




DSE精选文章
FL‑GUARD: A Holistic Framework for Run‑Time Detection and Recovery of Negative Federated Learning
文章介绍
方法框架
1. 负联邦学习形式化定义
联邦学习通过中央服务器与客户端之间的迭代交互,通信模型参数,来实现在不暴露客户端私有数据的前提下训练出一个共享的全局模型。在每一轮联邦学习中,服务器将全局模型传输给一批客户端,这些客户端接收后使用本地数据训练该模型,产出本地更新后的模型参数,进而传输回服务器,最后服务器聚合所有本地更新结果,并更新全局模型以及开启下一轮迭代。
理想的联邦学习算法应训练出具有优越性能表现(如具有高预测精度)的模型;假设客户端在参与联邦学习之前,拥有在自己本地数据上独立训练得到的私有模型;则在该情况下,客户端期望从联邦学习中获得的模型能够在性能表现上超过自己的本地私有模型;若无法超越,客户端很可能不会愿意继续为联邦学习贡献算力。
负联邦学习指的是联邦学习系统的一种非理想状态,在该状态下客户端从联邦学习系统中所获得的模型无法超越大部分客户端所持有的私有模型。
为了判断联邦学习是处于一个健康理想的状态还是负联邦学习状态, 本文定义了一个客户端性能增益指标,用于在算法运行时动态衡量客户端参与联邦学习所获得的性能增益,并基于该指标提出负联邦学习的形式化定义。
给定一个包含N个客户端的联盟,对于每个客户端i (其中i=1,…,N),本文用Vi表示联邦学习模型在该客户端的性能表现,用Pi表示该客户端本地私有模型的性能表现,并用如下公式定义该客户端的性能增益:
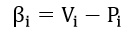
基于所有客户端的性能增益指标,本文定义了系统总体性能增益指标β,其中, αi为客户端i的权重,代表客户端i在系统总体性能增益评估中的重要性。
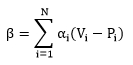
基于系统总体指标,本文将负联邦学习状态定义如下:对于任意一个联邦学习系统,如果不存在一个正整数R,使得该系统在第R轮联邦学习之后产出的所有模型满足β>0,那么该系统处于负联邦学习状态。在这种情况下,系统总体性能增益指标的绝对值(即|β|)量化了当前联邦学习系统对于所有客户端的总体负效应。
2. 负联邦学习动态检测与修复
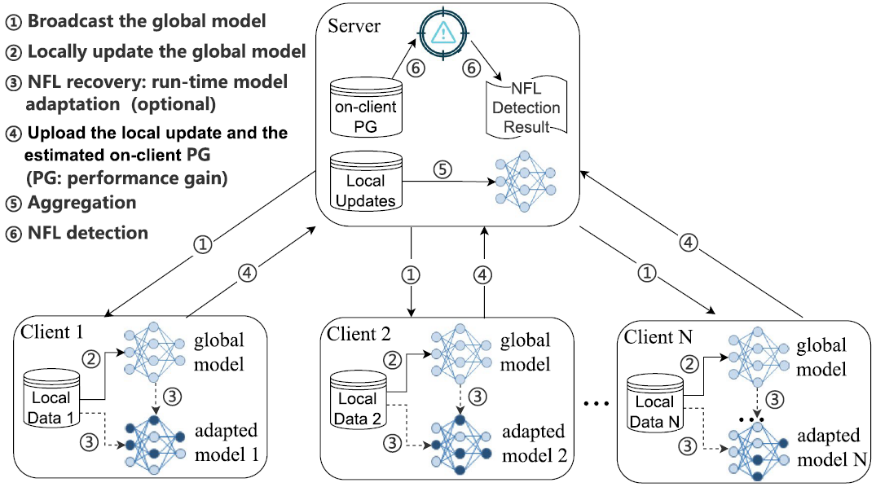
图1. FL-GUARD框架图
本文提出了一种在联邦学习算法运行时解决负联邦学习问题的系统框架FL-GUARD。该框架将负联邦学习视为一种可测量、可检测、可避免、并且可能发生在任意一次联邦学习过程中的状态。当负联邦学习状态出现时,系统可以采用我们所提出的自适应模型训练方案将负联邦学习状态修复为健康的联邦学习状态。图1展示了FL-GUARD总体框架图。
【负联邦学习检测】动态检测负联邦学习状态的一种直观做法是在每一轮联邦学习后计算一次系统总体性能增益指标β;然而,该做法需要客户端每一轮都对当前的全局模型做一次性能测试,因此会产生额外的计算代价。为了避免这种代价,本文提出利用客户端训练数据作为代理,实现对客户端性能增益的高效估计,并基于客户端性能增益的估值来实现负联邦学习动态检测。
具体来说,在每一轮联邦学习中,轮数索引为,全局模型参数为,客户端(其中=1,…,)用于训练该模型的第一批训练数据为,基于此,客户端i可以通过如下公式,在本轮第一次参数更新全局模型之前,就顺着联邦模型训练的原始过程得到性能增益的估值β
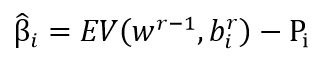
在接收到当前所有活跃客户端的性能增益估值后,服务器通过如下两个公式来计算系统总体性能增益估值,通过取中值以及最近轮结果平均的设计,本文能够提高了所提出框架对于极端性能增益估值的鲁棒性。
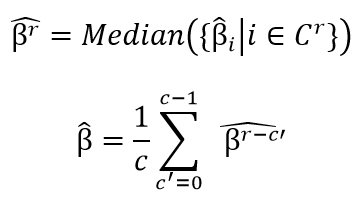
基于系统总体性能增益估值,本文提出如下动态检测负联邦学习方案:
首先,在每一轮联邦学习中,服务器监测是否出现,若该现象出现次数超过给定阈值,则服务器报告系统处于负联邦学习状态;
其次,已报告的负联邦学习状态允许被撤销,当服务器连续轮观测到,则撤销先前报告的负联邦学习状态;
需要注意的是,第一步检测过程在所有轮数的联邦学习中持续进行。为了能够尽早地检测出潜在的负联邦学习(避免客户端浪费算力在负联邦学习状态中)同时避免错误报告,本文建议将阈值NR设定在50-100的范围之间。
【负联邦学习修复】一旦检测到负联邦学习状态,本文所提出的框架将启动负联邦学习修复机制,让客户端在训练全局模型时并行学习一个自适应模型。该自适应模型目标能够更好地拟合客户端本地数据,同时从联邦学习全局模型中收获更好的泛化能力,进而让客户端从联邦学习中收获正向性能增益。
为了实现该目标,客户端在训练自适应模型的过程中最小化两个指标:一是自适应模型在本地数据上的损失值,二是自适应模型参数向量和全局模型参数向量之间的差异值(其中在每一轮联邦学习中由服务器传来的全局参数初始化进而在客户端本地数据上进行更新)。经验发现指出,当全局模型能够在本地数据上取得较高性能表现(如较小)时,最小化自适应模型参数向量和全局模型参数向量之间的差异值有利于自适应模型的训练;然而,当较大时,最小化两个参数向量的差异值并不利于自适应模型。基于该发现,本文引入了一个动态参数λ来灵活地调整自适应模型的优化目标,计算公式如下:
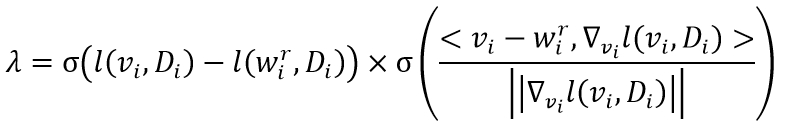
基于参数λ,客户端i将通过最小化损失来实现对自适应模型的优化,其中。参数λ将在两种情况下减小:一是全局模型对于客户端性能增益不显著,二是减少自适应模型参数与全局模型参数的差异会大幅影响本地数据拟合目标;在这两种情况下,较小的λ值能够让自适应模型训练更加稳定有效,实现本地数据拟合和提高泛化效果二者之间的动态平衡。
完整的FL-GUARD算法如图2所示。在每一轮联邦学习中,客户端只需要将本地更新后的全局模型参数以及一个浮点数值返回给服务器。因此,FL-GUARD与传统联邦学习算法相比,具有相似的通信代价和隐私保护性能。

图2. FL-GUARD完整算法图
针对FL-GUARD的使用,本文提出了两种模式:
一是如图2算法所示的动态检测和修复的模式;在该模式下,系统在检测到负联邦学习发生之前不会引入任何用于系统状态修复的额外代价,只有当检测到负联邦学习,系统才会激活修复策略,让客户端开始自适应模型与全局模型并行训练。
二是全过程修复模式;在该模式下,系统预设负联邦学习状态标识符为真,然后从第一轮联邦学习一直到最后算法结束,始终保持负联邦学习修复策略(即自适应模型训练)启动。
需要注意的是,在任意一种使用模式下,启动自适应模型训练并不会对全局模型训练有明显影响,然而,负联邦学习修复策略一旦启动,客户端就使用自适应模型来计算自身从联邦学习中获得的性能增益。
本文推荐用户采用动态检测和修复的使用模式,因为在FL-GUARD框架中负联邦学习动态检测的开销较小并且该使用模式能够避免在理想联邦学习过程中引入不必要的修复开销。
除了提供系统整体层面的设计,本文也考虑了客户端个体层面的行为,包括当客户端发现自身性能增益估值在超过NR轮学习过程中始终为负,而系统尚未报告负联邦学习状态,此时,客户端可以独立启动自适应模型训练用于修复本地学习状态;类似的,客户端也可以独立撤销自己所启动的修复策略。由于这些客户端个体行为不会影响系统整体层面的学习结果,因此FL-GUARD允许这些行为的存在。
实验效果
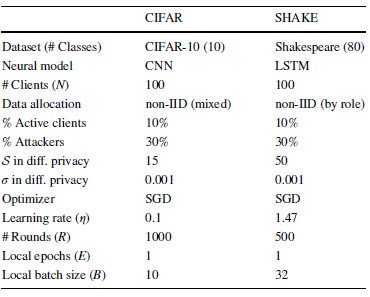
1. 负联邦学习动态检测与修复的有效性与高效性
为了验证所提出的系统总体性能增益估值指标对于负联邦学习动态检测的有效性与高效性,本文通过修改基线任务设定(即采用独立同分布的客户端数据分配方案以及移除恶意客户端),模拟了理想联邦学习环境,对比了系统总体性能增益估值及其真实值在理想联邦学习过程以及负联邦学习状态中的变化情况。
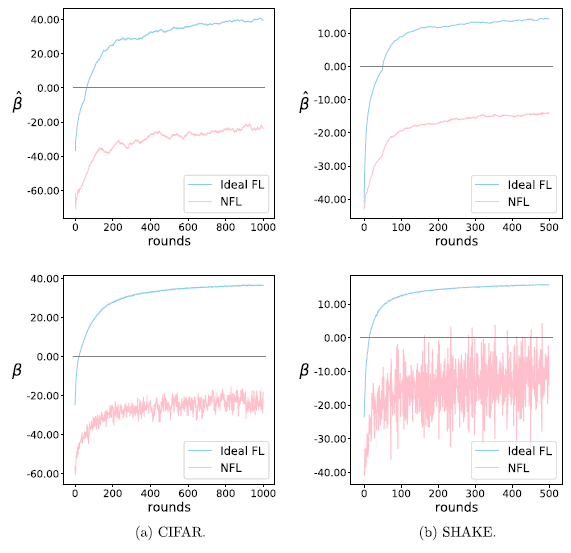
图3. 系统总体性能增益估值及其真实值在理想联邦学习状态和负联邦学习状态下的结果 (此实验采用传统联邦学习算法FedAvg以展示负联邦学习状态)
实验结果如图3所示,其中蓝线表示理想的联邦学习环境下的结果,粉线表示如表1所示的基线设定下的结果。可以看到,系统总体性能增益估值及其真实值在理想联邦学习过程中能够快速转为正值,而在负联邦学习状态下始终在负值区间范围内波动。这些结果一方面证明了系统总体性能增益指标对于区分负联邦学习状态和理想健康状态的有效性,另一方面说明了该指标的估值能够作为其真实值的替代品,以更小的计算代价,高效实现对负联邦学习状态的动态检测。
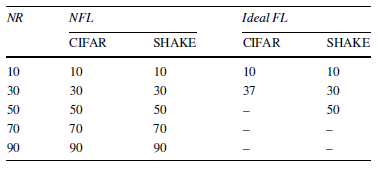
表2展示了本文所提出的动态检测方案在不同NR阈值下检测到负联邦学习状态所需要经历的联邦学习轮数。总的来说,本文所提出的检测方案能够对潜在的负联邦学习状态做出快速报告。在NR阈值较小(如CIFAR任务上NR<50以及SHAKE任务上NR<70)的情况下,检测方案会产生一些错误报告结果;但随着NR阈值增加,错误报告结果消失,与此同时报告潜在负联邦学习状态所需等待的轮数也增加。考虑到错误报告结果在本文所提出的检测方案中允许被撤销(因此对最终系统模型最终性能表现的影响可忽略不计,但会在客户端上引起一些不必要的双模型训练开销),本文推荐设置一个中等NR阈值,也就是在CIFAR任务上设置NR=50,在SHAKE任务上设置NR=70。SHAKE任务收敛速度相对更慢,因此需要设定比CIFAR任务稍微更大一些的阈值。
表2. 不同NR阈值下动态检测负联邦学习所需要的轮数 (横杆:未检出负联邦学习)
采用设定好的NR阈值,本文探查了FL-GUARD在不同使用模式下得到的系统总体性能增益估值以及联邦学习模型准确率随算法运行推进而产生的变化情况,结果如图4所示。除了前文提到的两种使用模式,本文在此实验中还探查了一种瞬时修复策略(short-term recovery),让系统在连续50轮观测到性能增益估值大于0之后,关闭之前激活的修复策略(以节省一些计算代价);此外,本文在本实验中展示了传统联邦学习算法FedAvg(不带有任何负联邦学习修复)的结果。实验结果进一步证明了本文所提出检测方案的有效性和高效性,并且证明了所提出的负联邦学习修复方案不论在持续修复还是瞬时修复模式下均能保持有效性。

图4. FL-GUARD不同使用模式的效果对比
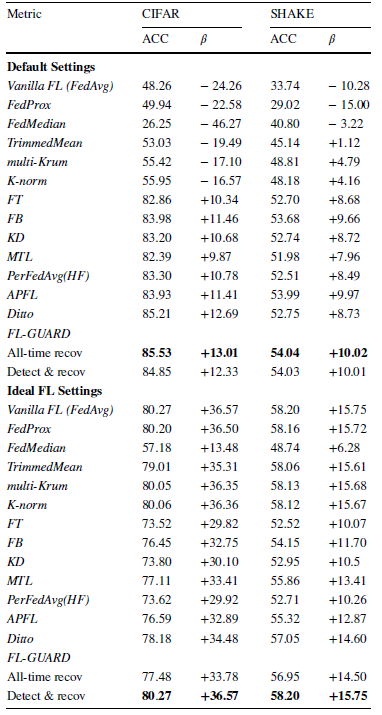
2. 方法对比
为了进一步论证本文所提出方法框架的有效性,本文选取了12种常见应对负联邦学习的算法,在理想联邦学习场景以及会发生负联邦学习的场景(表1设定)下分别进行对比,结果如表3所示。和现有算法相比,FL-GUARD通过其动态检测与修复的使用模式,能够在理想场景以及会发生负联邦学习的场景中均能取得更优异(或相似于最优算法)的准确率性能表现。这些实验结果进一步证明了采用算法运行时动态解决的范式来应对负联邦学习问题具有明显优越性。当负联邦学习发生时,动态检测与修复的范式能够及时地开启本文所提出的自适应模型训练,进而将联邦学习恢复到理想健康的状态;而当客户端联盟处在一个理想环境下,负联邦学习不会发生,此时FL-GUARD动态检测与修复的范式也能够避免引入额外代价来进行不必要的状态修复。
表3. 联邦学习算法对比结果
3. 联邦学习任务环境要素对FL-GUARD的性能效果影响
除了上述实验,本文还尝试变换联邦学习环境设定,测试FL-GUARD在不同设定下运行的效果,探查那些容易引起负联邦学习的环境要素(包括客户端数据分布,客户端活跃度,恶意客户端占比以及隐私保护引入的噪声)对于FL-GUARD所训练模型的准确率以及能够为客户端带来的总体性能增益的影响。在本实验中,传统联邦学习算法FedAvg的性能表现作为对照参考。
表4. 客户端数据分布对FL-GUARD的性能效果影响
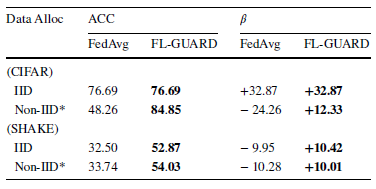
表5. 客户端活跃度对FL-GUARD的性能效果影响
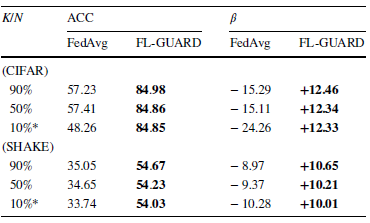
表6. 恶意客户端占比对FL-GUARD的性能效果影响
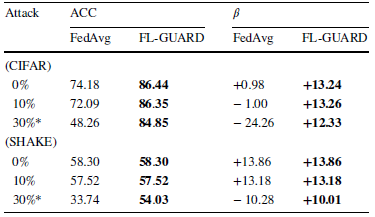
表7. 隐私保护策略引入的噪声大小对FL-GUARD的性能效果影响
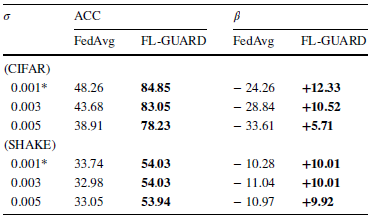
实验结果如表4,5,6,7所示。总的来说,负联邦学习(β<0)在本实验所调试的环境要素范围下非常常见;在大部分情况下,传统联邦学习算法无法训练出较高准确率的模型,无法将系统从负联邦学习状态修复到健康的学习状态;然而,FL-GUARD能在所有场景下保证系统总体性能增益为正,并且在多数情况下增益大小超过10个百分点。这种性能增益非常重要,因为它是客户端为联邦学习贡献算力的主要驱动力。
4. 灵活兼容性与可扩展性
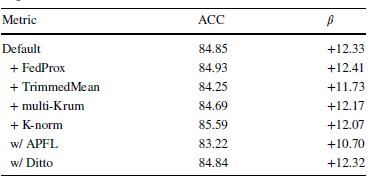
为了论证FL-GUARD框架与现有负联邦学习解决方案的灵活兼容性与可扩展性,本文从对照实验中选取了一部分性能表现较为优异的算法。表8展示了这些算法与FL-GUARD相融合的结果。实验结果证明了在FL-GUARD框架下,不同的联邦学习算法(及其算法内嵌的负联邦学习修复策略)能够与本文所提出的负联邦学习动态检测方案灵活兼容,使得联邦学习系统以一种算法运行时动态解决的范式处理负联邦学习问题。
表8. FL-GUARD兼容不同负联邦学习解决方案所取得的性能效果
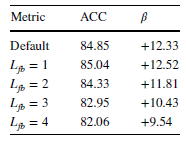
考虑到负联邦学习修复难免引入额外的计算代价,本文进行了一个补充实验,说明当采用本文所提出的自适应模型训练作为负联邦学习修复策略时,计算代价可以通过部分层自适应(即针对神经网络等分层模型,固定其位于低层的模型参数,只训练更新其他非固定部分)的方法来降低。表9展示了部分层自适应的结果,其中L_fb表示参数被固定的模型层数。实验结果表明,部分层自适应的方法能够在不牺牲负联邦学习修复效果的基础上减少计算代价,证明了本文所提出的负联邦学习修复策略(即自适应模型训练)的灵活性。
表9. FL-GUARD采用模型部分参数自适应策略所取得的性能效果
5. 针对不愿意配合负联邦学习状态修复的客户端的鲁棒性
最后,考虑到在现实升级一个在用联邦学习系统(如vanilla FL system)的时候,可能会遇到由于算力、不信任等原因不愿意配合系统启动负联邦学习状态修复策略的客户端,本文还展示了一个补充实验,测试FL-GUARD框架对于不愿意配合负联邦学习状态修复的客户端的鲁棒性。图5展示了系统总体性能增益指标在不配合的客户端(vanilla FL clients)和配合的客户端(FL-GUARD clients)占比不同的情况下的结果。从系统整体的角度来说,随着不配合的客户端占比的增加,系统对于负联邦学习的抵御能力会下降,然而,从那些配合的客户端的个体角度来说,FL-GUARD能够持续为这些客户端提供正向的性能增益,这种性能增益将有力地说服那些不愿意配合的客户端转向愿意遵循FL-GUARD框架。这些结果说明了本文所提出负联邦学习修复策略的有效性以及FL-GUARD框架对于不愿意配合负联邦学习状态修复的客户端具有鲁棒性。
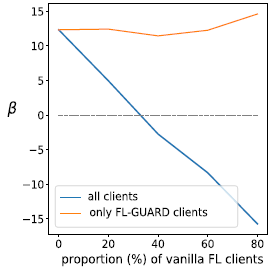
图5. FL-GUARD对于不愿意配合负联邦学习状态修复的客户端的鲁棒性结果
结语
作者简介





期刊简介

