




作者:ShunWah
在运维管理领域,我拥有多年深厚的专业积累,兼具坚实的理论基础与广泛的实践经验。我始终站在技术前沿,致力于推动运维自动化,不懈追求运维效率的最大化。
我精通运维自动化流程,对于OceanBase、MySQL等多种数据库的部署与运维,具备从初始部署到后期维护的全链条管理能力。凭借OceanBase的OBCA和OBCP认证、OpenGauss社区认证结业证书,以及崖山DBCA、亚信AntDBCA、翰高HDCA、GBase 8a | 8c | 8s、Galaxybase GBCA、Neo4j Graph Data Science Certification、NebulaGraph NGCI & NGCP等多项权威认证,我不仅展现了自己的专业技能,也彰显了对技术的深厚热情与执着追求。
在OceanBase & 墨天轮的技术征文大赛中,我凭借卓越的技术实力和独特的见解,多次荣获一、二、三等奖。同时,在OpenGauss第五届、第六届、第七届技术征文大赛,TiDB社区第三届专栏征文大赛,金仓数据库有奖征文活动,以及首批YashanDB「产品体验官」尝鲜征文等活动中,我也屡获殊荣。此外,我还活跃于墨天轮、CSDN等技术平台,经常发布原创技术文章,并多次被首页推荐,积极与业界同仁分享我的运维经验和独到见解。

前言
在大数据时代背景下,数据库的可扩展性和性能成为了企业关注的焦点。传统的关系型数据库在面对海量数据时,往往会遇到性能瓶颈和扩展难题。特别是在处理大规模数据时,传统的关系型数据库往往难以满足性能和可扩展性的需求。近期,我有幸阅读了二教老师的《播客|陨石撞地球也不怕?OceanBase CTO 杨传辉畅谈数据安全的“终极保障”》,对OceanBase及其背后的分布式技术有了更为深入的理解。文中提到的“原生分布式”概念以及OceanBase如何在不采用分库分表策略下实现高效的数据复制机制,让我对“分布式”这一术语有了全新的认识。OceanBase 原生分布式数据库如的出现,为我们提供了全新的视角和解决方案。本文将首先介绍OceanBase 4.3中的数据复制机制及“原生分布式”概念,随后详细阐述在OceanBase中进行分库分表的操作实践。在阅读了日照老师的解说(https://mp.weixin.qq.com/s/5jh8sA4qw72mlMmLjZ86uw)后,我终于对之前未曾深入探究的‘分布式’概念有了清晰的认识。这一术语听起来确实很酷,而现在,我已明了其真正含义。在此基础上,我决定撰写本文,学习OceanBase中的分库分表实践,同时回顾并分享我对“原生分布式”概念的理解。
一、OceanBase 原生分布式概述
OceanBase 数据库作为原生分布式数据库,区别于集中式数据库,其分区是独立的存储、高可用、事务单位,表的不同分区可以分布于不同服务器上,利用多机性能加快大表查询速度。同时,OceanBase 的原生分布式能力使应用程序可以像调用单机数据库一样使用,减少业务改造成本。
OceanBase 数据库采用 shared-nothing 架构,按日志流、分片(Tablet)组织用户数据。Tablet 具备存储数据的能力,支持在机器之间迁移(transfer),是数据均衡的最小单位。
在分布式环境下,为保证数据读写服务的高可用,OceanBase 数据库会把同一个日志流的数据拷贝到多个机器。不同机器同一个日志流的数据拷贝称为副本(Replica)。同一日志流的多个副本使用 Paxos 一致性协议保证副本的强一致,每个日志流和它的副本构成一个独立的 Paxos 组,其中一个日志流为主副本(Leader),其它日志流为从副本(Follower)。主副本具备强一致性读和写能力,从副本具备弱一致性读能力。
分区概述
在 OceanBase 数据库中,分区是指根据一定的规则,把一个表分解成多个更小的、更容易管理的部分。每个分区都是一个独立的对象,具有自己的名称和可选的存储特性。本章节主要介绍分区的相关概念以及使用分区的好处。
分区与分片:数据分布的核心机制
在 OceanBase 数据库中,分区(Partition) 是用户创建的逻辑对象,用于划分和管理表数据。每个分区对应一个物理存储对象,称为 Tablet,它是数据存储的基本单位,支持跨机器迁移,是数据均衡的最小粒度。
分区策略:
OceanBase 支持多种分区策略,包括 HASH、RANGE 和 LIST 等,满足不同业务场景的需求。例如:
按时间范围(RANGE)划分订单表。
按用户 ID 的哈希值(HASH)分布数据以实现负载均衡。
支持二级分区,例如先按用户 ID 划分为一级分区,再按月份划分为二级分区。
透明性:
分区对业务完全透明,用户无需修改现有 SQL 查询即可使用分区功能。这种设计既保留了关系数据库的易用性,又实现了分布式系统的扩展性。
二、从零构建分库分表:
无需人工分库分表的“自动分片”机制
- 数据按分区键(Partition Key)自动分片,存储层透明处理路由。
- 支持**Range(范围)、Hash(哈希)、List(列表)**等分区策略,与业务场景深度匹配。
1、使用 root 用户登录集群的 sys 租户。
[root@iZbp1h19y65t4hrdwapxz9Z ~]# obclient -h127.0.0.1 -uroot@sys -P2881 -Doceanbase -A
Welcome to the OceanBase. Commands end with ; or \g.
Your OceanBase connection id is 3221487617
Server version: OceanBase_CE 4.2.1.0 (r100000102023092807-7b0f43693565654bb1d7343f728bc2013dfff959) (Built Sep 28 2023 07:25:28)
Copyright (c) 2000, 2018, OceanBase and/or its affiliates. All rights reserved.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
obclient [oceanbase]>
复制
2、创建数据库与分区表
2.1 – 创建数据库
obclient [oceanbase]> CREATE DATABASE ob_ecommerce;
Query OK, 1 row affected (0.021 sec)
obclient [oceanbase]>
复制
2.2 – 创建订单表
(按用户ID哈希分片,4个分区)
obclient [oceanbase]>
obclient [oceanbase]> CREATE TABLE orders (
-> order_id BIGINT NOT NULL AUTO_INCREMENT,
-> user_id INT NOT NULL,
-> product_id INT,
-> amount DECIMAL(10,2),
-> order_time DATETIME DEFAULT CURRENT_TIMESTAMP,
-> PRIMARY KEY(order_id, user_id) -- 分区键需包含在主键中
-> ) PARTITION BY HASH(user_id) PARTITIONS 4;
Query OK, 0 rows affected (0.106 sec)
obclient [oceanbase]>
复制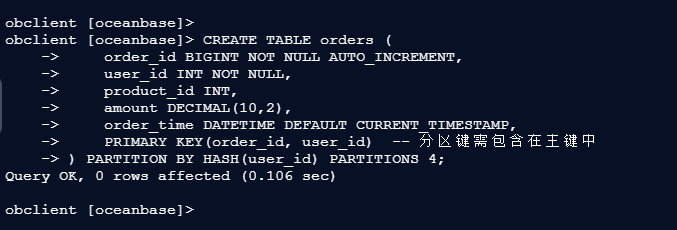
2.3 – 创建日志表
(按时间范围分片)
obclient [oceanbase]>
obclient [oceanbase]> CREATE TABLE user_behavior (
-> log_id BIGINT AUTO_INCREMENT,
-> user_id INT,
-> action VARCHAR(50),
-> log_time DATETIME DEFAULT CURRENT_TIMESTAMP,
-> PRIMARY KEY(log_id, log_time)
-> ) PARTITION BY RANGE COLUMNS(log_time) (
-> PARTITION p202301 VALUES LESS THAN ('2023-02-01'),
-> PARTITION p202302 VALUES LESS THAN ('2023-03-01'),
-> PARTITION p202303 VALUES LESS THAN ('2023-04-01')
-> );
Query OK, 0 rows affected (0.046 sec)
obclient [oceanbase]>
复制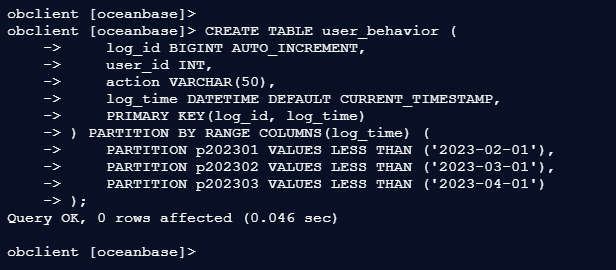
3、插入数据并验证分布
3.1 – 插入订单数据
(自动路由到对应Hash分区)
obclient [oceanbase]>
obclient [oceanbase]> INSERT INTO orders (user_id, product_id, amount) VALUES
-> (1001, 202, 99.99),
-> (1002, 305, 199.99),
-> (1003, 101, 50.00);
Query OK, 3 rows affected (0.020 sec)
Records: 3 Duplicates: 0 Warnings: 0
obclient [oceanbase]>
复制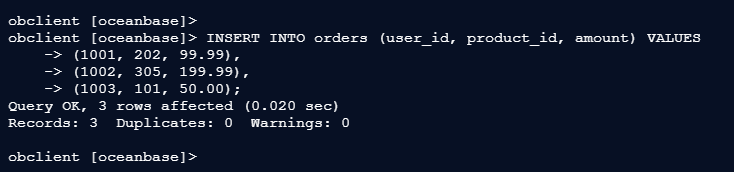
3.2 – 查询数据分布
(通过系统表查看分区归属)
obclient [oceanbase]>
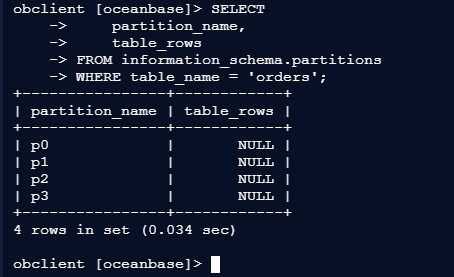
obclient [oceanbase]> SELECT
-> partition_name,
-> table_rows
-> FROM information_schema.partitions
-> WHERE table_name = 'orders';
复制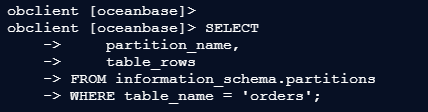
– 输出示例:
+----------------+------------+
| partition_name | table_rows |
+----------------+------------+
| p0 | NULL |
| p1 | NULL |
| p2 | NULL |
| p3 | NULL |
+----------------+------------+
4 rows in set (0.034 sec)
obclient [oceanbase]>
复制(数据根据Hash(user_id)均匀分布)
4、执行跨分区分布式事务
4.1 – 更新用户订单并记录日志
(跨分区事务)
obclient [oceanbase]>
obclient [oceanbase]> BEGIN;
Query OK, 0 rows affected (0.000 sec)
obclient [oceanbase]> UPDATE orders SET amount = 150 WHERE user_id = 1001;
Query OK, 0 rows affected (0.002 sec)
Rows matched: 1 Changed: 0 Warnings: 0
obclient [oceanbase]> INSERT INTO user_behavior (user_id, action, log_time)
-> VALUES (1001, 'update_amount', '2023-01-15 10:00:00');
Query OK, 1 row affected (0.001 sec)
obclient [oceanbase]> COMMIT;
Query OK, 0 rows affected (0.001 sec)
obclient [oceanbase]>
复制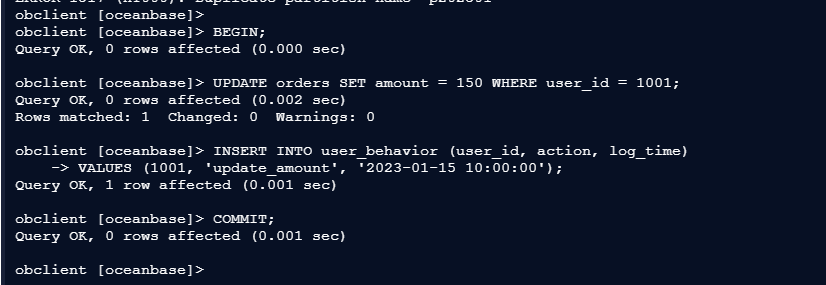
三、管理分库分表的基本测试
1、哈希(Hash)分区:
根据哈希函数将数据均匀分布到多个分区中。适合需要均匀分布的场景。
1.1 – 创建分区表,按 id 列进行哈希分区
obclient [oceanbase]>
obclient [oceanbase]> CREATE TABLE products (
-> id INT PRIMARY KEY,
-> name VARCHAR(255),
-> description TEXT,
-> price DECIMAL(10, 2)
-> ) PARTITION BY HASH(id) PARTITIONS 4;
Query OK, 0 rows affected (0.136 sec)
obclient [oceanbase]>
复制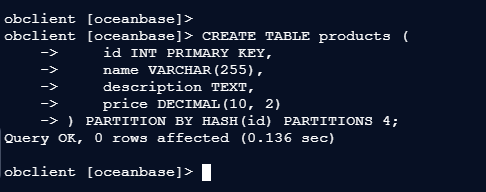
1.2 插入数据
obclient [oceanbase]>
obclient [oceanbase]> INSERT INTO products (id, name, description, price) VALUES
-> (1, '苹果', '新鲜红富士苹果', 3.99),
-> (2, '香蕉', '进口大蕉', 2.49),
-> (3, '牛奶', '全脂鲜牛奶', 4.99),
-> (4, '面包', '法式长棍面包', 2.99);
Query OK, 4 rows affected (0.019 sec)
Records: 4 Duplicates: 0 Warnings: 0
obclient [oceanbase]>
复制
1.3 查询数据
obclient [oceanbase]>
obclient [oceanbase]> SELECT * FROM products WHERE id = 1;
+----+--------+-----------------------+-------+
| id | name | description | price |
+----+--------+-----------------------+-------+
| 1 | 苹果 | 新鲜红富士苹果 | 3.99 |
+----+--------+-----------------------+-------+
1 row in set (0.002 sec)
obclient [oceanbase]>
复制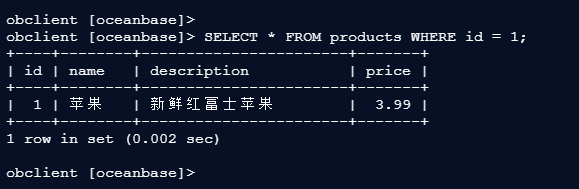
1.4 查看分区信息
obclient [oceanbase]> SHOW CREATE TABLE products;
+----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| products | CREATE TABLE `products` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`description` text DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by hash(id)
(partition p0,
partition p1,
partition p2,
partition p3) |
+----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.006 sec)
obclient [oceanbase]>
复制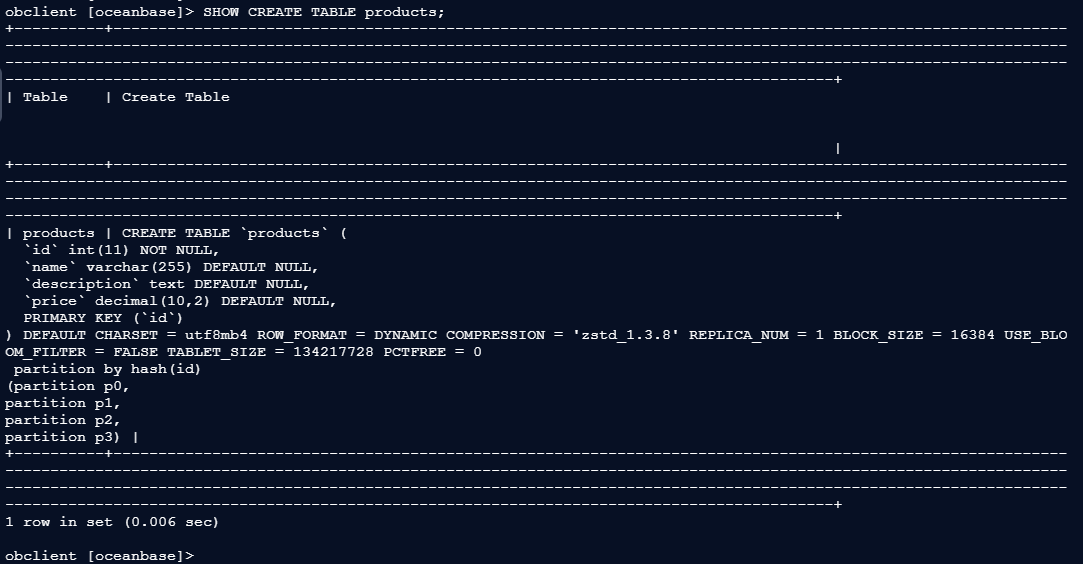
2、组合分区(二级分区)
使用 Range + Hash 的二级分区方式
组合分区是先使用一种分区策略(一级分区),然后在子分区中使用另一种分区策略(二级分区)。这种策略适合处理超大规模数据表。
示例:在一个包含 create_time 和 user_id 列的表中:
一级分区:按 create_time 使用 Range 分区。
二级分区:按 user_id 使用 Hash 分区。
以下是创建一个库和表的操作命令示例,基于您提供的需求:在一个包含 create_time 和 user_id 列的表中,一级分区按 create_time 使用 Range 分区,二级分区按 user_id 使用 Hash 分区。
2.1 创建数据库
在 OceanBase 数据库中,可以通过 CREATE DATABASE 命令创建一个新的数据库。例如:
obclient [oceanbase]>
obclient [oceanbase]> CREATE DATABASE my_database;
Query OK, 1 row affected (0.023 sec)
obclient [oceanbase]>
复制
切换到新创建的数据库:
obclient [oceanbase]> USE my_database;
Database changed
obclient [my_database]>
复制
2.2 创建表并定义分区
根据您的需求,创建一个包含 create_time 和 user_id 列的表,并使用 Range + Hash 的二级分区方式。
一级分区:按 create_time 使用 Range 分区SUBPARTITION BY HASH (user_id) – 二级分区:按 user_id 使用 Hash 分区
obclient [my_database]>
obclient [my_database]> CREATE TABLE user_bill (
-> user_id INT,
-> create_time DATETIME,
-> bill_amount DECIMAL(10, 2),
-> PRIMARY KEY (user_id, create_time)
-> )
-> PARTITION BY RANGE (TO_DAYS(create_time))
-> SUBPARTITION BY HASH (user_id)
-> SUBPARTITIONS 4
-> (
-> PARTITION p0 VALUES LESS THAN (TO_DAYS('2023-01-01')),
-> PARTITION p1 VALUES LESS THAN (TO_DAYS('2024-01-01')),
-> PARTITION p2 VALUES LESS THAN (TO_DAYS('2025-01-01'))
-> );
Query OK, 0 rows affected (0.098 sec)
obclient [my_database]>
复制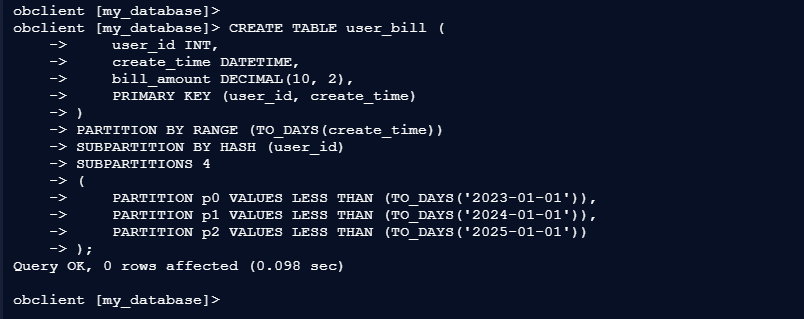
一级分区(RANGE 分区):
使用 TO_DAYS(create_time) 将 DATETIME 类型的时间值转换为天数(整型),以便满足 RANGE 分区的要求。
定义了三个一级分区:
p0 包含 create_time < ‘2023-01-01’ 的数据。
p1 包含 ‘2023-01-01’ <= create_time < ‘2024-01-01’ 的数据。
p2 包含 ‘2024-01-01’ <= create_time < ‘2025-01-01’ 的数据。
二级分区(HASH 分区):
按照 user_id 列进行 HASH 分区,将每个一级分区的数据进一步划分为 4 个子分区。
使用 SUBPARTITIONS 4 指定每个一级分区的二级分区数量。
主键定义:
主键由 user_id 和 create_time 组成,确保数据的唯一性。
2.3 验证分区
创建表后,可以使用以下命令验证分区是否正确创建:
obclient [my_database]>
obclient [my_database]> SHOW CREATE TABLE user_bill;
+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| user_bill | CREATE TABLE `user_bill` (
`user_id` int(11) NOT NULL,
`create_time` datetime NOT NULL,
`bill_amount` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`user_id`, `create_time`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by range(TO_DAYS(create_time)) subpartition by hash(user_id) subpartition template (
subpartition p0,
subpartition p1,
subpartition p2,
subpartition p3)
(partition p0 values less than (738886),
partition p1 values less than (739251),
partition p2 values less than (739617)) |
+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.004 sec)
obclient [my_database]>
复制这条命令会显示表的详细定义,包括分区规则和分区数量。通过查看输出结果,您可以确认分区是否按照预期创建。
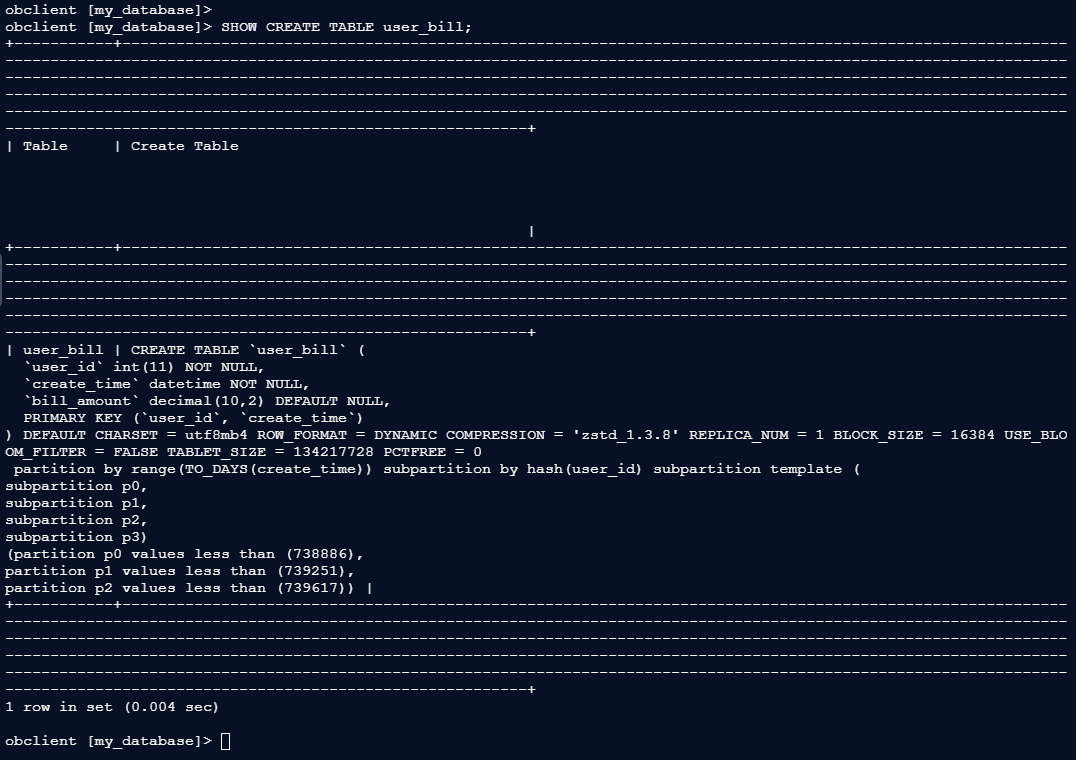
这将显示表的详细定义,包括分区规则和分区数量。
通过以上步骤,您可以成功创建一个包含 Range + Hash 二级分区的表,满足用户账单领域的典型需求。如果需要进一步调整分区策略或添加更多列,请提供更多业务细节,我可以为您优化设计!
3、联合主键分区
3.1-- 创建联合主键包含分区键
obclient [oceanbase]> CREATE TABLE user_orders (
-> order_id BIGINT,
-> user_id BIGINT,
-> amount DECIMAL(10,2),
-> PRIMARY KEY(order_id, user_id)
-> ) PARTITION BY HASH(user_id) PARTITIONS 4;
Query OK, 0 rows affected (0.126 sec)
obclient [oceanbase]>
复制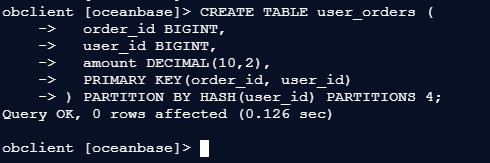
3.2 数据分布验证
查看分区物理分布
obclient [oceanbase]>
obclient [oceanbase]> SELECT * FROM oceanbase.DBA_OB_TABLE_LOCATIONS
-> WHERE TABLE_NAME='USER_ORDERS';
+---------------+-------------+----------+------------+----------------+-------------------+------------+---------------+-----------+-------+-------+-----------+----------+--------+--------------+-----------------+-----------+-----------------+---------------+----------+
| DATABASE_NAME | TABLE_NAME | TABLE_ID | TABLE_TYPE | PARTITION_NAME | SUBPARTITION_NAME | INDEX_NAME | DATA_TABLE_ID | TABLET_ID | LS_ID | ZONE | SVR_IP | SVR_PORT | ROLE | REPLICA_TYPE | DUPLICATE_SCOPE | OBJECT_ID | TABLEGROUP_NAME | TABLEGROUP_ID | SHARDING |
+---------------+-------------+----------+------------+----------------+-------------------+------------+---------------+-----------+-------+-------+-----------+----------+--------+--------------+-----------------+-----------+-----------------+---------------+----------+
| oceanbase | user_orders | 500002 | USER TABLE | p0 | NULL | NULL | NULL | 200001 | 1 | zone1 | 127.0.0.1 | 2882 | LEADER | FULL | NONE | 500003 | NULL | NULL | NULL |
| oceanbase | user_orders | 500002 | USER TABLE | p1 | NULL | NULL | NULL | 200002 | 1 | zone1 | 127.0.0.1 | 2882 | LEADER | FULL | NONE | 500004 | NULL | NULL | NULL |
| oceanbase | user_orders | 500002 | USER TABLE | p2 | NULL | NULL | NULL | 200003 | 1 | zone1 | 127.0.0.1 | 2882 | LEADER | FULL | NONE | 500005 | NULL | NULL | NULL |
| oceanbase | user_orders | 500002 | USER TABLE | p3 | NULL | NULL | NULL | 200004 | 1 | zone1 | 127.0.0.1 | 2882 | LEADER | FULL | NONE | 500006 | NULL | NULL | NULL |
+---------------+-------------+----------+------------+----------------+-------------------+------------+---------------+-----------+-------+-------+-----------+----------+--------+--------------+-----------------+-----------+-----------------+---------------+----------+
4 rows in set (0.074 sec)
obclient [oceanbase]>
复制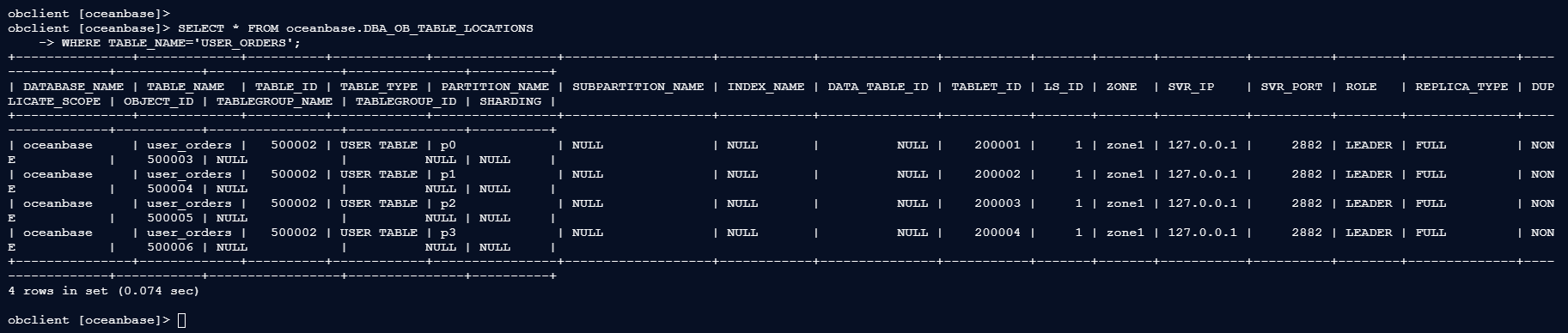
四、进阶技巧:动态扩容与分区管理
在 OceanBase 数据库中,动态扩容与分区管理是实现高性能、高可用性和弹性扩展的重要手段。以下是一个进阶技巧,结合动态扩容和分区管理的最佳实践,帮助您优化集群性能并满足业务需求。
1、-- 查看当前分区策略:
使用SHOW CREATE TABLE orders;命令来查看当前表的创建语句和分区策略。
obclient [oceanbase]> SHOW CREATE TABLE orders;
+--------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+--------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| orders | CREATE TABLE `orders` (
`order_id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`product_id` int(11) DEFAULT NULL,
`amount` decimal(10,2) DEFAULT NULL,
`order_time` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`order_id`, `user_id`)
) AUTO_INCREMENT = 4 AUTO_INCREMENT_MODE = 'ORDER' DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by hash(user_id)
(partition p0,
partition p1,
partition p2,
partition p3) |
+--------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.002 sec)
obclient [oceanbase]>
复制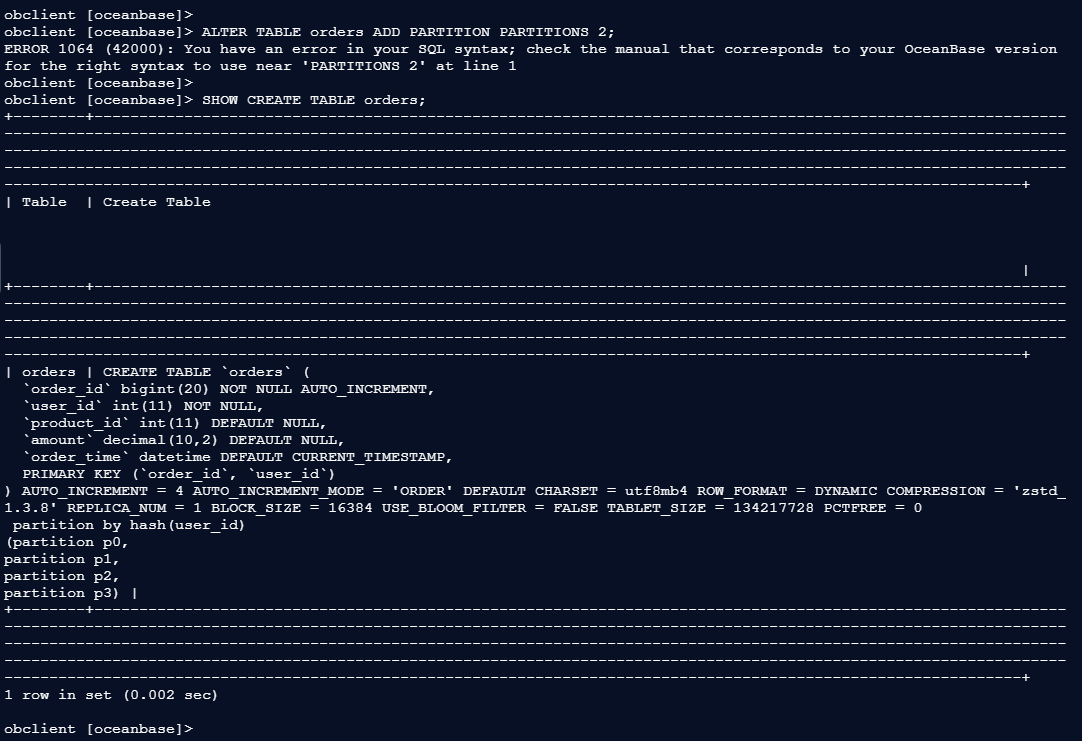
2、在线增加分区
(以Hash/Key 分区表为例)
– 将orders表从4个分区扩容到6个,重建表分区结构;Hash/Key 分区无法直接增加分区数量,需通过 ALTER TABLE … PARTITION BY 语句重新定义分区数:
obclient [oceanbase]> ALTER TABLE orders PARTITION BY HASH(user_id) PARTITIONS 6; -- 将原 4 分区改为 6 分区
Query OK, 0 rows affected (0.589 sec)
obclient [oceanbase]>
复制
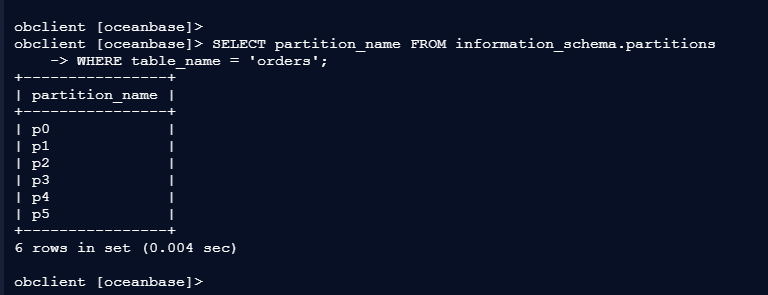
3、查看扩容后分布
obclient [oceanbase]>
obclient [oceanbase]> SELECT partition_name FROM information_schema.partitions
-> WHERE table_name = 'orders';
+----------------+
| partition_name |
+----------------+
| p0 |
| p1 |
| p2 |
| p3 |
| p4 |
| p5 |
+----------------+
6 rows in set (0.004 sec)
obclient [oceanbase]>
复制– 输出:p0, p1, p2, p3, p4, p5(数据自动重分布)
4、 热点分区处理
– 拆分热点分区(假设p202303为热点)
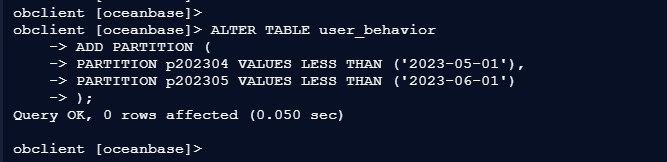
4.1 方案 1:追加未来时间段的分区
若需为未来数据扩展分区,需确保新增分区的起始值严格大于当前最大分区的上限值:
obclient [oceanbase]> ALTER TABLE user_behavior
-> ADD PARTITION (
-> PARTITION p202304 VALUES LESS THAN ('2023-05-01'),
-> PARTITION p202305 VALUES LESS THAN ('2023-06-01')
-> );
Query OK, 0 rows affected (0.050 sec)
obclient [oceanbase]>
复制仅对新写入数据生效,历史数据仍保留在原分区14;
无需数据迁移,操作简单46。
4.2 方案 2:调整分区定义范围
若需在现有分区范围内拆分(如优化历史数据分布),需通过重建表结构实现:
先查看原表分区结构
obclient [oceanbase]> SHOW CREATE TABLE user_behavior;
+---------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| user_behavior | CREATE TABLE `user_behavior` (
`log_id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL,
`action` varchar(50) DEFAULT NULL,
`log_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`log_id`, `log_time`)
) AUTO_INCREMENT = 2 AUTO_INCREMENT_MODE = 'ORDER' DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by range columns(log_time)
(partition p202301 values less than ('2023-02-01 00:00:00'),
partition p202302 values less than ('2023-03-01 00:00:00'),
partition p202303 values less than ('2023-04-01 00:00:00'),
partition p202304 values less than ('2023-05-01 00:00:00'),
partition p202305 values less than ('2023-06-01 00:00:00')) |
+---------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.002 sec)
obclient [oceanbase]>
复制确认现有分区最大值(如 p202303 VALUES LESS THAN (‘2023-04-01’))46。

4.3 新建临时表并调整分区定义
obclient [oceanbase]> CREATE TABLE user_behavior_new (
-> id INT,
-> 时间列 DATE NOT NULL,
-> PRIMARY KEY (id, 时间列)
-> ) PARTITION BY RANGE (TO_DAYS(时间列)) (
-> PARTITION p202301 VALUES LESS THAN (TO_DAYS('2023-02-01')),
-> PARTITION p202302 VALUES LESS THAN (TO_DAYS('2023-03-01')),
-> PARTITION p202303_1 VALUES LESS THAN (TO_DAYS('2023-03-15')),
-> PARTITION p202303_2 VALUES LESS THAN (TO_DAYS('2023-04-01')),
-> PARTITION p202304 VALUES LESS THAN (TO_DAYS('2023-05-01'))
-> );
Query OK, 0 rows affected (0.062 sec)
obclient [oceanbase]>
复制
4.4 迁移数据并切换表
obclient [oceanbase]> BEGIN;
Query OK, 0 rows affected (0.000 sec)
obclient [oceanbase]> INSERT INTO user_behavior_new SELECT * FROM user_behavior;
Query OK, 0 rows affected (0.015 sec)
obclient [oceanbase]> RENAME TABLE user_behavior TO user_behavior_old, user_behavior_new TO user_behavior;
Query OK, 0 rows affected (0.021 sec)
obclient [oceanbase]> COMMIT;
Query OK, 0 rows affected (0.000 sec)
obclient [oceanbase]>
复制- 确保操作要么全部成功,要么回滚:ml-citation{ref=“6,8” data=“citationList”}
4.5 检查分区顺序
obclient [oceanbase]> SELECT PARTITION_NAME, HIGH_VALUE
-> FROM DBA_TAB_PARTITIONS
-> WHERE TABLE_NAME = 'USER_BEHAVIOR';
+----------------+------------+
| PARTITION_NAME | HIGH_VALUE |
+----------------+------------+
| p202301 | 738917 |
| p202302 | 738945 |
| p202303_1 | 738959 |
| p202303_2 | 738976 |
| p202304 | 739006 |
+----------------+------------+
5 rows in set (0.025 sec)
obclient [oceanbase]>
复制
五、总结
本文回顾了我对OceanBase 原生分布式概念的理解,并详细探讨了在该平台上进行分库分表的实践方法。通过本文的探讨,我们可以看到,
OceanBase 数据库通过分区、表组、日志流和副本等机制,实现了原生分布式分库分表的功能。其核心优势包括:
灵活的分区策略:支持多种分区方式,满足不同业务需求。
高效的表组设计:减少跨机操作,优化 JOIN 查询和分布式事务性能。
这种设计不仅继承了传统关系数据库的易用性,还充分发挥了分布式系统的扩展性和灵活性,为大规模数据存储和处理提供了可靠的解决方案。在未来的数据库技术发展中,我们有理由相信,原生分布式数据库将成为处理大规模数据的首选方案。
—— 仅供参考。如果有更多具体的问题或需要进一步的帮助,请随时告知。
