




前面写了几篇对当前一些情况想法和看法,收效还凑合,不过回归老本行,还是要给各位客官整点干货。
刚好最近遇到几个案例,顺便和大家交流交流,以飨读者。
最近有个老客户来电反馈,某系统工作站报告退出慢,一般需要20秒左右,这对一个日常的OLTP系统来说,确实也有让客户无法接受。因此找到我,看看有没有啥好办法。既然找到俺,那就好好给看看,毕竟他们是我们的衣食父母,是我们的价值体现。于是约好远程时间,远程上去直接诊断,这样可以节约一些时间,规避中间沟通信息的失真和丢失。
那就首先介绍下系统的背景:服务器Linux,数据库Oracle 10g,系统是C/S架构。
其次,对踱岚来说一般需要调研和确认几个问题:
1、是所有工作站执行这个操作都慢还是个别工作站?
2、工作站慢有没有什么特征?比如时间段,操作特殊性等;
3、是整体系统都慢还是单个功能点或模块?
这些问题回答好或者调研好,就为问题的解决奠定了坚实基础。一般来说已经具备50%的成功概率,至少可以缩小和排除很多问题。
踱岚一直强调,对于诊断和解决信息系统的相关故障或性能问题,和医生看病的过程一样。我们一般去医院看病,先和医生做简单沟通交流,告诉医生哪里不舒服?多长时间了?可能引发的原因等等,同时医生对我们进行必要的查体,然后开出一系列检查单,最后根据检查报告和自己的临床经验,写处方并开药。对于信息系统性能或故障诊断,基本也遵循这个步骤:
1、“望闻问切”:了解系统问题产生的过程及可能的相关信息;
2、锁定问题:初步判定问题可能产生的环节,一般是怀疑并锁定几个故障点;
3、初次查体:现场查看,比如问题发生第一现场,这个一般是客户端或在信息系统前台;
4、开检查单:通过信息系统后台了解和分析信息系统相关软硬件日志,确认故障点;
5、开药:提供解决方案并应用解决方案。
有些问题一个过程就能解决问题,有些复杂问题需要几次不断循环上述步骤,才能最终彻底解决问题。就像医生第一次开药效果不佳,需要重新开药的过程,这就是信息系统故障的“误诊”一样。
对于本次工作站保存报告退出慢的问题,踱岚也基本遵循这个步骤:
首先,了解的情况是:所有工作站同类操作都慢,整体系统不慢,没有明显特征。
其次,踱岚要锁定可能原因,不是全局性问题,那说明系统整体资源暂时是充足的,一般涵括CPU、IO和内存。同类工作站相同操作都慢,那说明不是但工作站环境本身引发的问题,与环境无关;没有明显特征,那说明是常态现象,而不是偶发性问题。经过以上信息踱岚基本怀疑是个别top sql在搞鬼,过度耗费资源,导致单个操作执行慢。
再次,找证据,印证自己的推断。对于C/S架构的程序,比较好办。在工作站端部署一个oratracer工具(用来跟踪程序所发生的sql语句),然后运行工作站,把保存报告的步骤操作一遍,抓到客户端与服务器交互的sql语句,逐条分析排查。在本案例中,踱岚找到一些蛛丝马迹:

发现这条语句再保存报告前需要执行:
Select * From r_auditingtrace Where StudyID=553017;
是不是罪魁祸首, 找出这个语句的执行计划就知道了:
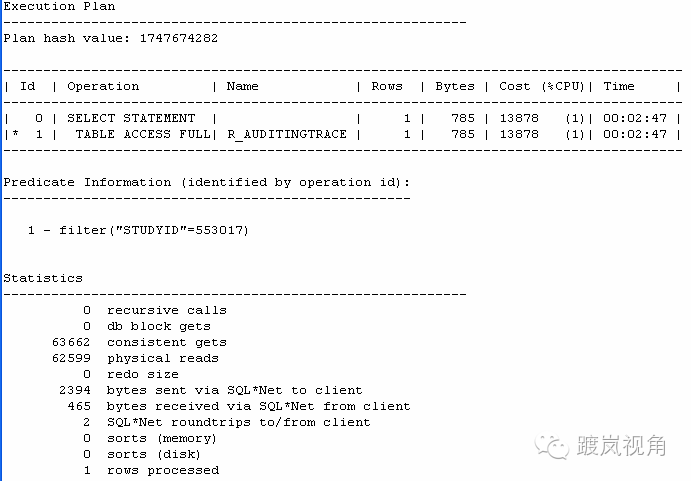
果然不出所料,该语句每次保存报告的时候都要执行一遍,且是全表扫描,当然耗费时间了。
下面就开药方了:
create index ind_att_studyid on r_auditingtrace(studyid);
然后继续查看,上述语句的执行计划:
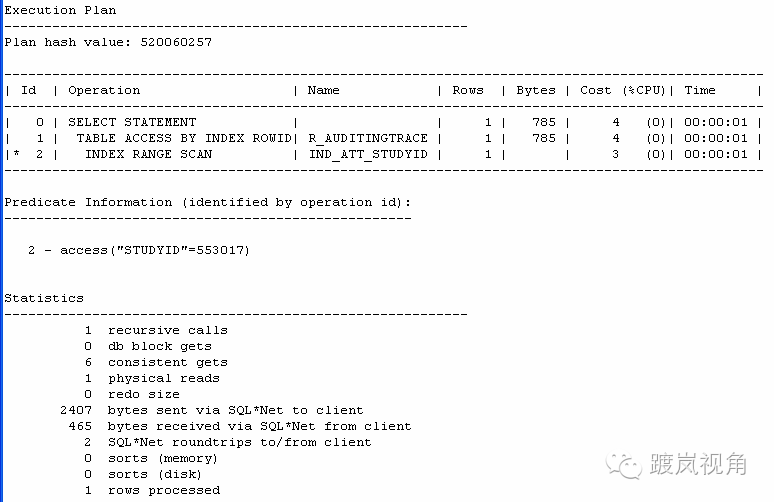
嗯,这下好多了,只有一个物理读。
可以鸣金收兵了,让客户重新使用工作站把保存报告退出的流程走一遍,这次果然不再便秘,非常通畅,一闪而过。
对于性能优化来说,每次都有一个明确的目标,当优化目标达到了就可以停止,而不是无休止。
篇尾语:
本文主要介绍信息系统性能或故障诊断流程。受限于篇幅原因,其中涉及到的居多方法或概念不一一讲解,可以在以后系列中展开。
希望能对大家有所启发。

