





本文字数:12795;估计阅读时间:32 分钟


ClickHouse 原生支持 70 多种输入格式,无需第三方工具即可导入数据,特别适用于一次性数据导入。然而,当没有预定义的格式时,众多选择可能会带来困惑。哪种格式速度最快、效率最高?ClickHouse 客户端会自动选择最佳格式吗?又该如何进一步优化?
为了回答这些问题,我们开发了 FastFormats——一个基准测试工具,用于衡量服务器端的数据导入速度和硬件效率,覆盖 ClickHouse 支持的所有格式。
本文将深入解析 ClickHouse 的数据插入流程,探讨可用的输入格式,并分析基准测试结果,以找出最适合高性能数据导入的格式。最后,我们将介绍 ClickHouse 客户端默认的插入优化机制,并探讨如何进一步优化配置。
如果你想快速获取推荐,可以查看相关文档【https://clickhouse.com/docs/interfaces/formats#input-formats】。
完整的测试结果可在 FastFormats 在线分析仪表板中查看【https://fastformats.clickhouse.com/】。
在之前的文章中,我们探讨了一次性数据加载时服务器端的插入扩展能力。在这类场景下,服务器主动获取数据,客户端无需参与,并且数据通常已经具有预定义的格式。
本文关注更常见的场景,即客户端持续或周期性地发送数据,并可以选择最优的数据格式,尤其是在源数据没有固定格式的情况下。我们将重点研究如何通过客户端优化——尤其是输入格式的选择——来提升服务器端的插入性能。
首先,我们简要回顾 ClickHouse 的 MergeTree 插入机制,以及客户端可用的关键优化选项:
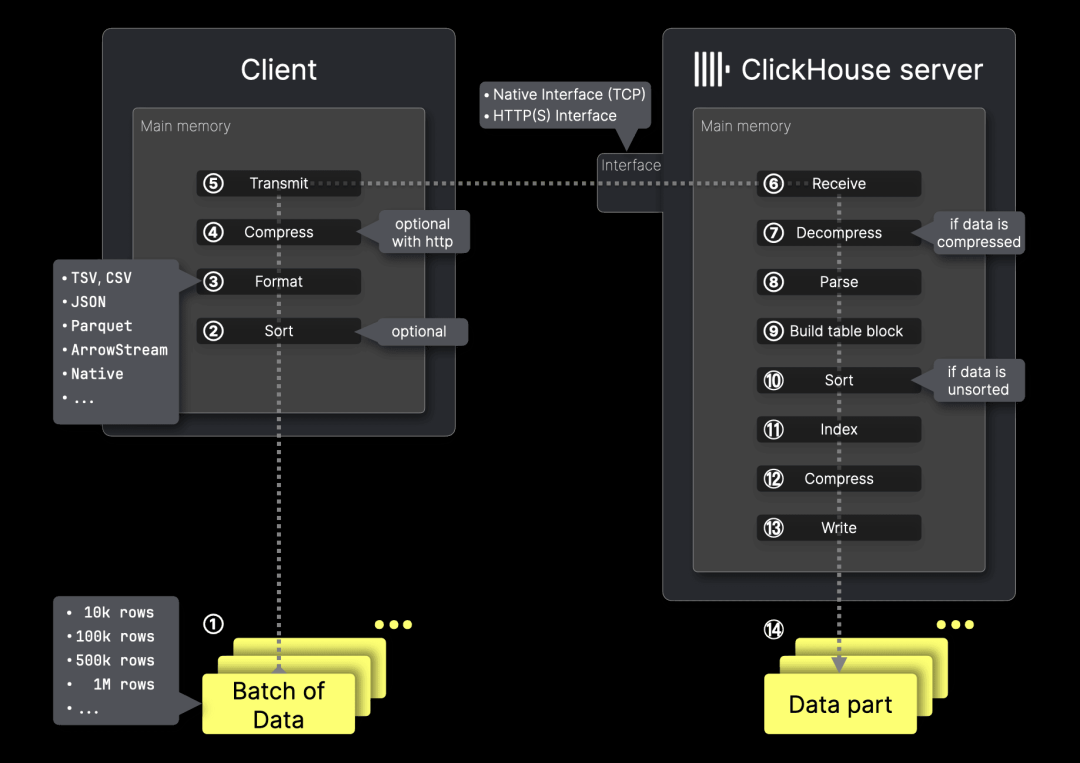
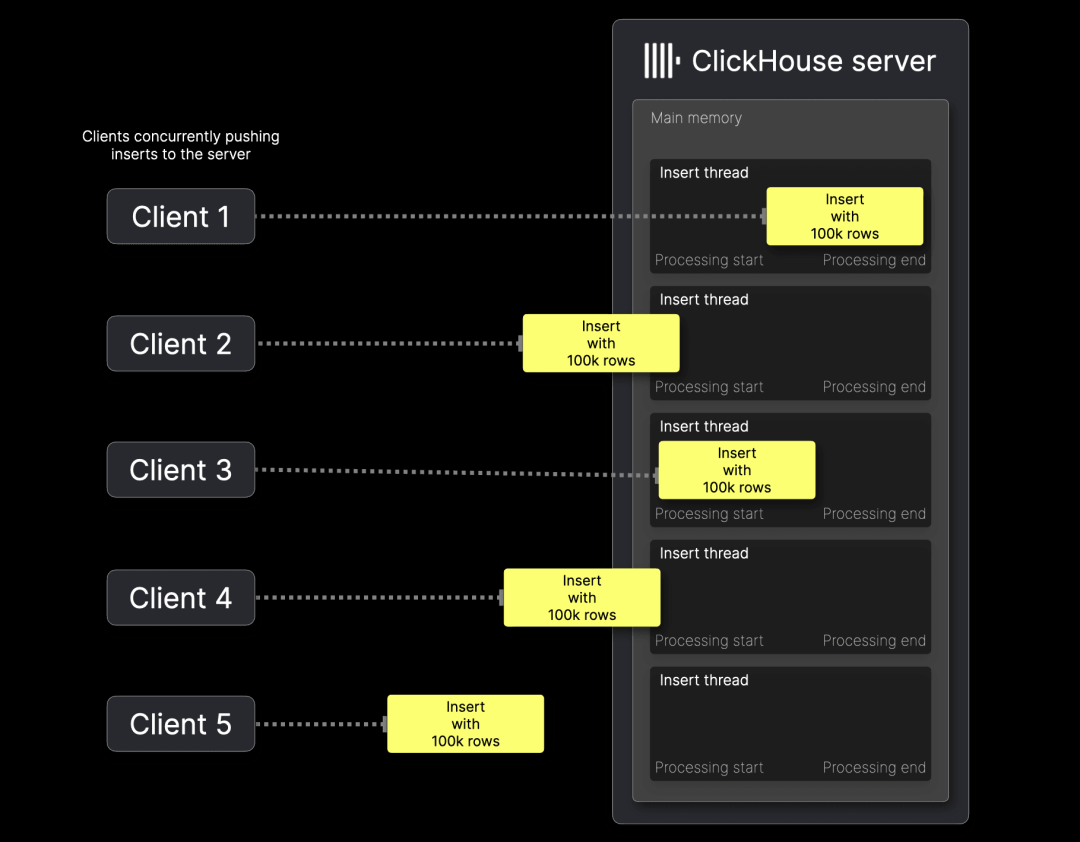
上图展示了客户端如何批量将数据导入远程 ClickHouse 服务器中的表。接下来,我们将详细介绍各个处理步骤。
客户端步骤
为了提升性能,数据应尽量 ① 进行批处理,因此选择合适的批量大小是首要决策。如果无法进行批处理,也可以采用异步插入模式,此时服务器端的插入流程保持不变,唯一的区别是,在步骤 ⑦(数据解压缩)和步骤 ⑧(数据解析)之间增加了一个缓冲区。
ClickHouse 会将插入的数据存储在磁盘上,并按主键列排序。第二个关键决策是是否在数据传输到服务器前 ② 进行预排序。如果批次数据已经按照主键列排序,ClickHouse 可以跳过 ⑨ 排序步骤,从而加快数据导入速度。那么,这种优化能提升多少性能?是否值得客户端投入额外的计算资源?我们将在后文进行演示,敬请关注。
如果数据没有固定的输入格式,选择合适的格式就至关重要。ClickHouse 支持 70 多种数据格式进行插入。但在使用 ClickHouse 命令行客户端或编程语言客户端时,系统通常会自动选择高效的默认格式,我们稍后会深入探讨这一点。如果需要,用户也可以手动指定格式,而不使用默认选择。
接下来的重要决策是 ④ 是否在数据传输到 ClickHouse 服务器前进行压缩。压缩可以减少传输数据量,提高网络效率,从而加快数据传输速度,并降低带宽占用,特别是在处理大规模数据集时尤为重要。
数据随后通过 ⑤ ClickHouse 的网络接口进行传输,用户可以选择原生接口或 HTTP 接口(我们将在后文对比两者的区别)。
服务器端步骤
当 ⑥ 服务器接收到数据后,如果数据经过压缩,则 ClickHouse 会先 ⑦ 进行解压缩,然后 ⑧ 解析原始格式的数据。
接下来,ClickHouse 根据解析出的数据和目标表的 DDL 语句,⑨ 构建一个 MergeTree 格式的内存块。如果数据尚未按主键列排序,则 ⑩ 进行排序。随后,⑪ 创建稀疏主键索引,⑫ 对各列数据进行压缩,并将数据作为新的 ⑭ 数据分片写入磁盘。
在深入分析 ClickHouse 的插入处理机制后,我们可以总结出一系列客户端调优选项。这些关键优化可以有效降低服务器负载,从而提升数据导入性能。核心思路是将部分计算任务转移到客户端,以优化服务器端的处理效率:
① 批量处理数据,减少插入开销并提高处理效率。
② 预排序数据,避免服务器端进行排序操作。
③ 选择服务器端处理更高效的数据格式,减少解析和转换成本。
④ 对数据进行压缩,降低传输数据量,提高网络效率。
这些优化策略可以提升服务器端的导入效率和吞吐量,但通常需要客户端投入额外的计算资源。
不过,正如我们即将展示的,在所有优化措施中,选择高效的数据格式 (③) 对性能的影响最大,其次是数据压缩 (④)。预排序 (②) 在某些特定场景下有帮助,但整体影响相对较小。而批处理 (①) 独立于其他优化措施,它能够减少插入开销,但不会直接影响格式效率、压缩或排序。
在掌握这些优化策略之后,下一步是了解 ClickHouse 支持的输入格式。格式的选择对数据导入性能至关重要。在下一节中,我们将简要介绍 ClickHouse 的输入格式,并通过基准测试量化格式选择、压缩、预排序和批处理对数据导入效率的影响。
ClickHouse 提供多种数据格式用于输入(以及输出)。当客户端持续收集数据且没有固定格式时,必须先 ① 转换为适当格式,然后再 ② 发送到服务器,服务器会对其进行处理,并存储为 MergeTree 表格式:
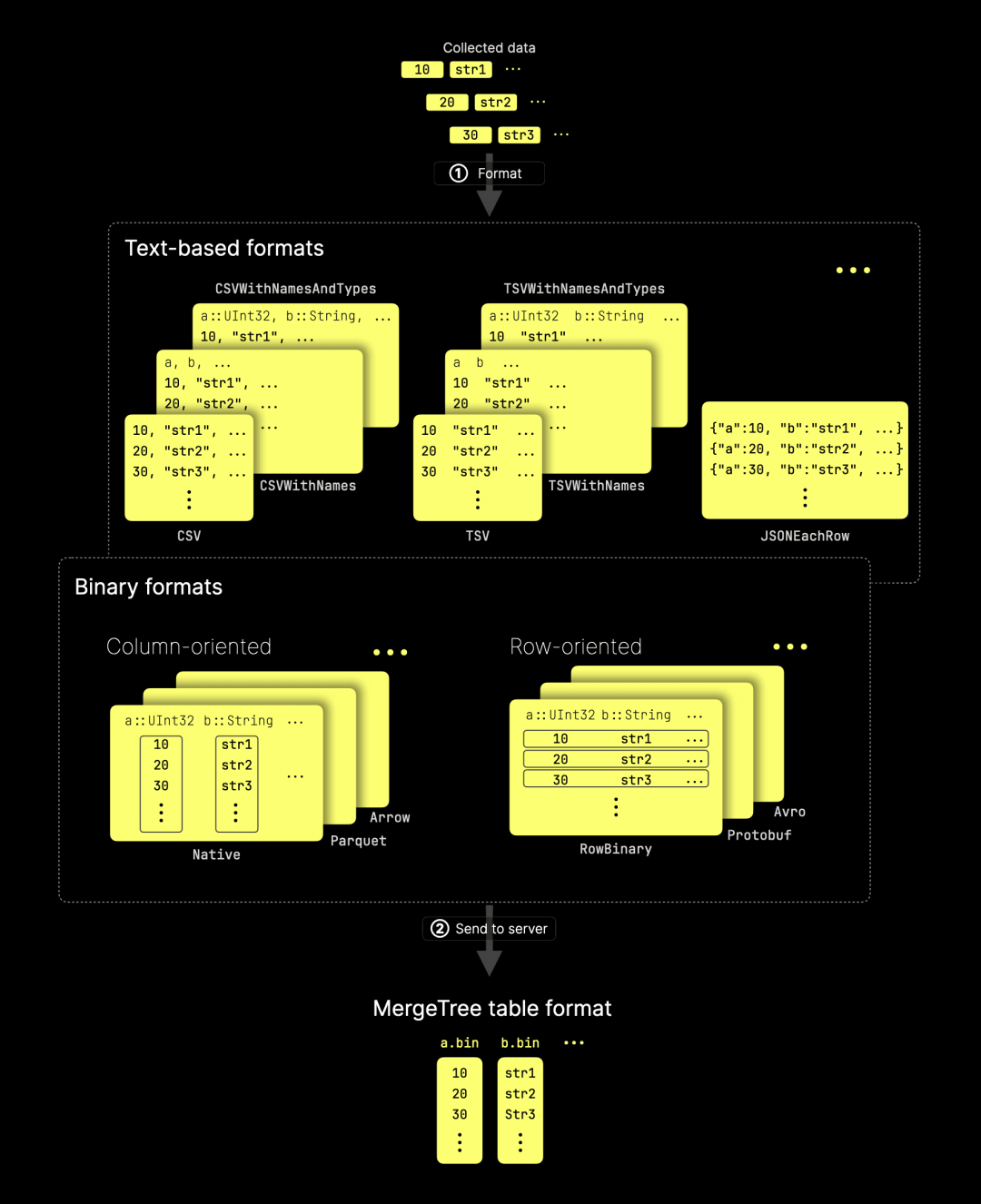
如图所示,ClickHouse 支持的 70 多种输入格式可大致分为三类:
文本格式(如 CSV、TSV 和 JSON 及其变体)。
二进制格式,进一步细分为:
列存格式(如 Native、Parquet、Arrow)。
行存格式(如 RowBinary、Protobuf、Avro)。
ClickHouse 原生支持所有这些格式,无需依赖第三方工具,即可高效加载数据。
在需要高效数据导入的持续推送场景中,可选的格式大大减少。其中,ClickHouse 的 Native 格式是最具优势的选择,我们稍后将对此进行详细分析。Native 格式专为高性能、低延迟数据处理设计,提供高压缩比,能够优化网络传输,并且最大程度减少服务器端的解析和转换开销。例如,如图所示,Native 格式采用的列存结构与 MergeTree 表的存储格式高度匹配,因此服务器端几乎不需要额外的数据转换。
为了量化不同格式的效率,并找出最适合高吞吐量数据导入的输入格式,我们进行了 FastFormats 基准测试。下一节将简要介绍其测试方法和核心机制。
为了系统评估客户端优化策略的影响,我们开发了 FastFormats——一个专门的基准测试工具,用于测量不同输入格式的数据导入速度和硬件效率,同时评估预排序、压缩和批处理的影响。
FastFormats 主要关注服务器端的处理时间,确保测试结果仅衡量服务器端的性能,而不受客户端计算时间的干扰。核心原则是服务器端硬件保持不变,而客户端资源可以扩展以提升处理速度。也就是说,尽管客户端的处理时间可能有所变化,只要服务器硬件不变,服务器端的处理时间就保持一致。
接下来的小节将介绍基准测试的执行机制,并详细说明我们如何基于这一原则确保性能比较的准确性。随后,我们将深入分析测试结果。
数据集
FastFormats 采用与 ClickBench 相同的 Web 分析数据集,确保测试数据能真实反映 ClickHouse 在生产环境中的典型应用场景,而非仅仅依赖合成测试数据。该数据集来源于实际的 Web 流量日志,并经过匿名化处理,同时保留了核心的数据分布特征。
基准测试机制
FastFormats 采用嵌套循环遍历数据集,并按照不同的批量大小、格式、预排序和压缩方式进行测试:
For BATCH_SIZE in [10k rows, 100k rows, 1M rows]:Split the dataset tsv file into N tsv files with BATCH_SIZE rows per file.For FORMAT in [CSV, TSV, Native, Parquet, Avro, Arrow, ...]:For PRESORT in [yes, no]:Convert all N tsv files into N files in FORMAT (via clickhouse-local).Pre-sort each formatted file (if not "no") (also via clickhouse-local).For COMPRESSOR in [none, lz4, zstd, ...]:Send all N formatted files sequentially to ClickHouse (with curl) for ingestion into the target table.Compress each file with COMPRESSOR (if not "none") before sending.Collect server-side insert performance metrics from system tables.Assemble a result document for this run and add it to the results folder.
通过这一流程,我们确保所有批量大小、数据格式、预排序和压缩方式组合下的服务器端数据导入性能都能被准确测量,并排除客户端处理的影响。
最终,测试产生了约 2000 份结果文档(4 种批量大小 × ~60 种格式 × 2 种预排序设置 × ~4 种压缩方式)。为便于分析,我们提供了一个在线分析仪表板,帮助用户直观地探索和比较测试结果。
这些测试数据是动态更新的——随着 ClickHouse 性能的不断优化,我们会定期重新运行基准测试,以确保结果能够反映最新版本的性能提升。
接下来的小节将介绍测试时需要考虑的特殊情况和边界条件,以确保测量结果的准确性。
具有内置压缩的格式
部分数据格式自带压缩功能,例如 Avro 和 Arrow 采用块级压缩,而现代列式存储格式(如 Parquet)则支持列级和块级压缩。
对于这些格式,我们在 clickhouse-local 预处理测试数据时,会应用相应的压缩参数,并跳过数据发送到 ClickHouse 之前的额外压缩步骤。原因是双重压缩不会显著提升压缩率,反而会增加 CPU 负担。
不受支持或冗余的格式
并非所有数据格式都适用于本次基准测试。例如:LineAsString 仅支持单个字符串字段。Npy 适用于 NumPy 数组存储格式。JSONAsObject 要求数据包含单个 JSON 字段。ProtobufSingle 适用于单条消息,不适用于批量数据插入。这些格式已被排除在基准测试之外。此外,一些格式只是别名,例如:NDJSON 和 JSONLines 是 JSONEachRow 的别名。TSV 是 TabSeparated 的同义词。为避免重复测试,我们仅保留其中的一个代表性格式。
ClickHouse 的 Native 接口与 HTTP 接口对比
HTTP 接口允许独立测试所有输入格式的服务器端数据导入性能,而 Native 接口仅支持 Native 格式。
为了保证测试的完整性,我们在基准测试中分别测试了 HTTP 和 Native 接口。然而,两者的测试结果不能直接对比,HTTP 接口,我们使用 curl 发送 已预排序、格式转换和压缩的数据。服务器端的性能指标仅衡量数据导入效率,不包含客户端的预处理开销(排序、格式化和压缩),这使得测试更专注于不同格式的服务器端表现。
Native 接口,我们使用 clickhouse-client,它采用流式的块级网络压缩,提升传输效率。在传输前自动转换数据为 Native 格式。因此,服务器端的性能数据,仅衡量 Native 格式的处理性能。包含数据压缩的传输时间,与 HTTP 接口的测试方式有所不同。
测试环境硬件配置
本次基准测试的硬件配置如下:
客户端机器:AWS EC2 m6i.8xlarge 实例(32 核 CPU,128 GiB RAM),用于运行 FastFormats。 服务器集群:ClickHouse Cloud 三节点计算集群(每个节点 30 核 CPU,120 GiB RAM)。 网络环境:客户端与服务器均部署在同一 AWS 区域(us-east-2),以消除额外的网络延迟影响。
在本部分,我们将重点介绍以下测试条件下的关键发现:
① 每次插入 10k 行数据。
② 采用 ClickHouse HTTP 接口。
①对于10k 行批量插入,不同格式的未压缩数据大小差异较大:最小:ORC(2 MiB)。最大:JSON(27 MiB)。大多数格式介于 5 MiB(Native)到 8 MiB(CSV) 之间。这些数据大小与 ClickHouse 异步插入的默认 10 MiB 缓冲区刷新阈值一致。因此,我们的基准测试采用的经典同步批量插入具有类似的性能特征,无需单独测试异步插入。
②此外,只有 HTTP 接口支持非 Native 格式以及额外的压缩选项。
完整的 10k 行批量插入测试结果可通过 FastFormats 在线仪表板(预设筛选条件)查看。
下图展示了 8 种常见输入格式在 1000 次连续插入(每次 10k 行) 时的总服务器端处理时间。 所有格式分别测试了以下四种方式:
未压缩 LZ4 压缩 预排序 + LZ4 压缩 ZSTD 压缩 预排序 + ZSTD 压缩
此外,我们还展示了服务器接收的数据总量:

测试涵盖以下格式:三种二进制列存格式(Native、ArrowStream、Parquet)。一种二进制行存格式(RowBinary)。三种文本格式(TSV、CSV、JSONEachRow)。JSON 的二进制格式(BSONEachRow)。
在所有测试的格式中,Native 格式在 10k 行批量大小下的导入速度最快,不仅仅是在上方的图表中如此。在完整的测试结果中,其他格式的相对排名与图表中所示一致。相比其他格式,Native 格式的导入速度提升如下。
在 LZ4 压缩模式下,服务器端使用 Native 格式接收并导入 2.55 GiB 数据,仅耗时 131 秒。相较于其他格式:
比 ArrowStream 快 10%(2.93 GiB 数据耗时 146 秒)
比 RowBinary 快 18%(3.27 GiB 数据耗时 161 秒)
比 TSV 快 31%(4.22 GiB 数据耗时 190 秒)
比 Parquet 快 32%(2.77 GiB 数据耗时 192 秒)
比 CSV 快 36%(4.32 GiB 数据耗时 204 秒)
比 BSONEachRow 快 38%(4.65 GiB 数据耗时 210 秒)
比 JSONEachRow 快 51%(5.39 GiB 数据耗时 266 秒)
因此,我们推荐在数据导入过程中使用 Native 格式。
如果 DDL 依赖计算字段,则客户端需要在本地预先计算并指示服务器跳过计算。目前仅 clickhouse-client 支持此功能。
此外,数据传输格式 ≠ 目标表的列类型。例如,在可观测性(observability)场景下:采集 JSON 数据,以 Native 格式高效传输,存储到 JSON 类型的列。ClickHouse Go 客户端可将 JSON 序列化为 Variant 或 Dynamic 列,并转换为 Native 格式,同时启用高效压缩。
压缩的影响
LZ4 以速度优先,牺牲部分压缩率,适用于低 CPU 开销的快速网络传输,同时在客户端和服务器端的计算负担极小。
ZSTD 提供更高的压缩比,但需要稍高的服务器解压缩计算量,在客户端端的压缩成本显著增加。
在所有测试的格式和编解码器中,Native 格式的速度最快,且压缩比最高,尤其适用于跨区域数据传输需要支付 CSP(云服务提供商)费用的场景,因其可以大幅减少网络带宽消耗。
在未压缩情况下,服务器使用 Native 格式导入 5.60 GiB 数据,耗时150 秒。LZ4 压缩后,数据量缩小至 2.55 GiB,导入时间减少至 131 秒。ZSTD 压缩进一步减少数据至 1.69 GiB(比 LZ4 额外减少 34%),但服务器端处理时间增加 10 秒,因其解压缩计算开销更高,部分抵消了带宽优化带来的收益。在低带宽环境中,ZSTD 可能仍能提供整体吞吐量提升,因为在这种情况下,网络传输时间通常是主要瓶颈。
在本次测试环境中,客户端与服务器位于同一 CSP 区域,因此压缩与未压缩之间的插入处理时间差异不大。
选择压缩方式的建议: 如果网络传输成本是关键因素,建议使用 ZSTD 或其他高压缩比算法。否则,LZ4 是最佳选择,它能在所有场景下以最小计算开销进行压缩,加速数据传输,并降低整体导入时间。
预排序的影响
传输预排序且压缩的数据可以带来两大关键优化:预排序可提升压缩效率,因为排序后的数据更容易被高效压缩。预排序能让服务器跳过排序步骤,减少额外的计算开销,加快数据导入速度。
总体而言,预排序能提升导入性能,但增益幅度有限。
我们的基准测试使用单线程(单客户端)方式对每种格式的插入性能进行独立评估。
然而,在实际应用场景(如可观测性)中,通常有数百甚至数千个客户端并发发送数据。为了评估高负载下的性能,我们首先分析单线程插入时 CPU 和内存占用情况(使用上一节的 8 种常见输入格式),然后测试并发插入时的性能表现。
下图展示了单个服务器节点在测试过程中每次插入的 CPU 和内存使用情况(99% 分位数):
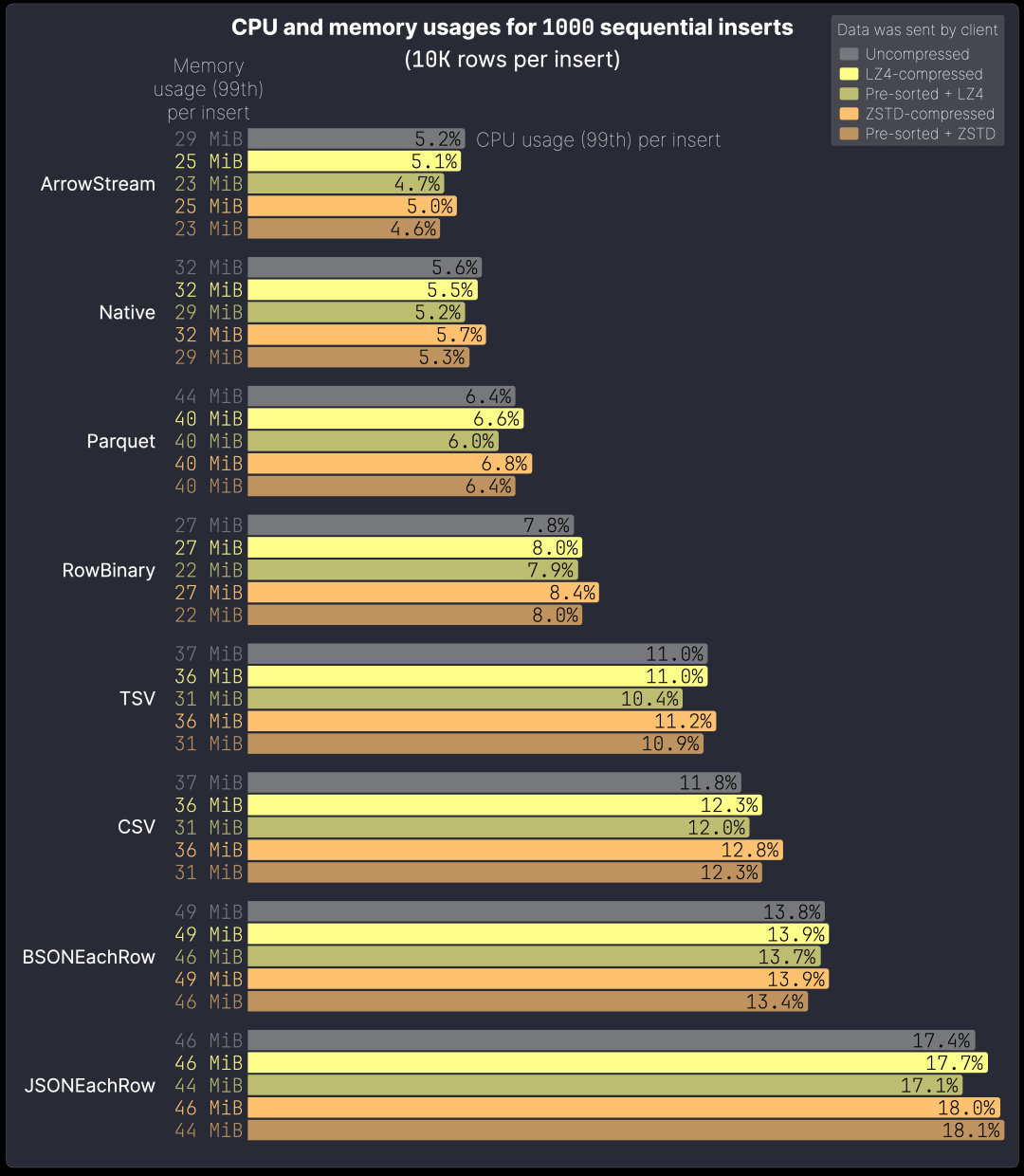
图表中的排名与上一节略有不同,因为此处的排序依据是低 CPU 和内存消耗,而非总体插入速度。
ArrowStream 在单次插入时的资源效率略高于 Native,而 Parquet 比 RowBinary 更高效。然而,Native 格式的压缩率更优(见上一节),因此整体插入速度更快。
文本格式(TSV、CSV、JSONEachRow)的插入速度比 Native 慢 30%~51%,同时 CPU 占用远高于 Native。 以 LZ4 压缩数据为例:
TSV:11% vs. Native:5.5% → 高 100% CSV:12% vs. Native:5.5% → 高 118% JSONEachRow:17% vs. Native:5.5% → 高 209%
这使得文本格式在高并发负载下不如 Native 高效。尤其是在多个客户端同时发送数据的场景中,JSONEachRow 并不是将 JSON 数据插入 JSON 列的最佳选择,Native 格式完全可以替代 JSONEachRow 进行高效插入。
压缩与预排序的影响
上图展示了客户端压缩和预排序对服务器端 CPU 负载的影响,同时也略微影响内存占用:LZ4 压缩对服务器端 CPU 影响 几乎可以忽略。ZSTD 压缩 提供更高的压缩比,但增加了解压缩计算开销,尤其是在数据未预排序时,CPU 负载上升更明显。
在某些情况下,客户端压缩还能降低服务器端的 CPU 负载,因为数据量减少后,传输优化的收益超过了解压缩的计算成本。
如前所述,预排序 + 压缩具有双重优化:预排序提升压缩效率,减少服务器需要接收和处理的数据量。预排序允许服务器跳过排序步骤,进一步降低计算开销。
从服务器 CPU 和内存使用情况可以看出:LZ4 压缩几乎不影响服务器 CPU 负载。ZSTD 压缩虽然占用更多 CPU 资源,但影响在可接受范围内。即使使用 LZ4,压缩也能显著减少网络传输的数据量。结合压缩和预排序,可最大化服务器端的资源利用率,尤其是在高并发数据导入场景下。
最终建议,我们推荐优先使用 Native 格式,并配合压缩进行数据导入。
并发客户端的插入效率分析
此前,我们主要分析了单客户端顺序执行插入时的 CPU 和内存消耗,并使用 query_log 系统表跟踪每次插入的资源占用。 然而,在实际工作负载中,ClickHouse 通常需要处理多个客户端的并发插入,例如: 在可观测性(observability) 场景下,数百或数千个代理(agents)会同时发送监控数据。
在并发插入情况下,监控服务器端资源占用变得更加复杂:单客户端插入时,可以直接从 query_log 统计每次插入的 CPU 和内存消耗。 多客户端并发插入时,数据会负载均衡到多个服务器节点,因此需要按服务器节点汇总资源使用情况,并考虑多个任务同时执行的影响。此外,本次测试未包含服务器端的 后台任务(如数据分片合并等周期性计算)。
为了评估高并发插入对服务器性能的影响,我们使用 metric_log 系统表监控整体 CPU 和内存占用。 测试步骤:测量服务器空闲状态下的基准负载。使用 Native + LZ4 压缩格式,测试不同批量大小(batch size)和并发客户端数量下的插入性能:

上图展示了不同批量大小和并发客户端数量(1、5、10 个)下,服务器端 99% 分位 CPU 和内存使用情况,包括后台合并任务的影响。测试环境:使用脚本模拟并发插入,在测试机上生成多个并发数据导入序列。测试限制:并发客户端数最多支持 10 个,以避免 32 核测试机成为性能瓶颈,确保服务器端仍是主要测试对象。
从上图可以看出:CPU 和内存使用量随着并发客户端数量增加而呈次线性增长(即增长趋势低于线性比例)。 批量大小越大,CPU 和内存消耗增长更明显。原因: 并发客户端的插入并非完全同步到达服务器。小批量插入处理速度快,服务器端任务仅偶尔重叠,导致 CPU 和内存的瞬时峰值,但整体负载较低。
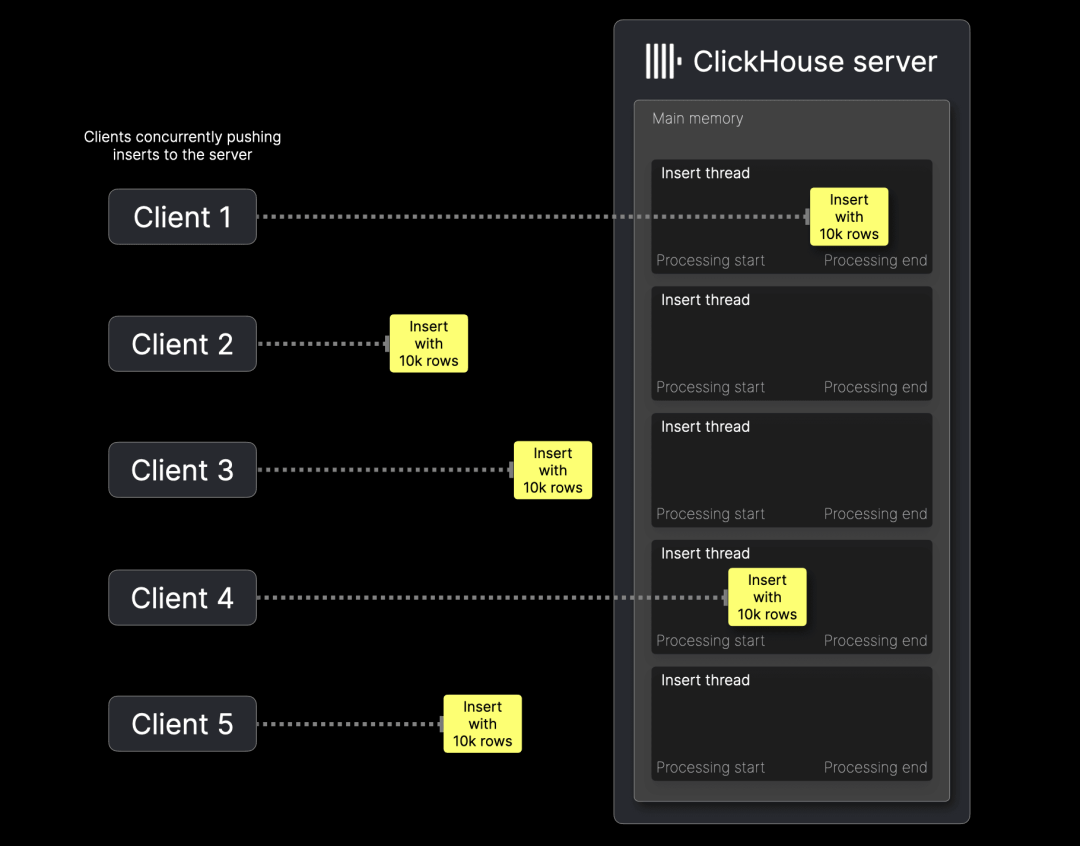
然而,较大批量的插入需要更长的服务器处理时间。更容易导致服务器端任务重叠,进而造成更持续的 CPU 和内存增长。
小批量插入的 CPU 和内存使用呈次线性增长,并不会导致明显的资源瓶颈。 随着批量大小和并发客户端数量增加,资源消耗增长更快。当所有客户端的插入操作同时进行时,服务器资源消耗达到峰值。
我们曾提到,ClickHouse 的数据处理能力就像一辆高性能 F1 赛车 🏎——你拥有强大的计算资源,可以发挥极限性能。但要真正优化数据导入速度,必须合理调整批量大小,就像驾驶 F1 需要在适当时机切换到更高档位。 下图展示了这一优化过程:
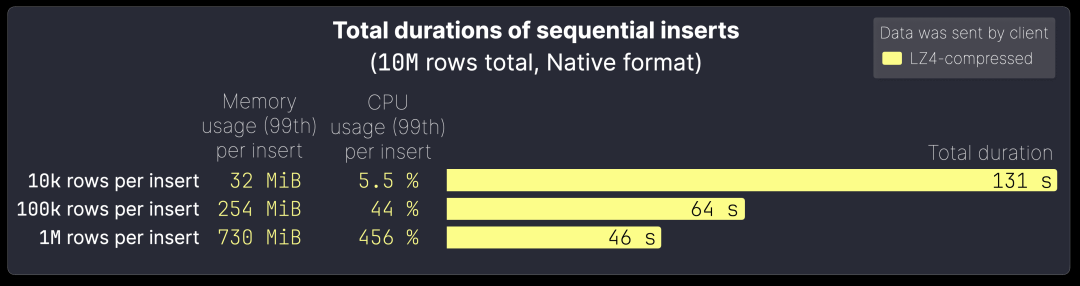
该图展示了在 Native 格式下,使用 LZ4 压缩时,插入 1000 万行数据的总服务器端处理时间,并对比了不同批量大小的影响。
批量越大,数据导入吞吐量越高,但每次插入的资源消耗也相应增加:
10k 行/批次(1000 次插入,共 1000 万行),总导入时间:131 秒;每次插入内存占用:32 MiB;CPU 占用:5.5%。 100k 行/批次(100 次插入,共 1000 万行),导入时间减少近一半,缩短至 64 秒;单次插入的内存消耗提升至 254 MiB;CPU 占用上升至 44%。 1M 行/批次(10 次插入,共 1000 万行),总导入时间进一步缩短至 46 秒,单次插入的内存占用增加至 730 MiB,CPU 负载达到 456%(约 4.56 个 CPU 核心并行处理),由此可见,批量大小的优化是提升 ClickHouse 导入性能的关键。
我们建议在可用内存和 CPU 资源允许的情况下,尽可能增加批量大小,但同时需要综合考虑并发客户端数量和系统整体负载。 合理调整批量大小不仅可以大幅提升数据导入吞吐量,还能确保系统性能稳定。
ClickHouse 的命令行客户端和各类编程语言客户端,会根据使用场景和接口自动优化数据导入格式。 在大多数情况下,它们默认使用高效的 Native 格式。 接下来的两节,我们将详细解析 ClickHouse 支持的两种数据导入接口。
Native 接口
为了演示Native 接口的特性,我们使用 clickhouse-client 进行测试。 它是功能最全面的客户端,能够充分利用 Native 接口的优势。
下图展示了clickhouse-client 发送数据到 ClickHouse 服务器时的导入流程:
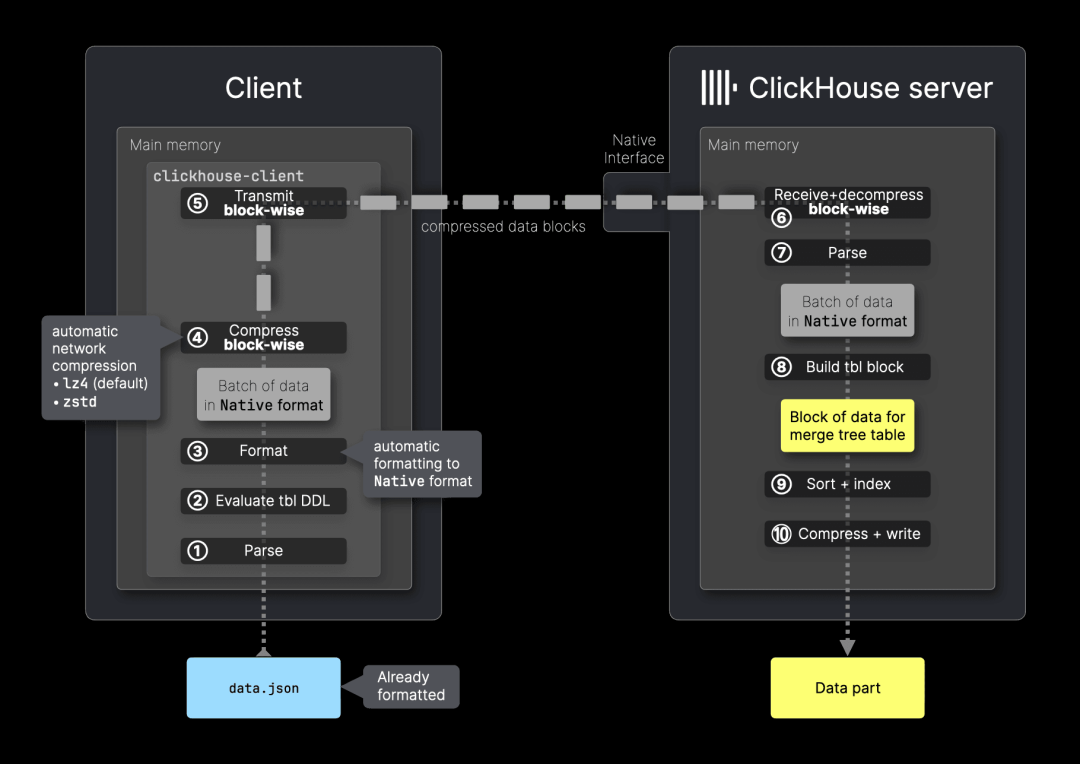
clickhouse-client 仅支持 Native 接口,并遵循计算前移的原则,即尽可能将计算任务转移到客户端,以减少服务器端的计算开销。 它不会直接发送原始数据(如 TSV 或 JSON),而是:解析输入数据(①)。 转换为高效的 Native 格式(③),以优化网络压缩率,并降低服务器端的解析和转换成本。
由于Native 格式与 MergeTree 表的存储结构完全一致,服务器可以直接写入数据,无需额外转换,从而减少服务器端步骤 ⑧ 的计算负担。 Native 格式是 Native 接口唯一支持的输入格式。
此外,Native 接口支持按数据块(block)进行流式压缩和解压缩:clickhouse-client 默认采用 LZ4(默认)或 ZSTD 进行压缩(④)。数据通过流式传输(⑤),避免一次性发送大数据块,提高带宽利用率。这使得 Native 接口成为 ClickHouse 最高效的数据导入方式之一。
客户端计算 MATERIALIZED 和 DEFAULT 值
在 clickhouse-client 中,输入数据会 自动转换为 Native 格式,这一特性得益于 Native 接口的高级通信机制,并经过额外的工程优化才能实现。
假设服务器上创建了如下 DDL 语句的表,并向该表插入数据:
CREATE TABLE test(data JSON,c String MATERIALIZED data.b.c)ORDER BY();
为了构造符合 MergeTree 存储格式的数据块(步骤 ⑧),ClickHouse 服务器需要访问原始 JSON 输入,以计算列 c 的 MATERIALIZED 值。 该计算依赖于从 JSON 数据的嵌套路径 b.c 提取值。
为了避免服务器端额外的计算负担,clickhouse-client 通过 Native 接口执行以下优化: 从服务器检索目标表的 DDL 语句。 在客户端执行 MATERIALIZED(或 DEFAULT)值计算,将该计算从服务器端步骤 ⑧ 转移到客户端步骤 ②。指示服务器跳过该计算,从而客户端可以直接使用 Native 格式插入数据,而无需保留 JSON 格式。这样,客户端能够在本地计算所有必要的字段值,并以最高效的格式发送完全处理好的数据:

需要注意的是,目前仅 clickhouse-client 支持在客户端计算 MATERIALIZED 和 DEFAULT 值,确保始终使用 Native 格式进行插入,以获得最佳性能。
ClickHouse 服务器针对高效、低延迟的数据处理进行了深度优化,而 clickhouse-client 也采用相同的优化策略。 借助Native 接口的高级优化技术,可以确保数据的高效传输,同时最小化服务器端的计算负担。
HTTP 接口
我们使用 curl 作为客户端,演示 ClickHouse 的 HTTP 接口:
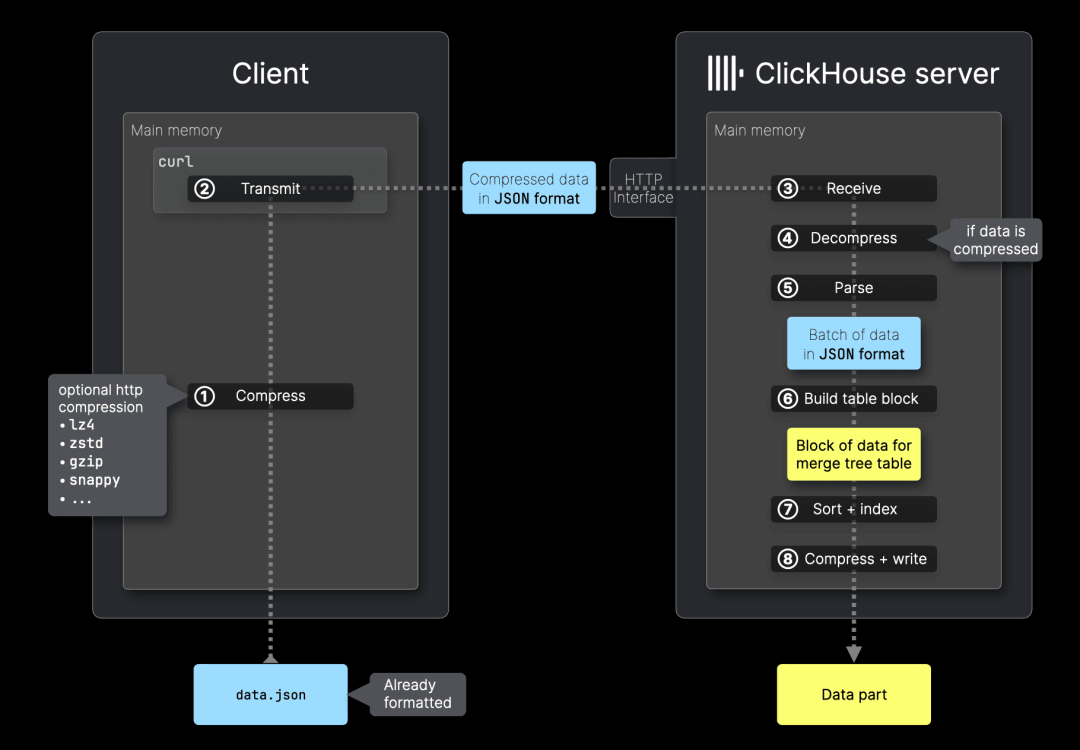
与Native 接口不同,HTTP 接口支持所有 ClickHouse 兼容的输入格式,不仅限于 Native 格式。
在 HTTP 接口中:支持 FORMAT 子句,但 不支持 COMPRESSION 子句,并且 不会自动检测数据压缩类型。要启用压缩,需要使用 HTTP 传输层压缩,并在请求头 Content-Encoding 中指定压缩方式。数据在传输前被整体压缩,而不像 Native 接口那样支持块级压缩。
尽管HTTP 接口允许以 Native 格式发送数据,但它缺少 Native 接口的高级通信机制,因此: 如果目标表的 DDL 依赖于特定格式(如 JSON),客户端无法查询表结构并调整数据格式。无法像 Native 接口那样,让服务器跳过 MATERIALIZED 和 DEFAULT 值的计算。因此,通过 HTTP 接口插入数据时,客户端无法自动确保数据转换为 Native 格式。
尽管存在上述限制,HTTP 接口提供了比 Native 接口更高的灵活性: 支持更多输入格式,无需受限于 Native 格式。支持比 LZ4 和 ZSTD 更多的压缩方式,适用于不同的网络环境。
在前文中,我们使用 clickhouse-client 演示了 Native 接口,并使用 curl 介绍了 HTTP 接口。 除了这些命令行工具外,各种 编程语言客户端对这两种接口的支持情况有所不同。 下表提供了整体概览,并包含 clickhouse-client 作为参考:
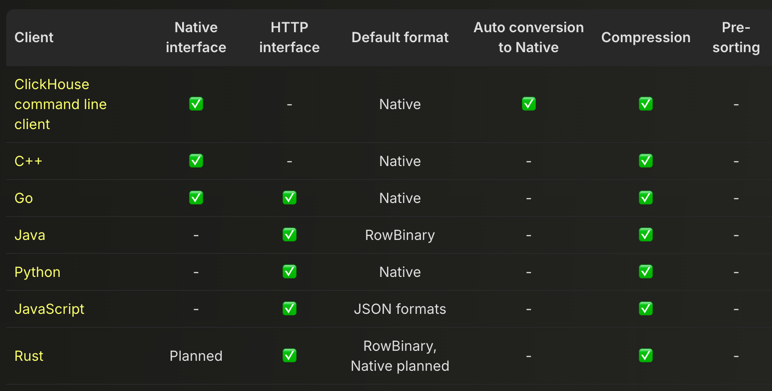
目前,除 ClickHouse 命令行客户端外,Native 接口仅被 C++ 和 Go 客户端支持,Rust 版本支持尚在规划阶段。所有主流编程语言客户端(除 C++ 外)均支持 HTTP 接口。
clickhouse-client 是当前功能最完整的客户端,可充分利用 Native 协议,并具备:自动将输入数据转换为 Native 格式。在客户端执行 MATERIALIZED 和 DEFAULT 值的计算。
需要注意的是: 目前没有任何客户端会在发送数据前自动预排序,预排序需要手动实现,但可能比服务器端排序效率更低。
客户端的特性支持取决于应用程序的典型工作负载:C++ 和 Go 主要用于高吞吐量的数据插入,因此它们的客户端默认支持 Native 接口。JavaScript 更常用于查询密集型应用,因此其客户端主要支持 HTTP 接口。这种差异直接影响不同语言客户端的功能设计。
本篇文章深入分析了 ClickHouse 支持的输入格式,并评估了不同格式对服务器端数据导入效率的影响。
优化客户端插入的核心原则:尽可能将计算任务从服务器端转移到客户端,以减少服务器负载。 在所有影响插入性能的因素中,选择高效的输入格式是最关键的。 基于 FastFormats 基准测试,我们得出以下结论:
Native 格式是所有测试场景下最优的输入格式,因其具备: 最高的压缩率、 最低的服务器端计算开销、 最小的内存与 CPU 资源占用 数据压缩是优化传输的关键:LZ4 压缩以最小的 CPU 开销减少数据体积,从而提升传输速度并降低插入延迟。如果网络带宽成本较高,可以考虑 ZSTD 压缩,但需注意其更高的 CPU 计算开销。 预排序的影响适中:ClickHouse 的并行排序通常比客户端更快。 仅在数据本身已接近有序,且客户端资源充足时,才推荐预排序。 批量大小对插入效率影响显著: 建议尽可能增大批量大小(受限于可用内存和 CPU)。 大批量插入可以减少请求开销,提高数据导入吞吐量。
ClickHouse 客户端会自动优化数据导入流程,高吞吐量插入的客户端(如 C++ 和 Go)优先采用 Native 格式,以获得最佳性能。
/END/
 注册ClickHouse中国社区大使,领取认证考试券
注册ClickHouse中国社区大使,领取认证考试券

ClickHouse社区大使计划正式启动,首批过审贡献者享原厂认证考试券!
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


