




 点击蓝字,关注我们
点击蓝字,关注我们
▍作者:张奇 蚂蚁集团图计算高级工程师
众所周知,当我们需要对数据做关联性分析的时候,一般会采用表连接(SQL join)的方式完成。但是 SQL join 时的笛卡尔积计算需要维护大量的中间结果,从而对整体的数据分析性能带来巨大影响。相比而言,基于图的方式维护数据的关联性,原本的关联性分析可以转换为图上的遍历操作,从而大幅降低数据分析的成本。
1、图计算
图是一种数学结构,由节点和边组成。节点代表各种实体,比如人、地点、事物或概念,而边则表示这些节点之间的关系。例如:
社交媒体:节点可以代表用户,边可以表示朋友关系。
网页:节点代表网页,边代表超链接。
交通网络:节点代表城市,边代表道路或航线。
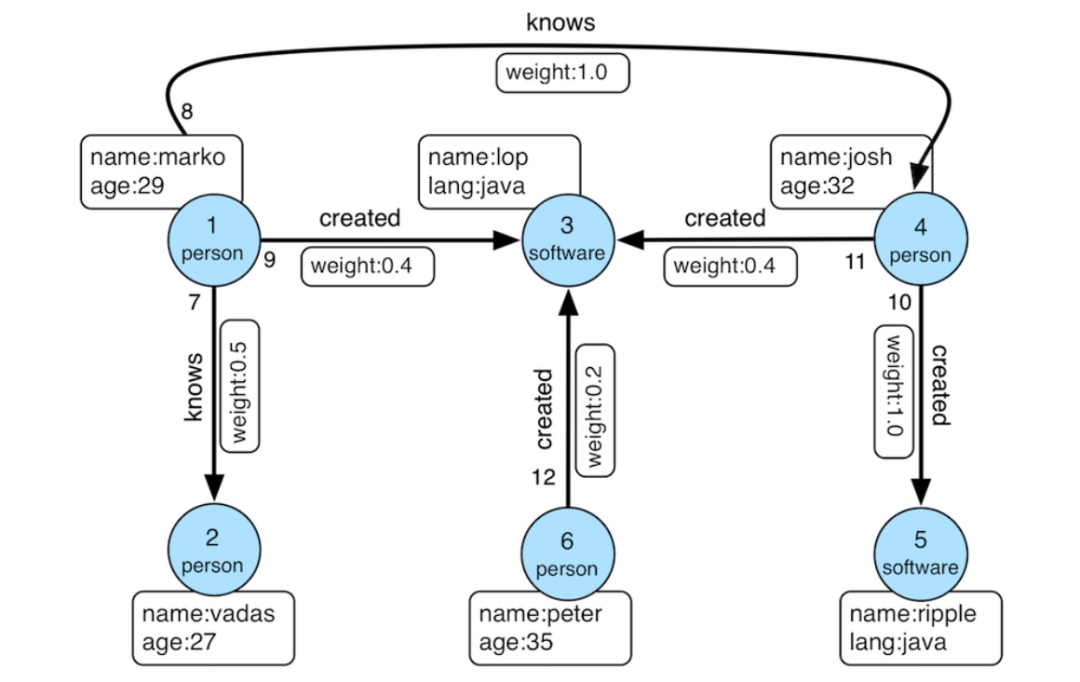
图本身代表了节点与节点之间的链接关系,而针对这些关系,我们可以利用图中的节点和边来进行信息处理、分析和挖掘,帮助我们理解复杂系统中的关系和模式。在图上开展的计算活动就是图计算。图计算有很多应用场景,比如通过社交网络分析可以识别用户之间的联系,发现社群结构;通过分析网页间的链接关系来计算网页排名;通过用户的行为和偏好构建关系图,推荐相关内容和产品。
我们就以简单的社交网络分析算法,弱联通分量(Weakly Connected Components, WCC)为例。弱联通分量可以帮助我们识别用户之间的“朋友圈”或“社区”,比如某个社交平台上,一群用户通过点赞、评论或关注形成一个大的弱联通分量,而某些用户可能没有连接到这个大分量,形成更小的弱联通分量。
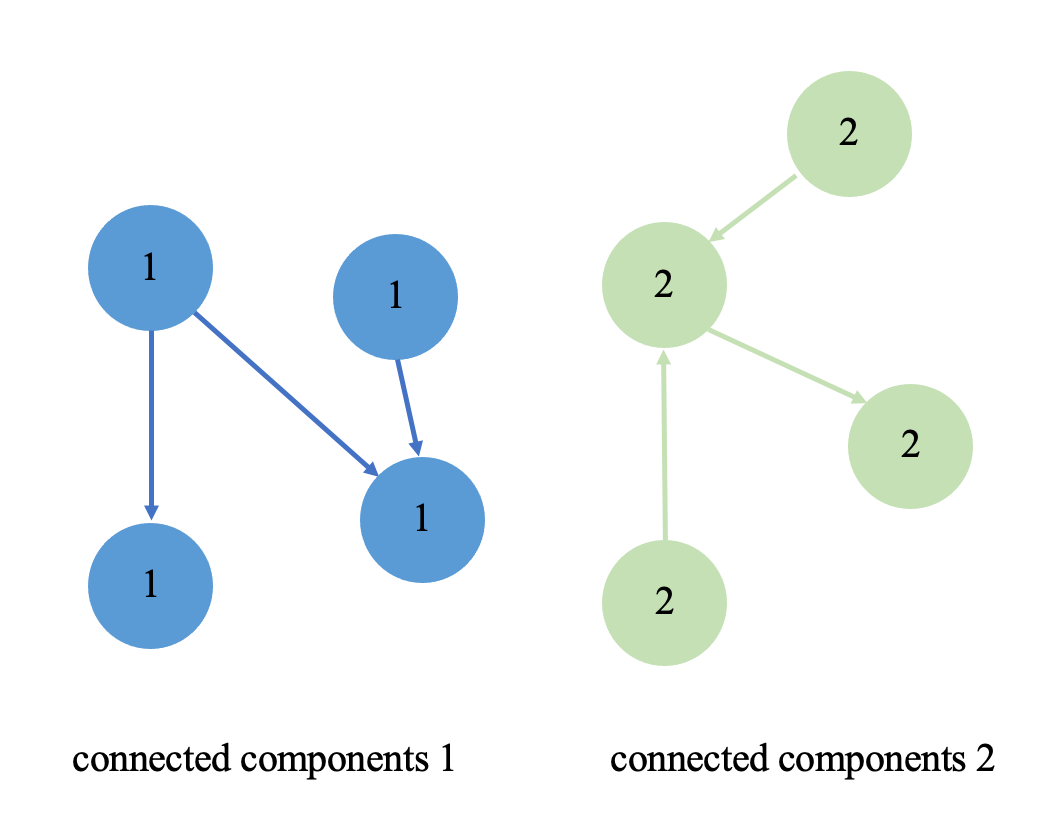
如果仅仅针对上面这张小图来构建弱联通分量算法,那么非常简单,我们只需要在个人 PC 上构建简单的点边结构然后走图遍历即可。但如果图的规模扩展的千亿甚至万亿,这时就需要用到大规模分布式图计算引擎来处理了。
2、分布式图计算:Spark GraphX
针对图的处理一般有图计算引擎和图数据库两大类,图数据库有 Neo4j、TigerGraph 等,图计算引擎有 Spark GraphX、Pregel 等。在本文我们主要讨论图计算引擎,以 Spark GraphX 为例,Spark GraphX 是 Apache Spark 的一个组件,专门用于图计算和图分析。GraphX 结合了 Spark 的强大数据处理能力与图计算的灵活性,扩展了 Spark 的核心功能,为用户提供了一个统一的 API,便于处理图数据。
那么在 Spark GraphX 上是如何处理图算法的呢?GraphX 通过引入一种点和边都附带属性的有向多图扩展了 Spark RDD 这种抽象数据结构,为用户提供了一个类似于 Pregel 计算模型的以点为中心的并行抽象。用户需要为 GraphX提供原始图 graph、初始消息 initialMsg、核心计算逻辑 vprog、发送消息控制组件 sendMsg、合并消息组件 mergeMsg,计算开始时,GraphX 初始阶段会激活所有点进行初始化,然后按照用户提供的发送消息组件确定接下来向哪些点发送消息。在之后的迭代里,只有收到消息的点才会被激活,进行接下来的计算,如此循环往复直到链路中没有被新激活的点或者到达最大迭代次数,最后输出计算结果。
def apply[VD: ClassTag, ED: ClassTag, A: ClassTag](graph: Graph[VD, ED],initialMsg: A,maxIterations: Int = Int.MaxValue,activeDirection: EdgeDirection = EdgeDirection.Either)(vprog: (VertexId, VD, A) => VD,sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexId, A)],mergeMsg: (A, A) => A): Graph[VD, ED]{var g = graph.mapVertices((vid, vdata) => vprog(vid, vdata, initialMsg))// compute the messagesvar messages = GraphXUtils.mapReduceTriplets(g, sendMsg, mergeMsg)// Loopvar prevG: Graph[VD, ED] = nullvar i = 0while (isActiveMessagesNonEmpty && i < maxIterations) {// Receive the messages and update the vertices.prevG = gg = g.joinVertices(messages)(vprog)graphCheckpointer.update(g)// Send new messages, skipping edges where neither side received// a message.messages = GraphXUtils.mapReduceTriplets(g, sendMsg, mergeMsg, Some((oldMessages, activeDirection)))}}
总的来说,用户首先需要将存储介质中原始的表结构数据转换为 GraphX 中的点边数据类型,然后交给 Spark 进行处理,这是针对静态图进行离线处理。但是我们知道,现实世界中,图数据的规模和数据内节点之间的关系都不是一成不变的,并且在大数据时代其变化非常快。如何实时高效地处理不断变化的图数据(动态图),是一个值得深思的问题。
3、动态图计算:Spark Streaming
针对动态图的处理,常见的解决方案是 Spark Streaming 框架,它可以从很多数据源消费数据并对数据进行处理。它是是 Spark 核心 API 的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。
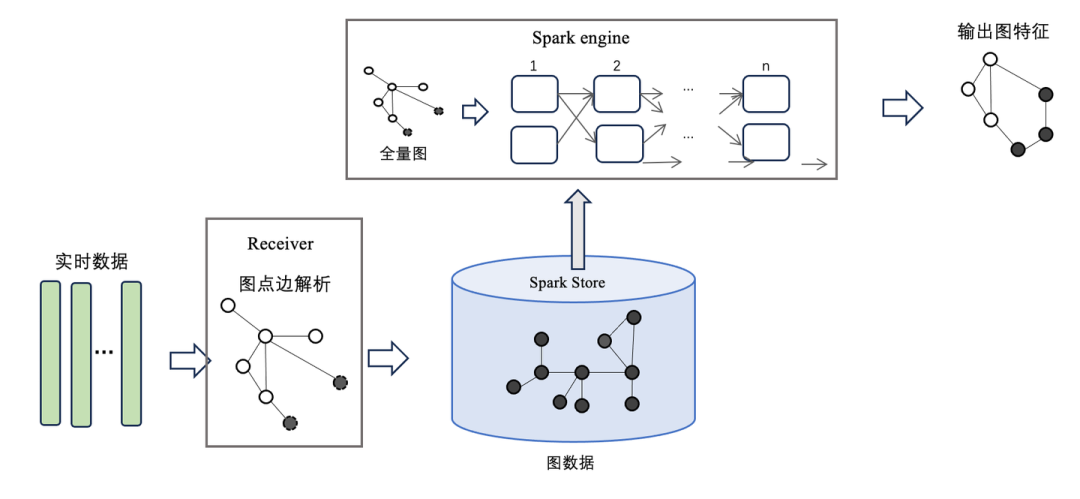
如上图所示是 Spark Streaming 对实时数据进行处理的流程。首先 Spark 中的每个 Receiver 接收到实时消息流后,对实时消息进行解析和切分,之后将生成的图数据存储在每个 Executor 中。每当数据累积到一定的批次,就会触发一次全量计算,最后将计算出的结果输出给用户,这也称之为基于快照的图计算方案。
但这种方案有一个比较大的缺点,就是它存在着重复计算的问题,假如我们需要以1小时一个窗口做一次计算,那么在使用 Spark 进行计算时,不仅要将当前窗口的数据计算进去,历史所有数据也需要进行回溯,存在大量重复计算,这样做效率不高,因此我们需要一套能够进行增量计算的图计算方案。
4、动态图增量计算:GeaFlow
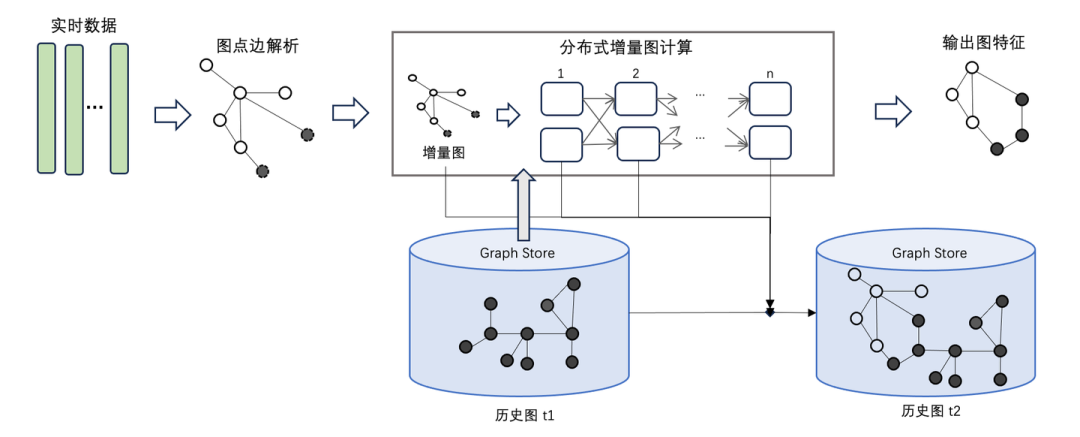
我们知道在传统的流计算引擎中,如 Flink,其处理模型允许系统能够处理不断流入的数据事件。处理每个事件时,Flink 可以评估变化并仅针对变化的部分执行计算。这意味着在增量计算过程中,Flink 会关注最新到达的数据,而不是整个数据集。于是受到 Flink 增量计算的启发,我们自研了增量图计算系统GeaFlow(也叫流图计算引擎),能够很好的支持增量图迭代计算。
那么 GeaFlow 是如何实现增量图计算的呢?首先,实时数据通过 connector 消息源输入的 GeaFlow 中,GeaFlow 依据实时数据,生成内部的点边结构数据,并且将点边数据插入进底图中。当前窗口的实时数据涉及到的点会被激活,触发图迭代计算。
这里以 WCC 算法为例,对联通分量算法而言,在一个时间窗口内每条边对应的 src id 和 tar id 对应的顶点会被激活,第一次迭代需要将其 id 信息通知其邻居节点。如果邻居节点收到消息后,发现需要更新自己的信息,那么它需要继续将更新消息通知给它的邻居节点;如果说邻居节点不需要更新自己的信息,那么它就不需要通知其邻居节点,它对应的迭代终止。
5、GeaFlow 架构简析
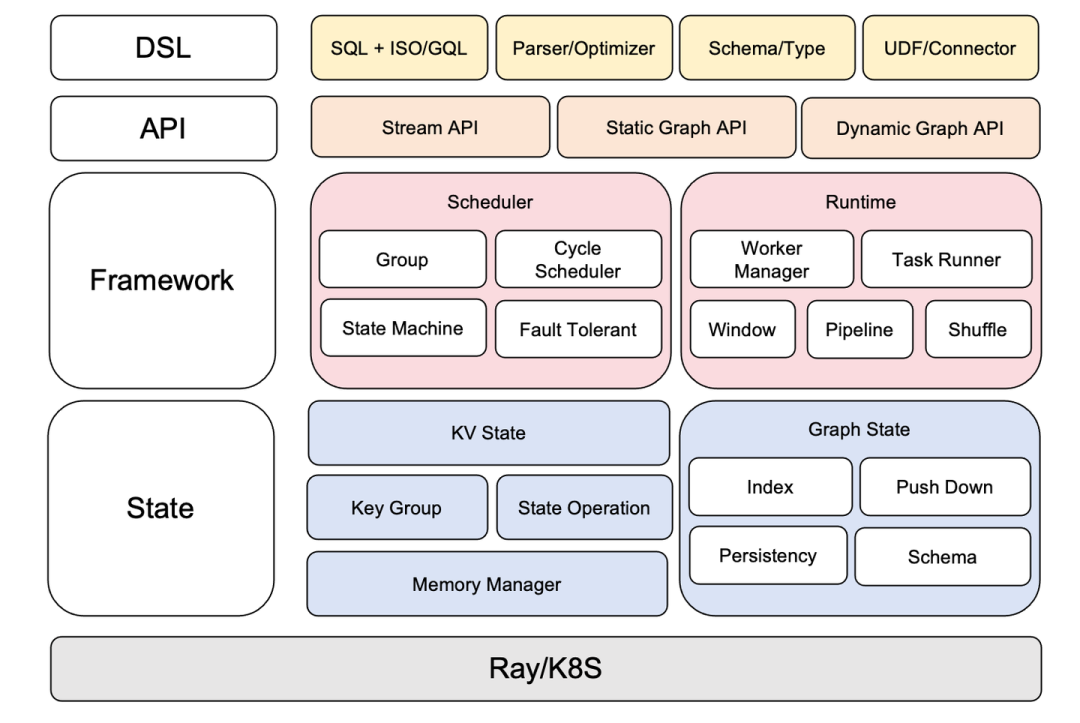
GeaFlow 引擎主要由三大主要部分组成,DSL、Framework 和 State,同时向上为用户提供了 Stream API、静态图 API 和动态图 API。DSL 主要负责图查询语言 SQL+ISO/GQL 的解析和执行计划的优化,同时负责 schema 的推导,也向外部承接了多种 Connector,比如 hive、hudi、kafka、odps 等。Framework 层负责运行时的调度和容灾,shuffle 以及框架内各个组件的管理协调。State 层负责存储底层图数据和数据的持久化,同时也负责索引、下推等众多性能优化工作。
6、GeaFlow 性能测试
为了验证 GeaFlow 的增量图计算性能,我们设计了这样的实验。一批数据按照固定时间窗口实时输入到计算引擎中,我们分别用 Spark 和 GeaFlow 对全图做联通分量算法计算,比较两者计算耗时。实验在3台24核内存128G 的机器上开展,使用的数据集是公开数据集 soc-Livejournal,测试的图算法是弱联通分量算法。我们以50w 条数据作为一个计算窗口,每输入到引擎中50w 条数据,就触发一次图计算。
Spark 作为批处理引擎,对于每一批窗口来的数据,不管窗口规模是大是小,都需要对增量图数据连同历史图数据进行全量计算。在 Spark 上,可以直接调用 Spark GraphX 内部内置的 WCC 算法进行计算。
object SparkTest {def main(args: Array[String]): Unit = {val iter_num: Int = args(0).toIntval parallel: Int = args(1).toIntval spark = SparkSession.builder.appName("HDFS Data Load").config("spark.default.parallelism", args(1)).getOrCreateval sc = new JavaSparkContext(spark.sparkContext)val graph = GraphLoader.edgeListFile(sc, "hdfs://rayagsecurity-42-033147014062:9000/" + args(2), numEdgePartitions = parallel)val result = graph.connectedComponents(10)handleResult(result)print("finish")}def handleResult[VD, ED](graph: Graph[VD, ED]): Unit = {graph.vertices.foreachPartition(_.foreach(tuple => {}))}}
GeaFlow 上支持 SQL+ISO/GQL 的图查询语言,我们使用图查询语言调用 GeaFlow 内置的增量联通分量图算法进行测试,图查询语言代码如下:
CREATE TABLE IF NOT EXISTS tables (f1 bigint,f2 bigint) WITH (type='file',geaflow.dsl.window.size='16000',geaflow.dsl.column.separator='\t',test.source.parallel = '32',geaflow.dsl.file.path = 'hdfs://xxxx:9000/com-friendster.ungraph.txt');CREATE GRAPH modern (Vertex v1 (id int ID),Edge e1 (srcId int SOURCE ID,targetId int DESTINATION ID)) WITH (storeType='memory',shardCount = 256);INSERT INTO modern(v1.id, e1.srcId, e1.targetId)(SELECT f1, f1, f2FROM tables);INSERT INTO modern(v1.id)(SELECT f2FROM tables);CREATE TABLE IF NOT EXISTS tbl_result (vid bigint,component bigint) WITH (ignore='true',type ='file');use GRAPH modern;INSERT INTO tbl_resultCALL inc_wcc(10) YIELD (vid, component)RETURN vid, component;
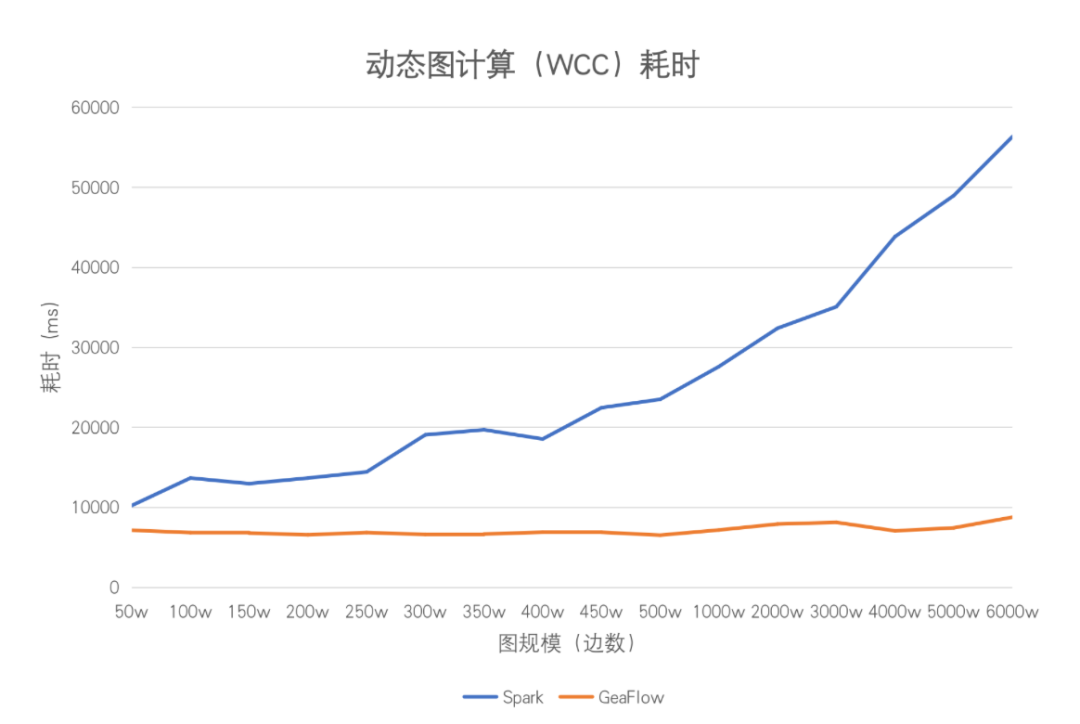
下图是对两者进行联通分量算法实验时得到的实验结果。以50w 条数据为一个窗口进行迭代计算,Spark 中存在大量的重复计算,因为其还要回溯全量的历史数据进行计算。而 GeaFlow 只会激活当前窗口中涉及到的点边进行增量计算,计算可在秒级别完成,每个窗口的计算时间基本稳定。随着数据量的不断增大,Spark 进行计算时所需要回溯的历史数据就越多,在其机器容量没有达到上限的情况下,其计算时延和数据量呈正相关分布。相同情况下 GeaFlow 的计算时间也会略微增大,但基本可以在秒级别完成。
7、总结
传统的图计算方案(如 Spark GraphX)在近实时场景中存在重复计算问题,受 Flink 流处理模型和传统图计算的启发,我们给出了一套能够支持增量图计算的方案。总的来说 GeaFlow 主要有以下几个方面的优势:
1、GeaFlow 在处理增量实时计算时,性能优于 Spark Streaming + GraphX 方案,尤其是在大规模数据集上。
2、GeaFlow 通过增量计算避免了全量数据的重复处理,计算效率更高,计算时间更短性能不明显下降
3、GeaFlow 支持 SQL+GQL 混合处理语言,更适合开发复杂的图数据处理任务。
GeaFlow 项目代码已全部开源,我们完成了部分流图引擎基础能力的构建,未来希望基于 GeaFlow 构建面向图数据的统一湖仓处理引擎,以解决多样化的大数据关联性分析诉求。同时我们也在积极筹备加入 Apache 基金会,丰富大数据开源生态,因此非常欢迎对图技术有浓厚兴趣同学加入社区共建。
社区中有诸多有趣的工作尚待完成,你可以从如下简单的「Good First Issue」开始,期待你加入同行。
支持 Paimon Connector 插件,连接数据湖生态。(Issue 361)
优化 GQL match 语句性能。(Issue 363)
新增 ISO/GQL 语法,支持 same 谓词。(Issue 368)
...
参考链接:
1、GeaFlow项目地址:https://github.com/TuGraph-family/tugraph-analytics
2、soc-Livejournal数据集地址:https://snap.stanford.edu/data/soc-LiveJournal1.html
3、GeaFlow Issues:https://github.com/TuGraph-family/tugraph-analytics/issues
·END·

欢迎关注TuGraph代码仓库✨
https://github.com/tugraph-family/tugraph-db
https://github.com/tugraph-family/tugraph-analytics
