





点击蓝字关注我们
分词机制概述
分词(Tokenization)是将文本拆分为一个个独立的词项(Token)的过程。Elasticsearch 通过分词器(Analyzer)来实现这一过程。分词器通常由以下三个组件构成:
字符过滤器(Character Filters):
对原始文本进行预处理,例如去除 HTML 标签、转换字符等。
常见用途:
HTML标签剥离:去除 HTML 标签,留下纯文本。
特殊符号替换:将 HTML 实体或其他特殊编码替换成标准字符。
正则表达式处理:根据需求批量替换或删除特定字符。
分词器(Tokenizer):
将文本按照特定规则拆分为词项,例如按照空格、标点符号等进行拆分。
常见分词器:
standard:默认分词器,适用于多种语言,能处理标点符号和常见分隔符。
whitespace:仅根据空白字符进行拆分,不考虑其他符号。
keyword:将整个文本作为一个整体,不做拆分,适合需要保持原文完整的字段。
pattern:使用正则表达式进行拆分,灵活性较高。
ngram:生成连续字符子串,常用于实现前缀查询和模糊搜索。等等
分词器内部机制:
在标准分词器中,文本会按照 Unicode 字符属性划分词边界,例如遇到标点、空格或其他分隔符时拆分成独立的 token。此外,每个 token 除了文本内容,还包含位置信息(offsets)、位置增量(position increment)等,供后续查询和高亮显示使用。
词项过滤器(Token Filters):
对分词后的结果进行进一步处理,例如将词项转换为小写、去除停用词、添加同义词等。
常见过滤器:
lowercase:将所有字符转换为小写,消除大小写差异。
stop:去除停用词,如“的”、“了”、“and”等,减少无意义词项对搜索结果的干扰。
synonym:进行同义词扩展,让搜索更智能。
stemmer:提取词干,减少单词的各种变形(如英语中的 running → run)。
edge_ngram:生成前缀 token,有助于实现前缀匹配。
过滤器可以链式组合,每个过滤器的执行顺序会影响最终 token 列表。例如,先做 lowercase,再做停用词过滤,可以保证停用词匹配时不受大小写影响。
分词动作一般工作在两个场景中:
在 indexing 的时候,也即在建立索引的时候
在 searching 的时候,也即在搜索时,分析需要搜索的词语
内置分词器
Elasticsearch 提供了多种内置分词器,以满足不同的文本分析需求,以下是一些常用的内置分词器:
Standard Analyzer: 默认分词器,按词切分,支持多语言,小写处理。
Simple Analyzer: 按照非字母字符切分文本,并将词项转换为小写。
Whitespace Analyzer: 按照空格切分文本。
Stop Analyzer: 在 Simple Analyzer 的基础上,增加了去除停用词的功能。
Keyword Analyzer: 将整个文本作为一个词项。
Pattern Analyzer: 使用正则表达式进行分词。
Language Analyzers: 针对特定语言的分词器,例如 english、chinese 等。
更多分词器的使用可以参考官方文档。
自定义分词器
除了使用内置分词器,Elasticsearch 还允许用户根据特定需求自定义分词器。自定义分词器需要在索引设置中进行配置,例如:
以上定义了一个名为my_custom_analyzer 的自定义分词器,它使用 standard 分词器进行分词,然后依次应用 lowercase 和 my_custom_filter 过滤器。my_custom_filter 是一个自定义的停用词过滤器,用于去除 "a"、"an" 和 "the" 等停用词。
使用示例如下:
PUT my_index{"settings": {"analysis": {"analyzer": {"my_custom_analyzer": {"type": "custom","tokenizer": "standard","filter": ["lowercase","my_custom_filter"]}},"filter": {"my_custom_filter": {"type": "stop","stopwords": ["a", "an", "the"]}}}}}复制
ES 提供了 _analyze API 用于测试分词器和分析文本,例如:
GET /my_index/_analyze{"analyzer": "my_custom_analyzer","text": "The quick brown fox jumps over the lazy dog"}复制
使用 my_custom_analyzer 分词器对文本 "The quick brown fox jumps over the lazy dog" 进行分析,返回结果如下:
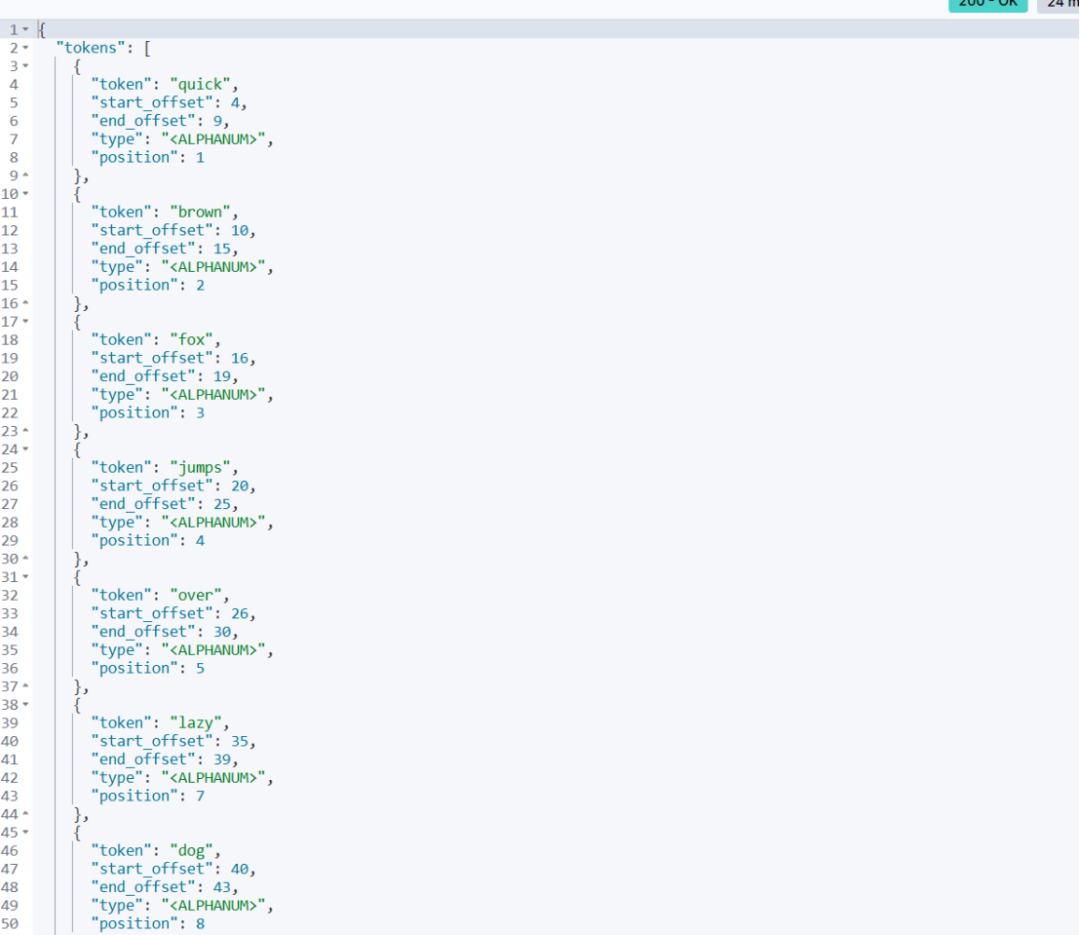
从结果中可以看到,文本被成功分词,并且停用词 "The" 和 "the" 被去除。
中文分词
对于中文文本,Elasticsearch 提供了 ik_smart 和 ik_max_word 等分词器。ik_smart 分词器会将文本按照最粗粒度进行切分,而 ik_max_word 分词器则会尽可能多地切分出词语。
注意:在使用IK分词器前需要先安装相关插件,例如:
简单使用:
GET /_analyze{"analyzer": "ik_max_word","text": "中华人民共和国"}复制
使用 ik_max_word 分词器对文本 "中华人民共和国" 进行分析:
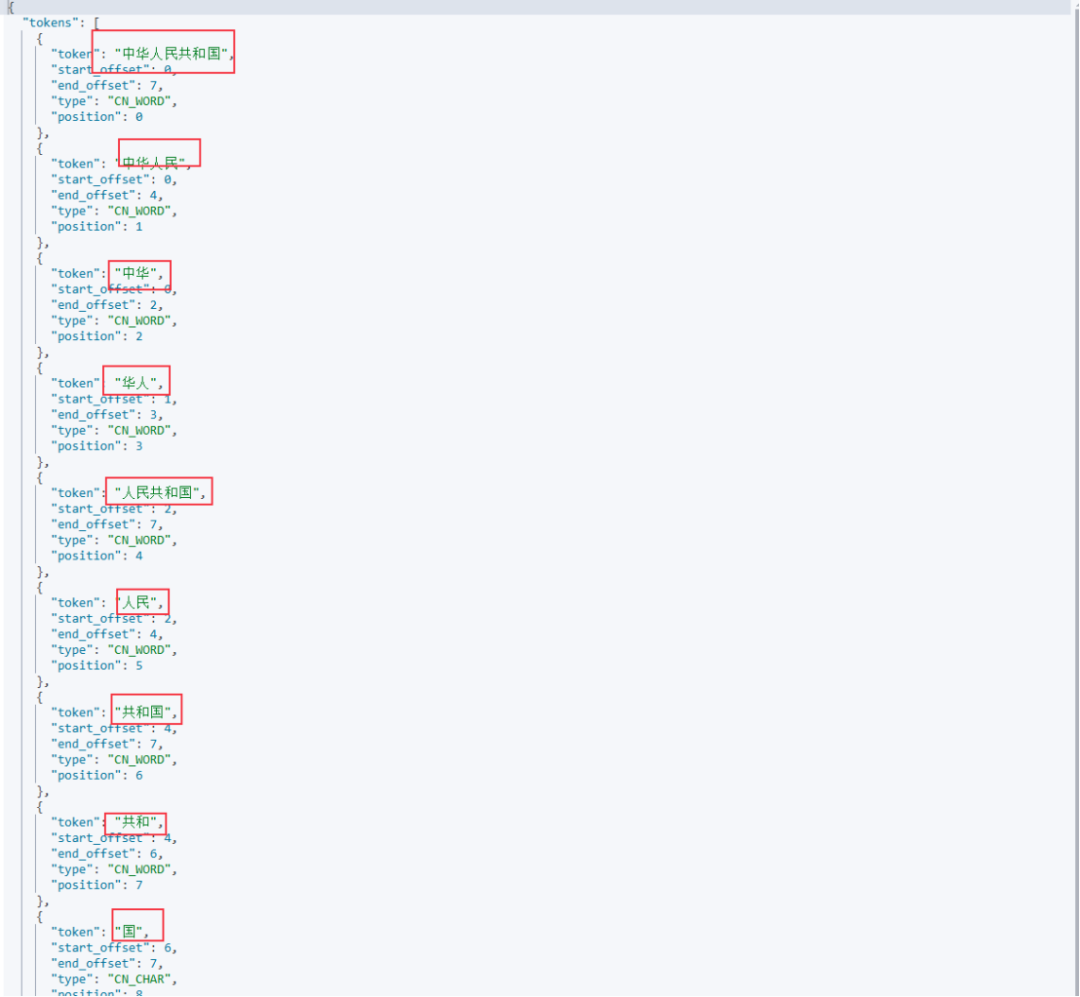
从结果可以看到它将“中华人民共和国”拆解为了许多词项以供查询匹配。
常见问题与调优建议
停用词过滤顺序问题
确保在进行同义词扩展或词干提取之前完成大小写转换和停用词过滤,以避免遗漏或误删有效 token。
中文分词效果不足
若标准分词器对中文处理效果不佳,建议使用 IK 分词器,并通过自定义词库进一步提高分词准确度。
查询时分词器不匹配
为避免索引时和查询时分词不一致的问题,可以分别为索引字段设置 analyzer 和 search_analyzer,保证在检索时对输入查询进行适当处理。
调试建议
使用 _analyze API 是调试和验证分析器配置的重要手段,建议在开发过程中频繁使用,直观了解每一步的处理效果。
总结
分词机制和文本分析是 Elasticsearch 实现高效文本搜索的关键。通过理解分词器的组成和工作原理,并结合实际需求选择合适的分词器,可以有效地提升搜索的准确性和效率。
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
