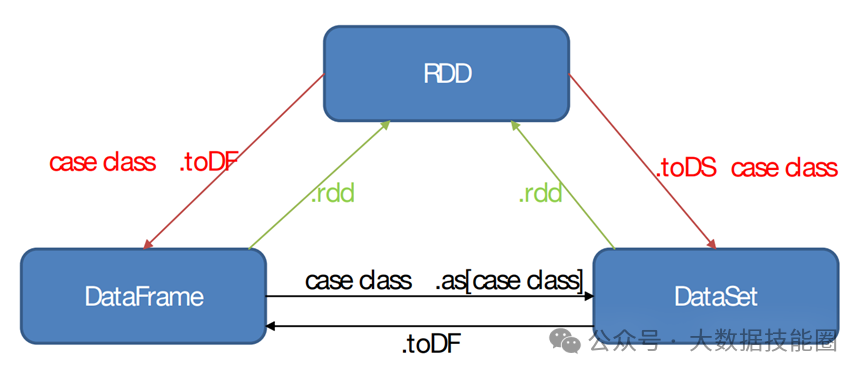
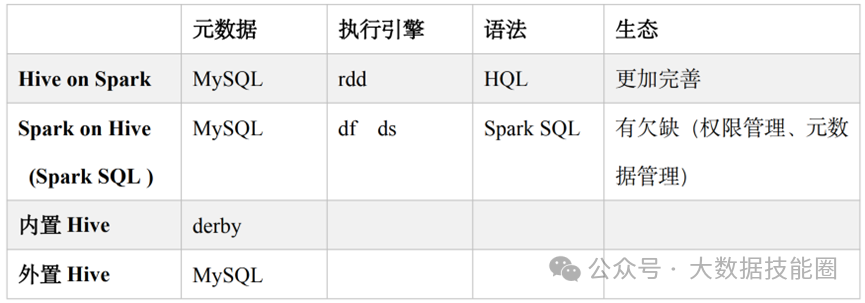
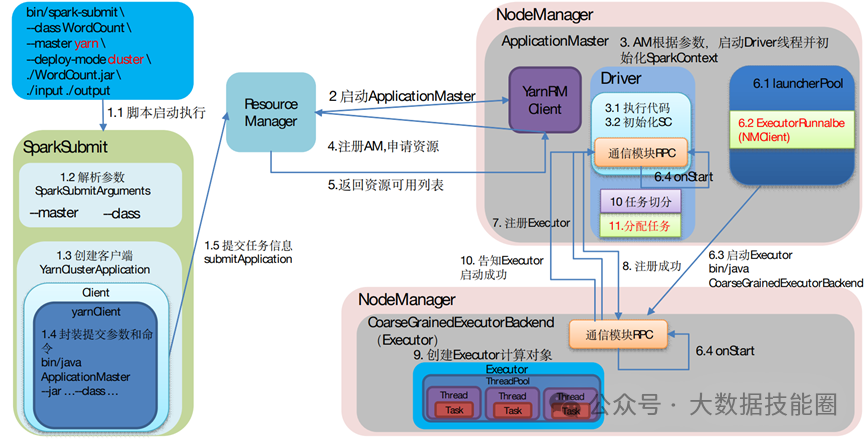
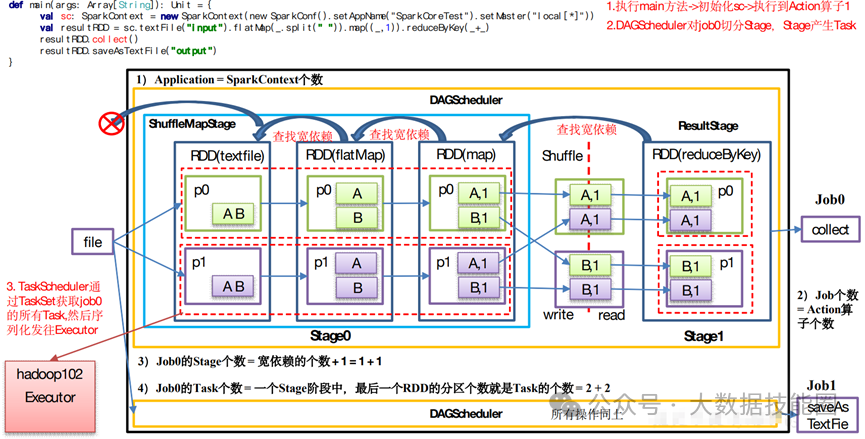
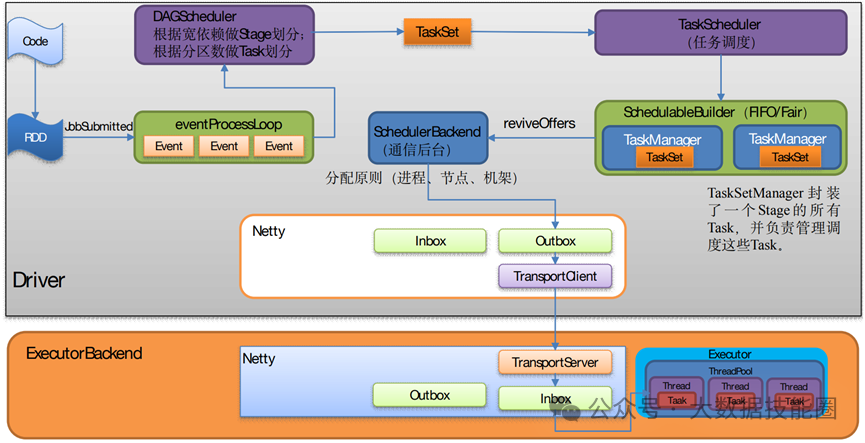
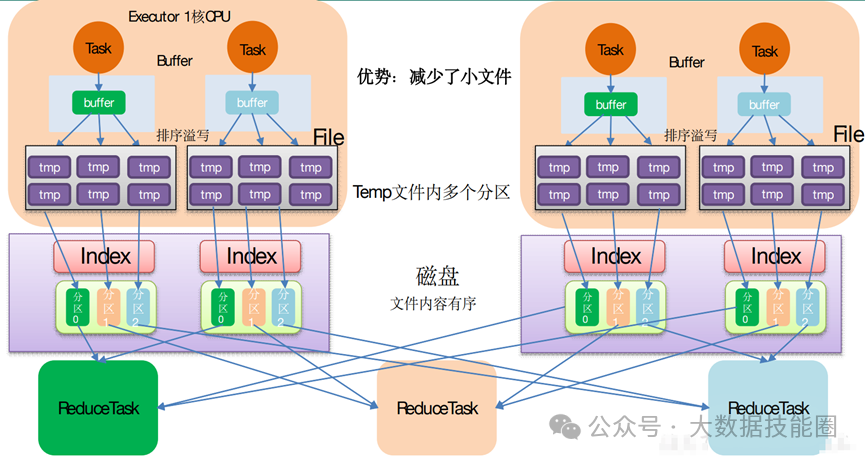
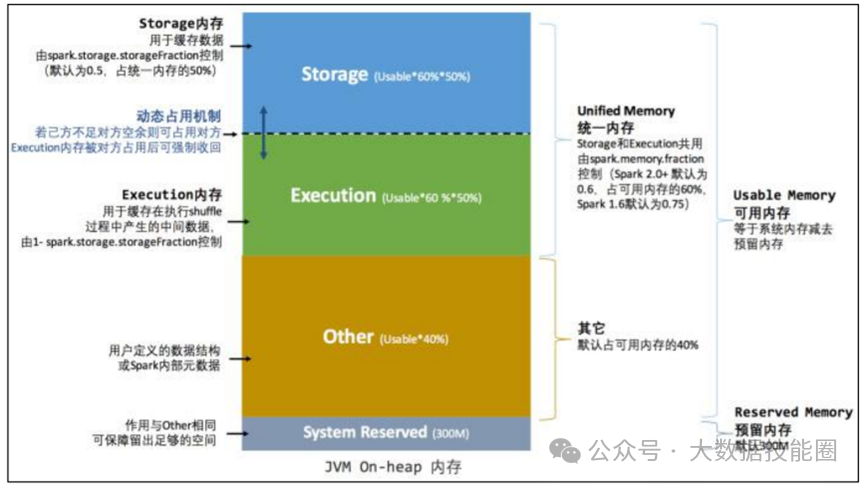
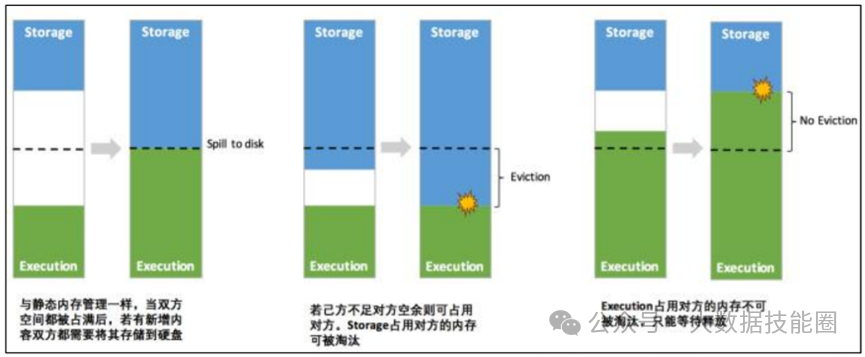
(2)Standalone:是 Spark 自身的一个调度系统。对集群性能要求非常高时用。国内很少使用。(3)Yarn:采用 Hadoop 的资源调度器。国内大量使用。Yarn-client 模式:Driver 运行在 Client 上(不在 AM 里)Yarn-cluster 模式:Driver 在 AM 上(5)K8S:趋势,但是目前不成熟,需要的配置信息太多。(2)7077 内部通讯端口。类比 Hadoop 的 8020/9000(3)8080 查看任务执行情况端口。类比 Hadoop 的 8088(4)18080 历史服务器。类比 Hadoop 的 19888注意:由于 Spark 只负责计算,所有并没有 Hadoop 中存储数据的端口 9870/50070主要表现为存储弹性、计算弹性、任务(Task、Stage)弹性、数据位置弹性,具体如 下(4)Stage 如果失败会自动进行特定次数的重试,而且只会只计算失败的分片(5)Checkpoint【每次对 RDD 操作都会产生新的 RDD,如果链条比较长,计算比较笨重,就把数据放在硬盘中】和 persist 【内存或磁盘中对数据进行复用】(检查点、持久化)(6)数据调度弹性:DAG Task 和资源管理无关(3)mapPartitionsWithIndex(2)mapPartitions:每次处理一个分区数据8 Repartition 和 Coalesce 区别两者都是用来改变 RDD 的 partition 数量的,repartition 底层调用的就是 coalesce 方法:coalesce(numPartitions, shuffle = true)repartition 一定会发生 Shuffle,coalesce 根据传入的参数来判断是否发生 Shuffle。一般情况下增大 rdd 的 partition 数量使用 repartition,减少 partition9 reduceByKey 与 groupByKey 的区别在不影响业务逻辑的前提下,优先采用 reduceByKey(1)Application:初始化一个 SparkContext 即生成一个 Application(2)Job:一个 Action 算子就会生成一个 Job(3)Stage:Stage 等于宽依赖的个数加 1(4)Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。12 SparkSQL 中 RDD、DataFrame、DataSet 三者的转换及区别DataFrame 和 DataSet 的区别:前者是 row 类型RDD 和 DataFrame 及 DataSet 的区别:前者没有字段和表信息13 Hive on Spark 和 Spark on Hive 区别(1)SortShuffle:减少了小文件。中间落盘应该是本地磁盘生成的文件数在溢写磁盘前,先根据 key 进行排序,排序过后的数据,会分批写入到磁盘文件中。默 认批次为 10000 条,数据会以每批一万条写入到磁盘文件。写入磁盘文件通过缓冲区溢写的 方式,每次溢写都会产生一个磁盘文件,也就是说一个 Task 过程会产生多个临时文件。最 后在每个 Task 中,将所有的临时文件合并,这就是 merge 过程,此过程将所有临时文件读取出来,一次写入到最终文件。(4)bypassShuffle:减少了小文件,不排序,效率高。在不需要排序的场景使用。(1)MR 在 Map 阶段会在溢写阶段将中间结果频繁的写入磁盘,在 Reduce 阶段再从 磁盘拉取数据。频繁的磁盘 IO 消耗大量时间(2)Spark 不需要将计算的中间结果写入磁盘。这得益于 Spark 的 RDD,在各个 RDD的分区中,各自处理自己的中间结果即可。在迭代计算时,这一优势更为明显。2)Spark DAG 任务划分减少了不必要的 Shuffle(1)对 MR 来说,每一个 Job 的结果都会落地到磁盘。后续依赖于次 Job 结果的 Job, 会从磁盘中读取数据再进行计算(2)对于 Spark 来说,每一个 Job 的结果都可以保存到内存中,供后续 Job 使用。配 合 Spark 的缓存机制,大大的减少了不必要的 Shuffle(1)MR 任务以进程的方式运行在 Yarn 集群中。N 个 MapTask 就要申请 N 个进程(2)Spark 的任务是以线程的方式运行在进程中。N 个 MapTask 就要申请 N 个线程。17 Spark Shuffle 和 Hadoop Shuffle 区别(1)Hadoop 不用等所有的 MapTask 都结束后开启 ReduceTask;Spark 必须等到父 Stage 都完成,才能去 Fetch 数(2)Hadoop 的 Shuffle 是必须排序的,那么不管是 Map 的输出,还是 Reduce 的输出, 都是分区内有序的,而 Sparkk 不要求这一点executor-cores —— 每个 executor 使用的内核数,默认为 1,官方建议 2-5 个,我们企业是 4 个num-executors —— 启动 executors 的数量,默认为 2
executor-memory —— executor 内存大小,默认 1G
driver-cores —— driver 使用内核数,默认为 1
driver-memory —— driver 内存大小,默认 512M
spark-submit
--master local[5] \ --driver-cores 2 \ --driver-memory 8g \ --executor-cores 4 \ --num-executors 10 \ --executor-memory 8g \ --class PackageName.ClassName XXXX.jar \ --name "Spark Job Name" \
InputPath \
OutputPath
19 Spark 任务使用什么进行提交,JavaEE 界面还是脚本Shell 脚本。海豚调度器可以通过页面提交 Spark 任务20 Spark 操作数据库时,如何减少 Spark 运行中的数据库连接数?使用 foreachPartition 代替 foreach,在 foreachPartition 内获取数据库的连接。