




为了方便朋友们理解,这里准备了表6-1、表6-2,本章所有的查询案例都基于这两个表展开。
表6-1 员工信息表(emp_info)
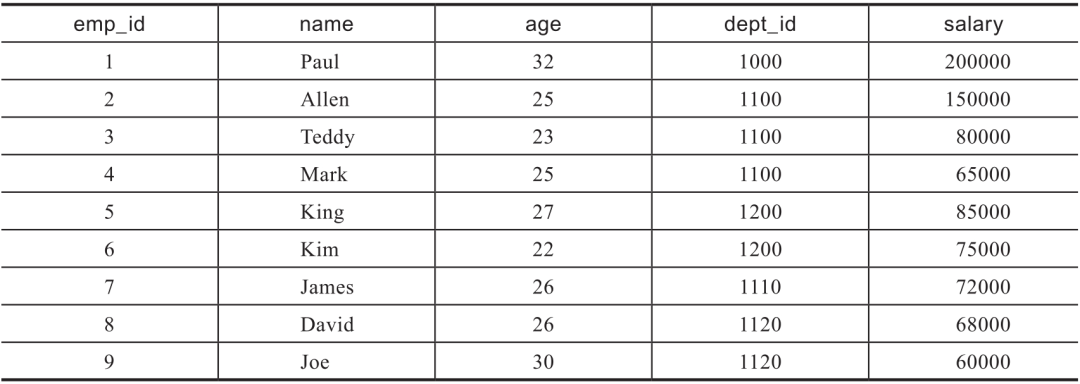
表6-2 部门信息表(dept_info)
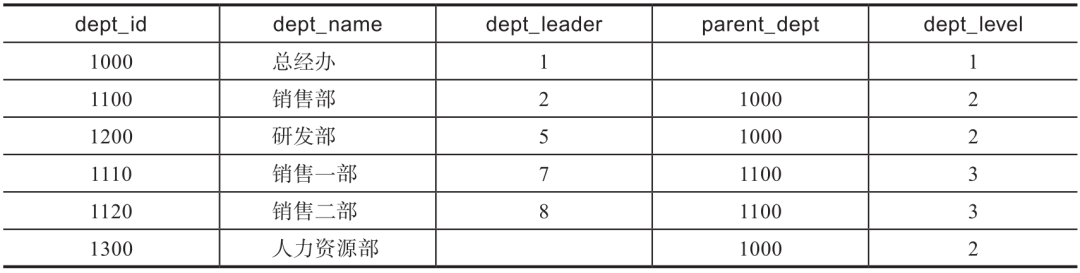
员工信息表建表语句如下:

部门信息表建表语句如下:

分别在两个表中插入数据,SQL语句如下:

插入数据以后,两个表的数据查询结果截图如图6-1、图6-2所示。
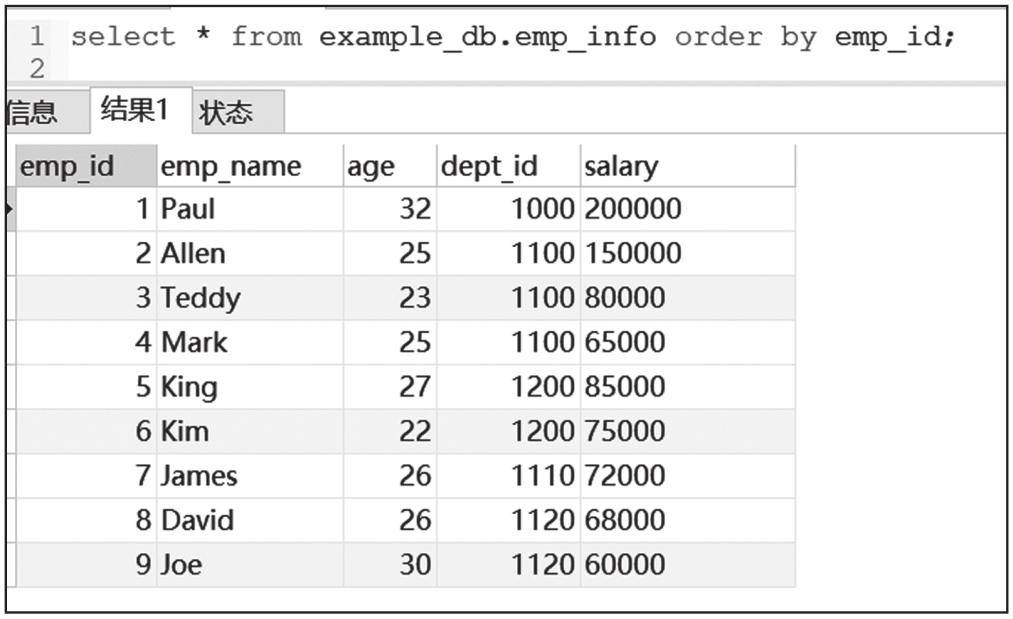
图6-1 员工信息表查询结果截图
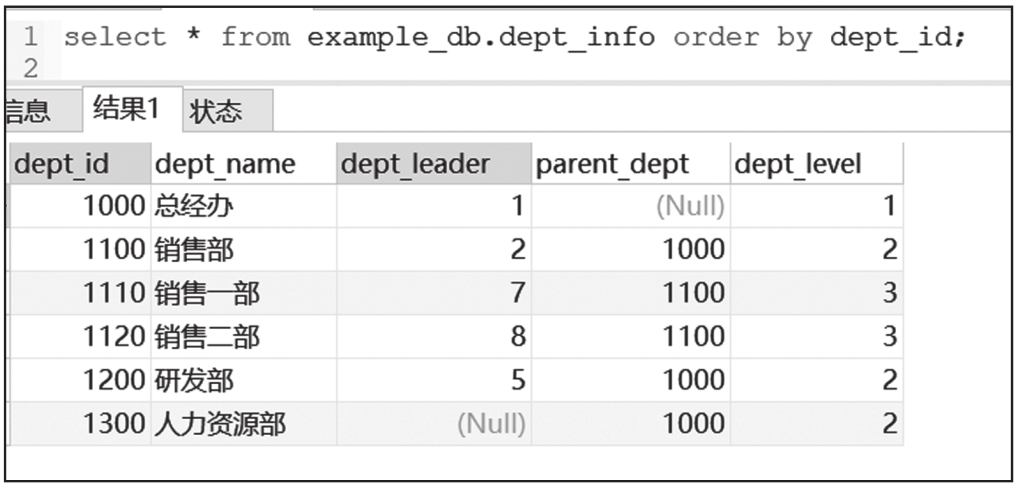
图6-2 部门信息表查询结果截图
SQL是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系型数据库。SQL语言主要包括数据定义语言(DDL)、数据操作语言(DML)和数据查询语言(DQL)三大类。本章重点介绍DQL语言。
01
简单的SQL语法
1. GROUP BY子句
在Doris中,GROUP BY语句和SELECT语句一起使用,用来对相同的数据进行分组。在一个SELECT语句中,GROUP BY子句放在WHRER子句后面、ORDER BY子句前面。
GROUP BY子句可用于对数据表的一列或者多列进行分组,但是被分组的列必须存在于列清单中。

GROUP BY子句查询结果截图如图6-3所示。
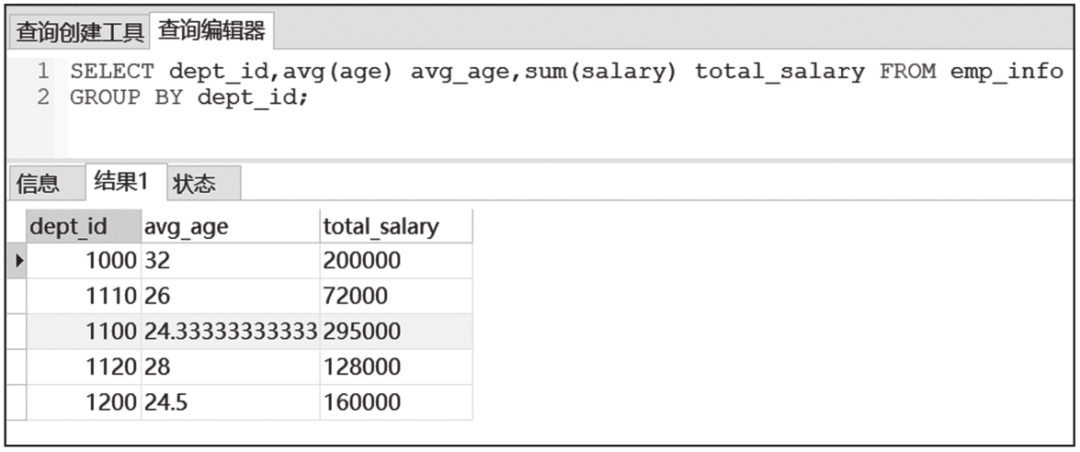
图6-3 GROUP BY子句查询结果截图
2. ORDER BY子句
在Doris中,ORDER BY可用于对一列或者多列数据进行升序(ASC)或者降序(DESC)排列。
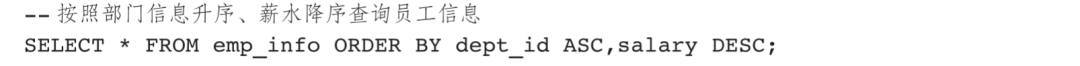
ORDER BY子句查询结果截图如图6-4所示。
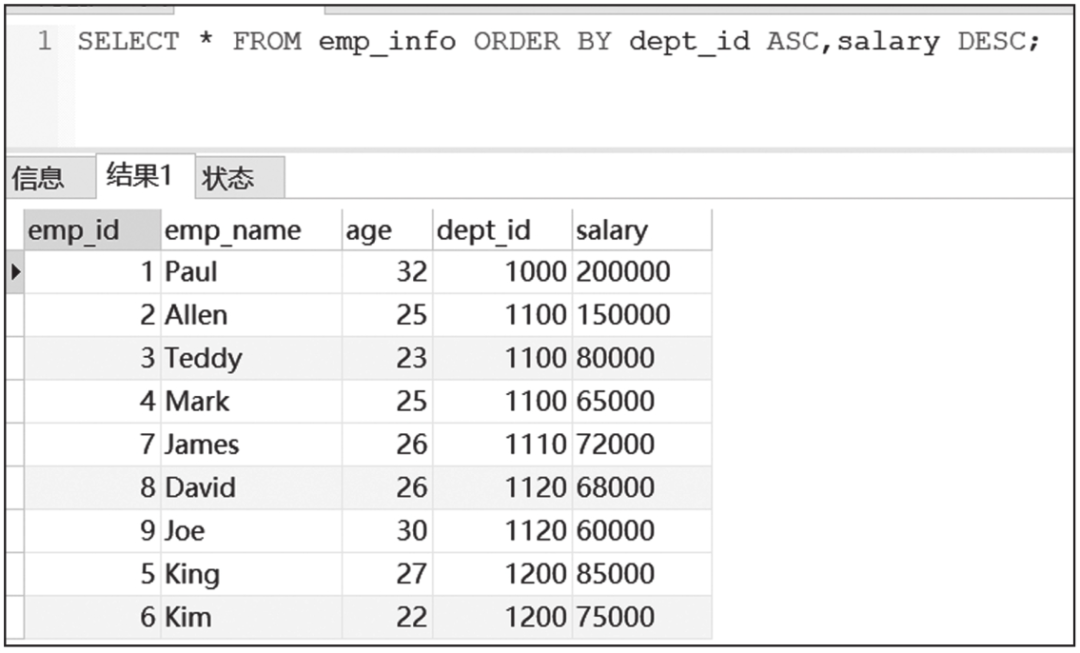
图6-4 ORDER BY子句查询结果截图
3. LIMIT子句
Doris数据库的LIMIT子句和MySQL的类似,用于限制查询返回的结果记录条数,可以加在任何查询语句末尾。
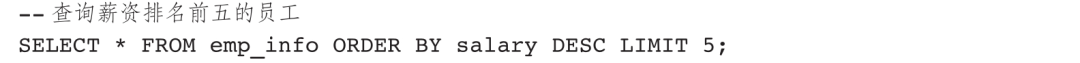
LIMIT子句查询结果截图如图6-5所示。
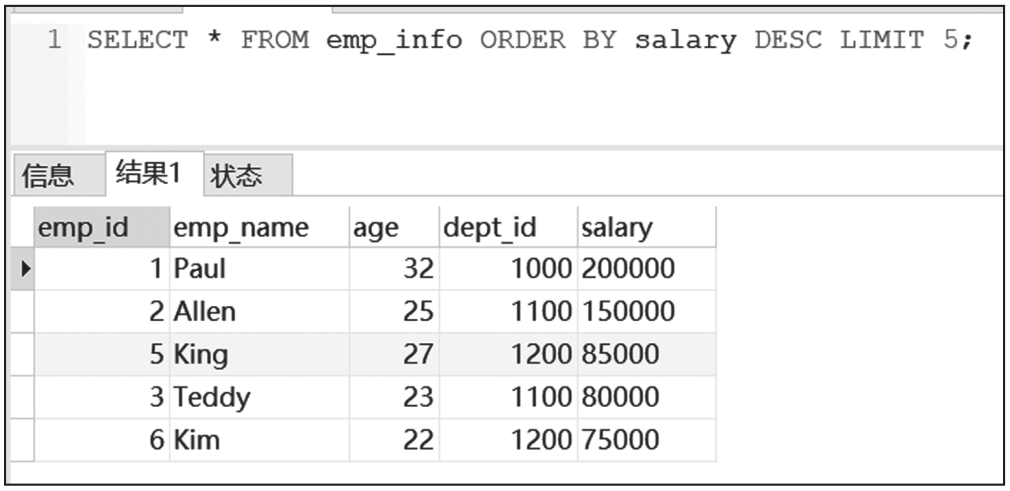
图6-5 LIMIT子句查询结果截图
4. UNION ALL子句
UNION ALL子句用于关联两个子查询,两个子查询的字段数、对应列的字段类型必须完全一致,查询结果的字段别名以第一个子查询的字段别名展示。

UNION ALL子句查询结果截图如图6-6所示。
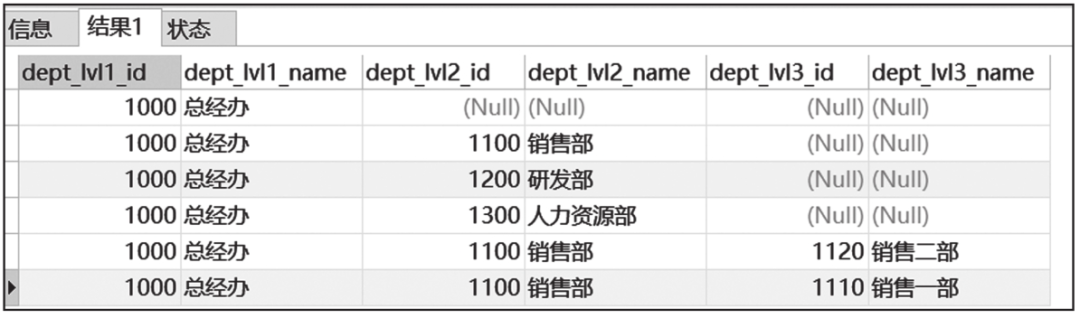
图6-6 UNION ALL子句查询结果截图
补充说明一点,UNION子句会自动去重,UNION ALL子句则是“诚实”地将两个子查询合并起来,通常情况下我们会用UNION ALL。

UNION子句查询结果截图如图6-7所示。
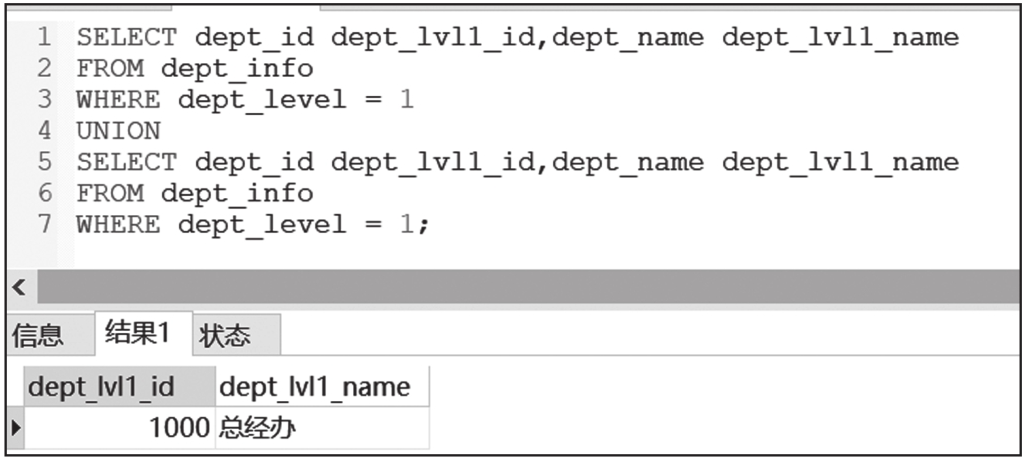
图6-7 UNION子句查询结果截图
相同的查询,换成UNION ALL子句,结果截图如图6-8所示。
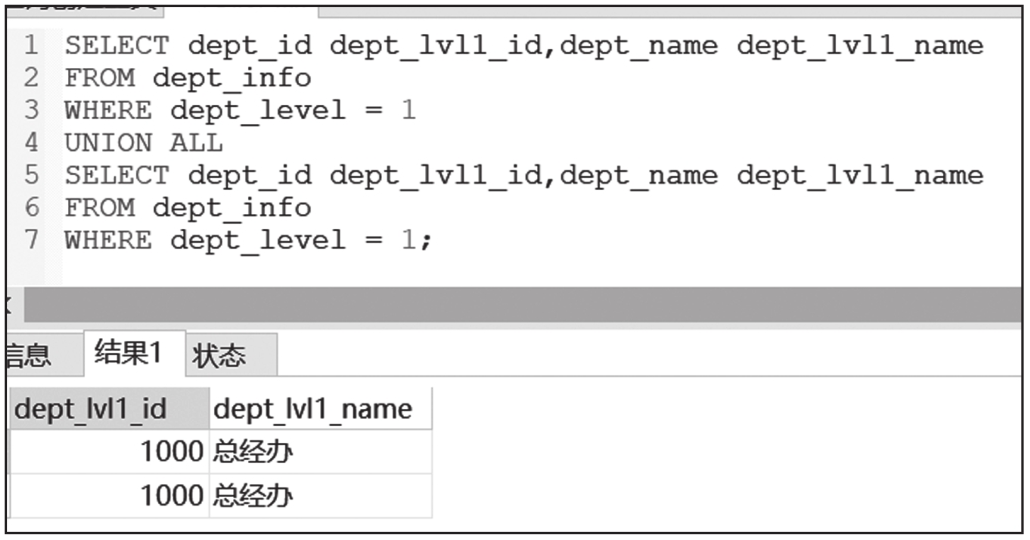
图6-8 UNION ALL子句查询结果截图
5. HAVING子句
HAVING子句用于限制查询结果。HAVING子句的查询限制和WHERE子句查询限制类似,不同的是HAVING子句是针对聚合结果进行限制。

HAVING子句查询结果截图如图6-9所示。
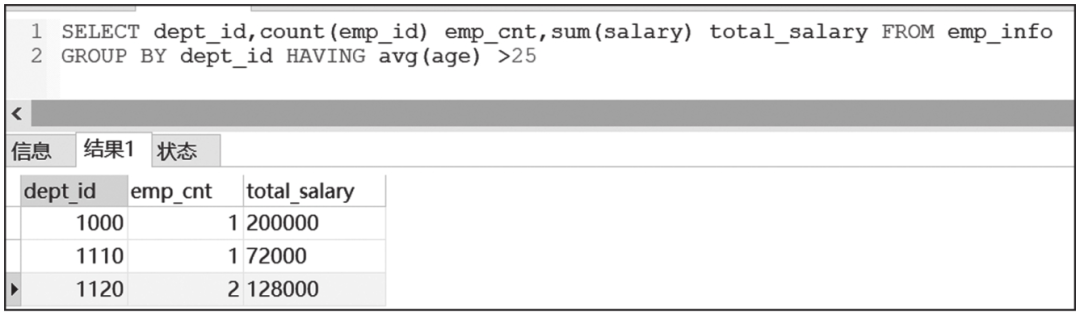
图6-9 HAVING子句查询结果截图
02
WITH特性
WITH子查询的一般语法如下:

使用WITH子句的注意事项如下。
1)使用WITH子句的目的是复用代码和简化逻辑,将复杂的SQL语句进行模块化拆解,让代码可读性更强。
2)WITH子句的返回结果存放于用户的临时表空间。
3)当同时存在多个查询定义时,第一个查询用WITH关键字,后面的查询不用WITH关键字,但是用逗号隔开。
4)最后一个WITH子句与主查询之间不能有逗号,只通过右括号分割。WITH子句的查询必须用括号括起来。
5)前面的WITH子句定义的查询在后面的WITH子句中可以使用。
WITH子句的使用样例如下:


WITH子句查询结果截图如图6-10所示。
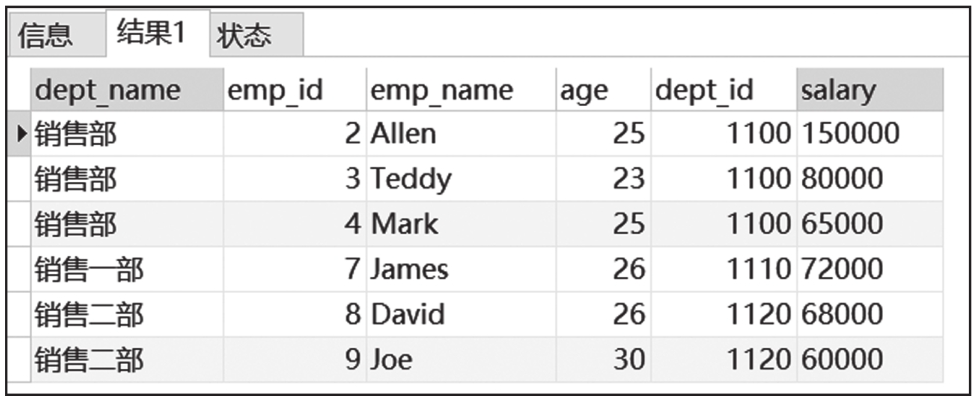
图6-10 WITH子句查询结果截图
而且WITH子句查询获得的是一个临时表,如果在查询中使用,必须采用SELECT FROM WITH查询名。即使WITH子句查询结果只有一个值,也要将其视为一个表,而不能当成字段或者变量直接使用。下面举一个反例。

后面的子查询可以引用前面已经定义的WITH子句查询结果,这里给出一个案例。查询sales_dept是在第一个WITH子句中定义的,查询结果可以在第二个WITH子句中直接当成表来使用。

嵌套WITH子句查询结果截图如图6-11所示。
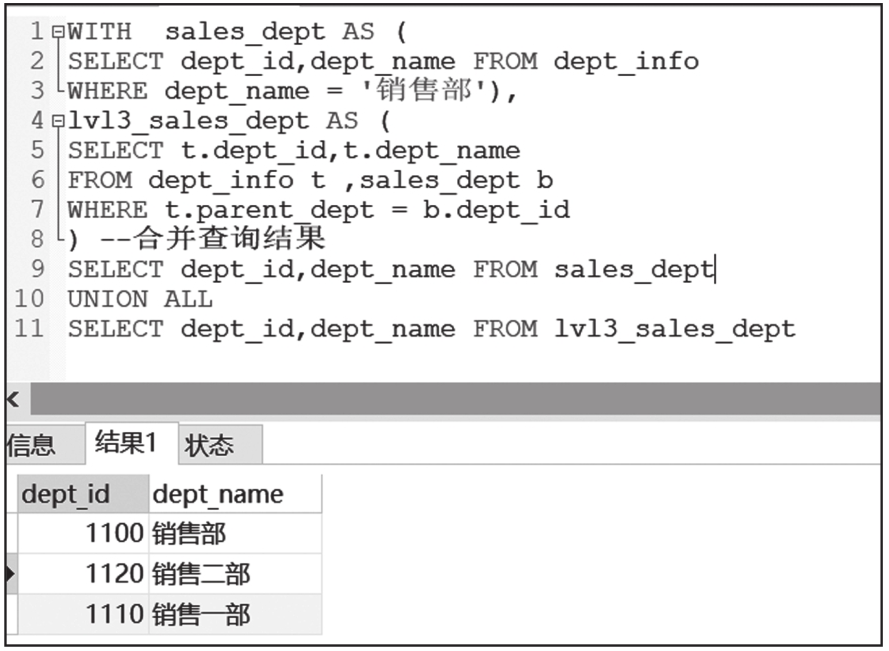
图6-11 嵌套WITH子句查询结果截图
WITH子句是一个可以大幅提高代码复用,降低代码复杂度的语法,特别在BI报表数据加工过程中广泛使用。
下面展示一个复杂的案例。

复杂WITH语句查询结果截图如图6-12所示。
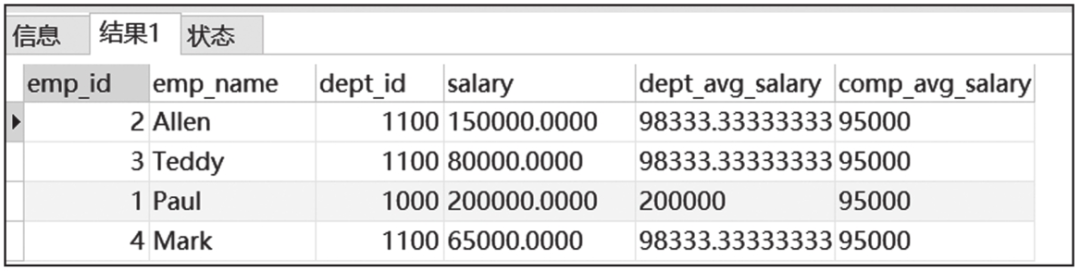
图6-12 复杂WITH语句查询结果截图
当然,针对该查询需求,我们还有另一种更简洁的写法,将在6.3节介绍。
03
IN语句和EXISTS语句
我们先看看IN语句的简单用法。IN语句可替代OR语句,用于从多个取值中筛选数据。下面两个语句效果是等同的,但用IN语句明显更简洁。

IN语句查询结果截图如图6-13所示。
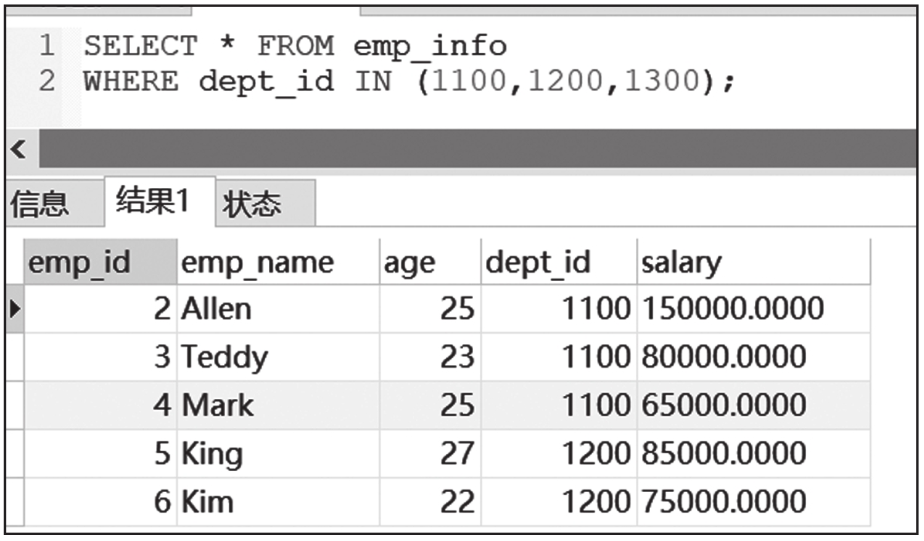
图6-13 IN语句查询结果截图
在该场景中,IN语句和EXISTS语句没有竞争关系,当我们需要判断的过滤条件是一个查询结果时,情况就不一样了。例如要查询研发部员工信息明细,就有下面3种不同写法并且结果是一样的。

EXISTS语句查询结果截图如图6-14所示。

图6-14 EXISTS语句查询结果截图
一般来说,IN语句逻辑更清晰,适用于b表(关联查询的右表或者查询的从表)数量少的情况。EXISTS和JOIN语句虽然可读性会差一点,但是在数据量大的情况下效率更高。EXISTS语句在实际执行中会自动转换成LEFT SEMI JOIN语句。
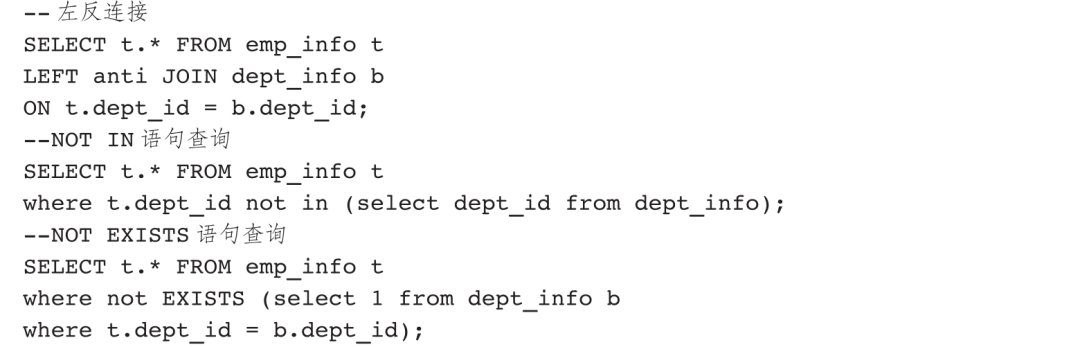
与IN和EXISTS语句相反的是NOT IN和NOT EXISTS语句,用于反向剔除满足某些条件的数据。我们同样用三个语句查询销售部的员工信息明细。

NOT EXISTS语句查询结果截图如图6-15所示。

图6-15 NOT EXISTS语句查询结果截图
NOT IN语句的执行顺序是从主表中逐条取出记录,然后去从表中匹配每一行数据,只有全部从表的记录都不满足匹配条件,才将主表的记录返回给结果集;一旦遇到从表的记录满足匹配条件,则跳出循环,继续取出主表的下一条记录重新开始匹配从表数据,直到把主表中的所有记录遍历完。整个过程只会通过游标去循环遍历,不会通过索引快速查找。
如果主表中记录少,从表中记录多,并且两表都有索引,NOT EXISTS语句的执行顺序变成:从主表和从表中各取出符合条件的数据,按照索引字段进行匹配,如果匹配失败就返回true,如果匹配成功就返回false,不会逐行遍历。这时,NOT EXISTS语句查询是快于NOT IN语句的。NOT EXISTS语句在实际执行中会解析成LEFT ANTI JOIN语句。
总体来说,如果主表的记录多,从表的记录少,应当优先使用NOT IN语句;如果二者的记录差异不大或者主表记录少,从表记录多,应该使用NOT EXISTS语句,通过索引提高匹配速度,以较大幅度提高查询效率。
JOIN是数据库最常见的操作,基于表之间的共同字段,把来自两个或多个表的行结合起来。接下来,我们从JOIN操作类型、JOIN算法实现和分布式JOIN优化策略三个方面展开介绍。
01
JOIN操作类型
常见的JOIN操作类型主要有INNER JOIN、CROSS JOIN、OUTER JOIN、SEMI JOIN和ANTI JOIN,不同的数据库会有不同的实现方式。其中,OUTER JOIN按照连接方向不同可以分为LEFT OUTER JOIN、RIGHT OUTER JOIN和FULL OUTER JOIN。SEMI JOIN也可以分为LEFT SEMI JOIN和RIGHT SEMI JOIN,ANTI JOIN可以分为LEFT ANTI JOIN和RIGHT ANTI JOIN,如图6-16所示。
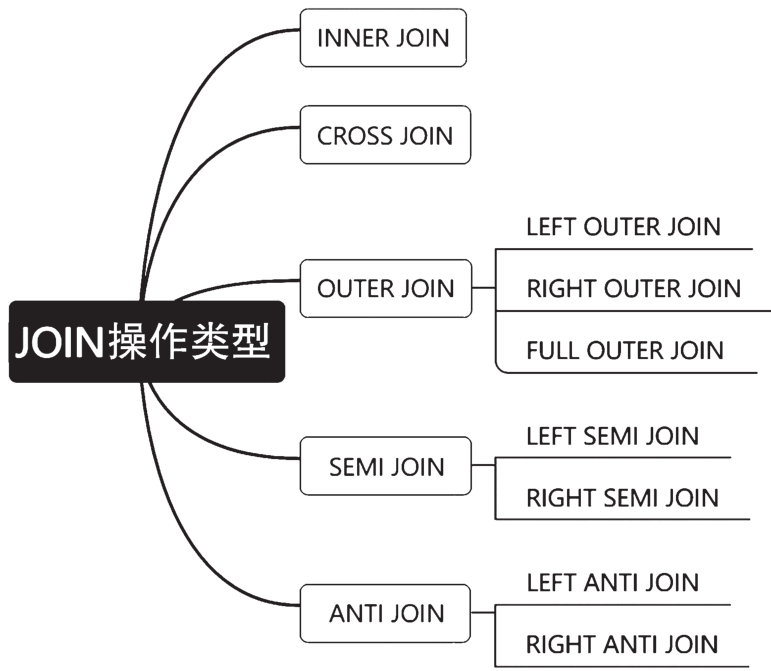
图6-16 JOIN操作类型
为了演示JOIN效果,我们在员工信息表中插入一条部门信息为空,薪水也为空的数据。

插入数据以后,员工信息表数据查询结果截图如图6-17所示。
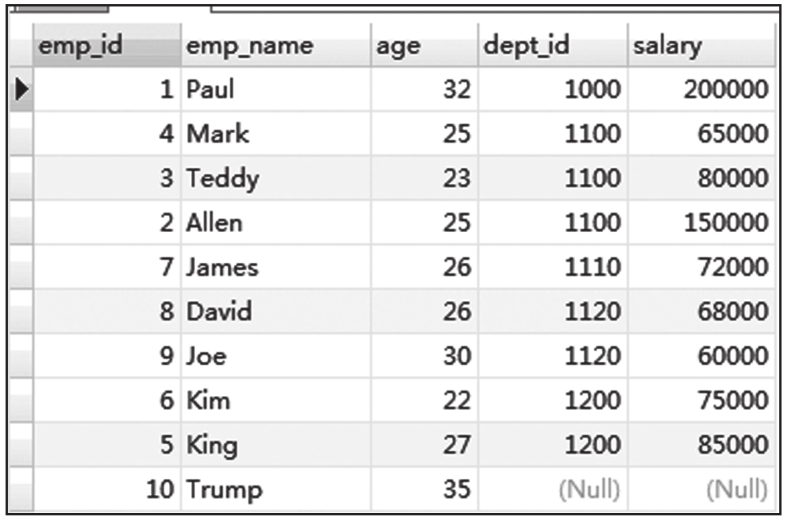
图6-17 插入数据后的员工信息表数据查询结果截图
1. INNER JOININNER
JOIN(内连接)是根据连接谓词,结合两个表(table1和table2)的列值创建一个新的结果表,具体是对table1中的每一行与table2中的每一行进行比较,找到所有满足连接谓词的行的匹配对。
当满足连接谓词时,A和B行的每个匹配对的列值会合并成一个结果行。INNER JOIN是最常见的连接类型,用法示例如下。

INNER JOIN查询结果截图如图6-18所示。
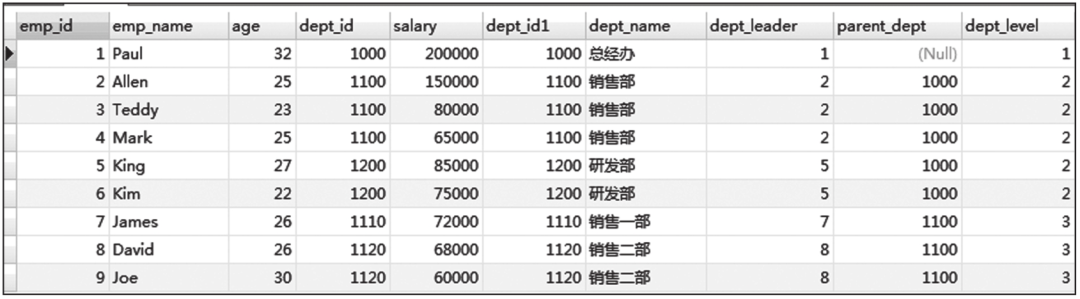
图6-18 INNER JOIN查询结果截图
10号员工Trump由于部门编号为空,所以无法关联。同样,由于人力资源部暂时没有员工,所以也无法关联。
INNER JOIN是Doris默认的连接方式,也就是说在做表关联时,如果不知道JOIN操作类型,默认是INNER JOIN。

不指定JOIN操作类型的查询结果截图如图6-19所示。
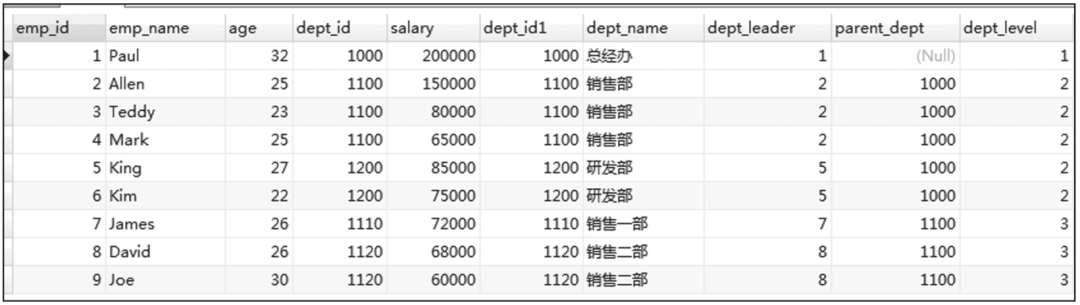
图6-19 不指定JOIN操作类型的查询结果截图
2. CROSS JOIN
CROSS JOIN(交叉连接,也叫笛卡尔连接)是把第一个表的每一行与第二个表的每一行进行匹配。如果两个输入表分别有x和y行,结果表有x×y行。CROSS JOIN有可能产生非常大的表,容易引发数据库内存溢出,所以必须谨慎使用。CROSS JOIN是INNER JOIN的一种特殊形式。
CROSS JOIN的查询结果截图如图6-20所示。
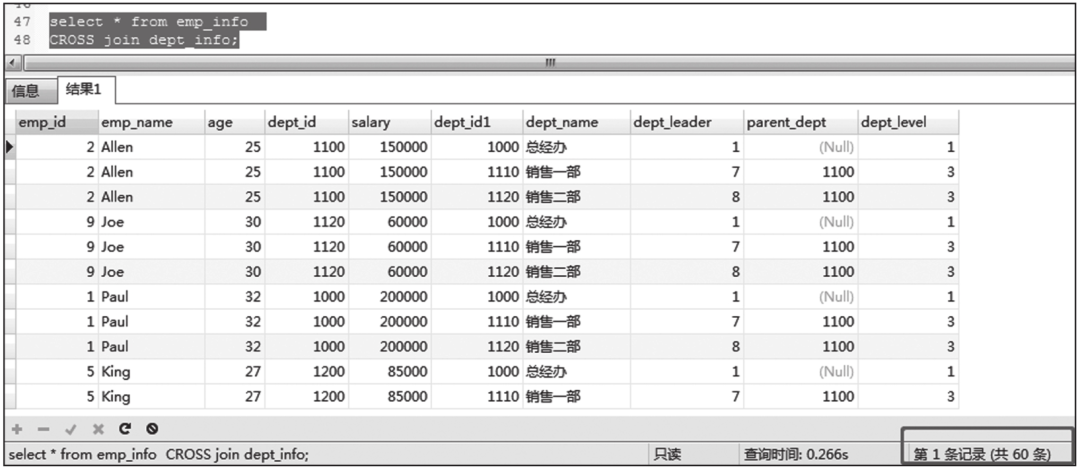
图6-20 CROSS JOIN的查询结果截图
3. OUTER JOIN
OUTER JOIN分为左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)和全外连接(FULL OUTER JOIN)。
左外连接在进行表关联时,是以左表为主表,取右表可以关联的数据,对于无法关联的数据,对应的字段值置为空。
右外连接是左外连接的一个反向操作,是以右表为主表,取左表可以关联的数据,对于无法关联的数据,对应的字段值置为空。
在某些情况下,我们既想看到左表的完整信息,又想看到右表的完整信息,这时就要用到全外连接。

三种连接方式查询结果截图如图6-21、图6-22、图6-23所示。
注意
INNER JOIN和LEFT JOIN是我们必须掌握的连接方式,也是日常开发中最常使用的连接方式。对于交叉连接、右外连接、全外连接,我们只需要掌握其原理即可。
图6-21 左外连接查询结果截图
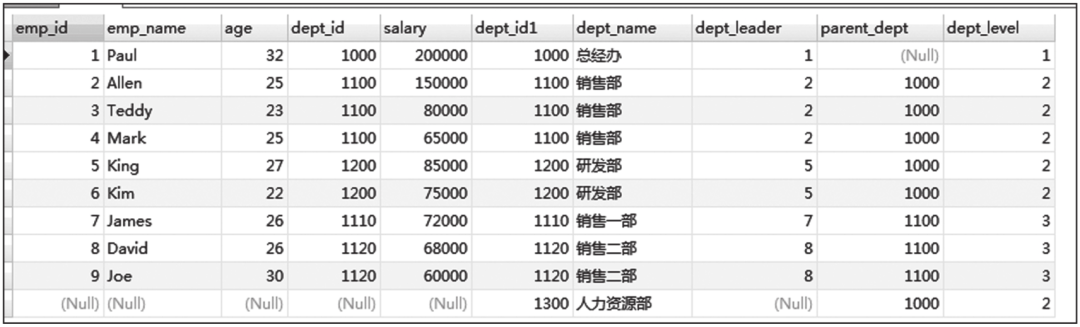
图6-22 右外连接查询结果截图
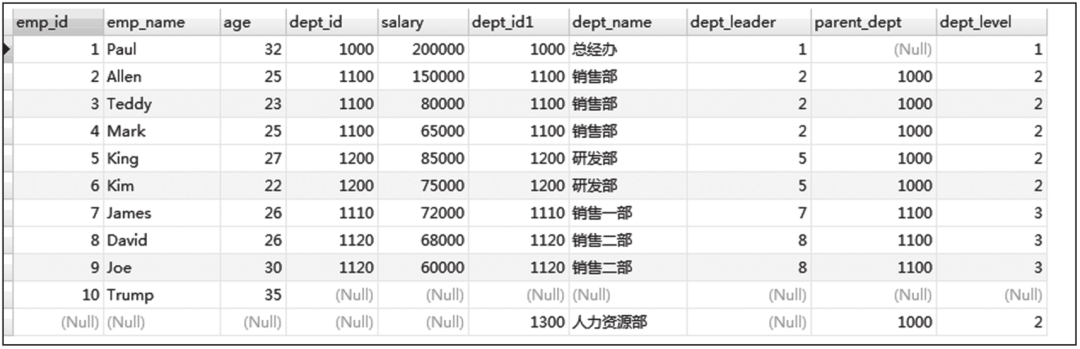
图6-23 全外连接查询结果截图
4. SEMI JOINSEMI
JOIN也叫半连接,可以分为左半连接(LEFT SEMI JOIN)和右半连接(RIGHT SEMI JOIN)两种,当连接条件满足时,返回左表中的数据,即如果左表中某行的ID在右表的所有ID中出现过,则此行保留在结果集中。左半连接和左外连接的区别在于,当左表关联字段在右表存在多条记录时,左表数据不会翻倍,并且返回的结果只能是左表的字段。右半连接只是将左半连接的左右表互换,一般较少使用。

左半连接和右半连接的查询结果截图如图6-24和图6-25所示。
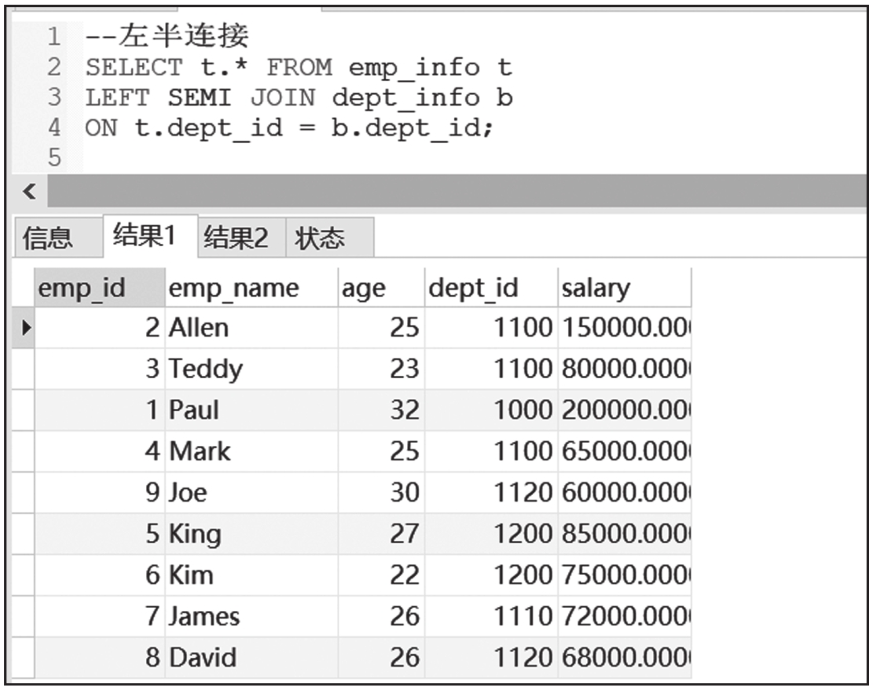
图6-24 左半连接查询结果截图
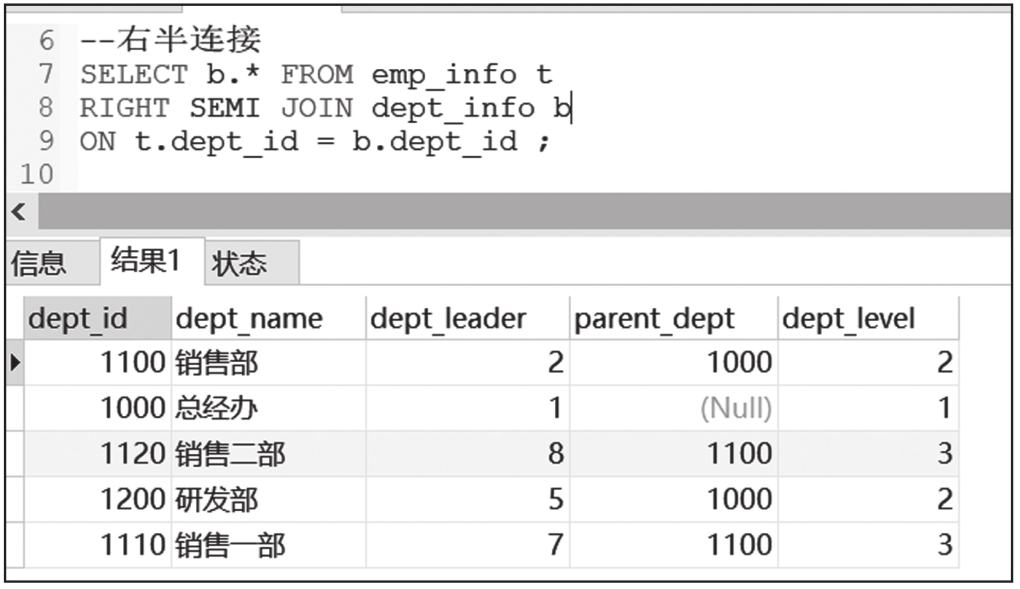
图6-25 右半连接查询结果截图
SEMI JOIN其实是IN和EXISTS语句查询的底层实现。以下三个语句查询效果是等同的。

5. ANTI JOIN
ANTI JOIN也叫反连接,分为左反连接(LEFT ANTI JOIN)和右反连接(RIGHT ANTI JOIN),当连接条件不成立时,返回左表中的数据。如果左表中某行的ID在右表的所有ID中没有出现过,则此行保留在结果集中。右反连接只是将左反连接的左右表互换,一般较少使用。

左反连接和右反连接的查询结果截图如图6-26和图6-27所示。
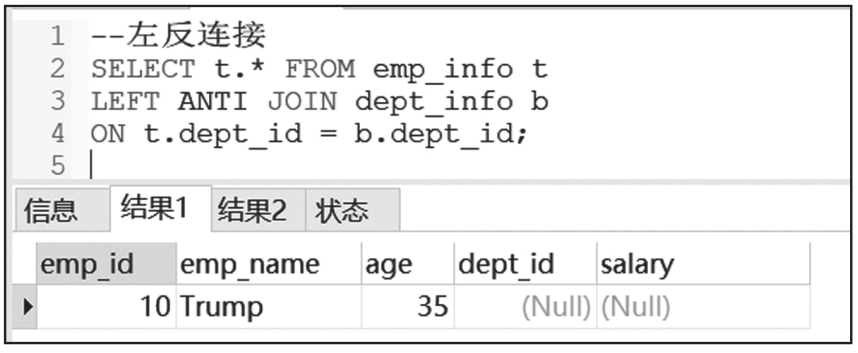
图6-26 左反连接查询结果截图

图6-27 右反连接查询结果截图
ANTI JOIN其实是NOT IN和NOT EXISTS语句的底层实现。以下3个语句查询效果是等同的。
02
JOIN算法实现
数据库中JOIN操作实现算法主要有3种:循环嵌套连接、归并连接和哈希连接。其中,循环嵌套连接有两种变形:块循环嵌套连接和索引循环嵌套连接。
1.循环嵌套连接
循环嵌套连接是最基本的连接。循环嵌套连接用于查询的选择性强、约束性高,并且仅返回小部分记录的结果集。通常,当驱动表的记录较少,且被驱动表的连接列有唯一索引或者选择性强的非唯一索引时,循环嵌套连接的效率是比较高的。
循环嵌套连接返回前几行记录是非常快的,这是因为不需要等到全部循环结束再返回结果集,而是不断地将查询出来的结果集返回。在这种情况下,终端用户将会快速得到返回的首批记录,且同时等待数据库处理其他记录并返回结果集。如果驱动表记录非常多,或者被驱动表的连接列无索引或索引不是高度可选,循环嵌套连接的效率是非常低的。
2.归并连接
归并连接也叫排序合并连接,没有驱动表概念的,两个互相连接的表按连接列的值先排序,再对排序完成后形成的结果集进行合并连接,提取符合条件的记录。相比循环嵌套连接,归并连接比较适用于返回大数据量结果集的场景。
归并连接在数据表预先排序好的情况下效率是非常高的,也比较适用于非等值连接的场景,比如>、>=、<=等情况下的连接(哈希连接只适用于等值连接)。由于排序操作的开销是非常大的,当结果集很大时,归并连接性能很差。
3.哈希连接
哈希连接计算过程分为两个阶段。
1)构建阶段:优化器首先选择一张小表作为驱动表,运用哈希函数对连接列进行计算,产生一张哈希表。通常,该步骤是在数据库内存中完成的,因此运算很快。
2)探测阶段:优化器对被驱动表的连接列应用同样的哈希函数进行计算,并对得到的结果与前面形成的哈希表中的记录进行对比,返回符合条件的记录。在该阶段中,如果被驱动表的连接列的值与驱动表的连接列的值不相等,这些记录将会被丢弃。
哈希连接需要满足两个应用条件:驱动表记录相对多且根据关联字段在驱动表上没有找到合适的索引;必须是等值连接,并且连接条件有一定的区分度。
总体来说,循环嵌套连接适合大表连接小表的场景;归并连接适合两个表记录数接近并且关联字段离散的场景,也适合非等值关联场景;哈希连接一般适合两个大表的多个字段关联场景。
03
分布式JOIN优化策略
分布式系统实现JOIN操作的常见策略有4种:Shuffle Join、Bucket Shuffle Join、Broadcast Join和Colocate Join。
Shuffle Join适合连接的两张表数据量基本相等的场景,首先将两张表中的数据按照关联字段的哈希值打散,使Key值相同的数据分配到同一个节点,然后按照Join算法进行数据关联,最后将结果返回汇总节点,如图6-28所示。
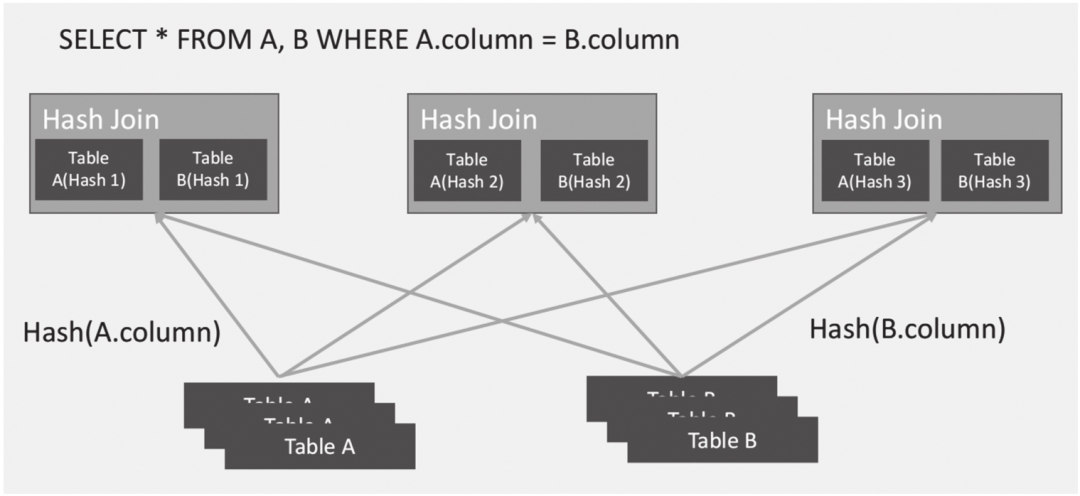
图6-28 Shuffle Join示意图
Bucket Shuffle Join是针对Shuffle Join的一种优化。当连接的两张表拥有相同的分布字段时,我们可以将其中数据量较小的一张表按照大表的分布键进行数据重分布,如图6-29所示。
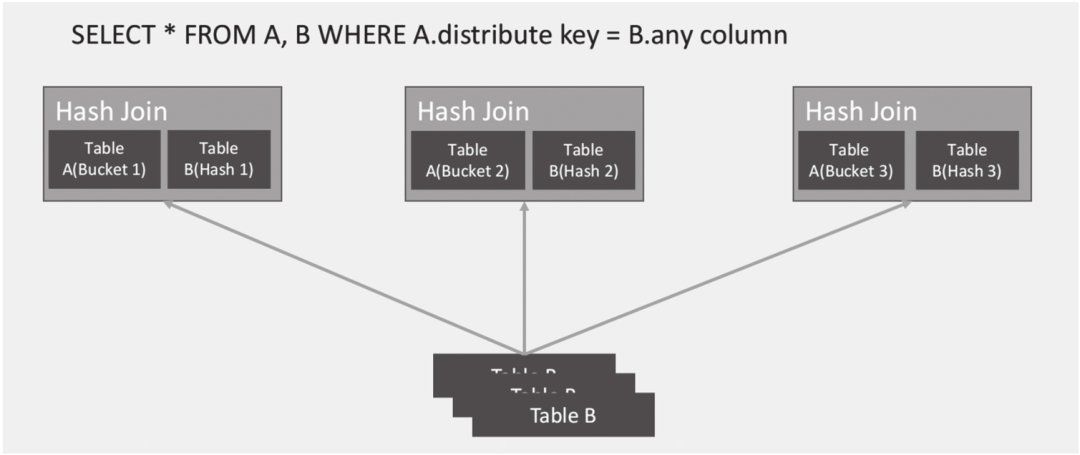
图6-29 Bucket Shuffle Join示意图
Broadcast Join适合大表关联小表的场景,将小表数据复制到所有大表有数据的节点,然后用大表的部分数据关联小表的全部数据,最后将结果返回汇总节点,如图6-30所示。
Colocate Join也叫Local Join,是指多个表关联时没有数据移动和网络传输,每个节点只在本地进行数据关联,然后将关联结果返回汇总节点,如图6-31所示。Colocate Join的前提是保证数据的本地性。
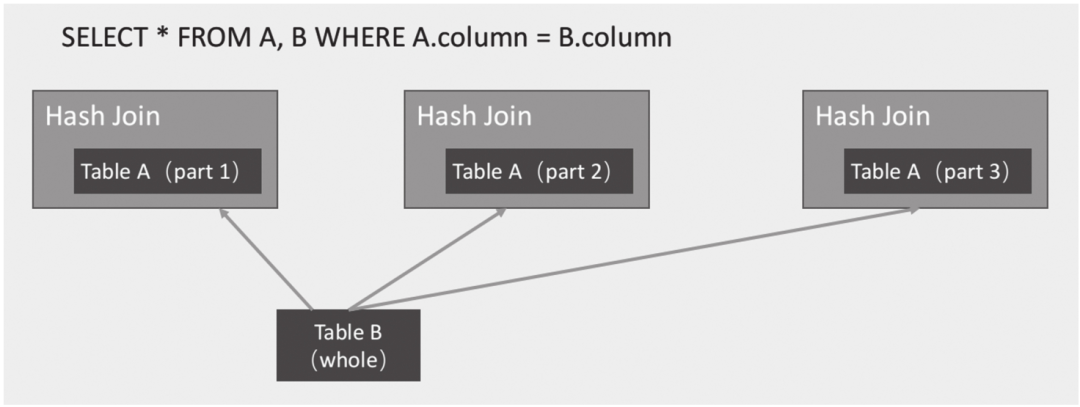
图6-30 Broadcast Join示意图
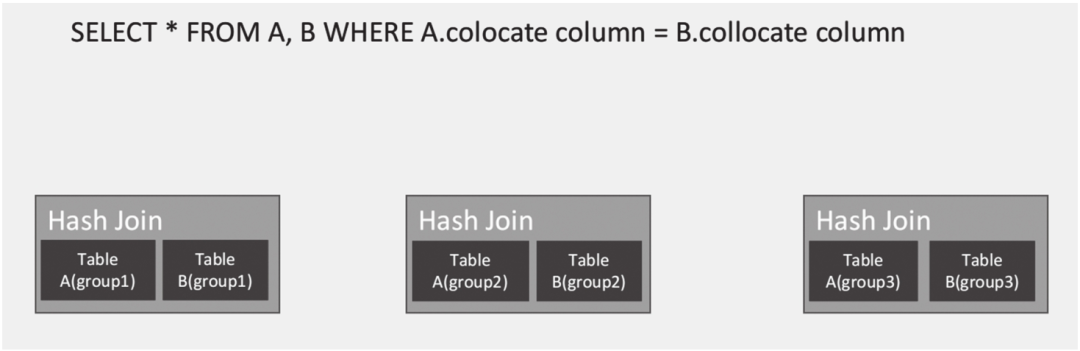
图6-31 Colocate Join示意图
通过以上策略的定义,我们可以很明显地看出,相比Shuffle Join和Broadcast Join,Colocate Join在查询时没有数据移动和网络传输,性能会更高。在Doris的具体实现中,Colocate Join相比Shuffle Join可以拥有更高的并发度,也可以显著提升关联性能。
目前的Doris版本已经支持Colocate Join,只不过默认是关闭的,只需要在FE配置中设置disable_colocate_join为false,即可开启Colocate Join功能。为了在Doris中实现Colocate Join,我们需要针对表进行一些特殊的设置。
1)Colocate Join的表必须是OLAP类型的表。
2)Colocate Join的表必须设置相同的colocate_with属性。
3)Colocate Join的表的BUCKET数必须一样。
4)Colocate Join的表的副本数必须一样。
5)Colocate Join的表的Distributed Columns的字段必须一样并且是关联字段中的一个。
假如需要对表t1和表t2进行Colocate Join,可以按以下语句建表:


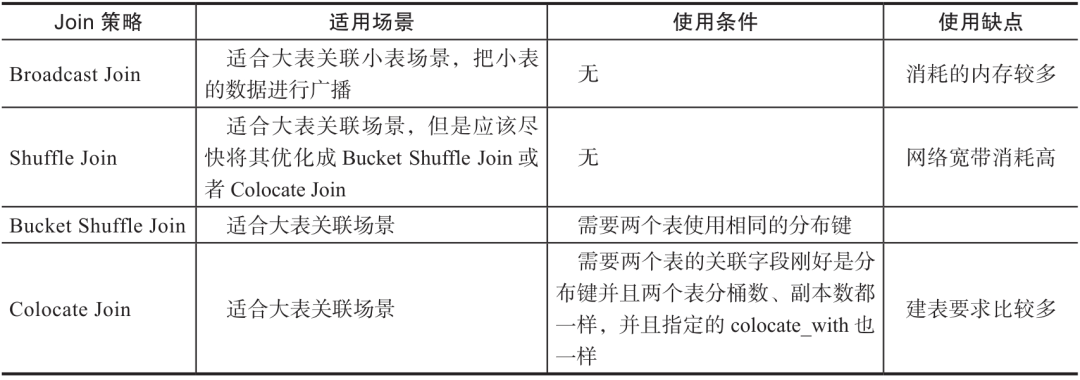
总体来说,Colocate Join在大表关联时可以带来性能的显著提升,但是使用的限制比较多,一般仅用于高频查询或者系统查询性能存在瓶颈的场景。四种Join策略对比如表6-3所示。
表6-3 Doris Join策略对比
开窗查询是数据分析中常见的一种查询语句,是基于窗口函数进行特殊计算的一种SQL表达方式。Doris作为一款定位于OLAP的数据库,对窗口函数的支持必不可少。窗口函数已经逐步成为SQL标准的一部分,越来越多的数据库开始支持窗口函数。
窗口函数具体的查询语法结构如下:

语法解析如下。
1)目前,Doris支持的函数包括avg()、count()、first_value()、lag()、lead()、last_value()、max()、min()、rank()、dense_rank()、row_number()和sum()。
2)PARTITION BY从句和GROUP BY从句作用类似,它把输入行按照指定的一列或多列分组,相同值的行分到一组。
3)ORDER BY和PARTITION BY配合使用,没有PARTITION BY时,ORDER BY表示全局排序;有PARTITION BY时,ORDER BY表示组内排序。ORDER BY并不会真对输出结果进行排序,只是在函数计算时提供逐行计算的顺序。
4)Window从句用来为窗口函数指定一个运算范围,以当前行为准,前后若干行作为窗口函数运算的对象。Window从句支持的方法有:avg()、count()、first_value()、last_value()和sum()。对于max()和min(),Window从句可以指定开始范围UNBOUNDED PRECEDING。语法如下:

ROWS有多个范围值(一般情况下省略),具体如下。
1)UNBOUNDED PRECEDING表示无限或不限定往前统计的范围。
2)n PRECEDING表示往前统计n行(n为1则往前统计1行,n为2则往前统计2行,以此类推)。
3)UNBOUNDED FOLLOWING表示无限或不限定往后统计的范围。
4)n FOLLOWING表示往后统计n行(n为1则往后统计1行,n为2则往后统计2行,以此类推)。
5)CURRENT ROW表示当前行。
下面使用员工信息表和部门信息表数据INNER JOIN结果(见图6-32)进行讲解。
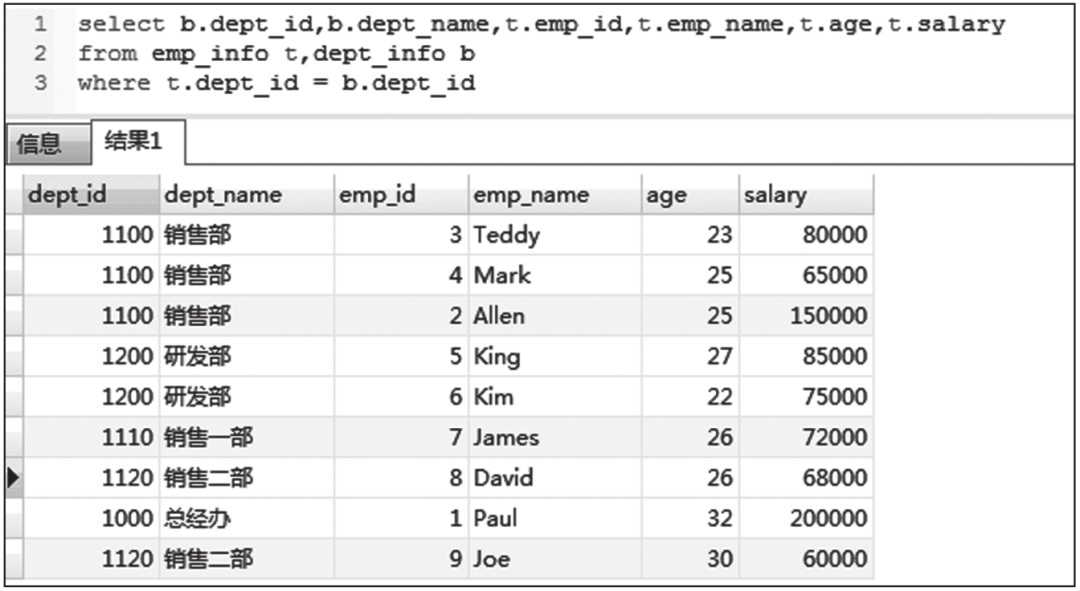
图6-32 INNER JOIN结果
案例1:利用min、max分别取出不同部门员工薪水的最高值和最低值,附带在上述结果数据后。

案例一窗口函数查询结果如图6-33所示。
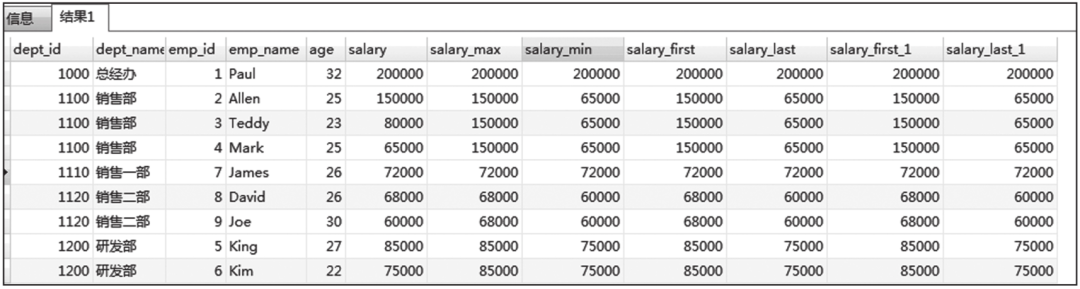
图6-33 案例一窗口函数查询结果
通过数据对比,我们可以发现以下信息。
1)min和max函数是直接获取组中的最小值和最大值。
2)first_value和last_value是返回窗口的第一行和最后一行数据,因为我们通过薪水字段对分组内的数据进行了降序排列,所以也可以达到在一定的窗口内获取最大值和最小值的目的。
3)排序不指定窗口时,以组内第一行到当前行为窗口,然后取出窗口的第一行和最后一行。
案例2:利用rank、dense_rank、row_number对员工年龄进行排序,比较3个不同函数排序的差异。

案例二窗口函数查询结果如图6-34所示。
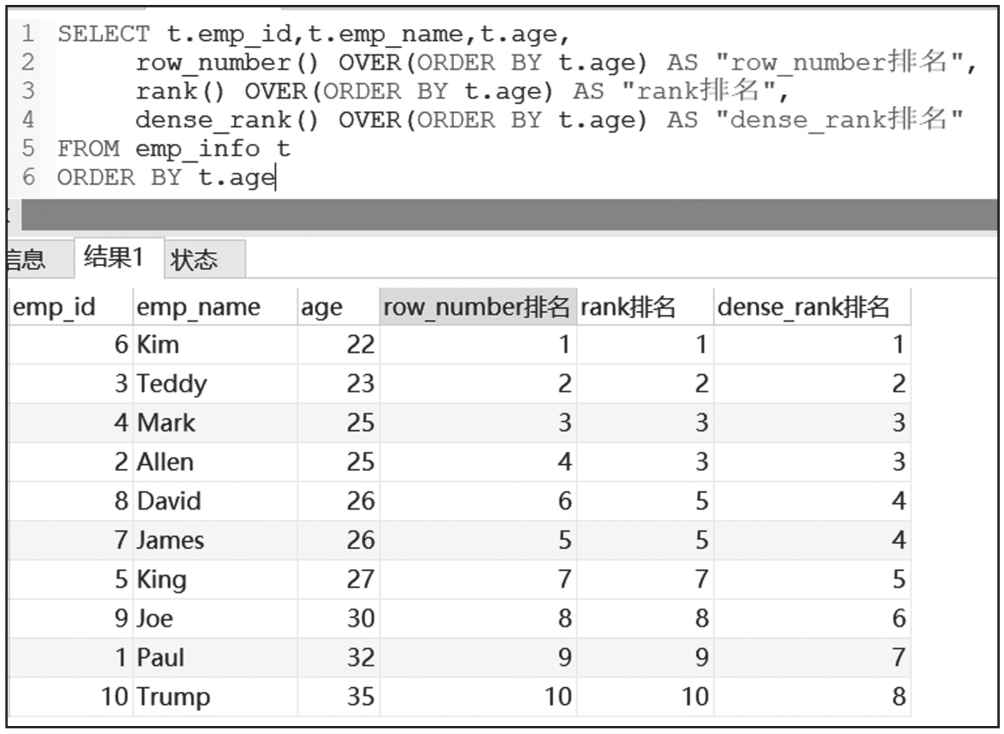
图6-34 案例二窗口函数查询结果
通过上述查询结果数据,我们可以看出以下信息。
1)row_number函数返回一个唯一的值,当碰到相同数据时,排名按照返回记录的顺序依次递增。
2)rank函数返回一个唯一的值,但是当碰到相同的数据时,所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。比如年龄都是26岁的两个人并列第5名,27岁的King排名是第7名。
3)dense_rank函数返回一个唯一的值,但是当碰到相同的数据时,所有相同数据的排名是一样的,同时在最后一条相同记录和下一条不同记录的排名之间不空出排名。比如年龄都是26岁的两个人并列第5名,27岁的King排名是第6名。
案例3:利用窗口函数对员工薪水进行不同条件的汇总,以便对比ORDER BY和PARTITION BY的作用。

案例三窗口函数查询结果如图6-35所示。
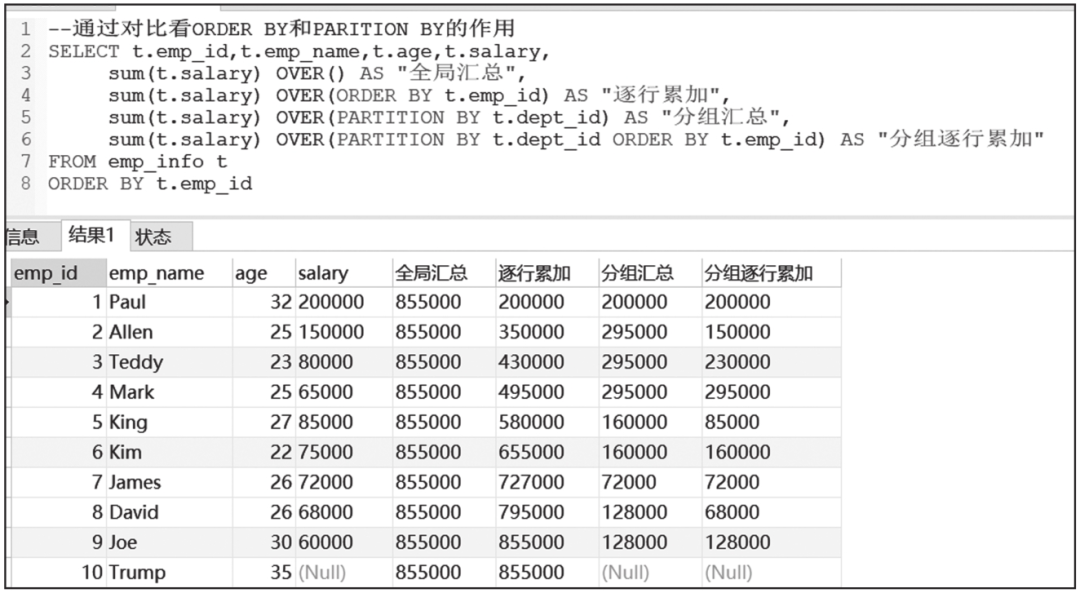
图6-35 案例三窗口函数查询结果
通过上述查询数据结果,我们可以看出如下信息。
1)OVER()默认是全局汇总,即所有可以查到的行数指标合集,可用于计算占比。
2)OVER+ORDER BY用于根据条件逐行相加汇总。
3)OVER+PARITION BY用于分组汇总,可以计算分组求和、分组占比、分组最大值和最小值等。
4)OVER+PARITION BY+ORDER BY用于分组逐行汇总。
总之,通过窗口函数联合使用,我们可以大大简化代码,提高代码执行效率。灵活使用窗口函数特别能体现程序员的SQL开发能力。
最后,针对6.1.2节的案例,下面提供一个使用窗口函数的高级写法。

窗口函数改写为SQL语句查询结果如图6-36所示。
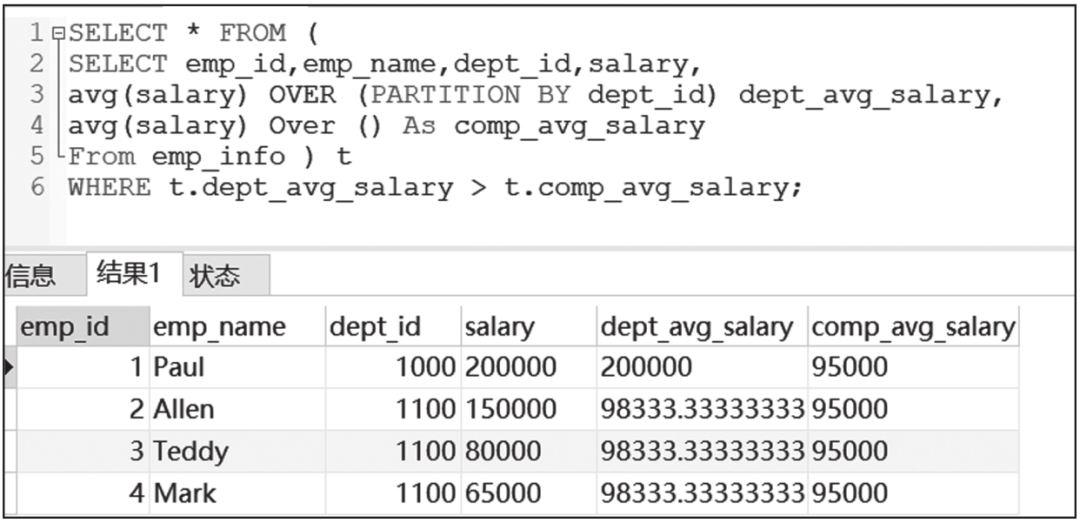
图6-36 窗口函数改写为SQL语句查询结果
用户在使用Doris进行精准去重分析时,通常会有两种方式。
1)基于明细去重:传统的COUNT DISTINCT方式,优点是可以保留明细数据,提高分析灵活性。缺点是需要消耗极大的计算和存储资源,对大规模数据集和查询延时敏感的去重场景不够友好。
2)基于预计算去重:这种方式也是Doris推荐的方式。在某些场景中,用户可能不关心明细数据,仅仅希望知道去重后的结果。在这种场景下,用户可以采用预计算的方式进行去重分析,本质上是利用空间换时间,也是MOLAP聚合模型的核心思路,就是将计算提前到数据导入过程,减少存储成本和查询时的计算成本,并且使用ROLLUP表降维方式,进一步减小现场计算的数据集大小。
Doris是基于MPP架构实现的,在使用COUNT DISTINCT做精准去重时,可以保留明细数据,灵活性较高;但是,在查询过程中需要进行多次数据重分布,会导致性能随着数据量增大而直线下降。
假设有一张用户访问明细表test_bitmap,有3个字段dt、page、user_id(见表6-4),现需要汇总计算PV。
表6-4 用户访问明细表

查询语句如下:
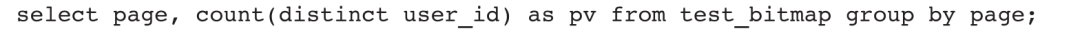
Doris会按照图6-37流程进行计算,先对page列和user_id列执行Group By语句,最后再执行Count操作。
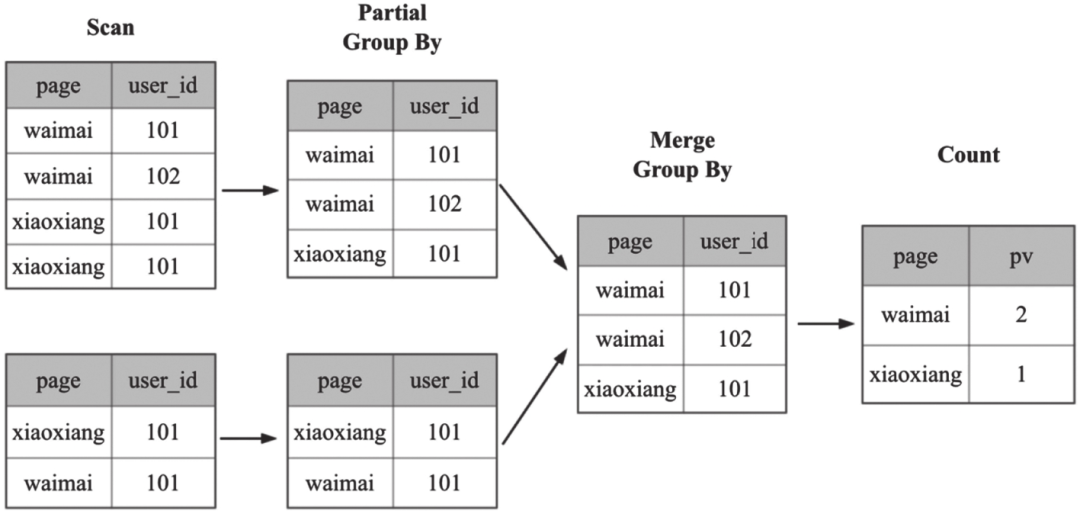
图6-37 Doris去重过程示意图
显然,上述去重方式需要数据进行多次重分布,当数据量越来越大时,所需的计算资源就会越来越多,查询也会越来越慢。BITMAP技术可解决传统COUNT DISTINCT在大量数据场景下的性能问题。
假如给定一个数组A,取值范围为[0, n),对该数组去重,可采用(n+7)/8的字节长度的BITMAP,初始化为全0;逐个处理数组A中的元素,以A中元素取值为BITMAP的下标并将对应下标的bit置1;最后统计BITMAP下标中1的个数(数组A的COUNT DISTINCT结果)。
用BITMAP的一个bit表示对应下标是否存在,具有极大的空间优势:比如对int32长度的字段去重,使用普通BITMAP所需的存储空间只占COUNT DISTINCT去重的1/32。Doris中的BITMAP技术采用Roaring Bitmap(高效压缩位图,简称为RBM,是普通Bitmap的进化)实现。对于稀疏的BITMAP,存储空间显著降低。BITMAP去重涉及的计算包括对给定下标的bit置位,统计BITMAP的bit置位0和1的个数,分别为O(1)操作和O(n)操作,并且后者可使用clzL、ctz等指令高效计算。此外,BITMAP去重在MPP执行引擎中还可以并行处理,每个计算节点各自计算本地子BITMAP,使用bitor操作(位或操作,即比特位的或计算)将这些子BITMAP合并成最终的BITMAP。bitor操作比基于Sort和基于Hash的去重效率要高,无条件依赖和数据依赖,可向量化执行。
需要注意,BITMAP INDEX和BITMAP去重都是利用的BITMAP技术,但引入动机和解决的问题完全不同,前者用于低基数的枚举型列的等值条件过滤,后者用于计算一组数据行的指标列的不重复元素的个数。
BITMAP列只能存在于聚合表中。创建表时,用户可指定指标列的数据类型为BITMAP,指定聚合函数为BITMAP_UNION。当在BITMAP类型列上使用COUNT DISTINCT时,Doris会自动转化为BITMAP_UNION_COUNT计算。
引入BITMAP类型的数据有两种场景。
场景一:导入数据或者插入数据的时候直接将数据转换成BITMAP类型。
创建一张含有BITMAP类型列的表,其中visit_users列为聚合列,列类型为BITMAP,聚合函数为BITMAP_UNION。

采用INSERT INTO语句向表中导入数据:

数据插入后查询结果如图6-38所示。
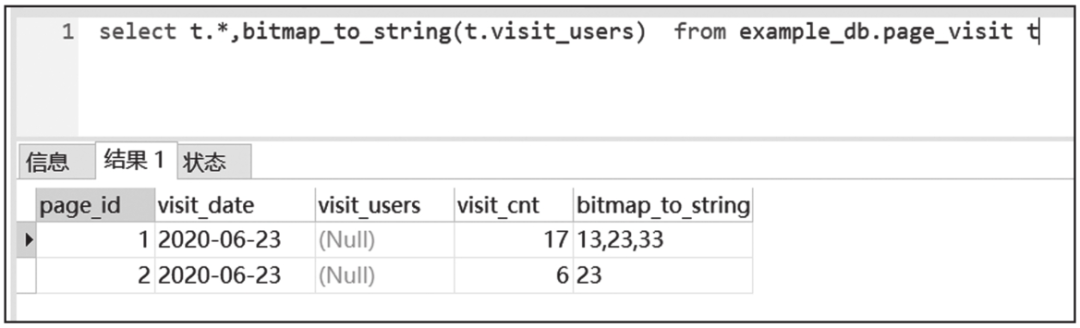
图6-38 Bitmap字段查询结果
更多情况下,用户可通过Stream Load方式向表中导入数据。

执行过程如图6-39所示。
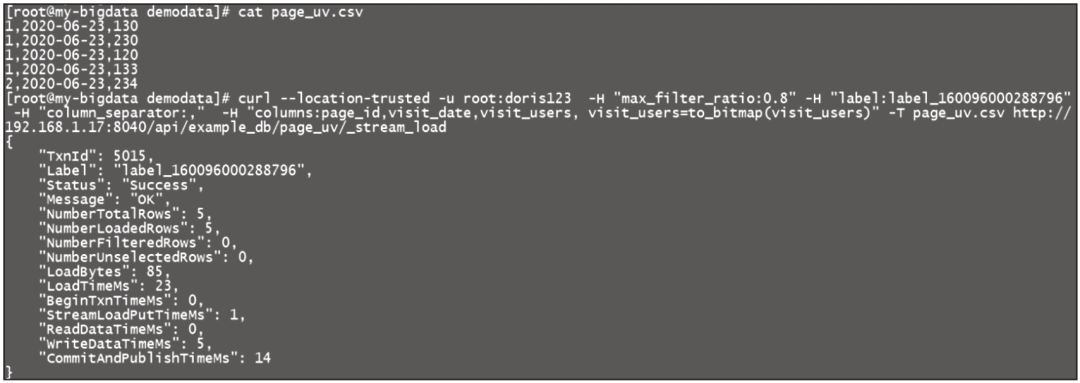
图6-39 Stream Load方式导入数据执行过程
场景二:在Doris数据库内部将字段转换成BITMAP类型。
在Doris数据库内部将字段转换成BITMAP类型也有两种方式:将其他类型表的数据通过INSERT INTO SELECT语句将字段加工成BITMAP类型;在表的某些列上创建BITMAP类型的ROLLUP。
创建一张明细数据表page_visit_detail。
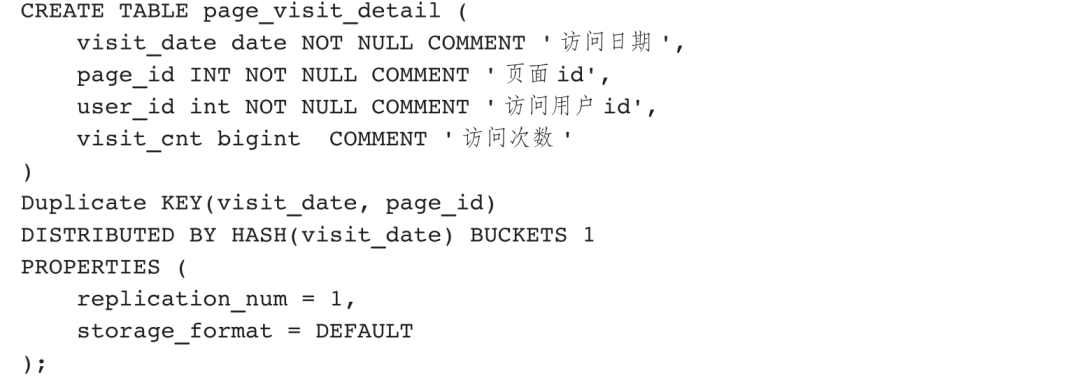
按照方式一将数据写入聚合表。

按照方式二直接在page_visit_detail表上创建一个ROLLUP。
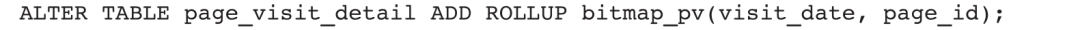
BITMAP技术除了可以在查询场景替换COUNT DISTINCT来加速去重计算以外,还可以用于用户画像场景进行用户圈选。针对用户画像场景,Doris也在逐步完善相关函数。
在现实场景中,随着数据量的增大,对数据进行去重分析的压力会越来越大。当数据规模大到一定程度时,精准去重的成本会比较高。此时用户通常会采用近似去重算法来降低计算压力。本节将要介绍的HyperLogLog(简称HLL)是一种近似去重算法,它的特点是具有非常优异的空间复杂度O(mloglogn),时间复杂度为O(n),计算结果误差可控制在1%~10%内,且误差与数据集大小以及所采用的哈希函数有关。
HLL算法是一种近似去重算法,能够使用极少的存储空间计算一个数据集的不重复元素的个数。
HLL算法是LogLog算法的升级版,作用是提供不精确的去重计数。由于HLL算法的原理涉及比较多的数学知识,这里我们仅通过一个实际例子来说明,其数学基础为伯努利试验。
硬币拥有正反两面,一次上抛至落下最终出现正反面的概率都是50%,一直抛硬币,直到出现正面为止,记录为一次完整的试验。
假设每次伯努利试验的抛掷次数为k,第一次伯努利试验次数设为k1,以此类推,第n次对应的是kn。
这n次伯努利试验中必然会有一个正面出现的最大抛掷次数k,例如抛了12次才出现正面,这被称为k_max。
伯努利试验总结得出的结论如下。
❑n重伯努利试验的投掷次数都不大于k_max。
❑n重伯努利试验过程中至少有一次投掷次数等于k_max。
最终结合极大似然估算方法,我们发现n和k_max存在估算关联:n = 2k_max,即当只记录了k_max时,可估算出总共有多少条数据,也就是基数。
假设试验结果如下:
❑第1次试验:抛了3次才出现正面,此时k=3,n=1
❑第2次试验:抛了2次才出现正面,此时k=2,n=2
❑第3次试验:抛了6次才出现正面,此时k=6,n=3
❑第n次试验:抛了12次才出现正面,此时n=212
取上面例子中前三次试验,那么k_max=6,最终n=3,代入估算关联公式,明显3≠26。也就是说,当试验次数很小的时候,这种估算方法的误差是很大的。我们称这三次试验为一轮估算。如果只是进行一轮,当n足够大时,估算误差率会相对降低,但仍然不够小。这就是HLL算法的核心思想。有兴趣的同学可以参考论文《HyperLogLog:the analysis of a near-optimal cardinality estimation algorith》。
HLL近似去重算法是保存计算过程的中间结果,并将其作为聚合表的Value列,通过聚合不断减少数据量,以此实现加快查询的目的。基于HLL算法得到的是一个估算结果,误差大概在1%。
HLL用法和BITMAP用法类似,也需要配合HLL_UNION函数构建聚合字段。以下是一个示例。
首先,创建一张含有HLL列的表,其中uv列为聚合列,列类型为HLL,聚合函数为HLL_UNION。

当数据量很大时,最好为高频率的HLL查询建立对应的ROLLUP表,语句如下:

然后使用Broker Load方式导入数据:

完成数据导入以后,我们就可以查询了。HLL列不允许直接查询它的原始值,支持用函数HLL_UNION_AGG进行查询。

GROUPING SETS最早出现在Oracle数据库中,是多维数据分析中比较常见的一个数据汇总方式,支持提前按照各种指定维度预聚合数据,通过扩展存储来提高特定组合条件下的数据查询性能。
GROUPING SETS是对GROUP BY子句的扩展,能够在一个GROUP BY子句中一次实现多个集合的分组。其查询效果等价于将多个GROUP BY子句进行UNION操作。特别地,一个空的子集意味着将所有的行聚集成一条记录。
GROUPING SETS语句模板如下:
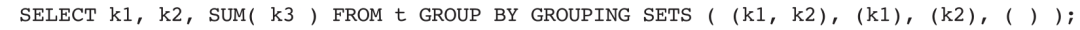
等价于:

继续以example_db.page_visit_detail为例,先插入数据:

然后执行如下SQL语句,得到的查询结果如图6-40所示。

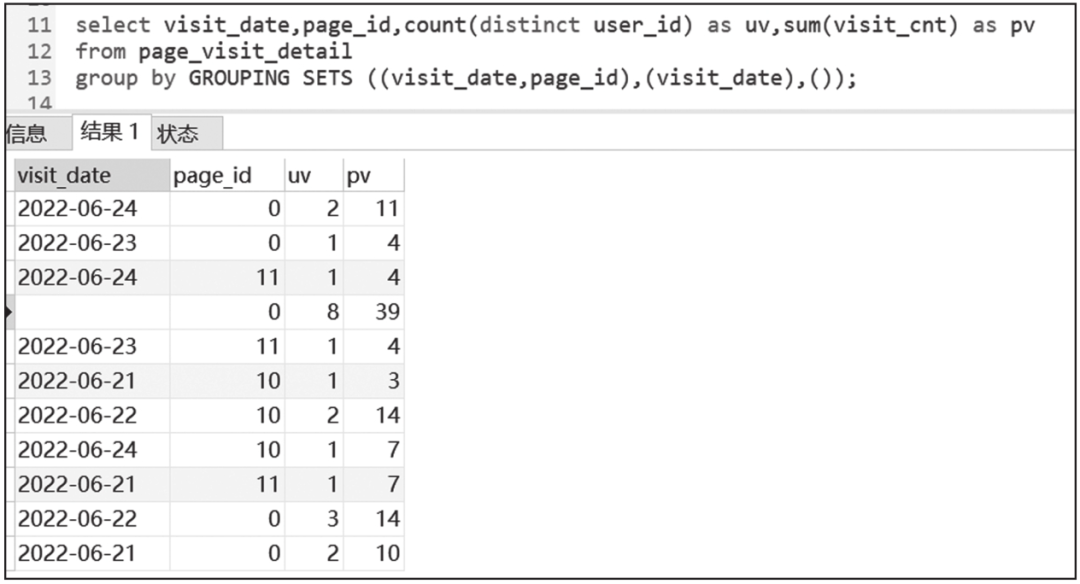
图6-40 GROUPING SETS语句执行结果
GROUPING SETS还有两个扩展子句——ROLLUP和CUBE,区别在于ROLLUP子句只会逐步减少分组字段,CUBE子句则是穷举所有可能的分组组合字段。
ROLLUP子句模板如下:

等价于:
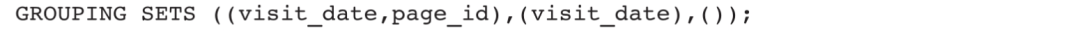
CUBE子句模板如下:

点击蓝字

关注我们
