




上期填坑
leetcode,2951. 找出峰值
给你一个下标从 0 开始的数组 mountain 。你的任务是找出数组 mountain 中的所有 峰值。
以数组形式返回给定数组中 峰值 的下标,顺序不限 。
注意:
峰值 是指一个严格大于其相邻元素的元素。
数组的第一个和最后一个元素 不 是峰值。
public List<Integer> findPeaks(int[] mountain) {List<Integer> res = new ArrayList<>();for (int i = 1; i < mountain.length - 1; i++) {//比较当前下标数组值与前后数值的大小即可if (mountain[i - 1] < mountain[i] && mountain[i] > mountain[i + 1]) {res.add(i);}}return res;}复制

慢查询
所谓慢查询是指在执行sql查询时,执行时间超过了阈值
。
当然这个阈值是可以进行人为设置
的。
阈值的大小取决于业务的容忍度
,不过一般来说查询进入秒级
,就已经可以被称之为”慢查询“。
慢查询的产生会导致数据库响应变慢,服务器性能下降,影响用户体验
,严重时会导致数据库连接打满,使应用宕机崩溃
。所以了解慢查询并进行优化,是DBA、程序员需要重视的。
慢查询设置
了解MySQL的慢查询并优化,首先要做的必然是捕获导致慢查询的sql语句。MySQL针对慢查询配置许多变量
,供不同场景进行按需设置
。
与慢查询相关的参数说明:
slow_query_log:是否开启慢查询日志,1表示开启,0表示关闭(在mysql配置文件.conf 中是以1/0表示)。
low-query-log-file:MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
ong_query_time:慢查询阈值,当查询时间多于设定的阈值时,记录日志。
log_queries_not_using_indexes:未使用索引的查询也被记录到慢查询日志中(可选项)。
log_output:日志存储方式。log_output='FILE'
表示将日志存入文件,默认值是'FILE'。 log_output='TABLE'
表示将日志存入数据库。
slow_launch_time=2- 表示如果建立线程花费了比这个值更长的时间,slow_launch_threads 计数器将增加。
只需要使用相关语句set global {variable}={value};
进行设置即可。或者在MySQL的my.cnf
文件中进行添加或者修改。本机的部分配置如图。
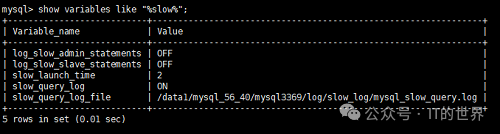
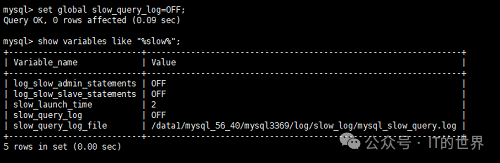
如果想关闭慢查询,使用set global slow_query_log=OFF;
即可,该命令当mysql重启后失效,所以如果想永久关闭,需要在配置文件my.cnf中修改。
慢查询日志分析
开启MySQL慢查询后,慢查询查询的写入会十分频繁,导致文件过大。使用tail -100f mysql_slow_query.log
也许可以查看一二。但是不太方便也不太全面。这里推荐使用mysql自带的mysqldumpslow
进行分析:
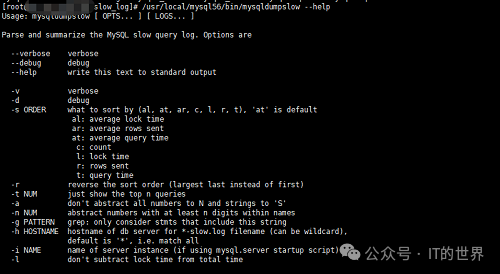
参数说明:
-s 排序方式:al: 平均锁定时间ar: 平均发送行数at: 平均查询时间c : 执行次数l : 锁定时间r : 总发送行数t : 总查询时间-r 倒序-t 选取前n项-a 不要隐藏sql语句中的数字与字符串,原样显示-n 抽象名字时添加N位的数字-g 即grep,只考虑包含改字符串的慢sql-h 根据服务器名称选择慢sql-i 根据mysql实例名称选择慢sql-l 不从总时间里面减去锁定时间复制
例如:
// 查询执行次数排名前10的慢sql
/usr/local/mysql56/bin/mysqldumpslow -s c -t 10 ./mysql_slow_query.log
//查询包含job,总查询时间排名前10的慢sql
/usr/local/mysql56/bin/mysqldumpslow -s t -t 10 -g "job" ./mysql_slow_query.log复制
慢查询的优化
捕获
的导致慢查询的sql语句后,就要着手进行优化
,解决
问题。
一般来说导致慢查询的原因有以下几种,不同的原因不同的解决方案
:
查询的数据量过大
• 可能是开发写的sql语句带的
筛选条件有问题
,笔者遇到过拼接“where 1 = 1“。——发现问题解决•
查询
语句条件可以更精确化
,不查询多余数据• 对于大查询,采用
分页查询
,限制每次查询的数据
查询语句没走索引
• 表存在索引,但是sql语句查询没走,
优化语句
;索引不合理就修改索引
。• 表不存在索引,
添加相关索引
锁竞争
• 锁竞争导致查询等待,验证导致死锁。
降低锁的粒度
。•
死锁
需要开发优化业务逻辑
。
查询语句优化不足
• 例如如in , order by ,子查询,函数索引等。
进行语句优化
。
数据库服务器性能问题:这就需要增加配置
了
慢查询需要长期监控并持续优化。慢查询的优化可以带来立竿见影的效果,相比于修改业务逻辑和代码,效果快代价小。
每日一算
leetcode,16.25. LRU 缓存
设计和构建一个“最近最少使用”缓存,该缓存会删除最近最少使用的项目。缓存应该从键映射到值(允许你插入和检索特定键对应的值),并在初始化时指定最大容量。当缓存被填满时,它应该删除最近最少使用的项目。
它应该支持以下操作:获取数据 get 和 写入数据 put 。
r 获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空.
