




背景
多模态大语言模型(MLLM)以大语言模型(LLM)为基础,能同时处理图像与文本等多种模态的信息。凭借强大的语言推理能力,MLLM在视觉问答、图像描述等任务中展现出了卓越的性能。然而,现有模型经常会出现幻觉(hallucination),即生成看似合理却并不正确的回答或描述。
现有的MLLM幻觉原因主要可以分为两类,其一是模态偏差(bias),指模型可能出现“只依赖文本”或“只依赖图像”的倾向,从而忽略了对另一模态关键信息的理解;其二是理解能力不足,指模型没能理解某模态的内容,导致做出错误推理。
本文围绕这两方面,介绍近期有关幻觉成因与缓解方法的相关论文。
模态偏差
Quantifying and Mitigating Unimodal Biases in Multimodal Large Language Models: A Causal Perspective
该论文从因果的视角量化和缓解单模态偏差。论文构建了一个因果图,以刻画在VQA任务中,各个因果要素对模型预测的影响方式,下图中的绿色子图代表人类回答VQA问题的因果机制:从问题文本Q中解码出核心语义S,从图像I中识别出核心实体E,将E和S结合推导出正确答案G。然而,现有MLLM往往由直接从Q和I获得答案A,并不清楚两种模态的信息是如何相互作用并生成答案的。理想情况下,模型应对G具有敏感性和鲁棒性,也就是说,答案A 不应因为与正确答案无关的信息而改变。
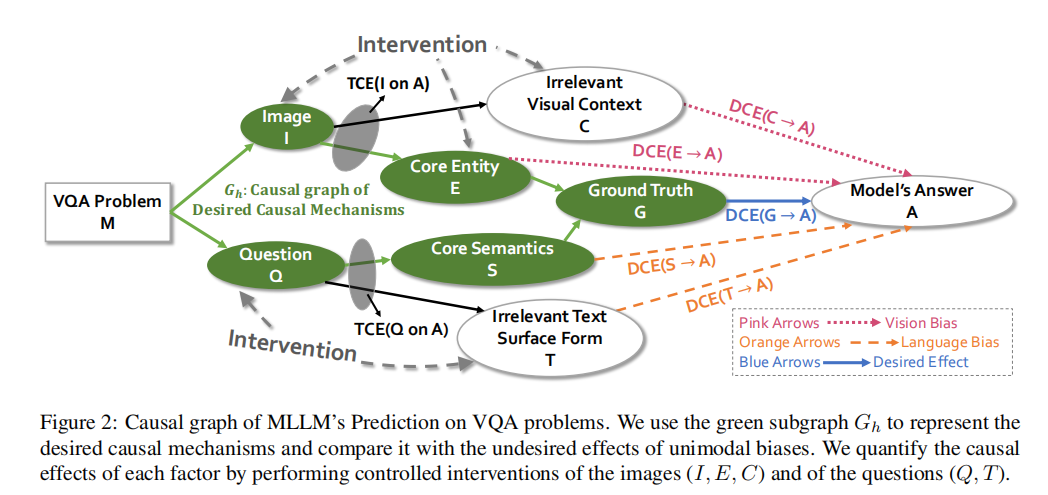
在这一因果分析框架下,作者引入了TCE(总体因果效应)与DCE(直接因果效应)来衡量单个因子对答案的影响。TCE代表从图像或问题等变量出发,经过所有可能路径对模型最终答案A产生的整体影响,用以衡量模型是否对两种模态的信息足够敏感;而DCE则只考虑与该变量直接相连的局部因果路径,排除其他中介因素干扰,用于度量模型在面对无关视觉背景或无关表层文本等噪声信息时,能否保持答案的稳定性。
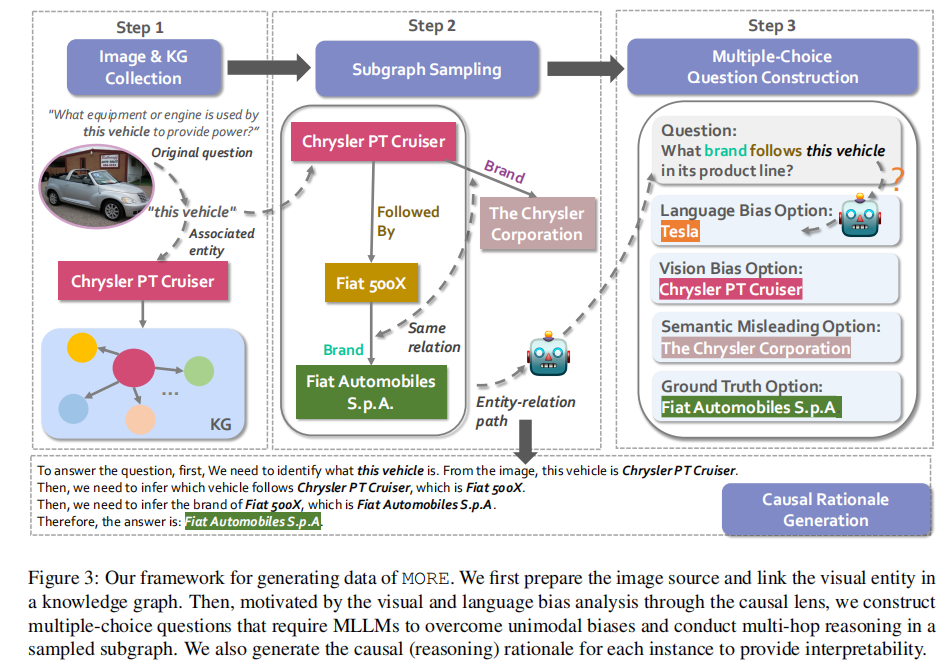
为了更好地检验并量化这些单模态偏差,作者构建了一个全新的VQA数据集MORE,共包含12,000个VQA样本,主要涉及2-hop、3-hop的复杂知识推理。具体流程是:使用已有的INFOSEEK数据集,其中图像实体与Wikipedia对齐,从Wikidata5M中检索与这些实体在三跳以内的相关知识路径。基于每个实体-关系路径,让大语言模型自动生成相应的多跳问题。然后为每个问题设置对应4个候选答案,其中包括:
•语言偏差选项:只提供文本信息时LLM的回答。
•视觉偏差选项:图像中实体的名称。
•语义误导选项:图像中实体与其检索得到的邻居共同拥有的一条关系所指向的实体。
•正确答案:该多跳路径最终得到的实体。
通过这些干扰选项,可以同时测试模型是否容易落入单模态偏差,或是否能真正对问题进行多跳推理。
为了缓解单模态偏差,作者提出了CAVE(Causality-enhanced Agent Framework)框架,主要包含以下阶段:
使用问题分解器,将复杂的多跳问题拆分为若干子问题,对于每个子问题:
•使用因果关系增强的推理器,判断重新表述问题文本,或用同一实体从不同角度或不同时间捕获的另一个图像替换图像是否改变子问题答案。如果需要改变子问题答案,则对问题进行重新分解,直到它确定当前的子问题是适当的和准确的。
•使用验证器,利用RAG方法,检索相关的图像或文本并验证子问题答案是否正确。
最后,将多轮子问题及检索结果进行综合,给出最终答案。

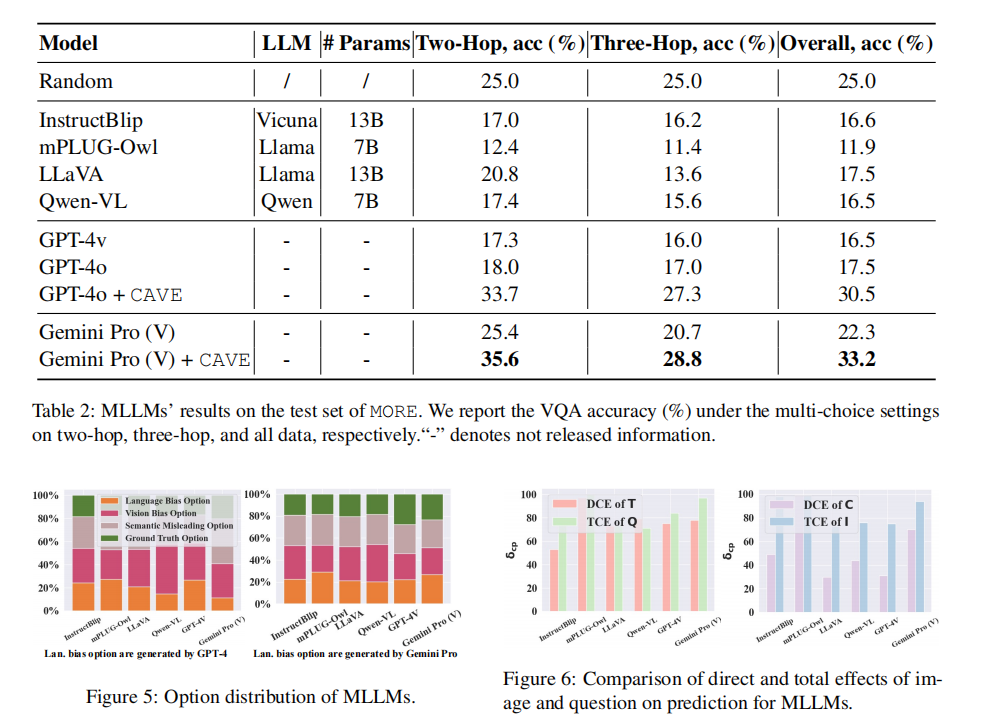
实验结果表明,多数主流多模态大模型在MORE上的多选答题准确率普遍较低,甚至低于随机猜测,引入CAVE后,模型的准确率有显著提升。进一步统计各模型在推理时偏向哪种类型的干扰选项,发现语言偏差与视觉偏差都广泛存在,语义误导也常常能使模型出错。这表明尽管模型尝试进行多跳推理,但未能将所有必要关系整合到位。
通过数据层面的“干预”手段(如替换问题中无关的文本、替换图像背景等),作者量化了模型的TCE和DCE。结果显示,许多大模型的TCE较高,即对图像或文本变动十分敏感;但DCE 也偏高,模型常常会因为与正确答案无关的噪声而改变答案,表现出对无关因素的过度敏感。
OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation
该论文发现,当出现“幻觉”时,往往伴随一种“知识聚合模式”(knowledge aggregation pattern):幻觉的发生常常在具有柱状注意特征的token后。而这些token往往是缺乏实质性信息的,如句号或引号。
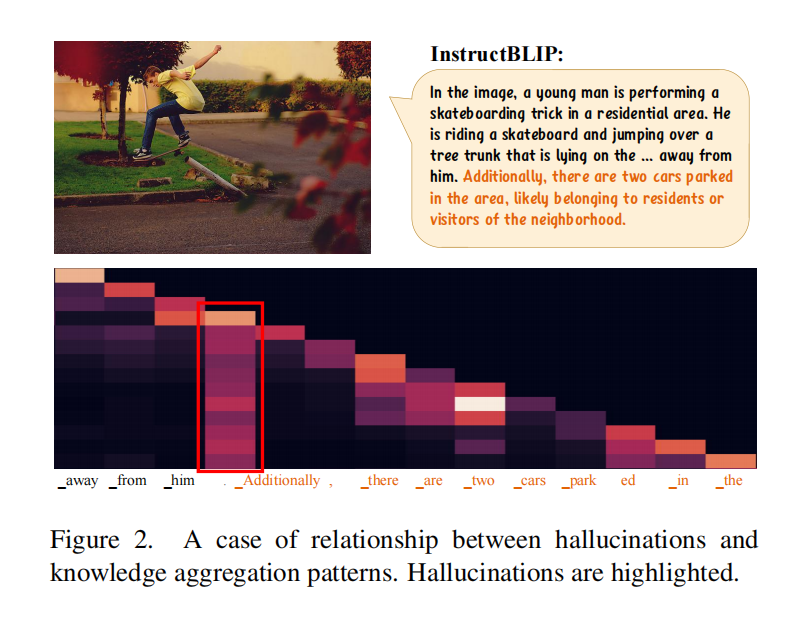
论文假设这样的token起到了summary token的作用,它集合了序列中先前token的关键知识,并指导后续token的生成。目前的MLLM往往将视觉token放在序列的最前端位置,当序列变长的时候,单个token不能记住整个图像的信息,视觉信息被减弱,所以后续的token可能会忽略最前面的视觉token,而过度信任邻近的summary token。summary token越多,则发生幻觉的概率越大。
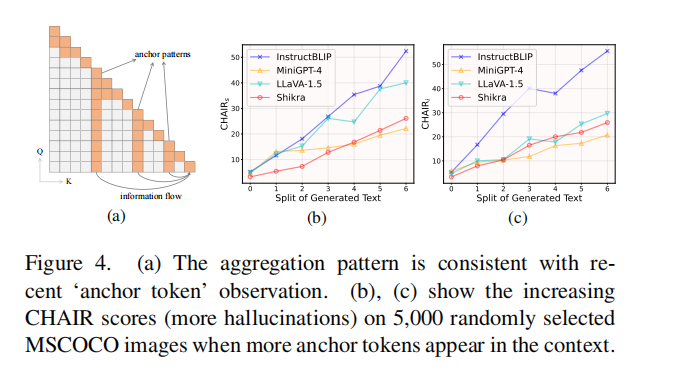
这种知识聚合特征具有显著的滞后性,即当相应的summary token被解码时,不能立即观察到这种特征,但在后续的token被解码出来之后,幻觉可能已经发生了。为了缓解这种幻觉,文章提出了OPERA(Over-trustPenalty and a Retrospection-Allocation strategy)方法,主要有两个核心思路:
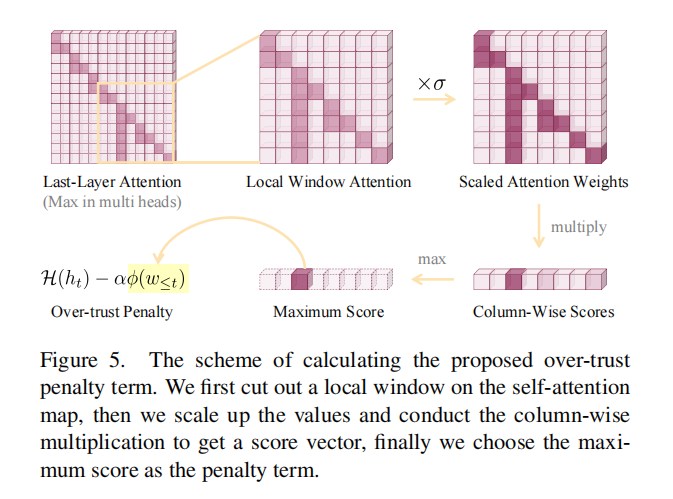
•Over-trust Logit Penalty
解码时,关注最后一层注意力矩阵,截取自注意力矩阵中的一个局部窗口。将所有权重放大,在注意力矩阵的下三角部分上进行列级乘法,得分越大代表这种知识聚合模式越明显。选择列级得分向量的最大值作为这一子序列的知识聚合模式的惩罚项。在beam得分上加入这一惩罚项,以指导序列的生成。
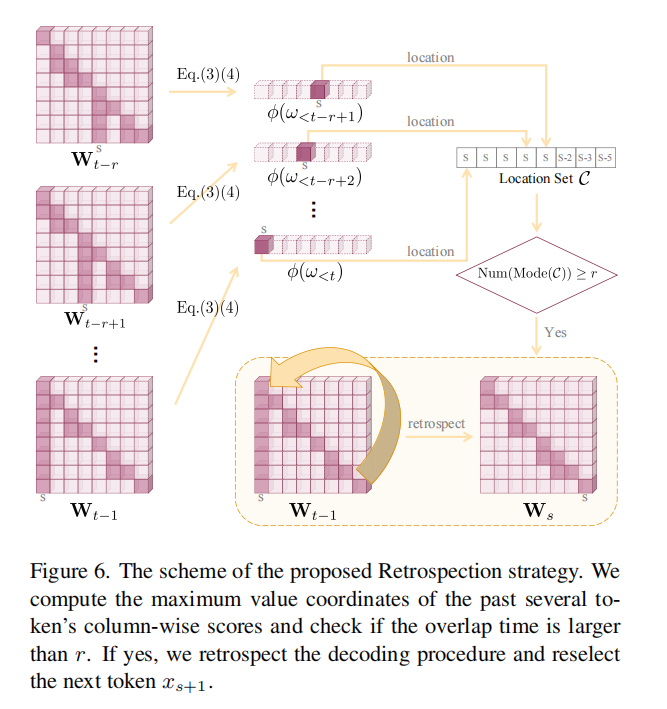
•Retrospection-Allocation
单纯的惩罚有时不足以彻底纠正幻觉。如果已经出现了强烈的“知识聚合”迹象,使得所有候选解码分支都带有幻觉,单次惩罚无法选出没有幻觉的的分支。为此,文章进一步提出“回溯”:一旦检测到连续多次知识聚合得分的最大值都在同一个token位置上,就回溯到到这个summary token,从该位置之后重新解码。
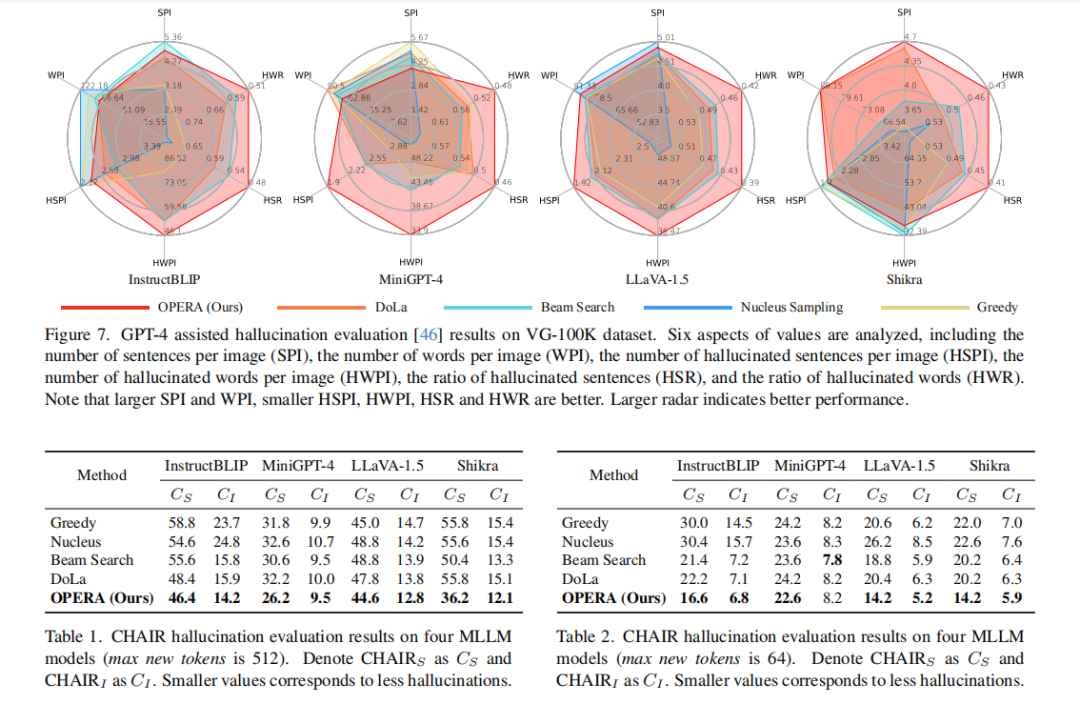
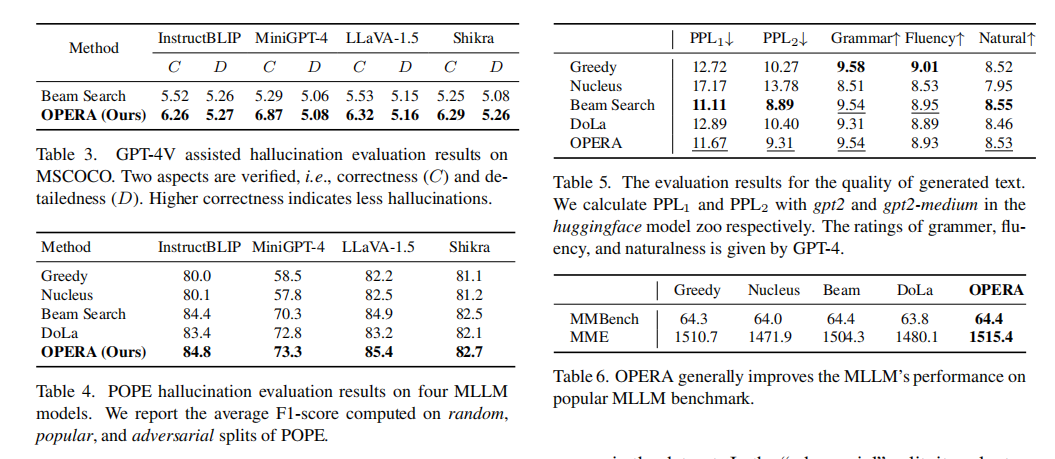
实验证明,OPERA在多种多模态大模型上都能显著减少幻觉发生,并且在流畅度、自然度等语言质量方面与原版Beam Search或其他采样策略相比,没有明显下降,在一些场景下还略有提升。
Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding
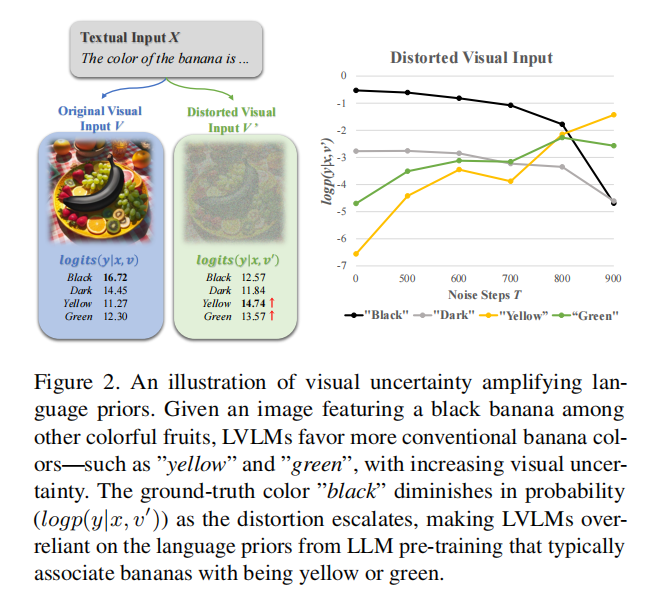
该论文通过在原始图像上添加高斯噪声(称作“扭曲图像”),并观察模型对“原始图像+文本”与“扭曲图像+文本”两种输入形式下的输出分布差异,发现当图像扭曲程度越大,越容易产生幻觉。作者认为主要是因为:
•模糊的图像使得模型对LLM的语言先验的依赖变得更明显。
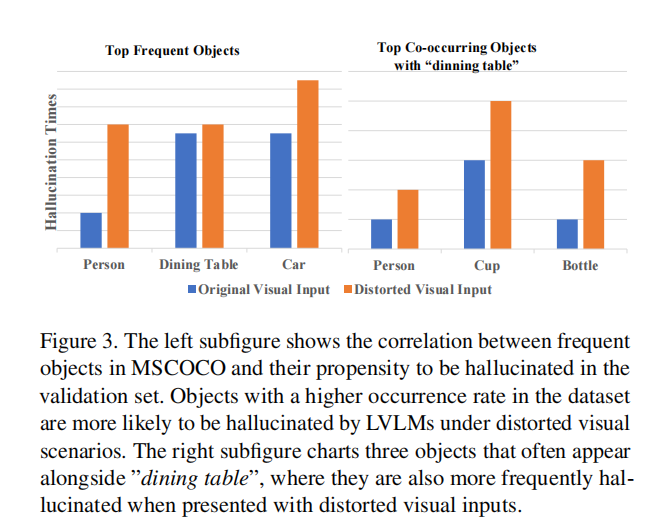
•大部分视觉-语言数据集以MSCOCO为基础构建,而该数据集本身存在不平衡的物体分布和有偏的物体相关性,使得图像模糊时,VLLM容易幻想出数据集中的高频物体或数据集中与原始图像物体频繁出现的相关物体。
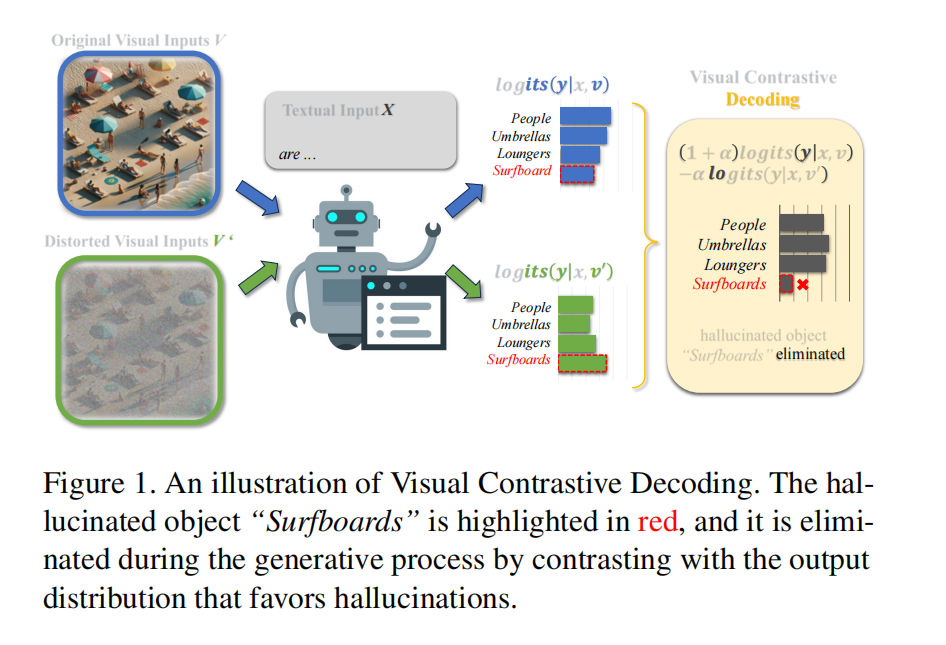
基于上述观察,作者提出了VCD(Visual Contrastive Decoding)方法:
•分别从“原始图像+文本输入”以及“扭曲图像+文本输入”得到两个输出分布。
•对比这两个分布的差别,并对那些只在“扭曲图像”条件下才被高估的候选词进行惩罚,降低模型过度依赖语言先验或统计偏差的错误倾向。
•通过对比后的分布进行采样或解码,得到更加贴合真实视觉信息的回答或描述。
实验结果表明,VCD可以减少对象层面、属性层面的幻觉,在增强了模型的视觉感知能力的同时,保留了模型的认知能力。
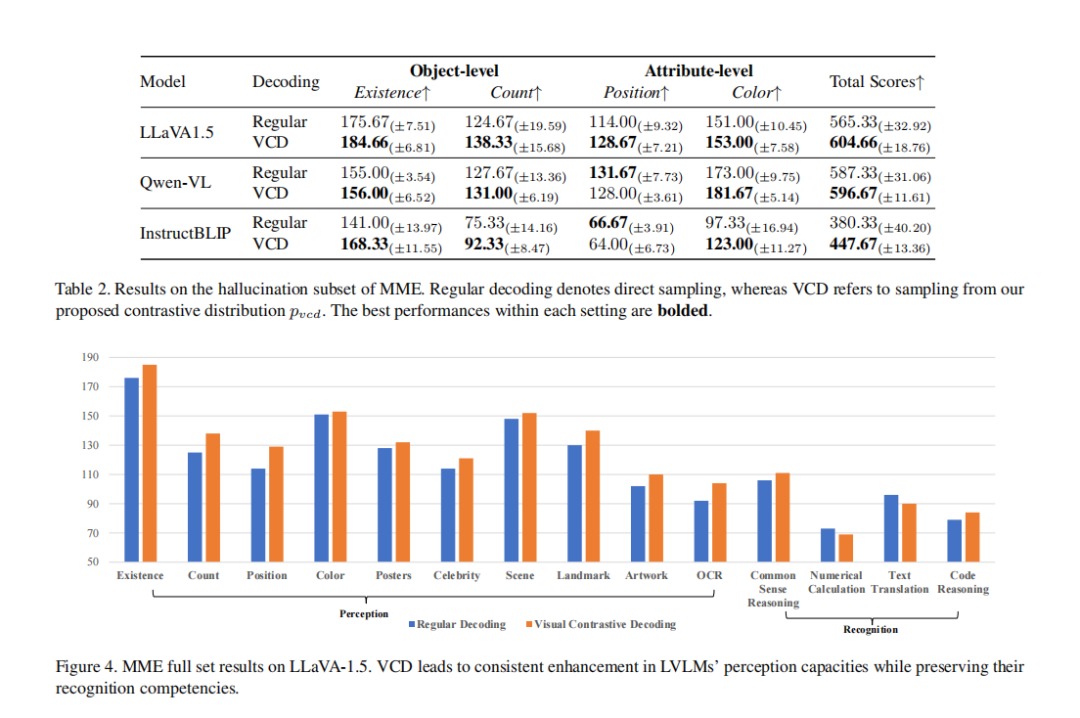
模型理解能力不足
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
该论文发现,尽管MLLM发展迅速,但仍会在一些基础且明显的视觉问题上犯错。作者提出了一个假设:问题主要在于视觉编码器本身。多数开源MLLM都使用类似CLIP的模型作为视觉编码器,虽然具有优秀的0-shot分类能力,但或许并不足以支持深入的视觉细节辨别。
若某两个图像在CLIP的特征空间中余弦相似度极高,但在传统的视觉自监督模型DINOv2的特征空间中余弦相似度很低,则说明这两个图像视觉上有明显差别,但CLIP对它们的区分能力不够。作者将这样的图像对称为CLIP-blind pair。
作者构建了一个新的Benchmark MMVP:在ImageNet、LAION-Aesthetics等数据集中,收集到大量的CLIP-blind pair,通过人工观察图像差异并设计简短的问题,对MLLM的视觉能力进行测试。模型需要分别对图像对中的两张图回答正确才得分,否则就被认为在视觉理解上存在盲点。

实验结果显示,人类在这些问题上的正确率在95%以上;但主流MLLM的准确率最多只有40%,有的甚至低于随机猜测。
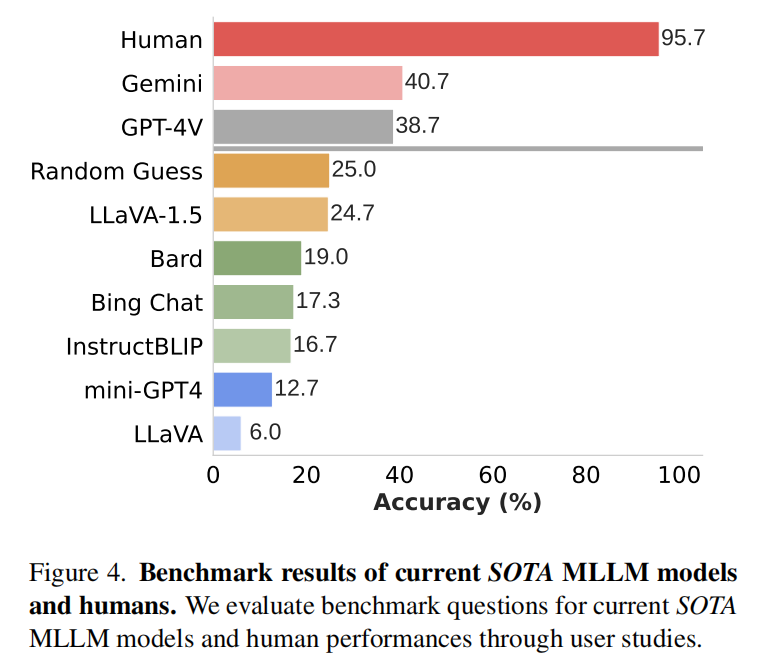
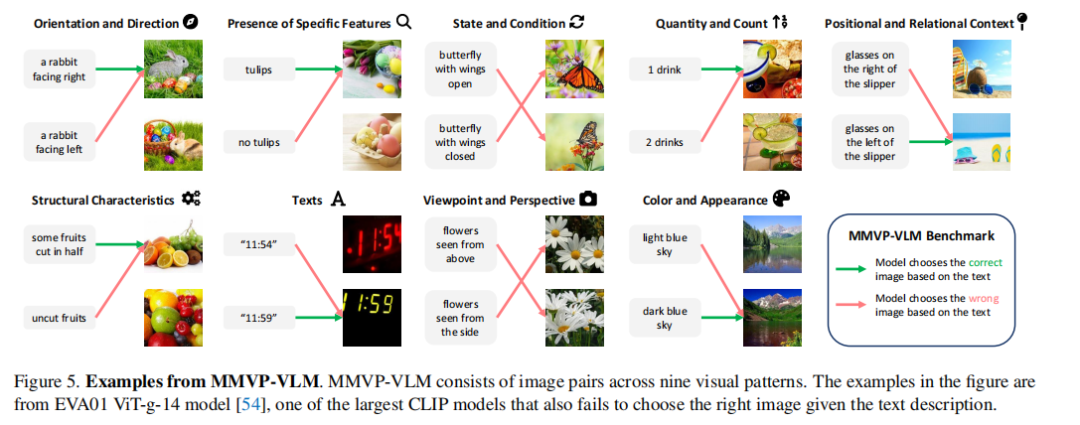
文章使用GPT-4将这些易错特征分成了9类:

为验证这些特征是否可以通过增加训练数据或模型参数来弥补,研究者使用测试集MMVP-VLM进行对照测试:从MMVP Benchmark中抽取部分问题,将其转换为简单文本描述,形成“图像-文本匹配”任务,用于评估模型对这类视觉差异的判别能力。
实验结果发现,随着模型规模增大,“color and appearance”和“state and condition”的识别确有一定程度改善,但面对多数类型的问题依旧难以区分图像之间的差别。
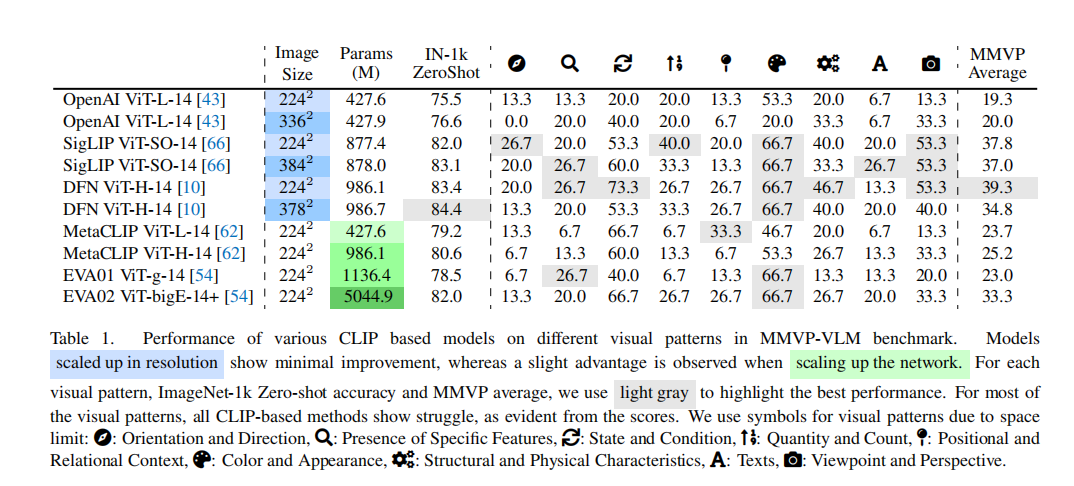
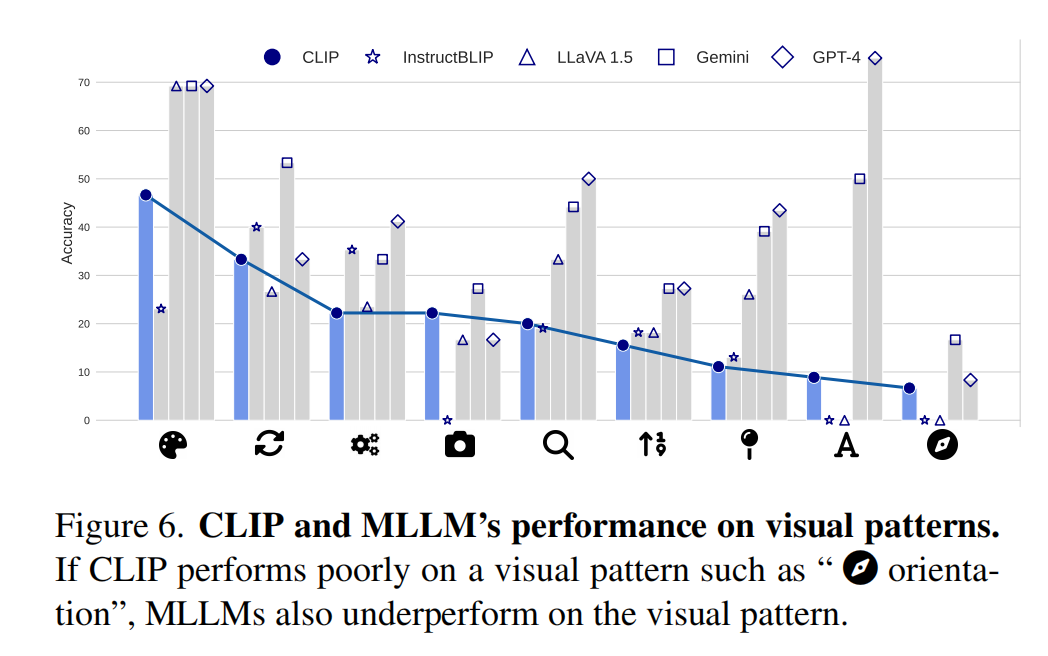
文章还观察到若CLIP在某类问题上难以区分,MLLM在处理相关视觉任务时往往也会出错。换言之,视觉编码器对图像的错误理解会“传递”给大语言模型。
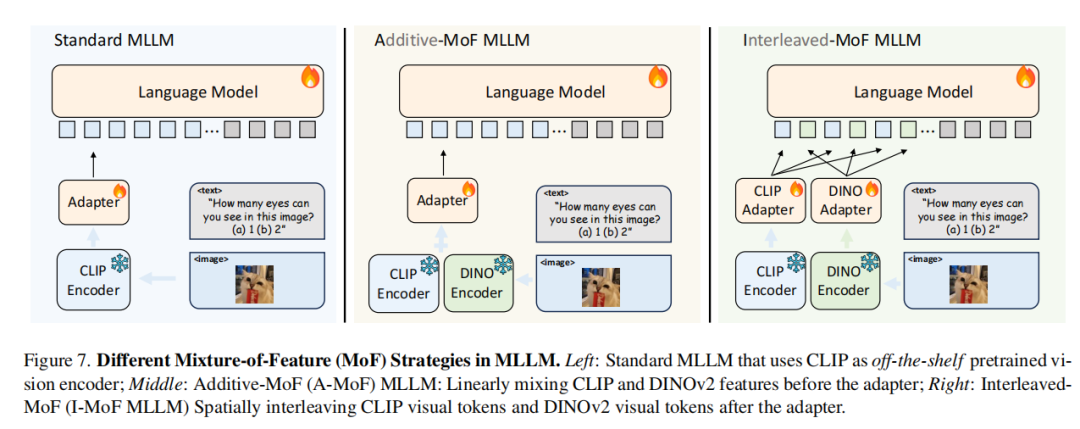
为了克服CLIP导致的视觉信息不充分的问题,作者提出了MoF方法,具体包括:
•Additive-MoF:将CLIP与DINOv2生成的feature加权平均后输入LLM。
•Interleaved-MoF:在保持其原始空间顺序的同时将CLIP和DINOv2的feature进行交错,再输入给LLM。
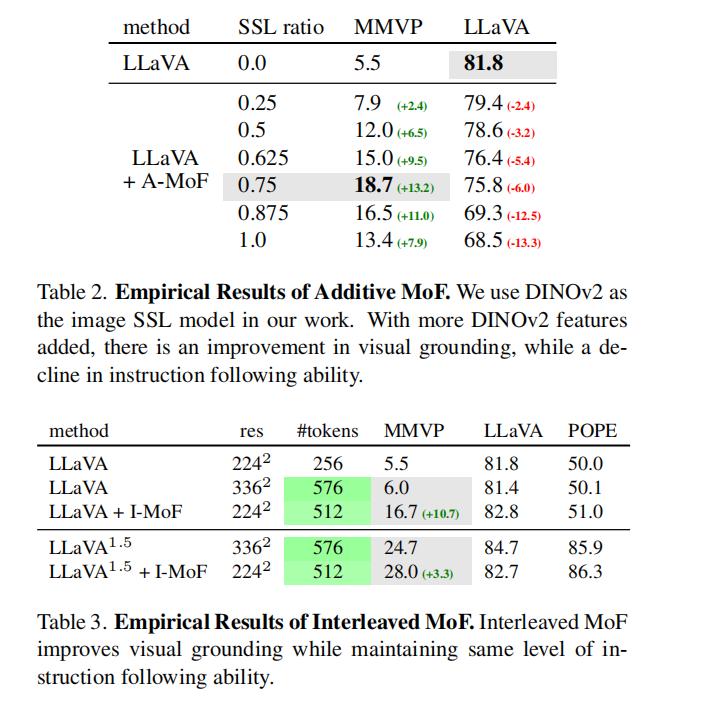
实验结果表明,Additive-MoF方法中随着DINOv2占比上升,模型在视觉推理上更准确,但指令遵循能力会下降。而Interleaved-MoF方法在视觉推理上的表现显著提升,同时仍能较好地保持大模型在通用指令或对话类任务上的能力。
-
讨论
通过前述文献的回顾可以发现,现有研究主要围绕两大方面展开:其一是语言模态的偏差,即当多模态模型只依据文本先验而忽略视觉证据时所产生的幻觉;其二是视觉理解能力,在视觉编码器本身难以区分图像细节时导致错误推断。虽然第一篇论文的研究结果显示,MLLM在一些情境下同样存在错误将视觉信息干扰项选为答案的情形(即视觉模态的偏差),但大部分现有工作仍然主要探讨了语言偏差对模型推理带来的影响,对视觉偏差的成因和系统性分析相对有限。
同时,在纯文本领域,研究者已经围绕LLM的语言理解能力进行了多方面的探讨,包括其对上下文、常识以及逻辑推理的把握等。对于多模态模型而言,将“语言理解不足”单独作为核心研究问题的文章还比较少见。
此外,与LLM类似,MLLM也容易因为专业性或时效性的知识缺失而出现幻觉。当图像或问题情境涉及未被模型训练语料覆盖的领域信息、或需实时更新的事件、时效性信息时,模型可能仅依据语言或视觉先验进行猜测。未来研究不仅需要聚焦如何平衡和纠正语言与视觉两种模态信息之间的偏差,还应考虑如何为MLLM接入更新机制或领域数据库,以进一步降低幻觉风险、提升其在实际应用场景中的可靠性和通用性。
参考文献
Chen, M., Cao, Y., Zhang, Y., & Lu, C. (2024). Quantifying and mitigating unimodal biases in multimodal large language models: A causal perspective. arXiv preprint arXiv:2403.18346.
Huang, Q., Dong, X., Zhang, P., Wang, B., He, C., Wang, J., ... & Yu, N. (2024). Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13418-13427).
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., & Bing, L. (2024). Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13872-13882).
Tong, S., Liu, Z., Zhai, Y., Ma, Y., LeCun, Y., & Xie, S. (2024). Eyes wide shut? exploring the visual shortcomings of multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9568-9578).


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
实验室开源产品图数据库gStore:
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

