




PostgreSQL PL/pgSQL 原理简析(2)
前情提要
上一篇文章我们主要介绍了用户创建、使用、删除一个 PL/pgSQL 语言的函数 (以下简称为函数)在 SQL 层中的流程,但没有详细说明从 SQL 执行器到 PL/pgSQL 引擎内的执行细节。本文我们就来探索一下 PL/pgSQL 函数体编译的一些细节(在下文中, PL/pgSQL块,函数体,块都指代同一个意思,即 DECLARE..BEGIN..END 这段内容)。
函数体编译
2.1 plpgsql_compile:查询缓存
上文提及到,函数体编译的时机在于函数验证或函数执行,此时通过不同的入口(plpgsql_validator plpgsql_call_handler)先获取函数的 oid,然后调用 plpgsql_compile 函数。plpgsql_compile 主要对缓存(也就是一个哈希表)进行操作,其哈希键的结构体如下:
typedef struct PLpgSQL_func_hashkey
{
Oid funcOid;
bool isTrigger; /* true if called as a DML trigger */
bool isEventTrigger; /* true if called as an event trigger */
/* be careful that pad bytes in this struct get zeroed! */
/*
* For a trigger function, the OID of the trigger is part of the hash key
* --- we want to compile the trigger function separately for each trigger
* it is used with, in case the rowtype or transition table names are
* different. Zero if not called as a DML trigger.
*/
Oid trigOid;
/*
* We must include the input collation as part of the hash key too,
* because we have to generate different plans (with different Param
* collations) for different collation settings.
*/
Oid inputCollation;
/*
* We include actual argument types in the hash key to support polymorphic
* PLpgSQL functions. Be careful that extra positions are zeroed!
*/
Oid argtypes[FUNC_MAX_ARGS];
} PLpgSQL_func_hashkey;复制
可以看到,由于 collation 和 argtypes 的存在,一个相同的函数在被指定了不同的字符集排序规则,或是存在 any 系列参数时,可能存在多个不同的 hashkey。
哈希值的结构体具体如下:
/*
* Complete compiled function
*/
typedefstruct PLpgSQL_function
{
char *fn_signature;
Oid fn_oid;
TransactionId fn_xmin;
ItemPointerData fn_tid;
PLpgSQL_trigtype fn_is_trigger;
Oid fn_input_collation;
PLpgSQL_func_hashkey *fn_hashkey; /* back-link to hashtable key */
MemoryContext fn_cxt;
Oid fn_rettype;
int fn_rettyplen;
bool fn_retbyval;
bool fn_retistuple;
bool fn_retisdomain;
bool fn_retset;
bool fn_readonly;
char fn_prokind;
int fn_nargs;
int fn_argvarnos[FUNC_MAX_ARGS];
int out_param_varno;
int found_varno;
int new_varno;
int old_varno;
PLpgSQL_resolve_option resolve_option;
bool print_strict_params;
/* extra checks */
int extra_warnings;
int extra_errors;
/* the datums representing the function's local variables */
int ndatums;
PLpgSQL_datum **datums;
Size copiable_size; /* space for locally instantiated datums */
/* function body parsetree */
PLpgSQL_stmt_block *action;
/* data derived while parsing body */
unsignedint nstatements; /* counter for assigning stmtids */
bool requires_procedure_resowner; /* contains CALL or DO? */
/* these fields change when the function is used */
struct PLpgSQL_execstate *cur_estate;
unsignedlong use_count;
} PLpgSQL_function;复制
里面包括了函数的许多元信息,例如函数的变量数组,入参数量,为入参构建的结构体在变量数组的位置,返回值类型等等。
plpgsql_compile 的主要工作流程如下:
pg 在 fmgr 的结构体中预留了一个指针 fn_extra,如果遇到在一条 SQL 中会多次执行同一个函数的情况(例如一个where语句的表达式中含有可变的函数,或是触发器频繁触发某一函数),直接使用暂存在该指针的函数编译信息即可,无需查询缓存。如果有结果,结束;
计算 hashkey,查询缓存;
如果查询到结果,还需要对比该缓存是否有效,判定依据就是该函数是否被 replace 过,如果被 replace 过,heaptuple 上的元信息(例如 xmin )就会不同;如果已经失效,则需要删除旧的缓存;如果有效,结束;
实际执行函数的编译流程,具体逻辑在 do_compile;
2.2 do_compile:编译函数体
在具体编译函数体之前,我们还需要做最后一件重要的事情:编译一些预设的变量。对于函数来说,这些预设变量就是函数的入参,包括 1 这样的位置表示法,以及可能存在的名称表示法。对于触发器函数来说,可能就需要 new、old、tg_name 等预设变量。这些变量会被逐个放在变量数组中,在内存形式上与存储过程内声明的各种局部变量并无差别。这件事完成后,才开始调用 plpgsql_yyparse 真正编译从 pg_proc 取出的 prosrc 字符串,即函数体。
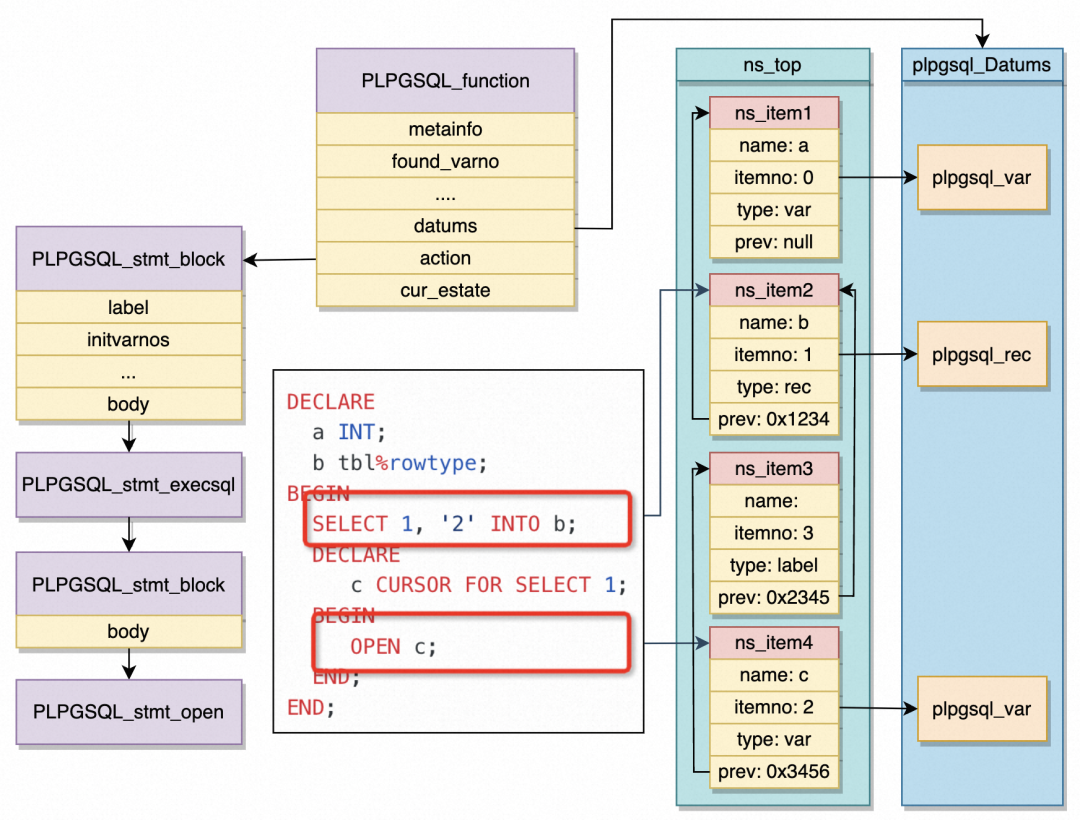
上图给出了一个存储过程的例子,以及相关联的多个结构体。可以看出,不带异常处理的存储过程块一般分为两段,我们可以简单的称它们是 DECLARE 段和 BEGIN 段。DECLARE 段主要完成变量的声明和初始化,BEGIN 段用于写各种具体的控制逻辑和 SQL 语句。可以看到, BEGIN 段中是可以继续嵌套存储过程块的,这就类似于 c 语言中用 {} 包裹的代码块。在 DECLARE 段中声明的变量会被继续插入变量数组中。如图所示,该图展示了一个不带入参的函数编译情况。这里有两个重要的东西需要介绍:ns_top 指针和 plpgsql_Datums 数组。前者起到索引、检查变量重名和限制语句可见域的作用,后者则是具体存储变量结构体的数组,就是上文提到的变量数组。当 plpgsql 引擎的 scanner 和 parser 解析出 a int;
是一个变量声明语句时,他会为 int 字符串调用 parse_datatype 创建出 PLpgSQL_type 结构体来表示变量的类型,结构体内容如下:
typedef struct PLpgSQL_type
{
char *typname; /* (simple) name of the type */
Oid typoid; /* OID of the data type */
PLpgSQL_type_type ttype; /* PLPGSQL_TTYPE_ code */
int16 typlen; /* stuff copied from its pg_type entry */
bool typbyval;
char typtype;
Oid collation; /* from pg_type, but can be overridden */
bool typisarray; /* is "true" array, or domain over one */
int32 atttypmod; /* typmod (taken from someplace else) */
/* Remaining fields are used only for named composite types (not RECORD) */
TypeName *origtypname; /* type name as written by user */
TypeCacheEntry *tcache; /* typcache entry for composite type */
uint64 tupdesc_id; /* last-seen tupdesc identifier */
} PLpgSQL_type;复制
普通变量和游标会被 PL/pgSQL 创建出 PLpgSQL_var 来指代,结构体内容如下:
typedef struct PLpgSQL_var
{
PLpgSQL_datum_type dtype;
int dno;
char *refname;
int lineno;
bool isconst;
bool notnull;
PLpgSQL_expr *default_val;
/* end of PLpgSQL_variable fields */
PLpgSQL_type *datatype;
/*
* Variables declared as CURSOR FOR <query> are mostly like ordinary
* scalar variables of type refcursor, but they have these additional
* properties:
*/
PLpgSQL_expr *cursor_explicit_expr;
int cursor_explicit_argrow;
int cursor_options;
/* Fields below here can change at runtime */
Datum value;
bool isnull;
bool freeval;
/*
* The promise field records which "promised" value to assign if the
* promise must be honored. If it's a normal variable, or the promise has
* been fulfilled, this is PLPGSQL_PROMISE_NONE.
*/
PLpgSQL_promise_type promise;
} PLpgSQL_var;复制
此外,还有指代行变量的 PLpgSQL_rec,以及包装游标参数列表,into targets 的 PLpgSQL_row 等其他存储不同形式变量的结构体,他们都有统一的基类:PLpgSQL_datum,以这种形式存在 plpgsql_Datums 中。从 plpgsql_Datums 中读取变量信息也只需要判断PLpgSQL_datum_type 的类型,转换成不同的结构体来进一步处理即可。为变量 a 创建出 PLpgSQL_var 结构体后,还会创建一个 ns_item 结构体。从图中可以看出,这是一个通过 prev 指针相连的链表,ns_top 始终指向链表的末端。当开始解析select 1, '2' into b;
时,plpgsql 会认为这是一个表达式,通过 PLpgSQL_expr 来存储相关的信息,并记录好当前的 ns_top 的位点。在之后具体解析表达式时,如果发现表达式内有变量存在(这个例子里就是b),就会顺着这个位点不断向前查找,通过 name 字段字符串匹配变量名,并通过 itemno 找到真正指代变量的结构体。显然,这条语句能识别 b 和 a, 但它看不见在它之后声明的游标 c。我们注意到 ns_item 里还有一个 type 字段,除了提前记录变量类型,它还可能是一个 嵌套块的 label 的名字。对于语句来说,如果在当前块匹配不到变量名,它可以继续去外层块查找,但如果我们想在变量 b 后面再次声明一个其他类型的变量 b,PL/pgSQL 将会顺着 ns_top 查找到第一个 type 为 label 的位点就停下 (想想 C 语言的 {} 里的变量声明和语句的可见域)。
至此,变量声明部分的大致框架我们已经有一个较为清晰的概念了,通过 flex/bison 的规则匹配,当 PL/pgSQL 认为是一条创建变量的语句且处于 DECLARE 段时,它会为该变量创建对应的变量结构体,并创建一个 ns_item 的索引节点。该变量结构体上会记录着变量名,变量值,是否非空,变量类型,默认值等等与变量相关的信息。
当 scanner 读到 BEGIN 关键字时,PL/pgSQL 将状态从 IDENTIFIER_LOOKUP_DECLARE 切换为 IDENTIFIER_LOOKUP_NORMAL,这意味着要读取各种语句了。PL/pgSQL 将实现的每个控制语句都和某个 PLpgSQL_stmt_xxx,它们都以PLpgSQL_stmt 作为基类,通过 PLpgSQL_stmt_type 来做转换。在这里我们罗列了所有相关的结构体:
PLpgSQL_stmt_block
PLpgSQL_stmt_assign
PLpgSQL_stmt_perform
PLpgSQL_stmt_call
PLpgSQL_stmt_commit
PLpgSQL_stmt_rollback
PLpgSQL_stmt_getdiag
PLpgSQL_stmt_if
PLpgSQL_if_elsif
PLpgSQL_stmt_case
PLpgSQL_stmt_loop
PLpgSQL_stmt_while
PLpgSQL_stmt_fori
PLpgSQL_stmt_forq
PLpgSQL_stmt_fors
PLpgSQL_stmt_forc
PLpgSQL_stmt_dynfors
PLpgSQL_stmt_foreach_a
PLpgSQL_stmt_open
PLpgSQL_stmt_fetch
PLpgSQL_stmt_close
PLpgSQL_stmt_exit
PLpgSQL_stmt_return
PLpgSQL_stmt_return_next
PLpgSQL_stmt_return_query
PLpgSQL_stmt_raise
PLpgSQL_stmt_assert
PLpgSQL_stmt_execsql
PLpgSQL_stmt_dynexecute复制
我们基本可以望文生义猜测出它们的用途。每一个存储过程块都对应了一个 PLpgSQL_stmt_block,它有一个 body 字段是一个 List,挂载了这个块里所有的语句(当然也可能是另一个 PLpgSQL_stmt_block,这样就形成了嵌套)。图中也显示了这样的结构。因此,实际执行时,只需要对顶层的 PLpgSQL_stmt_block 进行处理,通过对 PLpgSQL_stmt_type 的判断路由到不同的 exec_stmt_xxx 处理函数即可。
最后,将创建好的变量信息和语句信息保存在函数编译信息的结构体 PLpgSQL_function 中,往哈希表中插入该函数编译信息做好缓存,就完成了函数编译的流程。
总结
本章节介绍了存储过程编译的主要流程,说明了变量信息和语句信息在内存里存在的形式。
