




MySQL 组复制(GR)是实现 MySQL 部署高可用性的强大解决方案。为了进一步增强组复制集群的可靠性和弹性,我们引入了一项新功能: 组复制资源管理器。此功能使组复制系统能够主动识别和隔离过度消耗资源或在应用事务时长时间延迟的实例。通过隔离这些实例,系统可以防止级联故障,最大限度地减少停机时间,并确保集群的持续平稳运行。此功能在 MySQL 企业版 9.2.0中可用,包括 InnoDB Cluster 和 ClusterSet,与自动重新加入和 InnoDB 克隆等现有功能结合使用,为组复制集群提供强大的自我修复能力。
组复制资源管理器是升级到 MySQL 企业版并充分发挥 MySQL 部署潜力的另一个原因。
理解问题
在组复制中,次要节点滞后或成员资源耗尽可能会给整个组带来问题。这可能会减慢组速度,增加故障风险,并且可能需要手动干预。
组复制资源管理器简介
为了解决这个问题,我们开发了一个新的组件“组复制资源管理器”,它执行以下操作:
持续监控: 组复制资源管理器持续监控关键指标,即应用程序通道滞后、恢复通道滞后和集群内的内存使用情况。
主动弹出: 如果实例超出预定义的阈值,则组复制资源管理器将通过启动从组的正常退出并将成员转换为错误状态来自动将其从组中弹出。
自动重新加入: 被弹出的实例可以使用现有的自动重新加入机制自动尝试重新加入组。
InnoDB Clone(如有必要): InnoDB Clone 可用于分布式恢复,确保更快的恢复并最大限度地减少停机时间。
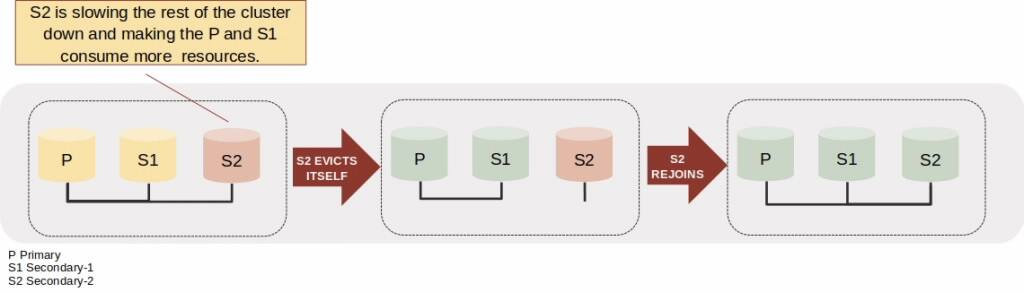
下图说明了组复制资源管理器检测到辅助服务器 (S2) 中的应用程序通道滞后较高、恢复通道滞后较高或内存使用量过大时的过程。它显示了此辅助服务器的自动弹出以及随后的自动重新加入尝试。
如何使用此功能
要启用组复制资源管理器功能并配置阈值,请使用安装组件。 该组件包含多个配置选项,您可以调整这些选项以满足您的要求。这些选项代表最大阈值,一旦超过,将 触发实例自动从组中弹出。INSTALL COMPONENT ‘file://component_group_replication_resource_manager’.
- group_replication_resource_manager.applier_channel_lag: 设置在实例自动从组中弹出之前应用程序通道应用事务日志的最大可接受延迟(以秒为单位)。
- group_replication_resource_manager.recovery_channel_lag: 设置实例自动从组内弹出之前恢复通道追上主服务器的最大可接受延迟(以秒为单位)。
- group_replication_resource_manager.memory_used_limit: 设置实例自动从组内弹出之前可接受的最大内存使用量百分比。
重要注意事项:
配置自动弹出的阈值时,请考虑以下因素,因为最佳值会有很大差异:
工作负载特征: 交易量、交易大小和查询模式都会影响预期的滞后和资源消耗。
硬件和软件配置: 服务器硬件、存储基础设施和网络配置将影响性能和资源利用率。
运营要求: 可接受的滞后和资源利用率水平取决于您的应用程序的特定服务水平目标 (SLO)。
在配置自动弹出阈值时,仔细考虑这些因素至关重要。建议在正常运行条件下仔细监控集群的行为,并根据需要调整阈值以确保最佳性能和稳定性。
监控组复制集群的健康状况
要监控组复制集群的运行状况以及自动弹出和重新加入功能的有效性,可以使用以下 SQL 语句及其相应的状态变量:
- gr_resource_manager_applier_channel_lag: 显示当前应用程序通道滞后时间(秒)。
- gr_resource_manager_recovery_channel_lag: 显示当前恢复通道滞后(秒数)。
- gr_resource_manager_memory_used: 显示当前内存使用百分比。
- gr_resource_manager_applier_channel_threshold_hits: 计算应用程序通道滞后阈值被超出的次数。
- gr_resource_manager_recovery_channel_threshold_hits: 计算超出恢复通道滞后阈值的次数。
- gr_resource_manager_memory_threshold_hits: 计算超出内存使用率阈值的次数。
- gr_resource_manager_applier_channel_eviction_timestamp: 显示由于应用程序通道滞后而导致最后一次驱逐的时间戳。
- gr_resource_manager_recovery_channel_eviction_timestamp: 显示由于恢复通道滞后而导致最后一次驱逐的时间戳。
- gr_resource_manager_memory_eviction_timestamp: 显示由于内存使用而导致的最后一次驱逐的时间戳。
通过执行 SQL 语句,您可以轻松监控与组复制资源管理器相关的关键指标,并深入了解组复制集群的健康状况。
自我修复的实际应用:自动弹出、重新加入和 InnoDB 克隆如何协同工作
组复制资源管理器的真正强大之处在于它能够促进组复制集群内的自我修复。让我们探索这些组件如何协同工作以解决常见场景:
-
场景 1:应用者渠道滞后较高
- 问题: 辅助服务器遇到严重的应用通道滞后,这可能是由于资源限制或网络问题造成的。
- 解决:
自动弹出: 组复制资源管理器检测到过度滞后并自动从组中弹出辅助服务器。
自动重新加入: 被驱逐的服务器启动 自动重新加入程序,尝试重新加入组,最多尝试系统变量指定的次数 group_replication_autorejoin_tries (默认值:尝试 3 次,每次尝试间隔 5 分钟)。
InnoDB 克隆: 根据 group_replication_clone_threshold 值自动重新加入尝试期间, 可以使用 InnoDB 克隆执行恢复,确保服务器能够使用干净且一致的数据集重新加入组。组内的供体成员将其数据的快照提供给被弹出的成员,与仅依赖二进制日志复制相比,恢复过程大大加快。然后,被弹出的成员使用克隆的数据加入组。
-
场景 2:高恢复通道滞后
- 问题: 辅助服务器遇到严重的恢复通道滞后,可能是由于资源限制或网络问题造成的。
- 解决:
自动弹出: 组复制资源管理器检测到过度滞后,并自动从组中弹出辅助服务器。
自动重新加入: 被驱逐的服务器启动自动重新加入程序,尝试重新加入组。
InnoDB 克隆: InnoDB 克隆可用于 根据选项 执行分布式恢复group_replication_clone_threshold。组内的供体成员向被弹出的成员提供其数据的快照,从而实现更快的恢复并最大限度地减少停机时间。
-
场景 3:内存使用量过大
- 问题: 辅助服务器的内存使用量过多,可能导致不稳定和性能下降。
- 解决:
自动弹出: 组复制资源管理器检测到过多的内存使用情况,并自动将服务器从组中弹出。
自动重新加入: 被弹出的服务器将根据设置自动尝试重新加入组 group_replication_autorejoin_tries 。
InnoDB Clone: InnoDB Clone 可用于 根据选项 执行分布式恢复group_replication_clone_threshold,确保服务器可以使用干净、一致的数据集重新加入组。
自我修复的主要优点:
- 最小化停机时间: 通过利用 InnoDB Clone 在自动重新加入期间进行分布式恢复,与在极端滞后期间仅依赖二进制日志复制相比,停机时间显著减少。
- 提高弹性: 集群对意外事件的弹性更强,例如滞后的辅助服务器会严重影响整体集群性能,从而确保持续可用性并最大限度地减少服务中断。
- 减少运营开销: 自动缓解常见问题,例如弹出高延迟或过度资源消耗的实例,减少人工干预的需要并释放宝贵的 IT 资源以用于其他关键任务。
通过结合自动弹出、现有的自动重新加入机制以及 InnoDB Clone 强大的分布式恢复功能,MySQL 企业版提供了一个强大且可自我修复的组复制环境,可以适应各种挑战并确保关键应用程序的最高可用性。
原文地址:https://blogs.oracle.com/mysql/post/automatic-health-check-in-mysql-group-replication
原文作者:Jaideep Karande
