉,等价于:
select a from test_table where b = 1 group by a;
适用场景:分组key中含有常量或者推导出来有常量的情况。
2、等价关系优化
select b1 from t1, t2 where t1.b1 = t2.b2 group by b1, b2
由于t1.b1 = t2.b2,对b1分组和b2分组都是一样的结果,因此可以去掉b2
select b1 from t1, t2 where t1.b1 = t2.b2 group by b1
适用场景:当分组key中包含等价类关系时,只保留一个关键元素即可,避免重复计算。
3、主键优化
例1:如果a1,b1是t1的主key
select a1, c1 from t1 group by a1, b1, c1
由于a1, b1是主key,其已经决定了t1表的分组,因此c1可以去掉。
select a1, c1 from t1 group by a1, b1
例2:如果存在关联关系使得分组key包含等价关系
select a1, b2 from t1, t2 where t1.b1 = t2.b2 group by a1, b2, c1
由于t1.b1 = t2.b2,因此group by等价保护t1表的唯一key,因此c1也可以去掉。
select a1, b2 from t1, t2 where t1.b1 = t2.b2 group by a1, b1
适用场景:分组key中包含表的主key的场景。建议合理建立主key,去除冗余字段,优化分组过程。
4、分组顺序变化
例如group a, b 和group by b, a是一样的结果。当分组和其他的算子组合时,交换分组key的顺序可以带来优化。
Select a1, b1 from t1 group by a1, b1 order by b1
先对a1,b1进行分组,然后对b1进行分组,对于排序分组a1, b1,其出来的结果是按照a1, b1有序的。如果我们交换b1, a1的顺序,那么出来的结果就是按照b1有序的,那么后面的排序 order by b1 就可以去掉了,省掉了后面的排序操作。
select a1, b1 from t1 group by b1, a1 order by b1
适用场景:分组之后需要对分组key进行排序的场景。
聚集带Distinct的算法
select count(distinct c2) from t1 group by c1
聚集上带distinct时,有两种算法:
方式一:先按照C1分组,在每个组内按照C2除重。
方式二:先按照C1,C2分组(去重),再执行一遍不带distinct的分组汇聚,等价如下:
Select count(c2) from (select c1, c2 from t1 group by c1, c2) group by c1;
适用场景:Hash分组和排序分组都支持上面两种算法,但是当分组数比较多,资源紧张时,使用排序分组会更加合适。
分组并行
分组并行是利用多Cpu core同时进行分组,其可以大幅降低分组查询的时延。在追求低时延且CPU充足的情况下,需要开启并行;而在业务并发比较多且CPU或者内存资源紧张时,不建议开启并行。
分组并行的策略有两种:两阶段并行和一阶段并行。
1、两阶段并行
各线程内先做一次分组,后由一个线程基于一阶段的结果再做一次分组汇总结果。
适用场景:
1)聚集函数支持两阶段,例如Count,Sum,Max/Min。对于Count聚集,第二阶段的聚集需要变成Sum聚集;
2)分组数比记录数少。两阶段分组的主要目的是通过一阶段就可以把总数据量压低,让第二阶段的计算量足够小。如果分组后记录数还是比较大,用两阶段的效果就会比较差。
2、一阶段并行
数据经过分发(按照Group key或者其子集)之后,再做分组。
当分区key是分组key的子集时,就可以不需要做数据分发了。
适用场景:一阶段并行是比较通用的并行策略,两阶段不适合的场景,其都可以适用。当分组数量和输入差不多的情况下,必须选择一阶段并行,才能达到性能最优。当分区key是分组key的子集,没有数据分发,性能更加优,建议合理规划表的分区key。
聚集函数的优化
聚集运算在分组聚集中,开销占比是比较大的。聚集运算的数据类型对性能的影响比较大的,特别是SUM运算,int类型和float类型都比较快。使用Number类型时有下面的建议:
•指定p(precision)和s(scale),避免精度过大和scale不对齐需要额外的计算开销。
•p值定义在满足业务要求的情况下尽量小,减少不必要的存储开销和计算成本。
•避免用字符串类型代替number类型。字符串转成number类型时,其P是最大精度38,而Scale是浮动值,插入数据时没有做归一化,应避免数据类型混用情况。
例如
create table test(a number(6, 2))
插入值:2.34,3.4,4.78
由于number类型指定了p和s,插入存储后会规整成scale都为2的number值: 2.34,3.40,4.78
select sum(a) from test;
进行sum计算时:由于scale都是相同的,进行sum运算之后,其scale还是2,可以把number当成整数234,340,478进行运算,其结果是scale为2的number值。
这种scale为固定值的number类型,在计算引擎内存会变成内部的数据类型进行计算。数据库用户感知不到内部类型的存在。
适用场景:当number的p值和s值可以指定的情况下,最好执行p和s,并且p值在满足业务精度要求的情况下,尽可能小。
向量化提升分组性能
在YashanDB的向量化执行引擎中,向量化会对分组做下面的优化。
1、减少函数调用
所有的计算都按照批量数据的方式计算,会明显减少函数的调用,例如在Hash Group中计算Hash值时,一次性处理多个数据,极大提升计算效率。
2、按照列计算表达式,减少cache miss
访问数据都是采用按列读取的方式,会明显减少cache miss。
3、利用批量数据的信息加速计算
以计算Count值为例:
select count(col1) from test_table;
count(col1)是要取列col1值不为NULL的总记录行数,由于向量化执行器引擎里面,每列数据有专门的Bitmap表示数据是否为NULL,因此只需要取这个列的Not Null Bitmap就可以快速计算其非NULL的count值。
适用场景:在分组数据比较多的场景,用向量化执行引擎可以通过高效批量处理,显著提升分组效率,加速数据处理进程。
分组下推
在分组操作和join操作同时出现的场景下,将分组下推到join之下,可以利用分组减少join操作的数据记录数(当分组数和记录数几乎一样时,根据Cost 会选择不出来分组下推的计划),可以减少Hash join的开销。
select t1.a1, sum(t1.b1) from t1 join t2 on t1.a1 = t2.a2 group by t1.a1;
等价
select t1.aa1, sum(t1.sumb1) from (select a1 aa1, sum(b1) sumb1 from t1 group by a1) t1 join t2 on t1.aa1 = t2.a2 group by t1.aa1;
上面语句的执行计划如下:
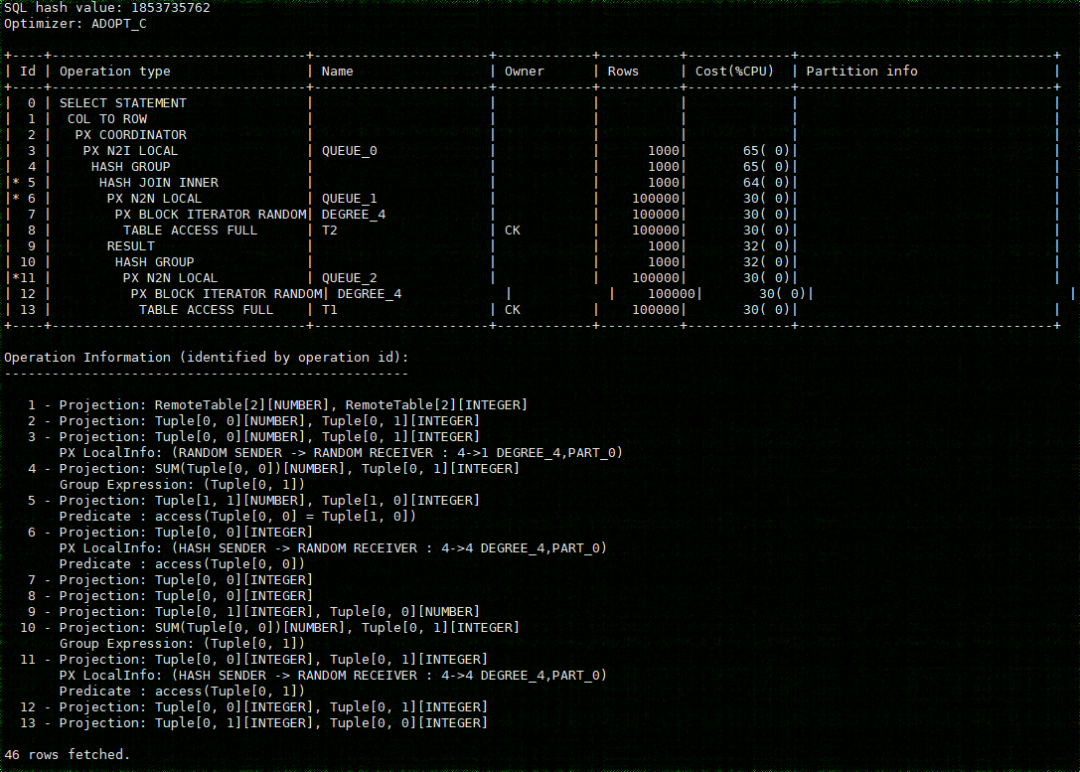
从计划中可以看到分组下推到了Hash join之下。
适用场景:一是适用于分组之后结果比原始表记录数大幅减少的场景;二是常用于分组或者聚集函数不能含有NULL值敏感的函数(例如NVL)时。
05
结语
总之,不同的分组策略各自有着独特的适用场景,在实际的数据库操作中,我们需要依据数据规模、业务需求、系统资源等多方面因素综合考量。精准选择并灵活运用这些分组策略,才能让我们在面对海量数据处理时游刃有余。本次只是介绍了一些常用的优化算法,后面我们还会分享更多的优化算法,并且针对一些优化算法再深入呈现,敬请关注。
>>相关阅读<<

