




导读:
作为 NAVER 的数据平台团队,我们为韩国领先的门户网站提供分析支持。NAVER 支持着超过 200 个互联服务的生态系统,包括搜索、电商、媒体以及人工智能驱动的应用。随着平台在韩国的普及,几乎所有韩国人都在使用我们的服务。与此同时,我们在 Iceberg Lakehouse 中积累了超过 20PB 的数据,并处理着韩国最高的数据流量之一。
为了提供流畅的用户体验和及时的决策支持,我们的分析系统必须提供实时洞察,处理复杂的指标,并能够灵活扩展以应对不断增长的流量。
服务性能监控:确保服务高效运行,始终满足用户期望。 用户行为分析:洞察用户与服务的互动方式,推动数据驱动的决策。
在构建第一个版本的分析平台时,我们希望能够快速搭建,因此选择了 ClickHouse 作为最初的解决方案。其快速的聚合查询性能让我们在初期能够迅速交付结果。然而,随着平台的发展,我们遇到了不少显著的限制。
固定维度
可扩展性问题
有限的数据更新/删除
ClickHouse 通过“merge on read”来处理实时可变数据(mutable data)。尽管这种方式能保持数据的新鲜度,但它严重影响了性能,这是我们无法接受的。这一限制使得许多场景难以支持,甚至完全无法实现,特别是在需要可变数据和复杂架构的分析工作流中。
技术选型-Trino、Pinot、Druid、StarRocks
我们对 Trino、Pinot、Druid 和 StarRocks 等几种解决方案进行了评估与基准测试,并根据以下标准进行了对比:
多表 JOIN:能够处理跨多个表的复杂查询,而无需依赖反范式化。 实时聚合查询性能:确保动态实时分析的查询执行快速高效。 扩展能力:支持无缝地横向扩展,处理不断增长的数据量,同时保持最低的运维开销。 数据更新:支持实时数据更新而不影响查询性能。

开箱即用的多表查询:StarRocks 原生支持复杂的多表 JOIN,消除了对反范式化表格的需求。 联邦分析:通过与 Apache Iceberg 及其他开放格式的集成,我们能够无缝分析内部和外部数据集,提供统一且灵活的查询接口。 卓越的聚合查询性能:即使在动态工作负载下,StarRocks 的聚合查询性能也能与 ClickHouse 媲美,甚至表现更优。 云原生扩展性:其解耦的存储计算架构简化了扩展过程,支持跨节点共享数据,并实现高效的资源管理。
测试性能与资源配置
为了确定最佳资源配置,我们使用真实查询和数据测试了 StarRocks 的性能,并将其与 ClickHouse 在1小时、6小时、12小时、18小时和24小时的数据表现进行了对比。
多列聚合查询
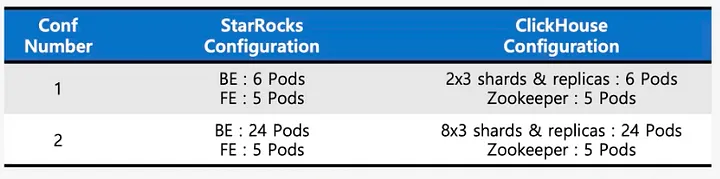
第一个基准测试聚焦于多列 GROUP BY 查询。我们在两种配置下对 StarRocks 和 ClickHouse 进行了评估:Kubernetes 上的小型集群和大型集群。结果显示,StarRocks 在这两种配置下的表现始终优于 ClickHouse。

JOIN 查询
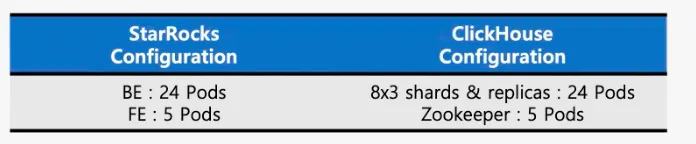
接下来,我们测试了 StarRocks 和 ClickHouse 在上述集群配置下处理多表 JOIN 操作的能力。
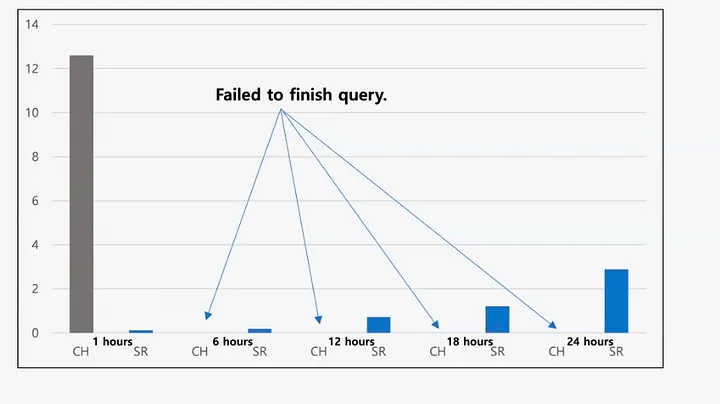
StarRocks 顺利完成了所有 JOIN 查询,且延迟表现优异。相比之下,ClickHouse 在五个查询中有四个未能完成。
横向扩展性
下图对比了 StarRocks 和 ClickHouse 在横向扩展时的表现:
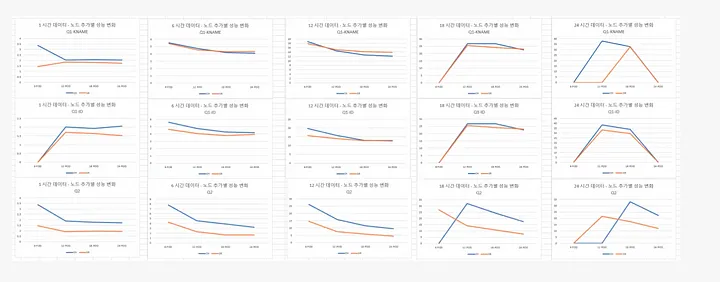
如上图所示,随着资源的增加,StarRocks 表现出线性增长。这种扩展性使我们能够高效地处理不断增长的工作负载,同时保持可预测的性能。
资源配置
根据测试结果,我们对 StarRocks 基础设施进行了优化,配置如下:
5个前端(FE)Pod:负责查询解析、计划和协调,确保高效执行。 80个后端(BE)Pod:专门用于数据存储,每个 Pod 配备48个 CPU、50Gi 内存和 10TB 的 SSD 存储,确保快速可靠的数据访问。 70个无状态计算节点(CN)Pod:根据需要动态分配计算资源,每个 Pod 配备48个 CPU 和 50Gi 内存,用于处理高查询量和复杂分析工作负载。
监控设置
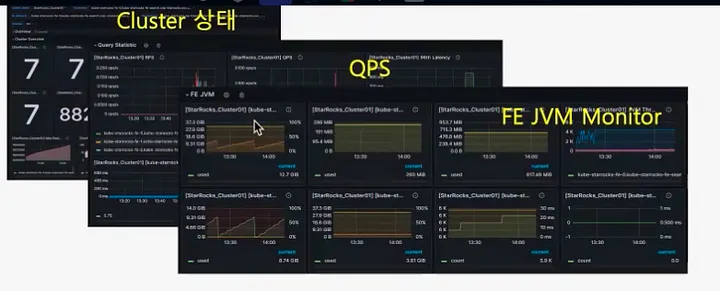
该模板包含安装指南和预定义的仪表板,用于监控集群状态、合并状态以及 BE 和 FE 的各项指标。这些指标使我们能够实时监控系统的健康状况和性能,从而实现主动维护和快速解决问题。
通过物化视图进一步加速查询
查询重写:自动优化查询,在适用时使用物化视图,从而减少手动重写 SQL 的需求。 自动/定时刷新:通过最小的人工干预保持视图的最新状态,确保数据的一致性。
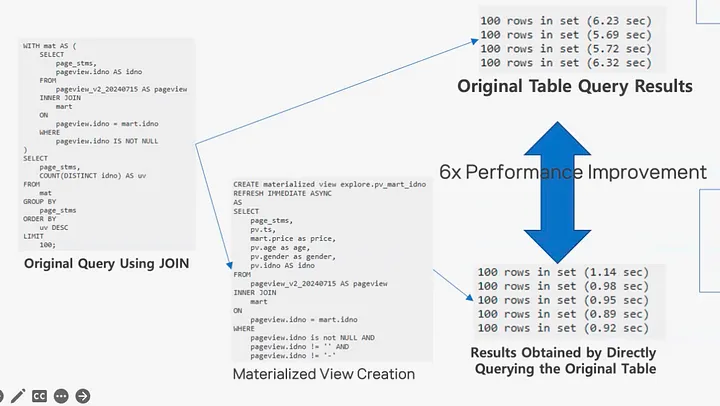
迁移至 StarRocks 后,我们的分析平台在以下方面实现了显著提升:
灵活的交互式查询
工程师现在可以直接使用 SQL 查询原始数据,与 ClickHouse 的固定预定义指标相比,提供了无与伦比的灵活性。
全面提升的性能
多表 JOIN 和多列 GROUP BY 查询的执行速度大幅提升,即使在包含实时数据更新和删除的数据集上也是如此。
统一查询平台
StarRocks 通过内部 catalog 提供高性能查询,利用 Apache Iceberg 的外部 catalog 管理外部数据,并通过 Apache Hive 外部 catalog 支持遗留的(legacy)孤立数据集,从而实现了所有数据源之间的无缝、高效整合。
可扩展性
StarRocks 的横向扩展能力与 Kubernetes 结合,确保了处理能力的线性增长,使平台能够以具有成本效益的方式处理动态和异构的工作负载。
这些优势简化了我们的工作流程,使平台能够更高效、更灵活地支持 NAVER 不断发展的分析需求。
在 NAVER,高效处理多表 JOIN 的能力彻底改变了我们的分析平台。StarRocks 帮助我们突破了以往的限制,实现了更快的查询性能、无缝扩展性,以及与多元数据源集成的统一查询平台。这些改进使我们能够提供实时洞察,支持整个生态系统中的数据驱动决策。
性能优化:优化分区策略,提升查询效率,尤其是针对基于时间戳的查询,实现更快的分析处理。 社区贡献:将我们的内部进展贡献给开源社区,帮助增强 StarRocks 的功能,为更广泛的用户群体提供支持。 更广泛的集成:扩大 StarRocks 的应用范围,处理更多外部数据集,利用 Apache Iceberg 进行动态和管控数据查询。
推荐阅读:StarRocks 全球用户精选案例
关于 StarRocks
StarRocks 是隶属于 Linux Foundation 的开源 Lakehouse 引擎 ,采用 Apache License v2.0 许可证。StarRocks 全球社区蓬勃发展,聚集数万活跃用户,GitHub 星标数已突破 9600,贡献者超过 450 人,并吸引数十家行业领先企业共建开源生态。
StarRocks Lakehouse 架构让企业能基于一份数据,满足 BI 报表、Ad-hoc 查询、Customer-facing 分析等不同场景的数据分析需求,实现 "One Data,All Analytics" 的业务价值。StarRocks 已被全球超过 500 家市值 70 亿元人民币以上的顶尖企业选择,包括中国民生银行、沃尔玛、携程、腾讯、美的、理想汽车、Pinterest、Shopee 等,覆盖金融、零售、在线旅游、游戏、制造等领域。


行业优秀实践案例
泛金融:中国民生银行|平安银行|中信银行|四川银行|南京银行|宁波银行|中原银行|中信建投|苏商银行|微众银行|杭银消费金融|马上消费金融|中信建投|申万宏源|西南证券|中泰证券|国泰君安证券|广发证券|国投证券|中欧财富|创金合信基金|泰康资产|人保财险
互联网:微信|小红书|滴滴|B站|携程|同程旅行|芒果TV|得物|贝壳|汽车之家|腾讯大数据|腾讯音乐|饿了么|七猫|金山办公|Pinterest|欢聚集团|美团餐饮|58同城|网易邮箱|360|腾讯游戏|波克城市|37手游|游族网络|喜马拉雅|Shopee|Demandbase|爱奇艺
新经济:蔚来汽车|理想汽车|吉利汽车|顺丰|京东物流|跨越速运|沃尔玛|屈臣氏|麦当劳|大润发|华润集团|TCL |万物新生|百草味|多点 DMALL|酷开科技|vivo|聚水潭|泸州老窖|中免集团|蓝月亮|立白|美的|伊利|公牛



