




deepseek+ragflow离线环境安装部署实战篇
最近大模型很火,由于行业环境的限制,需要在内网搭建自己的知识库,然后想看看结合行业的知识,看看能否查出点火花。
安装包梳理
由于在离线环境安装,因此需要软件需要提前准备,下面软件下载篇幅只是为了文章的完整性而添加的。在这里我们把需要的软件全部梳理一下,仅供大家参考。
--ollama安装包
ollama-linux-amd64.tgz
--模型数据文件
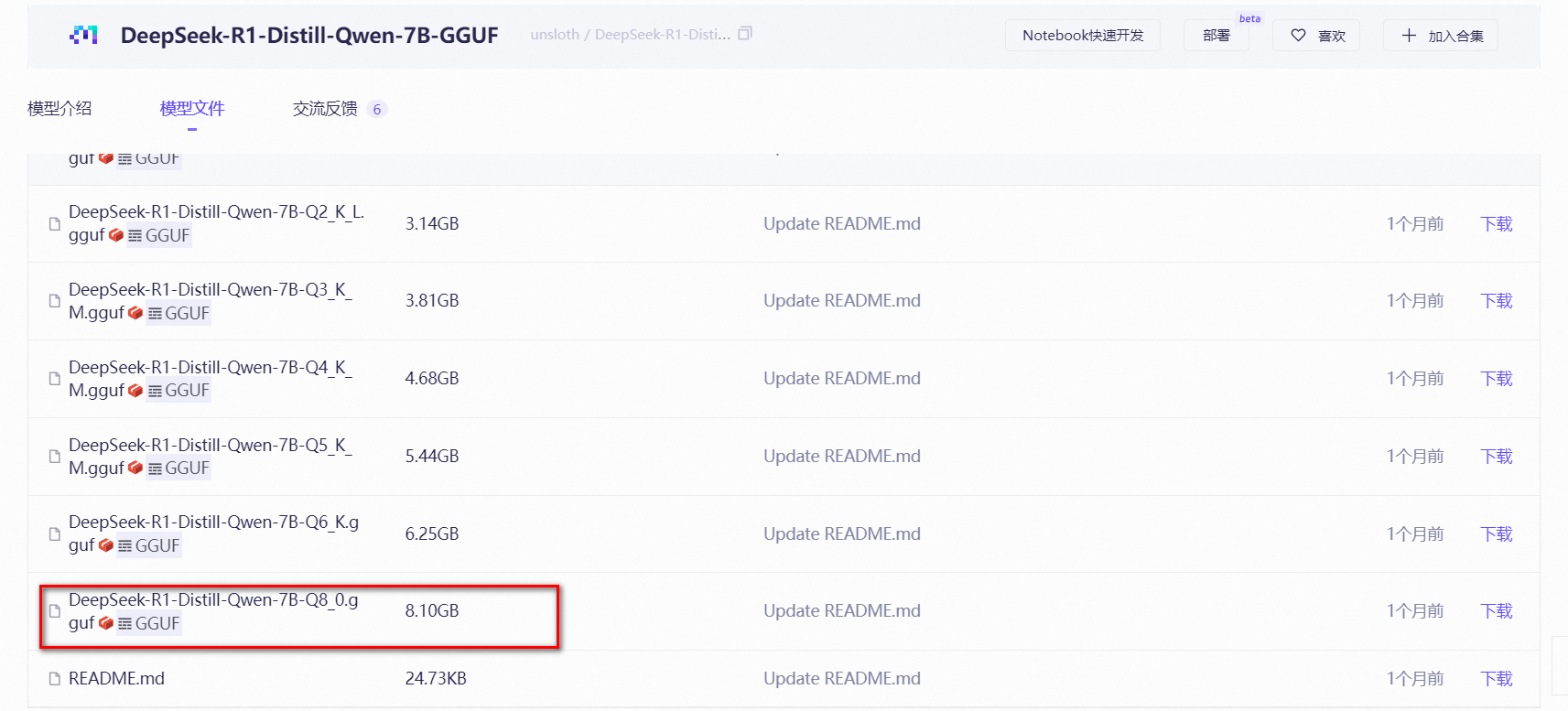
DeepSeek-R1-Distill-Qwen-7B-Q8_0.gguf
--docker安装包
docker-27.5.1.tgz
docker-compose-linux-x86_64
c-0.16.0.tar.gz
ragflow的五个镜像包
如果有需要安装包的,请关注【墨竹札记】,输入“deepseek离线安装包”,获取链接下载。
ollama安装部署
ollama下载
先访问https://github.com/ollama/ollama/releases/tag/v0.5.12链接地址,在当前页面下拉找到最新的linux版本。在这里你可以使用命令下载
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz

也可以通过其他的工具下载,右击上述的文件,复制文件链接,复制到迅雷或者其他工具,都可以下载。
ollama安装
把ollama离线安装包上传到指定的服务器,在这里上传到/data/deepseek目录,自己根据实际情况进行调整
将安装的内容解压到/usr/local
tar -C /usr/local -xzf ollama-linux-amd64.tgz
由于在Linux下,当ollama离线安装时,模型默认存放在/root/.ollama/models路径下。为了管理的需求,在这里更改模型的存放目录,先创建下面的路径
mkdir -p /data/deepseek/models
该路径在下面的ollama.service文件中添加配置。
配置ollama为系统服务
创建一个服务文件
vi /etc/systemd/system/ollama.service
在文件中添加如下的内容
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=root
Group=root
Restart=always
RestartSec=3
Environment="PATH=$PATH"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_MODELS=/data/deepseek/models"
[Install]
WantedBy=default.target
加载配置的服务文件并将ollama配置为系统服务
--加载配置文件
systemctl daemon-reload
--启用ollama服务
systemctl enable ollama
--重启服务
systemctl restart ollama
--查看服务状态
systemctl status ollama
验证安装状态
验证ollama安装是否成功,输入ollama命令
[root@jcyjs4 deepseek]# ollama -v
Warning: could not connect to a running Ollama instance
Warning: client version is 0.5.12
检查端口是否启用
[root@dc system]# netstat -anp | grep 11434
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN 941/ollama
[root@dc system]#
当看到服务启用并且端口也正常启用,则ollama安装完成。
deepseek模型加载
deepseek下载
在魔塔平台中找到GGUF格式的deepseek的模型文件,具体下载那个蒸馏模型,根据自己的服务器配置自行修改,我这边下载的是最新的模型文件7B_Q8。
创建modefile
先将之前下载的deepseek模型文件上传到指定的服务器,在这里上传到/data/deepseek目录。另外,需要先创建一个modefile文件,名称可以自定义,该文件主要为了保存gguf模型文件的路径,路径可以写绝对路径或者相对路径。
vim /data/deepseek/ds7b
然后再modefile中添加如下的内容:
FROM ./DeepSeek-R1-Distill-Qwen-7B-Q8_0.gguf
保存文件并退出。
ollama运行模型
在创建完modefile文件后,就可以在本地创建模型,具体命令也可以查看ollama的help。在这里deepseek7b为模型的名称,-f后指定创建的modefile的存放路径
ollama create deepseek7b -f /data/deepseek/ds7b

创建成功后,可以使用下面的命令来检查ollama中是否有模型存在
ollama list
ollama运行模型
在创建模型后,就可以使用下面的命令把模型给运行起来
ollama run deepseek7b
docker安装
访问https://download.docker.com/linux/static/stable/x86_64/地址,根据自己的情况,下载离线的安装包,在这里我下载的版本为docker-27.5.1.tgz。

访问https://github.com/docker/compose/releases地址,下面页面找到assets目录,然后根据服务器的版本,下载对应的版本
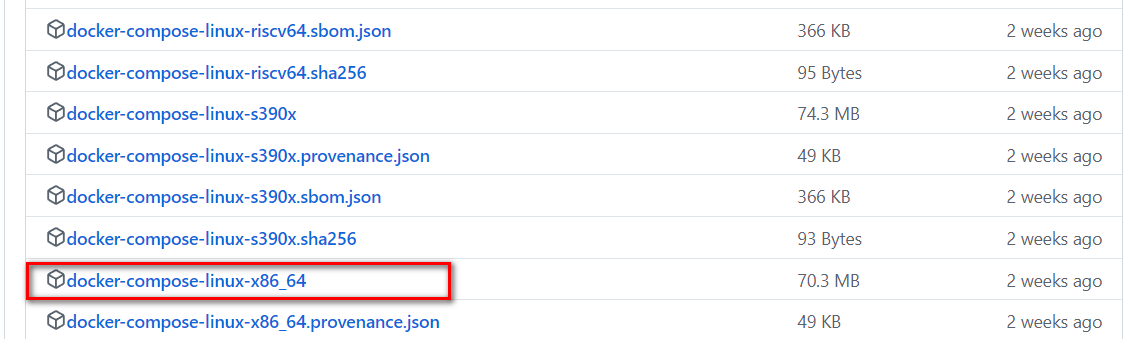
将下载的docker安装包和docker-compose文件上传到服务器中,解决文件
tar -xvf ./docker-27.5.1.tgz
cp docker/* /usr/bin/
创建docker的服务文件
vim /etc/systemd/system/docker.service
在该文件中添加如下的内容
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Uncomment TasksMax if your systemd version supports it.
# Only systemd 226 and above support this version.
#TasksMax=infinity
TimeoutStartSec=0
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
# restart the docker process if it exits prematurely
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
加载配置的服务文件并将docker配置为系统服务
--加载配置文件
systemctl daemon-reload
--启用ollama服务
systemctl enable docker
--重启服务
systemctl restart docker
--查看服务状态
systemctl status docker
docker-compose安装
上传文件至/usr/local/bin下,并授执行权限
mv docker-compose-linux-x86_64 docker-compose
chmod +x /usr/local/bin/docker-compose
docker-compose --version
ragflow安装部署
设置参数
修改vm.max_map_count参数
sysctl -w vm.max_map_count=262144
sysctl vm.max_map_count
如果希望做永久改动,还需要在 /etc/sysctl.conf 文件里把 vm.max_map_count 参数进行添加:
vm.max_map_count=262144
导出镜像文件
离线镜像包时利用本地环境自行打包的。然后导入离线镜像文件
docker load -i mysql.tar
docker load -i elasticsearch.tar
docker load -i ragflow.tar
docker load -i valkey.tar
docker load -i minio.tar
ragflow安装
访问https://github.com/infiniflow/ragflow地址下载ragflow,然后将该文件包上传到服务器的目录中,并对该文件进行解压
tar -xvf ragflow-0.16.0.tar.gz
cd ragflow-0.16.0/docker
由于ragflow默认使用的是RAGFlow slim Docker 镜像,因此需要修改环境变量RAGFLOW_IMAGE,把文件的slim 对应的行注释,然后把ragflow:v0.16.0对应的行取消注释
RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0
如果你没有修改参数,在后续的启动就会报如下的错误
[root@dc docker]# docker-compose -f docker-compose.yml up -d
WARN[0000] The "MACOS" variable is not set. Defaulting to a blank string.
(root) Additional property include is not allowed
另外如果启动的过程报address already in use,如下的错误信息
Error response from daemon: driver failed programming external connectivity on endpoint ragflow-server (8599de1bc86a87c6bc5865bd0e8c92ca05dd9c0ed9de0b3f030c7953b66aa8db): failed to bind port 0.0.0.0:80/tcp: Error starting userland proxy: listen tcp4 0.0.0.0:80: bind: address already in use
该问题是由于端口冲突引起,需要我们修改docker-compose.yml 的端口或者检查服务器中占用端口的服务,停止该服务。在这里,就直接修改下面的文件的80端口为8088。

启动服务
docker-compose -f docker-compose.yml up -d
服务器启动成功后再次确认服务器状态:
docker logs -f ragflow-server
ragflow配置
需要先访问http://ip地址:80 地址,如果端口在上面有,则需要修改对应的端口,然后登录进行账号注册。
注册登录后就到下面的页面
点击右上角的圆形图标,在弹出页面中选中模型供应商,然后ollama进行模型的添加

在弹出的对话框中,选择模型类型为chat,模型的名称需要和加载的模型保持一致,基础url为http://IP:11434,最大的token数,设置10000就可以,也可以设置其他值。
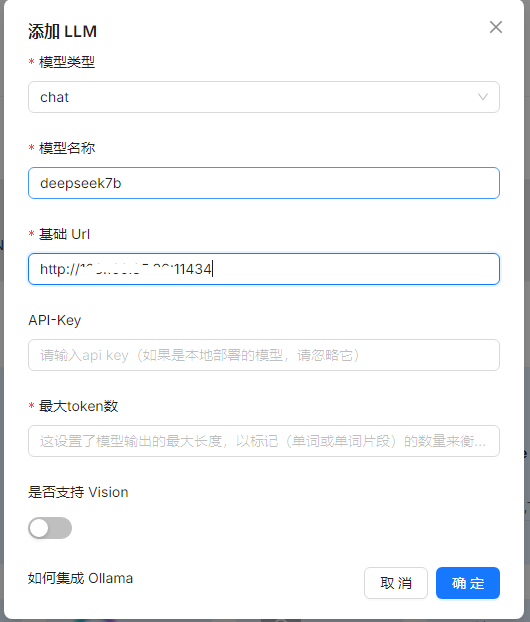
如果在添加模型的时候报如下的错误,就需要检测网络问题、防火墙、还有就是端口是否冲突导致连接不上,我这边遇到的问题就是当前的11434端口与之前的端口冲突导致。
Fail to access model(deepseek7b).**ERROR**: [Errno 111] Connection refused
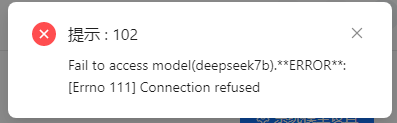
点击当前页面的系统模型设置,在弹出框中的聊天模型,选择刚才添加的模型,然后点击保存按钮。
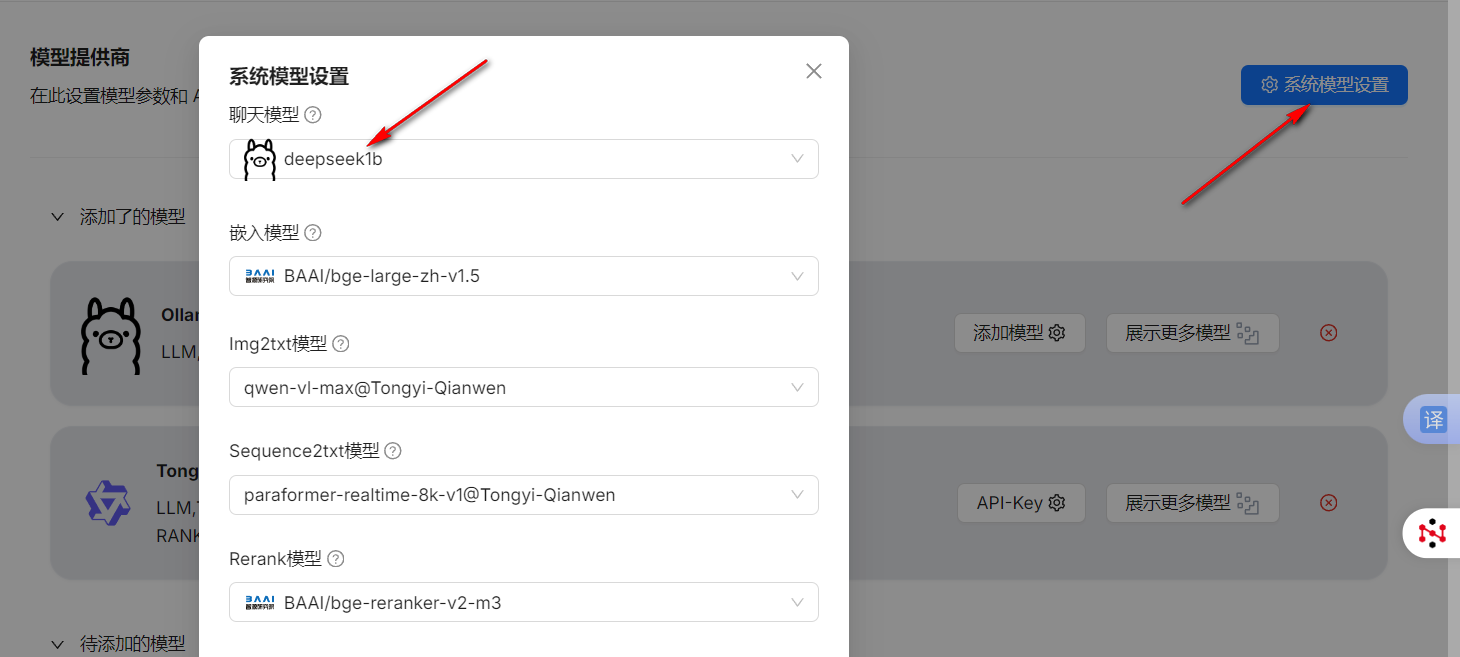
到这一步,我们就可以创建自己的知识库了。点击知识库,然后再次点击创建知识库,在弹出的对话框中添加知识库的名称
在知识库的配置中,文档语言可以选择中文,另外对于嵌入模型为刚才配置的,默认为刚才配置的嵌入式模型。其他的没有特殊要求,则保存该信息。
在数据集中,我们就可以上传自己的文档。

点击新增文件,上传成功后。需要点击下图中的执行按钮,对文件进行解析。
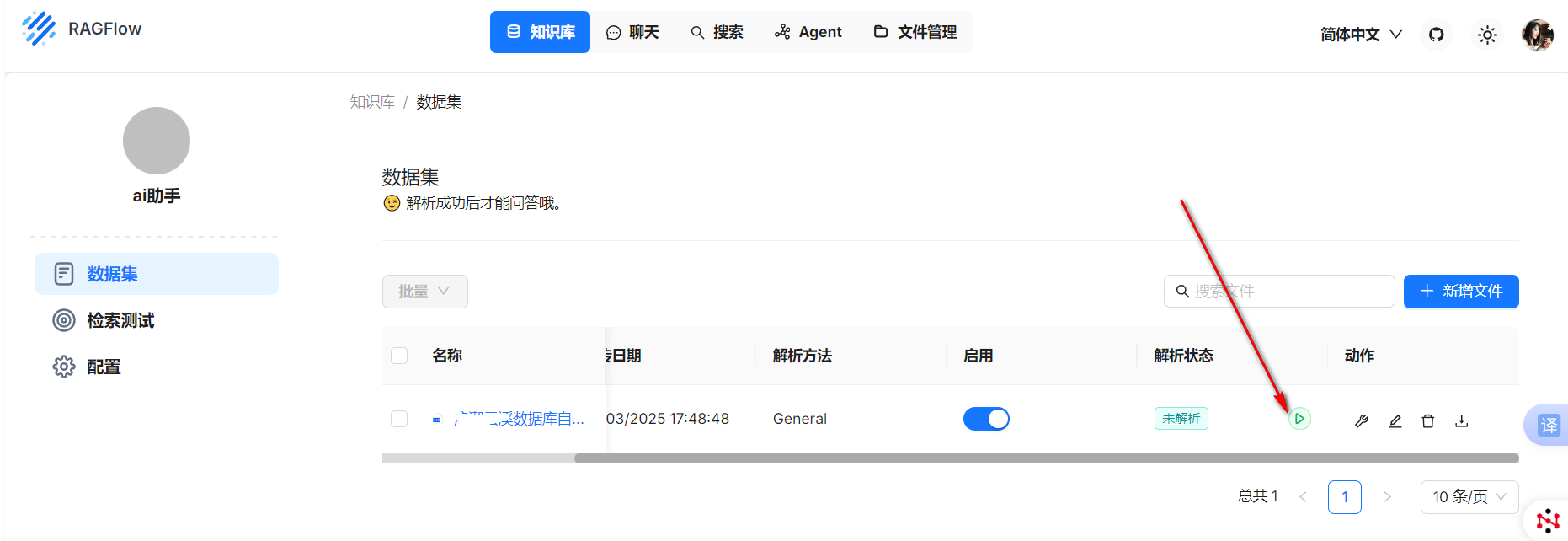
在文件解析完成后,我们就可以在聊天页面,创建助理,知识库选择之前创建的知识库,然后在模型设置中把token数拉大,避免回答问题比较短。

最后在我们创建聊天会话就可以进行对话了。

参考
https://github.com/infiniflow/ragflow/blob/main/README_zh.md
– / END / –
可以通过下面的方式联系我
如果这篇文章为你带来了灵感或启发,就请帮忙点赞、收藏、转发;如果文章中不严谨或者错漏之处,请及时评论指正。非常感谢!
