




前言:
上一期我们分享了C语言中的指针,本篇我们来介绍C语言中最重要的基础知识点——链表。最近由于工作原因,确实更新的不够及时,在此给各位表示歉意(鞠躬)。
一、链表简介:
C语言中的链表 是一种动态数据结构,用于存储和管理数据。它通过指针将多个独立的内存块(称为节点)串联起来,形成一个逻辑上连续的序列。与数组不同,链表的内存空间不需要预先分配,可以动态扩展或收缩,因此非常适合处理不确定数据规模或需要频繁增删元素的场景。通俗来讲,我们可以将链表想象成一辆火车,每节车厢(节点)载有货物(数据)和挂钩(指针),车厢之间通过挂钩连接,最后一节车厢的挂钩为空,如果要增加车厢,只需修改挂钩;不需要移除车厢,只需调整前后车厢的挂钩即可。
二、链表的结构
1. 核心组件
节点(Node):
- 数据域:存储实际数据(如int、char、结构体等)。
- 指针域:指向其他节点的地址。
struct ListNode {
int data; // 数据域
struct ListNode *next; // 指针域(单向链表)
// struct ListNode *prev; // 双向链表的额外指针域
};复制头指针(Head Pointer):
指向链表的第一个节点,是访问链表的唯一入口。
若链表为空,头指针为
NULL。
头节点(Dummy Head)(可选):
不存储实际数据,仅作为哨兵节点,简化插入/删除操作。
示例:
Dummy → A → B → C → NULL。
2. 内存分配
动态内存:节点通过
malloc动态分配,内存非连续。手动管理:需显式调用
free释放内存,避免泄漏。
三、常见的链表的类型

- 单向链表的结构特点:
单向链表每个节点都包含一个数据域和一个指向下一个节点的指针 next,其中尾部节点的next为null。
示例:
#include <stdio.h>
#include <stdlib.h>
// 定义单向链表节点结构
struct Node {
int data;
struct Node* next;
};
// 创建新节点
struct Node* createNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
if (newNode == NULL) {
printf("内存分配失败!\n");
exit(1);
}
newNode->data = data;
newNode->next = NULL; // 初始化为独立节点
return newNode;
}
// 在链表头部插入节点
void insertAtHead(struct Node** head, int data) {
struct Node* newNode = createNode(data);
newNode->next = *head; // 新节点指向原头节点
*head = newNode; // 更新头节点为新节点
}
// 遍历链表
void printList(struct Node* head) {
struct Node* current = head;
while (current != NULL) {
printf("%d -> ", current->data);
current = current->next;
}
printf("NULL\n");
}
// 释放链表内存
void freeList(struct Node* head) {
struct Node* tmp;
while (head != NULL) {
tmp = head;
head = head->next;
free(tmp);
}
}
int main() {
struct Node* head = NULL;
insertAtHead(&head, 3);
insertAtHead(&head, 2);
insertAtHead(&head, 1);
printList(head); // 输出: 1 -> 2 -> 3 -> NULL
freeList(head);
return 0;
}复制这里需要注意,头部插入仅需要修改指针和新节点的next 链表的遍历过程也是从头部开始,依次访问next 直到最后的null。同时在链表内存释放时,需要逐个释放节点,避免内存泄漏的问题。
- 双向链表的结构特点:
我们先看一个示例,在双向链表中,每个节点均包含数据域,前驱指针prev和后继指针next,并且支持双向遍历。
示例:
#include <stdio.h>
#include <stdlib.h>
// 定义双向链表节点结构
struct DNode {
int data;
struct DNode* prev;
struct DNode* next;
};
// 创建新节点
struct DNode* createDNode(int data) {
struct DNode* newNode = (struct DNode*)malloc(sizeof(struct DNode));
if (newNode == NULL) {
printf("内存分配失败!\n");
exit(1);
}
newNode->data = data;
newNode->prev = newNode->next = NULL; // 初始化为独立节点
return newNode;
}
// 在链表头部插入节点
void insertAtDHead(struct DNode** head, int data) {
struct DNode* newNode = createDNode(data);
if (*head != NULL) {
(*head)->prev = newNode; // 原头节点的前驱指向新节点
}
newNode->next = *head; // 新节点的后继指向原头节点
*head = newNode; // 更新头节点
}
// 正向遍历链表
void printDListForward(struct DNode* head) {
struct DNode* current = head;
while (current != NULL) {
printf("%d <-> ", current->data);
current = current->next;
}
printf("NULL\n");
}
// 反向遍历链表(需传入尾节点)
void printDListBackward(struct DNode* tail) {
struct DNode* current = tail;
while (current != NULL) {
printf("%d <-> ", current->data);
current = current->prev;
}
printf("NULL\n");
}
// 释放链表内存
void freeDList(struct DNode* head) {
struct DNode* tmp;
while (head != NULL) {
tmp = head;
head = head->next;
free(tmp);
}
}
int main() {
struct DNode* head = NULL;
insertAtDHead(&head, 3);
insertAtDHead(&head, 2);
insertAtDHead(&head, 1);
printDListForward(head); // 输出: 1 <-> 2 <-> 3 <-> NULL
freeDList(head);
return 0;
}复制在上述的代码中,详细展示了双向链表的典型运行过程,涵盖了从结构体存储节点存储数据,头部节点插入节点函数,正向遍历函数,反向遍历函数,最后内存释放函数并输出结果。同时在双向链表中,需要注意在删除的时候,需要更新前驱和后继节点的指针。我们可以详细的拆解下步骤来进一步了解双向链表。
双向链表是一种链式数据结构,其每个节点(Node)包含三个部分:
数据域:存储数据(如整数、字符串等)。
前驱指针(
prev):指向前一个节点的地址。后继指针(
next):指向后一个节点的地址。
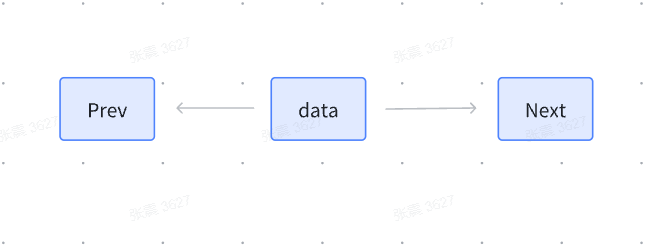
双向链表的核心特性
双向遍历:
支持从头节点到尾节点的正向遍历(next指针)。同时支持从尾节点到头节点的反向遍历(prev指针)。动态内存分配:
节点通过动态内存分配(如malloc)创建,内存非连续。
灵活增删:
插入和删除节点时,只需修改相邻节点的指针,无需移动其他元素。
双向链表的基本操作
(1) 创建节点:
struct DNode* createDNode(int data) {
struct DNode* newNode = (struct DNode*)malloc(sizeof(struct DNode));
newNode->data = data;
newNode->prev = NULL;
newNode->next = NULL;
return newNode;
}复制功能:动态分配内存,初始化节点数据域和指针域。
注意:必须检查
malloc是否成功
(2) 头部插入节点
void insertAtHead(struct DNode** head, int data) {
struct DNode* newNode = createDNode(data);
if (*head != NULL) {
(*head)->prev = newNode; // 原头节点的前驱指向新节点
}
newNode->next = *head; // 新节点的后继指向原头节点
*head = newNode; // 更新头指针
}复制这部分的逻辑是新节点的next指向原头节点,原头节点的prev指向新节点(若链表为非空),同时更新头指针为新节点。
(3) 尾部插入节点
void insertAtTail(struct DNode** head, int data) {
struct DNode* newNode = createDNode(data);
if (*head == NULL) {
*head = newNode;
return;
}
struct DNode* current = *head;
while (current->next != NULL) {
current = current->next; // 找到尾节点
}
current->next = newNode;
newNode->prev = current; // 新节点的前驱指向原尾节点
}复制(4) 遍历链表
正向遍历:
void printForward(struct DNode* head) {
struct DNode* current = head;
while (current != NULL) {
printf("%d <-> ", current->data);
current = current->next;
}
printf("NULL\n");
}复制反向遍历:
void printBackward(struct DNode* tail) {
struct DNode* current = tail;
while (current != NULL) {
printf("%d <-> ", current->data);
current = current->prev;
}
printf("NULL\n");
}复制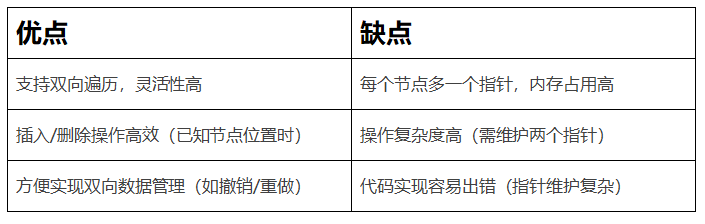
最后:
虽然是慢工,但是不是什么细活
