开篇语:这些年做的项目很多,一直很忙,很少将实战中的一些所思所想进行提炼总结,从今日起,付之行动。
理论少讲,直接上干货,按步骤操作就可以操作。
一、环境规划
1.1、操作系统
Linux ubuntu2204 5.15.0-119-generic #129-Ubuntu SMP
Fri Aug 2 19:25:20 UTC 2024 x86_64 x86_64 x86_64 GNU/Linux |
注:主从库尽量保持一致。
1.2、数据库版本
mysql Ver
8.0.39-0ubuntu0.22.04.1 for Linux on x86_64 ((Ubuntu)) |
注:主从库尽量保持一致。
1.3、存储规划
项目 | 项目值 | 备注 |
数据库配置文件目录 | /etc/mysql | 按实际调整 |
数据库数据存储目录 | /var/lib/mysql | 按实际调整 |
数据库日志文件目录 | /var/log/mysql | 按实际调整 |
数据库启动脚本目录 | /etc/systemd/system | /etc/init.d |
注:主从库尽量保持一致。
1.4、IP地址
服务器 | 主机名 | IP地址 | 端口号 | 备注 |
主库 | Master | 192.168.56.18 | 3306 | 按实际调整 |
从库 | Slave | 192.168.56.19 | 3306 | 按实际调整 |
1.5、主从复制数据库初始化方式
本次采用MYSQLDUMP对主库进行逻辑备份,然后在从库上进行还原的方式进行主从复制初始化工作。
当然也可以通过XTRABACKUP进行主库物理备份,然后在从库上进行还原的方式进行主从复制初始化工作。
也可以通过clone技术在线搭建主从复制环境。
在后续的文章中会逐一介绍。
1.6、主从复制机制
本次采用基于row的模式对主库进行同步复制到备库。
当然也可以通过statement、mixed、GTID等复制方式进行主从同步,在后续的文章中会逐一介绍。
1.7、主从复制模式
本次采用默认的复制模式,异步复制,主服务器提交事务后立即返回,而不等待从服务器确认。
当然也可以设置为半同步复制,完全同步复制模式,在后续的文章中会逐一介绍。
1.8、数据库参数
参数名 | 主库 | 从库 | 备注 |
basedir | |||
datadir | |||
character-set-server | utf8mb4 | utf8mb4 | |
lower-case-table-names | 1 | 1 | |
default_authentication_plugin | mysql_native_password | mysql_native_password | |
server-id | 1 | 2 | |
log-bin | mysql-bin | mysql-bin | |
binlog-ignore | sys,mysql, information_schema,performance_schema | sys,mysql, information_schema,performance_schema | 可逗号分隔,也可写多条 |
binlog-do-db | mydb | mydb | 多数据库写多条 |
replication-do-table | |||
replication-ignore-table | 格式:库名.表名 | 格式:库名.表名 | 多表写多条 |
binlog_format | row | row | |
relay-log | mysql-relay | mysql-relay | |
log-error | /var/log/mysql/error.log | /var/log/mysql/error.log | |
port | 3306 | 3306 | |
expire_logs_days | 14 | 14 | |
slow_query_log | 1 | 1 | |
slow_query_log_file | /var/log/mysql/mysql-slow.log | /var/log/mysql/mysql-slow.log | |
long_query_time | 2 | 2 | |
max_binlog_size | 100M | 100M | |
read-only | 0 | 1 |
二、配置步骤
2.1、主库侧按照上表进行数据库参数设置
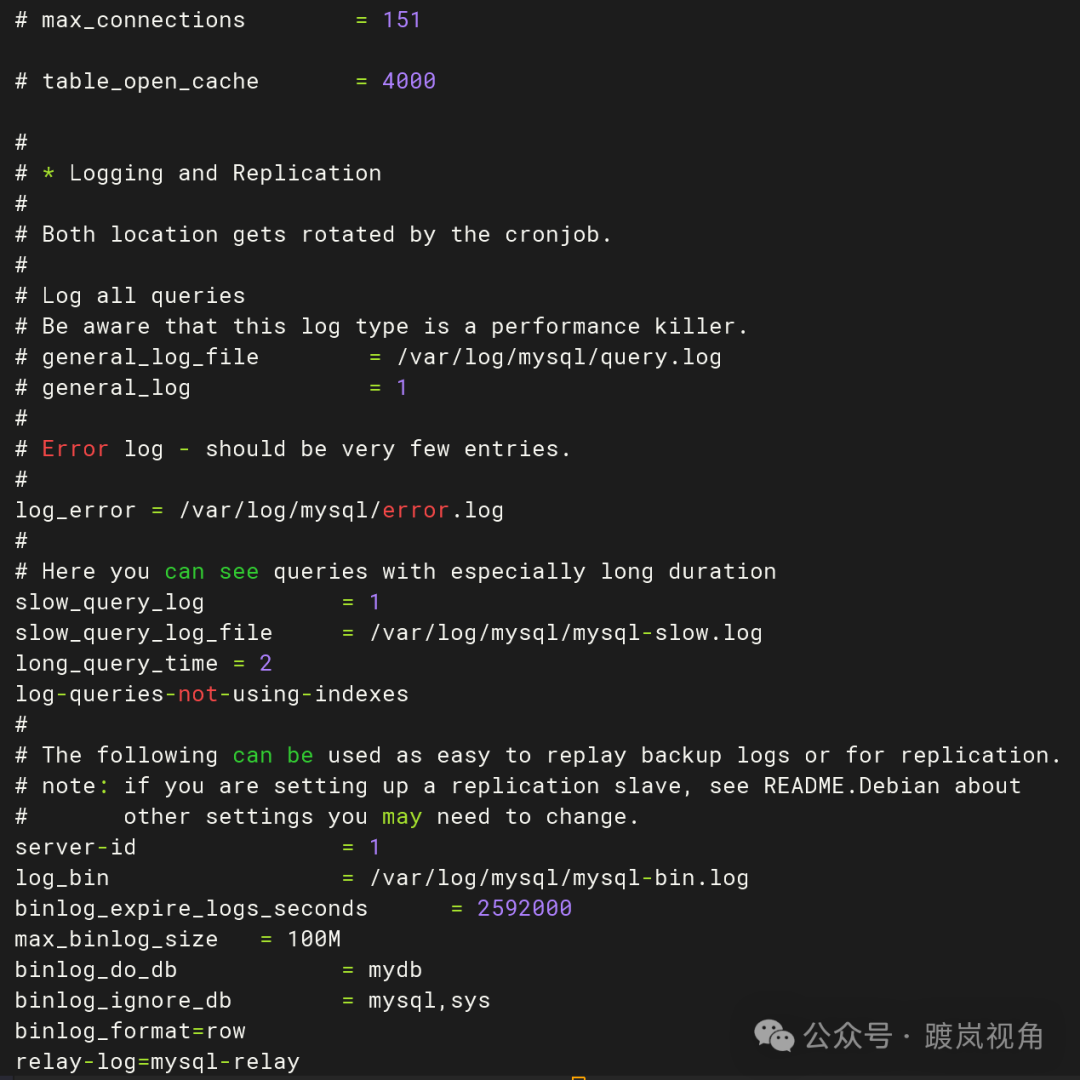
2.2、从库侧按照上表进行数据库参数设置
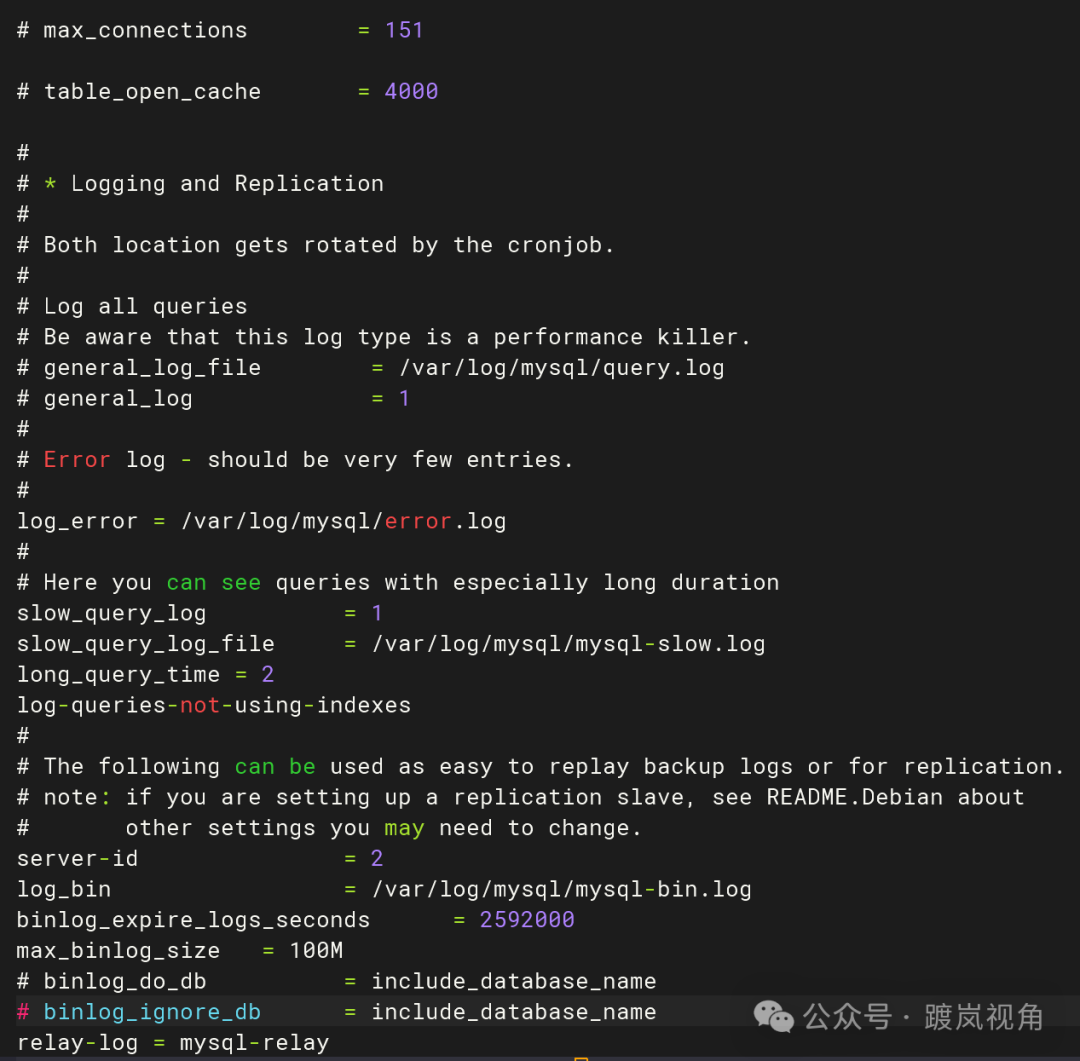
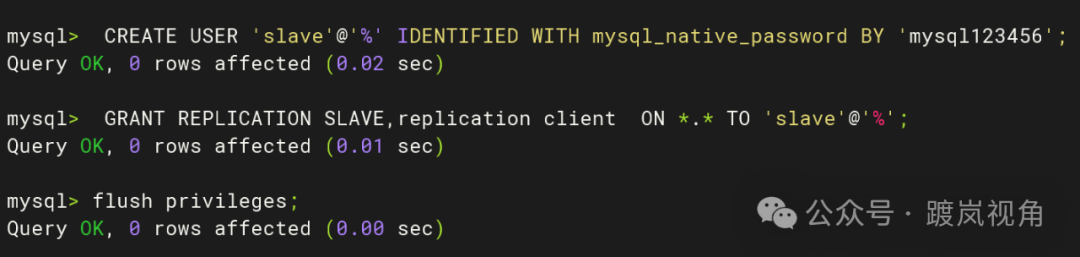
2.3、主库侧创建同步专属账号并授权
CREATE USER 'slave'@'%' IDENTIFIED WITH
mysql_native_password BY 'mysql123456'; GRANT REPLICATION SLAVE,replication client ON *.* TO 'slave'@'%'; flush privileges; |
2.4、主从侧数据库重启
主库:systemctl restart mysql 从库:systemctl restart mysql |
2.5、对主库进行备份并拷贝至从库
2.5.1、主库没有业务数据是新库时
可以直接跳过本步骤,直接执行下一步;
2.5.2、主库已有业务数据且正在运行时
2.5.2.1、主库开启锁表模式,防止备份期间数据写入
flush tables with
read lock; |
2.5.2.2、备份需要同步的数据库
mysqldump --lock-all-tables --all-databases
--flush-logs --master-data=2 > root/allsql.sql lock-all-tables:锁表 all-databases:备份所有库 flush-logs:切换日志 master-data:备份文件记录日志及位置 |
2.5.2.3、将备份文件拷贝至从库
scp allsql.sql root@192.168.56.19:/tmp |
2.5.2.4、在从库侧进行数据库恢复
mysqldump -uroot -p -A > allsql.sql 这种方式就是数据库恢复时间比较长,后期会介绍利用Xtrabackup、GTID或clone方式来进行同步。 |
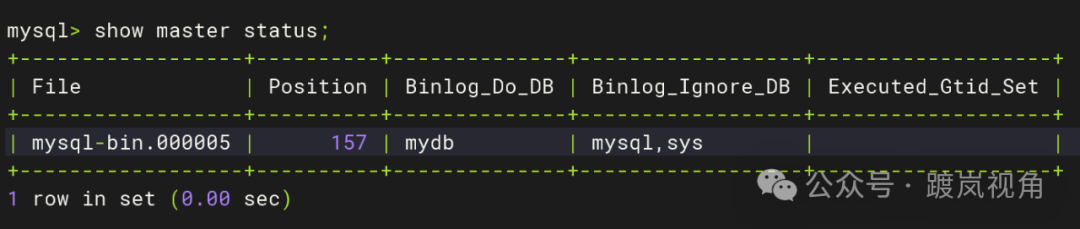
2.6、查看主库的偏移量|二进制文件名
2.6.1、主库没有业务数据查看方式
show master status; |
2.6.2、从库通过备份恢复初始化查看方式
head -n 30 allsql.sql 找到CHANGE
MASTER TO条目,记录下binlog和pos信息; |
2.7、在从库执行同步配置
change master to master_host='192.168.56.18',master_user='slave',master_password='mysql123456',master_log_file='binlog.000005',master_log_pos=157; master_host为主服务器的ip; master_user为连接主服务器的用户名; master_password为连接主服务器的密码; master_log_file为要同步的日志文件file,即对应上面主服务器查看时的File字段; master_log_pos为要同步日志文件的位置,即对应上面主服务器查看时的Position字段; |
2.8、在从库侧开启同步slave进程
start slave; |

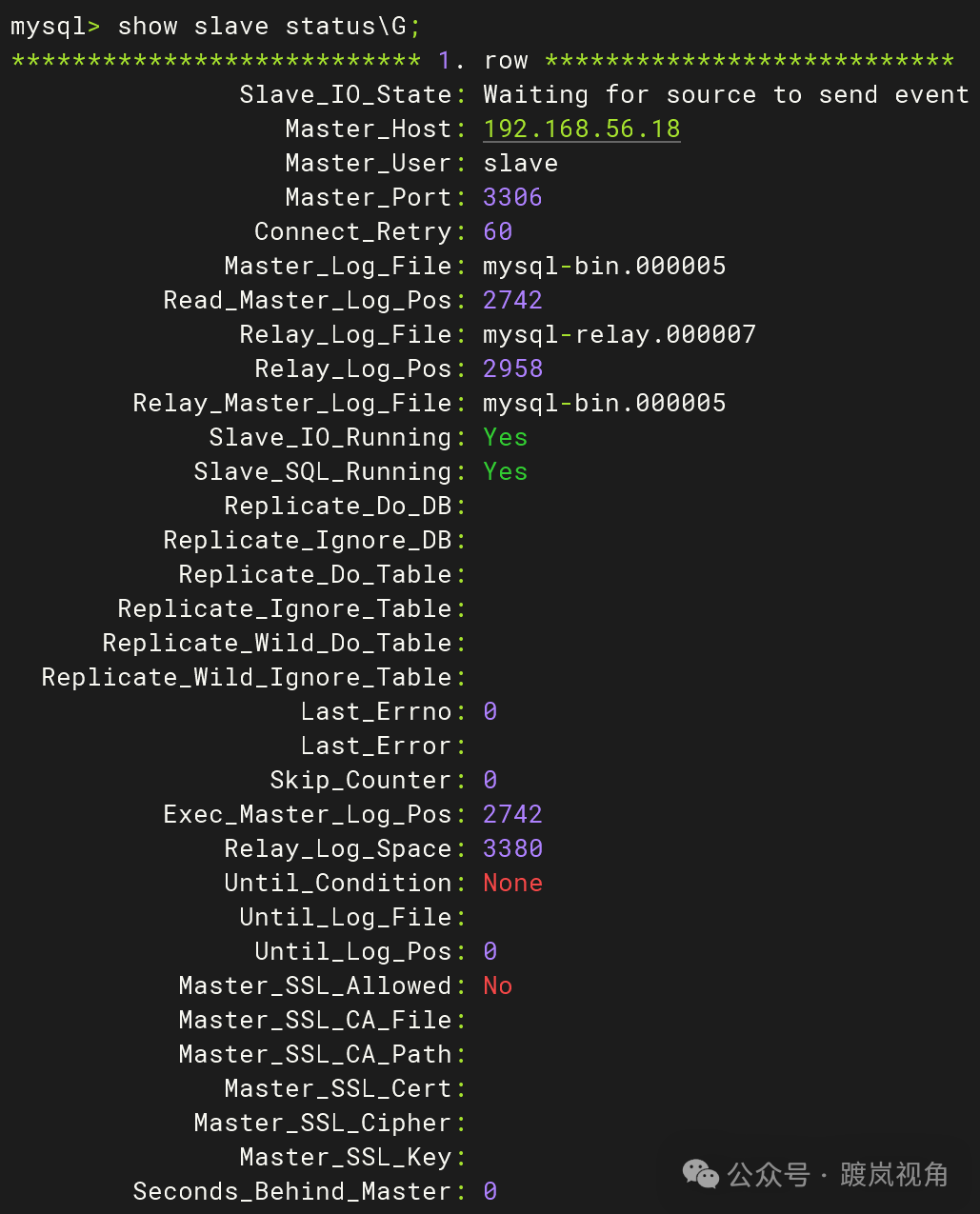
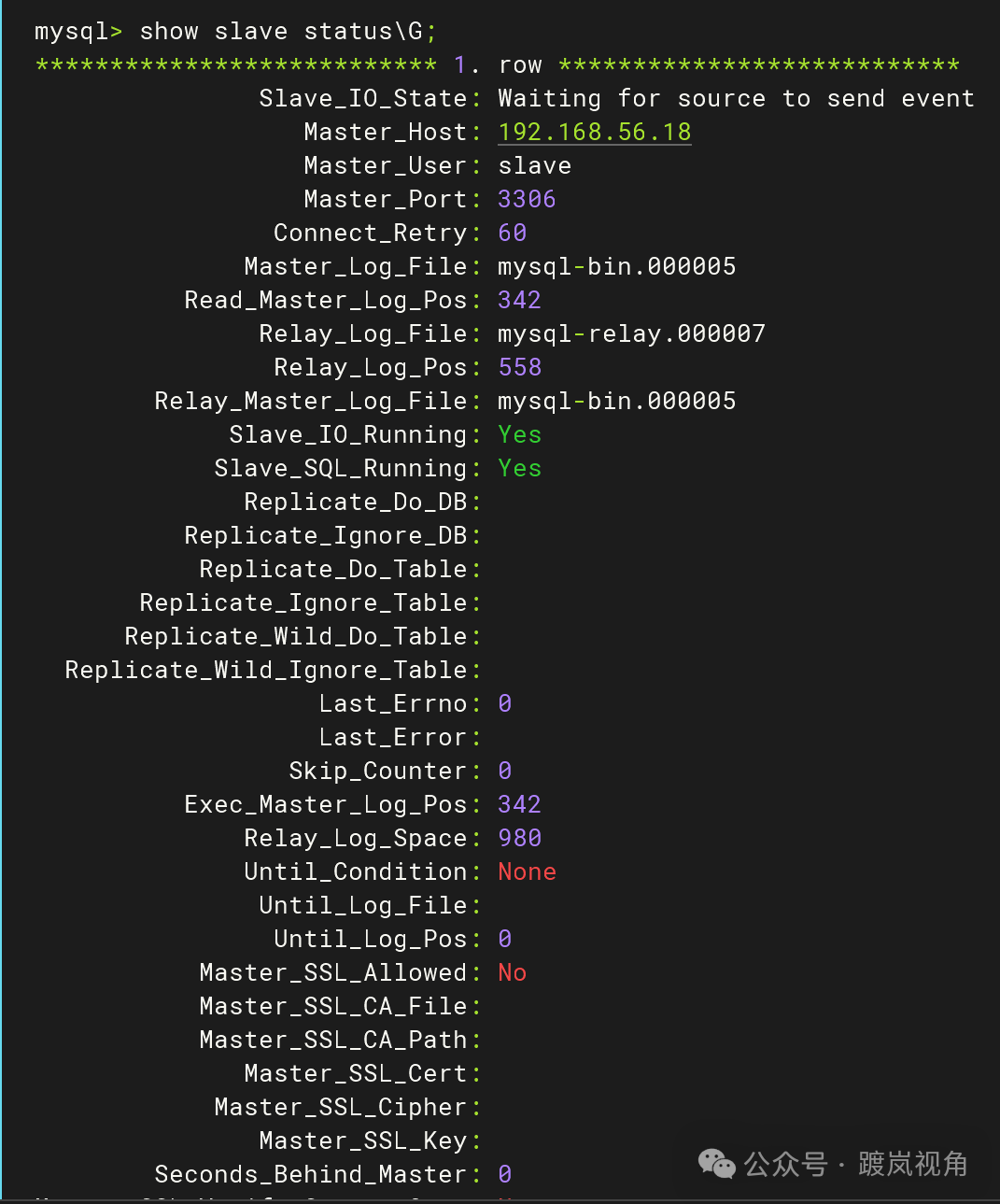
2.9、在从库侧查看slave状态
start slave; Slave_IO_Running: Yes Slave_SQL_Running: Yes 都为Yes则代表配置成功。 |
2.10、关闭主库侧锁表模式
unlock tables; 仅在前面执行了主库侧锁表操作的场景才执行本步骤。 |
三、数据同步测试
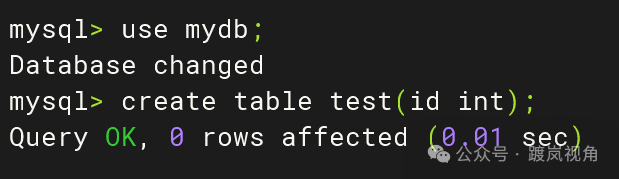
3.1、在主库侧mydb创建一个test表
use mydb; create table test(id int); |
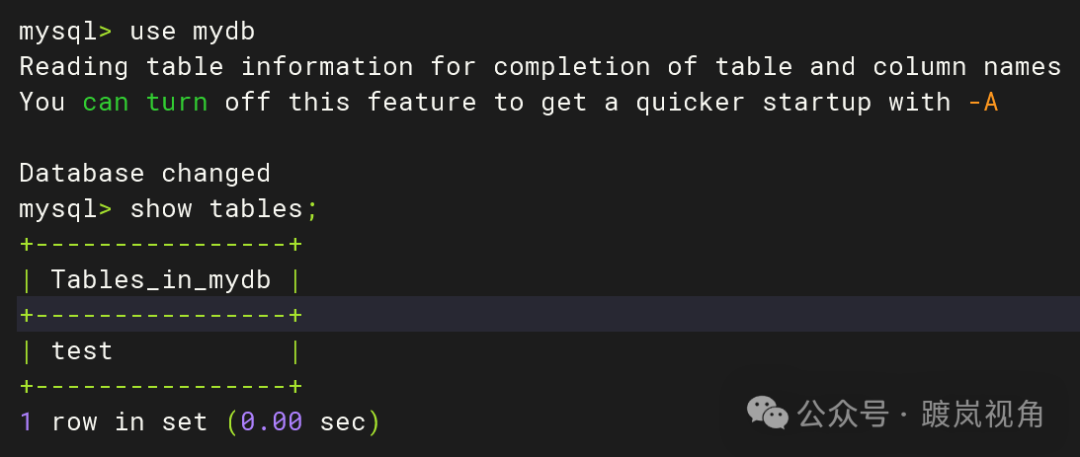
3.2、在从库侧查看同步情况
use mydb; show tables; |
3.3、在主库侧给表mydb.test插入记录
use mydb; insert into test(id) values(1); insert into test(id) values(2); insert into test(id) values(3); insert into test(id) values(4); select count(1) from test; commit; |
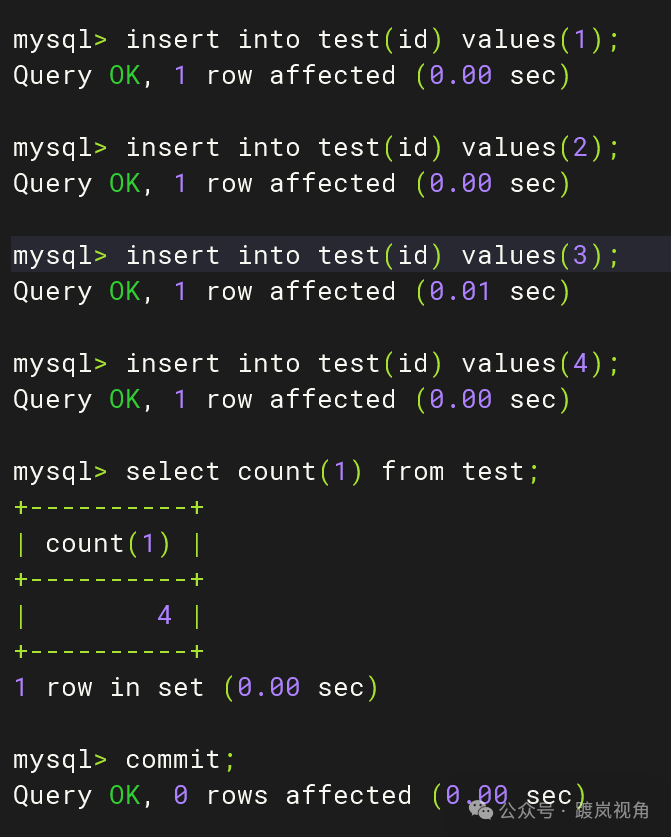
3.4、在从库侧确认mydb.test记录同步情况
use mydb; select count(1) from test; |
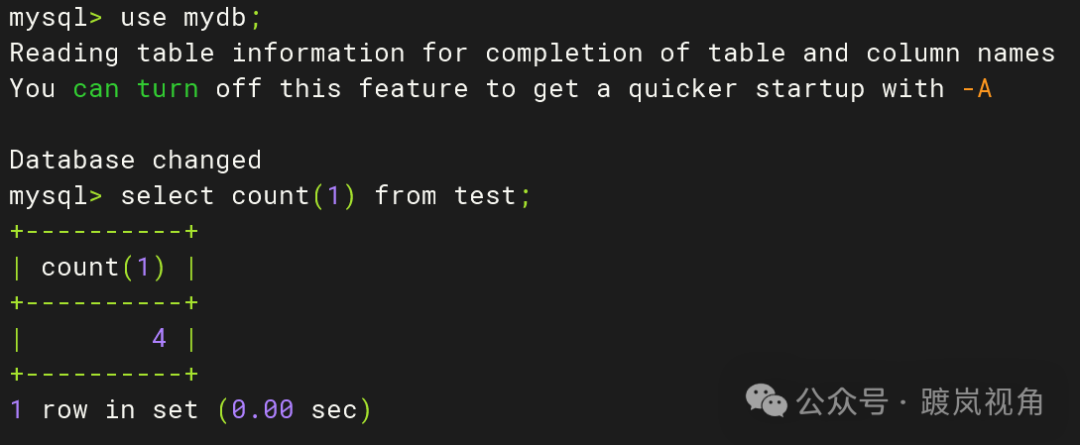
3.5、再次查看主从库同步情况
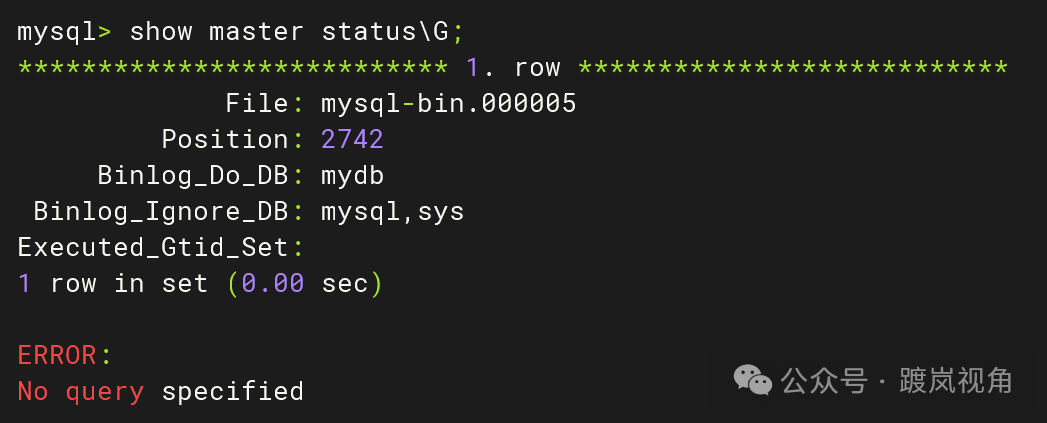
3.5.1、主库侧
show master status\G; |
3.5.2、从库侧
show slave status\G; |