




前面我已经分享了如何编译Flink源码,以及总结了Streaming api及Table Api 版本WordCount的源码解析。
万字长文 | 透过现象看本质 | 从WordCount 到Flink Streaming API 源码详细解读
今天我们来总结一下在不同Api模式下的WordCount执行步骤有哪些。下图展示了WordCount代码分别在Streaming API、Table API 及 SQL模式下的执行流程。整体可以分为十步,其中SQL本身不存在独立读取数据这一步,可以理解为九步。
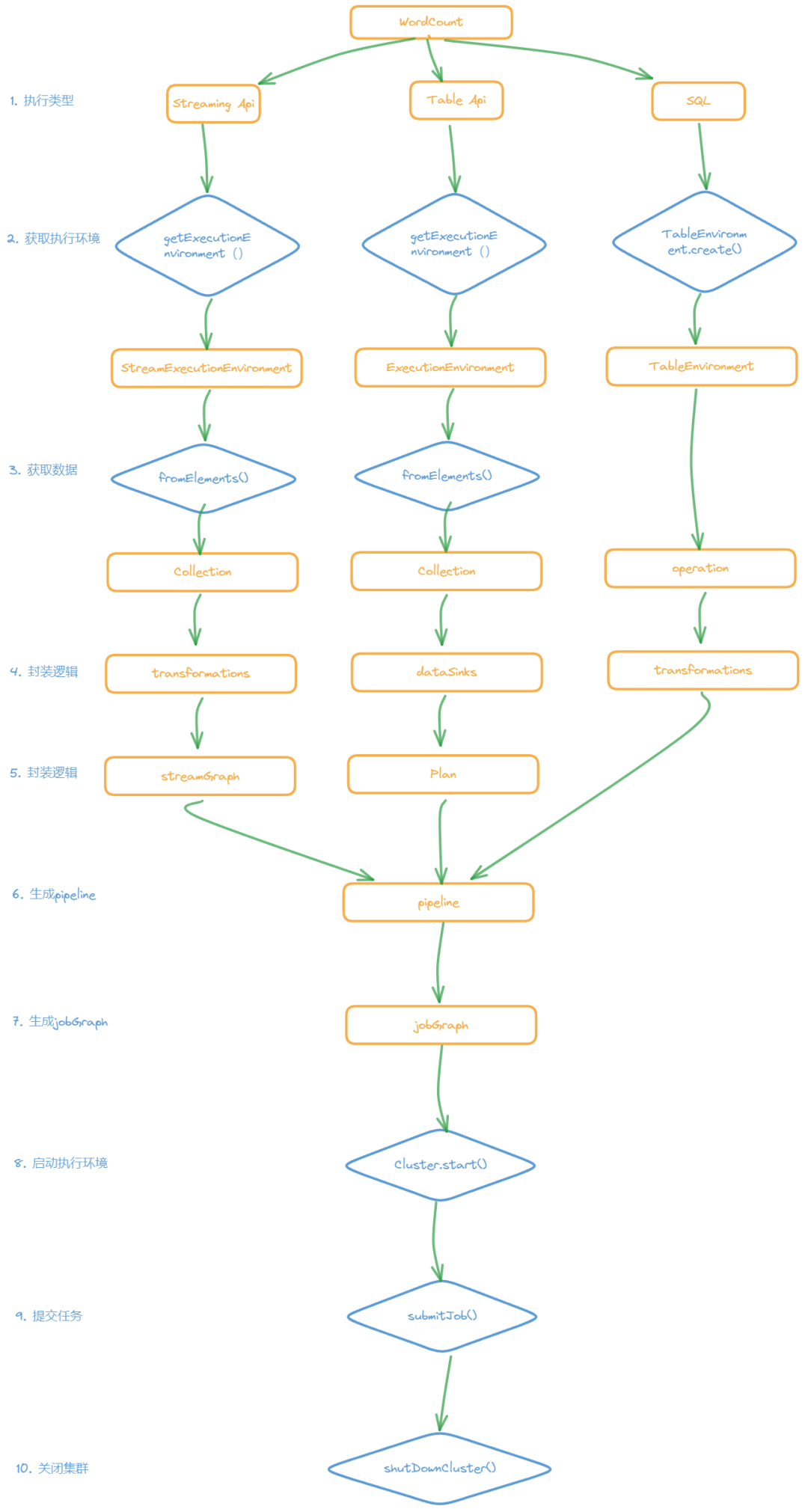
1. 确认执行模式
目前Flink1.8 可以分为 Streaming API Table API 以及 SQL 三种
2. 获取执行环境
Streaming API 会获取 StreamExcutionEnviroment
Table API 会获取 ExcutionEnvironment
SQL 会获取 TableEnviroment或者 StreamTableEnviroment
3. 获取数据
Streaming API 和 Table API 会将获取到的任何类型的数据经过一系列转换后转成Collection类型
4. 封装逻辑1
Streaming Api 所有的处理逻辑首先会被封装到tansformations对象中
Table Api 所有的处理逻辑首先都会封装到 DataSinks对象中
SQL 会被封装到 opreation 中
5. 封装逻辑2
Streaming Api 的 tansformations 会被进一步封装成 StreamGraph 对象
Table Api 的 DataSinks 会被进一步封装成 Plan 对象
SQL 的 opreation 会被 进一步封装成 tansformations 对象
6. 生成 Pipeline
在这一步,三种模式的数据处理逻辑都会统一成一种对象,就是Pipeline
7. 生成 JobGraph
Pipeline会进一步被封装成 JobGraph
8. 启动集群
这是在本地调试的步骤,如果是集群提交的话,应该就直接到下一步提交代码了,后续也不会关闭集群。
9. 提交代码
封装好的JobGraph被正式提交给集群进行运行,并返回对应的结果。
10. 关闭集群
