




1.只有SQL,AI优化能力怎么样?
上周开发同事发给我一个sql,说这个sql需要调优一下,看着执行计划还好,但是执行时间超过15秒
具体sql如下:
SELECT COUNT(*) AS COUNT
FROM (
SELECT DATA_4_VALUE || '/' || DATA_1_VALUE AS AA,
KEY_1_VALUE,
DATA_1_VALUE AS INSTANCE_ID,
DATA_4_VALUE AS DEFECT_IPQC_CATEGORY
FROM REFERENCE_FILE_DETAIL R
JOIN NAMED_OBJECT N ON R.REFERENCE_FILE_RRN = N.INSTANCE_RRN
LEFT JOIN (
SELECT REASON_DETAIL, COUNT(1) AS RANK_NUM
FROM CELL_INFO_HISTORY
WHERE CREATE_DATE >= ADD_MONTHS(SYSDATE, -1)
GROUP BY REASON_DETAIL
) T ON R.DATA_1_VALUE = T.REASON_DETAIL
WHERE N.OBJECT = 'REFERENCEFILE'
AND N.INSTANCE_ID = '$DEFECT_IPQC'
AND N.NAMED_SPACE = 'MYCIM2'
ORDER BY T.RANK_NUM DESC NULLS LAST, DATA_4_VALUE, KEY_1_VALUE
);
单纯看sql的执行计划,感觉相对还好
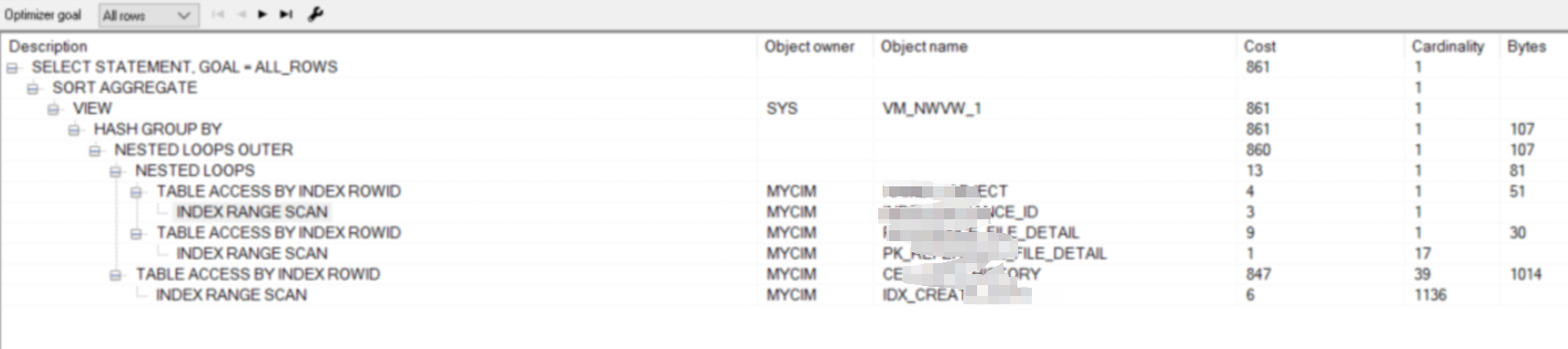
那么我们试试AI的sql优化能力怎么样?首先我先试试将sql直接丢给deepseek,如下是deepseek给出的优化建议
优化点:
-
减少嵌套子查询:将最内层的子查询合并到主查询中,减少嵌套层级。
-
避免不必要的计算:
NVL(T.RANK_NUM, 0)可以在外层处理,减少内层计算。 -
索引优化:确保
REFERENCE_FILE_DETAIL.REFERENCE_FILE_RRN、NAMED_OBJECT.INSTANCE_RRN、CELL_INFO_HISTORY.REASON_DETAIL和CELL_INFO_HISTORY.CREATE_DATE上有索引。 -
过滤条件提前:将
NAMED_SPACE = 'MYCIM2'提前到WHERE子句中,减少连接的数据量。 -
去除不必要的字段:在最终查询中只选择需要的字段,减少数据传输量。
进一步优化建议:
-
如果
CELL_INFO_HISTORY表数据量较大,可以考虑对CREATE_DATE和REASON_DETAIL创建复合索引。 -
如果
NAMED_OBJECT表的OBJECT和INSTANCE_ID字段选择性较高,可以为其创建复合索引。
因为没有将执行计划,统计信息等信息给AI,AI仅仅根据sql给出的优化建议 更像是CRO,基于规则来给出的优化建议;优化建议也是基于通用的sql编码最佳实践来进行给建议,但是对于一般的优化也是有一定的参考意义的。
2.给AI更详细的执行信息
那么我把更为详细的信息丢给AI,来试试AI的优化能力怎么样呢?
如下我把这个sql的sqlmonitor信息全部丢给AI来试试,他的优化能力会不会更好?
根据sqlid抓取sqlmonitor信息
SELECT DBMS_SQLTUNE.report_sql_monitor(sql_id => '&sql_id', type => 'TEXT') AS report FROM dual;
sql monitor中有详细的执行计划,执行时间,IO信息,等待信息等等,这些信息足够AI对这个sql做出判断


如下是ChatGpt给出的优化建议
SQL 性能分析与优化方案
✅ 1. SQL 主要问题分析
从 SQL Monitoring Report 可以看出以下几个 性能瓶颈:
1️⃣ 查询执行时间较长(17 秒)
-
主要消耗在
CELL_INFO_HISTORY表的查询上(Id = 10, 11)。 -
INDEX RANGE SCAN (IDX_CREATE_DATE)处理 20M 行数据,可能索引未优化。
-
NESTED LOOPS OUTER连接方式可能导致 大量随机 I/O。
2️⃣ Buffer Gets 非常高(14M)
- 说明 SQL 扫描的数据量过大,可能是缺乏合适的索引或不合理的嵌套查询。
3️⃣ 高 CPU 消耗(75% 计算集中在 CELL_INFO_HISTORY 上)
-
GROUP BY 和嵌套查询的 Hash Group By 可能占用大量 CPU 计算
。
-
可能缺乏适当的索引
,导致大量表扫描。
✅ 2. SQL 优化方案
📌 方案 1:优化索引
🔹 在 CELL_INFO_HISTORY 表上创建复合索引
CREATE INDEX IDX_CELL_INFO_HISTORY ON CELL_INFO_HISTORY (REASON_DETAIL, REASON_CODE, CREATE_DATE);
📌 作用:
- 减少
IDX_CREATE_DATE过大的索引范围扫描 - 让查询的
GROUP BY更快执行
🔹 优化 NAMED_OBJECT 查询索引
CREATE INDEX IDX_NAMED_OBJECT_INSTANCE ON NAMED_OBJECT (INSTANCE_ID, OBJECT);
📌 作用:
- 让
NAMED_OBJECT过滤OBJECT='REFERENCEFILE'更高效。
📌 方案 2:优化 CELL_INFO_HISTORY 子查询
问题:
SELECT REASON_DETAIL, REASON_CODE,
COUNT (1) RANK_NUM FROM CELL_INFO_HISTORY
WHERE CREATE_DATE BETWEEN ADD_MONTHS(SYSDATE, -1)
AND SYSDATE GROUP BY REASON_DETAIL, REASON_CODE
这个查询 扫描了 20M 行数据,优化方法如下:
优化方案
💡 使用 MATERIALIZED VIEW 提前计算
CREATE MATERIALIZED VIEW MV_CELL_INFO_HISTORY BUILD IMMEDIATE
🔹 优势:
- 让
T.RANK_NUM直接从MV_CELL_INFO_HISTORY读取,减少 20M 行扫描。
📌 方案 3:重写 SQL 语句
优化后的 SQL:
-
SELECT COUNT(*) AS COUNT FROM ( SELECT AA, KEY_1_VALUE, INSTANCE_ID, DEFECT_IPQC_CATEGORY FROM ( SELECT NVL(T.RANK_NUM, 0) NUM, DATA_4_VALUE ||'/'|| DATA_1_VALUE AA, KEY_1_VALUE, DATA_1_VALUE INSTANCE_ID, DATA_4_VALUE DEFECT_IPQC_CATEGORY, N.NAMED_SPACE FROM REFERENCE_FILE_DETAIL R LEFTJOIN NAMED_OBJECT N ON R.REFERENCE_FILE_RRN = N.INSTANCE_RRN AND N.OBJECT ='REFERENCEFILE' LEFTJOIN MV_CELL_INFO_HISTORY T ON R.DATA_1_VALUE = T.REASON_DETAIL WHERE N.NAMED_SPACE ='MYCIM2' ));
🔹 优化点:
-
使用
MATERIALIZED VIEW代替原始GROUP BY计算,减少查询开销。
-
调整
JOIN条件,提前过滤
N.OBJECT='REFERENCEFILE',提高INDEX INSTANCE_ID的效率。
✅ 3. 预期优化效果
| 优化项 | 优化前 | 优化后 | 预期改进 |
|---|---|---|---|
| 查询时间 | 17 秒 | < 5 秒 | 减少大表扫描 |
| Buffer Gets | 14M | < 5M | 减少 I/O 负载 |
| CPU 消耗 | 75% 在 CELL_INFO_HISTORY | < 30% | 减少计算负担 |
| 索引使用 | 大量全表扫描 | 高效 INDEX RANGE SCAN | 提升查询效率 |
🎯 结论
1️⃣ 创建复合索引 IDX_CELL_INFO_HISTORY (REASON_DETAIL, REASON_CODE, CREATE_DATE),加速 GROUP BY 查询。
2️⃣ 使用 MATERIALIZED VIEW (MV_CELL_INFO_HISTORY) 预计算,避免重复扫描 20M 行数据。
3️⃣ 调整 SQL 结构,减少 LEFT JOIN 计算量,提高索引使用率。
🚀 预期 SQL 执行时间降低到 5 秒以内,显著提升数据库性能!
可以看到这个优化建议,已经非常清晰,而且给预估出了优化后的执行时间<5秒,我根据chatgpt的建议优化后,执行时间为4.2秒;

总结
我又尝试了多个大sql给chatgpt,它基本上都是按这三种模式来给我提出优化建议
1.根据具体的sql建议创建联合索引
2.使用MV物化耗时较久的子查询模块,这个建议有点耍流氓,你说有用吗?确实有用,但是在实际操作中可操作性较小,除非该子查询会被大量使用;
3.代码重构
而且chatgpt给出的优化后的时间和io的估算也是比较准确的,这点不得不说还是蛮强大的。如果想进一步调优,还可以使用ash,sqlhc等脚本跑出更详细的sql执行信息,丢给AI相信给出的优化信息将会更精准。AI的sql优化能力,取决于你给他多少数据,给的数据越多,回答的越精准。我认为目前chatgpt和deepseek的sql优化能力可以应付80%的通用场景,这可以大大的弥补DBA和开发sql优化层面的不足。

可以想象一个可行的自动化优化方案

