




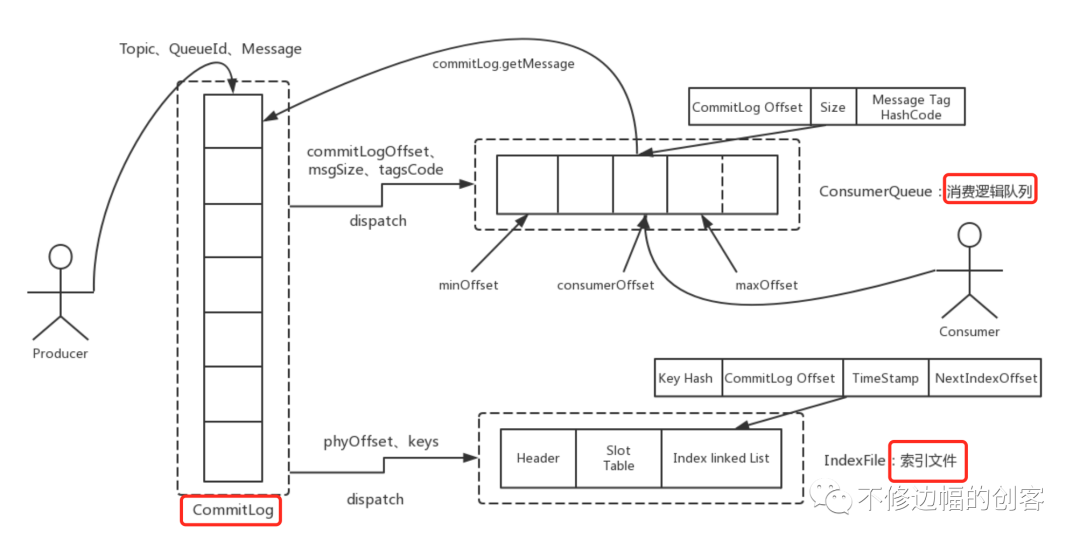
RocketMQ中针对消息的存储,有三个很重要的文件,1、原始消息文件,主要通过CommitLog对消息的存储进行抽象封装;2、消息索引文件,主要通过IndexService实现对索引文件的存储;3、消费逻辑队列文件,主要是通过ConsumeQueue记录消息在CommitLog中的位置。
1
消息文件的存储 复制
1.fileFromOffset 每个文件的大小是1G = 1024 * 1024 * 1024,每个文件的命名都是在队列MapedFileQueue中的偏移量,比如: 第一个文件名为:00000000000000000000, 那么第二个文件名就为:00000000001073741824, 那么第三个文件名就为:00000000002147483648。 ... 剩下的以此类推。 2.appendMessage(Object msg,AppendMessageCallback cb) 该方法通过回调AppendMessageCallback实现数据存储。
3.selectMapedBuffer(int pos, int size) 返回从pos到size的内存映射,用于读取数据。3
MapedFileQueue类代表了MapedFile组成的队列(由大小相同的多个文件构成),重要方法解释:
1.getLastMapedFile 获取队列最后一个MapedFile对象,以下两种情况会创建新的MapedFile对象:a、最后一个不存在 b、文件写满了
2.findMapedFileByOffset(final long offset)
根据offset/filesize计算该offset所在那个文件中。
介绍完上面两个关键类,我们在看消息的存储。消息到达broker主要通过SendMessageProcessor.processRequest(ctx,request)进行处理,通过代码追踪很快定位到CommitLog.putMessage(msg)方法,该方法里对消息进行落盘处理,这里我们主要看两行代码,代码如下:
复制
//获取到队列中最新MapedFile文件
MapedFile mapedFile = this.mapedFileQueue.getLastMapedFile();
if (null == mapedFile) {
log.error("create maped file1 error, topic: " + msg.getTopic() + " clientAddr: "
+ msg.getBornHostString());
return new PutMessageResult(PutMessageStatus.CREATE_MAPEDFILE_FAILED, null);
}
//在当前MapedFile中追加消息到文件尾部
result = mapedFile.appendMessage(msg, this.appendMessageCallback);复制
public AppendMessageResult appendMessage(final Object msg, final AppendMessageCallback cb) {
assert msg != null;
assert cb != null;
int currentPos = this.wrotePostion.get();
// 表示有空余空间
if (currentPos < this.fileSize) {
//类似于浅拷贝,byteBuffer与this.mappedByteBuffer共享子序列
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
//在该byteBuffset上设置新的position
byteBuffer.position(currentPos);
//传入当前MapedFile文件的起始offset、byteBuffer、剩余空间和消息
AppendMessageResult result =
cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos, msg);
this.wrotePostion.addAndGet(result.getWroteBytes());
this.storeTimestamp = result.getStoreTimestamp();
return result;
}
// 上层应用应该保证不会走到这里
log.error("MapedFile.appendMessage return null, wrotePostion: " + currentPos + " fileSize: "
+ this.fileSize);
return new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR);
}复制
/**
* 1s执行一次,把内存未落盘的数据落盘
*/
class FlushRealTimeService extends FlushCommitLogService {
public void run() {
...
try {
//间隔1s
if (flushCommitLogTimed) {
Thread.sleep(interval);
}
else {
this.waitForRunning(interval);
}
if (printFlushProgress) {
this.printFlushProgress();
}
//调用MapedFileQueue.commit()对消息进行落盘,flushPhysicQueueLeastPages = 4 ;
//注意:并不是每次都刷盘,内存中的消息堆积到:对消息进行落盘,flushPhysicQueueLeastPages * 一页大小(4K)才会刷盘,考虑到磁盘IO的影响
CommitLog.this.mapedFileQueue.commit(flushPhysicQueueLeastPages);
long storeTimestamp = CommitLog.this.mapedFileQueue.getStoreTimestamp();
if (storeTimestamp > 0) {
CommitLog.this.defaultMessageStore.getStoreCheckpoint().setPhysicMsgTimestamp(
storeTimestamp);
}
}
catch (Exception e) {
CommitLog.log.warn(this.getServiceName() + " service has exception. ", e);
this.printFlushProgress();
}
...
}
}复制
/**
* 消息刷盘
*
* @param flushLeastPages
* 至少刷几个page
* @return
*/
public int commit(final int flushLeastPages) {
//未刷盘的数据必须有 > 4 * 4K(一页是4K,现在是4页)
if (this.isAbleToFlush(flushLeastPages)) {
if (this.hold()) {
int value = this.wrotePostion.get();
//强制刷一次盘
//不要经常调用MappedByteBuffer.force()方法,这个方法强制操作系统将内存中的内容写入硬盘,所以如果你在每次写内存映射文件后都调用force()方法,你就不能真正从内存映射文件中获益,而是跟disk IO差不多。
this.mappedByteBuffer.force();
this.committedPosition.set(value);
this.release();
}
else {
log.warn("in commit, hold failed, commit offset = " + this.committedPosition.get());
this.committedPosition.set(this.wrotePostion.get());
}
}
return this.getCommittedPosition();
}复制
read()是系统调用,首先将文件从硬盘拷贝到内核空间的一个缓冲区,再将这些数据拷贝到用户空间,实际上进行了两次数据拷贝;
map()也是系统调用,但没有进行数据拷贝,当缺页中断发生时,直接将文件从硬盘拷贝到用户空间,只进行了一次数据拷贝。
MappedByteBuffer使用虚拟内存,因此分配(map)的内存大小不受JVM的-Xmx参数限制,但是也是有大小限制的。如果当文件超出1.5G限制时(当前为1G,处理起来更简单),可以通过position参数重新map文件后面的内容。MappedByteBuffer在处理大文件时的确性能很高,但也存在一些问题,如内存占用、文件关闭不确定,被其打开的文件只有在垃圾回收的才会被关闭,而且这个时间点是不确定的。
2
消费队列文件存储 复制
offset(long 8字节)+size(int 4字节)+tagsCode(long 8字节)
消费队列文件名规则:消息数(30W)*消息位置固定大小(20字节)=6000000字节,故每6000000字节一个文件,文件名依次递增,前缀不够20位补0,类似如下:
00000000000000000000
00000000000006000000
00000000000012000000
…
剩下的以此类推,如下图为实际情况,可以看到每个文件大小:6000000字节,文件名相差:6000000字节。

ConsumeQueue中有一些重要的属性和方法,提前做一个介绍。
1.属性 mapedFileQueue 存储消息消费消息的文件,由于一个文件只存30W条消息,所以如果需要一个队列来管理这些文件。
2.方法:putMessagePostionInfo(long offset, int size, long tagsCode,long cqOffset) 其中:offset:消息在commitLog中的起始位置;size:消息长度;cqOffset:该消息在topic对应的queue中的下标,参照Commitlog.topicQueueTable。
该方法主要实现了消息位置的存储,并产生消息文件:{storePathRootDir}/consumequeue/{topic}/${queueId}/消息位置队列文件 3.方法:getIndexBuffer(long startIndex) startIndex代表了起始偏移量索引。 该方法会根据startIndex查找到相应的索引文件,并返回该文件当前写到的位置到startIndex的消息分区。 startIndex为客户端目前消费的进度,实际为消息位置队列文件的消费偏移量索引。
CommitLog.putMessage在存储消息成功之后,需要把当前消息的commitOffset及消息其它信息封装成DispatchRequest进行分发,一方面由ConsumeQueue构建消费队列文件,另一方面还需要由IndexService构建消息的索引文件。
DispatchRequest dispatchRequest = new DispatchRequest(//
topic,// 1
queueId,// 2
result.getWroteOffset(),// 3
result.getWroteBytes(),// 4
tagsCode,// 5
msg.getStoreTimestamp(),// 6
result.getLogicsOffset(),// 7
msg.getKeys(),// 8
/**
* Transaction
*/
msg.getSysFlag(),// 9
msg.getPreparedTransactionOffset());// 10
this.defaultMessageStore.putDispatchRequest(dispatchRequest);复制
DispatchMessageService主要负责消息的分发,这里主要看其doDispatch方法。
public void putDispatchRequest(final DispatchRequest dispatchRequest) {
this.dispatchMessageService.putRequest(dispatchRequest);
}复制
private void doDispatch() {
if (!this.requestsRead.isEmpty()) {
for (DispatchRequest req : this.requestsRead) {
final int tranType = MessageSysFlag.getTransactionValue(req.getSysFlag());
// 1、分发消息位置信息到ConsumeQueue
switch (tranType) {
case MessageSysFlag.TransactionNotType:
case MessageSysFlag.TransactionCommitType:
// 将请求发到具体的Consume Queue
DefaultMessageStore.this.putMessagePostionInfo(req.getTopic(), req.getQueueId(),
req.getCommitLogOffset(), req.getMsgSize(), req.getTagsCode(),
req.getStoreTimestamp(), req.getConsumeQueueOffset());
break;
case MessageSysFlag.TransactionPreparedType:
case MessageSysFlag.TransactionRollbackType:
break;
}
}
//2、构建索引文件
if (DefaultMessageStore.this.getMessageStoreConfig().isMessageIndexEnable()) {
DefaultMessageStore.this.indexService.putRequest(this.requestsRead.toArray());
}
this.requestsRead.clear();
}
}复制
下一章节,我们着重讲索引文件的存储,这一节我们先看ConsumeQueue消费队列的储存。DefaultMessageStore.putMessagePostionInfo()方法。代码如下:
public void putMessagePostionInfo(String topic, int queueId, long offset, int size, long tagsCode,
long storeTimestamp, long logicOffset) {
//根据topic和queueId获取对应的consumeQueue对象
ConsumeQueue cq = this.findConsumeQueue(topic, queueId);
//追加消息到当前队列
cq.putMessagePostionInfoWrapper(offset, size, tagsCode, storeTimestamp, logicOffset);
}复制
一个ConsumeQueue中可能会有多个文件,因为上面提到一个文件最多放30W条消息,如果大于30W需要创建新MapedFile文件,这也就解释了,为什么ConsumeQueue中有mapedFileQueue属性。ConsumeQueue的putMessagePostionInfoWrapper方法负责存储当前消息,其内部调用了putMessagePostionInfo方法进行处理。
/**
* 存储一个20字节的信息,putMessagePostionInfo只有一个线程调用,所以不需要加锁
*
* @param offset
* 消息对应的CommitLog offset
* @param size
* 消息在CommitLog存储的大小
* @param tagsCode
* tags 计算出来的长整数
* @return 是否成功
*/
private boolean putMessagePostionInfo(final long offset, final int size, final long tagsCode,
final long cqOffset) {
// 在数据恢复时会走到这个流程
if (offset <= this.maxPhysicOffset) {
return true;
}
this.byteBufferIndex.flip();
this.byteBufferIndex.limit(CQStoreUnitSize);
this.byteBufferIndex.putLong(offset);
this.byteBufferIndex.putInt(size);
this.byteBufferIndex.putLong(tagsCode);
final long expectLogicOffset = cqOffset * CQStoreUnitSize;
//1、获取最新的MapedFile
MapedFile mapedFile = this.mapedFileQueue.getLastMapedFile(expectLogicOffset);
if (mapedFile != null) {
// 纠正MapedFile逻辑队列索引顺序
if (mapedFile.isFirstCreateInQueue() && cqOffset != 0 && mapedFile.getWrotePostion() == 0) {
this.minLogicOffset = expectLogicOffset;
this.fillPreBlank(mapedFile, expectLogicOffset);
log.info("fill pre blank space " + mapedFile.getFileName() + " " + expectLogicOffset + " "
+ mapedFile.getWrotePostion());
}
if (cqOffset != 0) {
long currentLogicOffset = mapedFile.getWrotePostion() + mapedFile.getFileFromOffset();
if (expectLogicOffset != currentLogicOffset) {
// XXX: warn and notify me
logError
.warn(
"[BUG]logic queue order maybe wrong, expectLogicOffset: {} currentLogicOffset: {} Topic: {} QID: {} Diff: {}",//
expectLogicOffset, //
currentLogicOffset,//
this.topic,//
this.queueId,//
expectLogicOffset - currentLogicOffset//
);
}
}
// 记录物理队列最大offset
this.maxPhysicOffset = offset;
//2、追加消息到消费队列文件
return mapedFile.appendMessage(this.byteBufferIndex.array());
}
return false;
}复制
因为MapedFile被抽象出来了,所以实现跟CommitLog文件相似,这里不在细说,当append消息之后,消息在内存中,并没有落盘,ConsumeQueue的落盘,需要看:FlushConsumeQueueService.doFlush()方法。FlushConsumeQueueService的run由单线程每隔一秒执行一次,专门做消息的刷盘。doFlush()方法会对所有的ConsumeQueue进行刷盘(因为一个broker上的topic可能有多个queueId)。
ConcurrentHashMap<String, ConcurrentHashMap<Integer, ConsumeQueue>> tables =
DefaultMessageStore.this.consumeQueueTable;
for (ConcurrentHashMap<Integer, ConsumeQueue> maps : tables.values()) {
for (ConsumeQueue cq : maps.values()) {
boolean result = false;
for (int i = 0; i < retryTimes && !result; i++) {
result = cq.commit(flushConsumeQueueLeastPages);
}
}
}复制
通过代码发现执行的还是CosumeQueue.commit()方法,其内部丢给MapedFileQueue.commit()方法,下面的逻辑就跟CommitLog一致了,也是调用mappedByteBuffer.force(),把内存中的消息刷到磁盘中。
public boolean commit(final int flushLeastPages) {
return this.mapedFileQueue.commit(flushLeastPages);
}复制
3
索引文件存储 复制
try {
String fileName =
this.storePath + File.separator
+ UtilAll.timeMillisToHumanString(System.currentTimeMillis());
indexFile =
new IndexFile(fileName, this.hashSlotNum, this.indexNum, lastUpdateEndPhyOffset,
lastUpdateIndexTimestamp);
this.readWriteLock.writeLock().lock();
this.indexFileList.add(indexFile);
}复制
/**
* 向队列中添加请求,队列满情况下,丢弃请求
*/
public void putRequest(final Object[] reqs) {
boolean offer = this.requestQueue.offer(reqs);
if (!offer) {
if (log.isDebugEnabled()) {
log.debug("putRequest index failed, {}", reqs);
}
}
}复制
@Override
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStoped()) {
try {
Object[] req = this.requestQueue.poll(3000, TimeUnit.MILLISECONDS);
if (req != null) {
//对当前的请求构建索引
this.buildIndex(req);
}
}
catch (Exception e) {
log.warn(this.getServiceName() + " service has exception. ", e);
}
}
log.info(this.getServiceName() + " service end");
}复制
//尝试获取IndexFile
IndexFile indexFile = retryGetAndCreateIndexFile();
...
//循环每条消息的keys,用这些keys为当前消息构建索引
if (keys != null && keys.length() > 0) {
String[] keyset = keys.split(MessageConst.KEY_SEPARATOR);
for (String key : keyset) {
// TODO 是否需要TRIM
if (key.length() > 0) {
//直到putKey执行成功结束
for (boolean ok =
indexFile.putKey(buildKey(topic, key), msg.getCommitLogOffset(),
msg.getStoreTimestamp()); !ok;) {
log.warn("index file full, so create another one, " + indexFile.getFileName());
indexFile = retryGetAndCreateIndexFile();
if (null == indexFile) {
breakdown = true;
break MSG_WHILE;
}
ok =
indexFile.putKey(buildKey(topic, key), msg.getCommitLogOffset(),
msg.getStoreTimestamp());
}
}
}
}复制
//上一次写入的位置
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * HASH_SLOT_SIZE
+ this.indexHeader.getIndexCount() * INDEX_SIZE;
// 写入真正索引
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
// 更新哈希槽
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
// 第一次写入
if (this.indexHeader.getIndexCount() <= 1) {
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
this.indexHeader.incHashSlotCount();
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);复制
// 每创建一个新文件,之前文件要刷盘
if (indexFile != null) {
final IndexFile flushThisFile = prevIndexFile;
Thread flushThread = new Thread(new Runnable() {
@Override
public void run() {
IndexService.this.flush(flushThisFile);
}
}, "FlushIndexFileThread");
flushThread.setDaemon(true);
flushThread.start();
}复制
