




Redis 为数据库提供了非常丰富的操作命令,通过这些命令,用户可以:
指定自己想使用的数据库
一次获取数据库包含的所有键,迭代获取数据库包含的所有键,或者随机获取数据库中的某个键
根据给定键进行排序
检查给定的一个或多个键,看他们是否存在数据库中
查看给定键的类型
对给定键进行重命名
移除指定键,或者将它从一个数据库移动到另一个数据库
清空数据库包含的所有键
交换给定的两个数据库
SELECT: 切换至指定的数据库
一个Redis服务器包含多个数据库,默认情况下是16个(标号0 ~ 15)
语法
select 5 // 选择 5 数据库
KEYS: 获取所有与给定匹配符相匹配的键
语法
KEYS pattern
示例
获取所有键:KEYS *
获取所有以user开头的:KEYS user::*
全局匹配符
匹配符 | 作用 | 例子 |
* | 匹配零个或任意多个任意字符 | user::* 可以匹配任何以user::为前缀的字符串 |
? | 匹配任意的单个字符 | user::i? 可以匹配任何以user::i为前缀,后跟单个字符的字符串,比如:user::ip, user::id,但是不能匹配user::time |
[] | 匹配给定字符串中的单个字符 | user::i[abc]可以匹配user::ia、user::ib、user::ic,但不能匹配除此之外的其他字符串,比如user::ip或user::time |
[?-?] | 匹配给定范围中的单个字符 | user::i[a-d]可以匹配user::ia, user::ib,user::ic, user::id, 但不能匹配除此之外的其他字符串,比如user::ip等 |
SCAN: 以渐进方式迭代数据库中的键
KEYS命令需要检查数据库包含的所有键,并一次将符合条件的所有键全部返回给客户端,当数据库包含的键数量比较大时,使用KEYS命令可能会导致服务器被阻塞。
语法
SCAN cursor [count number]
scan 命令的执行结果由2个元素组成:
第一个元素:进行下次迭代所需的游标,如果游标为0,那么说明客户端已经对数据库完成了一次完整的迭代
第二个元素:一个列表,包含了本地迭代所取得的数据库的键,如果SCAN命令在某次迭代中没有获取到任何键,那么这个元素将是一个空列表
count:
期望的键数量,并不是准确的键数量。但每次迭代返回的键数量仍然是不确定的。
通常情况下,count越大将返回的键越多
注意事项
SCAN可能返回重复的键,用户需要自己在客户端中进行检测和过滤
SCAN返回的键数量不确定,有时甚至不返回任何键,但只要返回的游标不为0,表示迭代就没有结束
HSCAN: 以渐进方式迭代给定散列包含的键值对
语法:与SCAN的参数说明类似
hscan hash cursor [match pattern] [count number]
SSCAN:以渐进方式迭代给定集合包含的元素
语法:与SCAN的参数说明类似
SSCAN set cursor [match pattern] [count number]
ZSCAN: 以渐进方式迭代给定有序集合包含的成员和分值
语法:与SCAN的参数说明类似
ZSCAN sorted_set cursor [match pattern] [count number]
RANDOMKEY: 随机返回一个键
语法:
RANDOMKEY
SORT: 对键的值进行排序
sort命令可以对list,set或zset进行排序。默认会按照存储元素的数字值进行排序。
SORT key
按指定方式排序--升序|降序
SORT key [asc|desc]
对字符串进行排序
SORT key ALPHA
获取部分结果
SORT key [limit offset count]
参数说明:
offset:跳过的元素数量
count:指定获取的元素数量
获取外部键的结果
SORT key [[get pattern] [get pattern]...]
参数说明:
get pattern: pattern可以是
包含*符号的字符串
包含*符号和-> 符号的字符串
一个单独的#符号
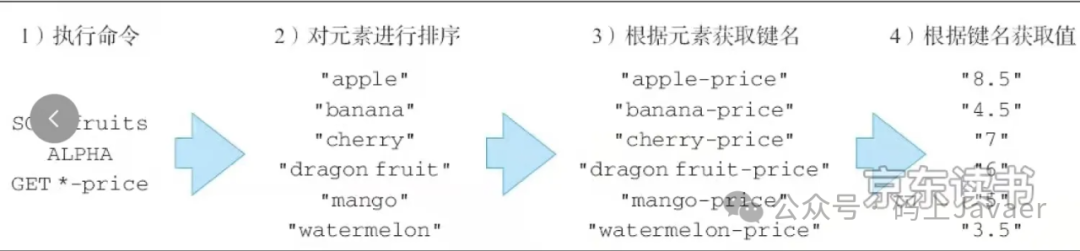
1. 获取字符串键的值示例
数据初始化
# 创建列表rpush fruits banner apple cherry mango# 设置值set apple-price 8.5set banner-price 2.5set cherry-price 5.5set mango-price 4.5
排序:
127.0.0.1:6379> sort fruits alpha get *-price1) "8.5"2) "2.5"3) "5.5"4) "4.5"
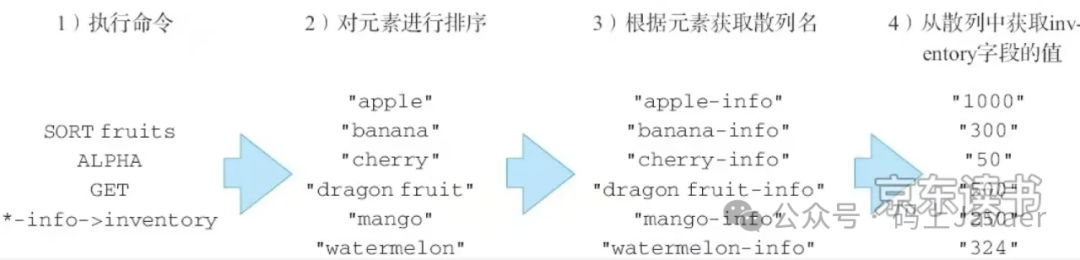
2. 获取散列中的键值
数据初始化
127.0.0.1:6379> hset apple-info inventory 200(integer) 1127.0.0.1:6379> hset banenr-info inventory 22D0(integer) 1127.0.0.1:6379> hset cherry-info inventory 22D(integer) 1127.0.0.1:6379> hset mango-info inventory 22(integer) 1
sort指令
127.0.0.1:6379> sort fruits alpha get *-info->inventory1) "200"2) "1"3) "22D"4) "22"
3. 获取被排序元素本身
当pattern值是一个#符号时,SORT命令将返回被排序元素本身
127.0.0.1:6379> sort fruits alpha get #1) "apple"2) "banner"3) "cherry"4) "mango"
更多样式的排序:
127.0.0.1:6379> sort fruits alpha get # get *-price get *-info->inventory1) "apple" -- 水果2) "8.5" -- 价格3) "200" -- 库存4) "banner"5) "2.5"6) "1"7) "cherry"8) "5.5"9) "22D"10) "mango"11) "4.5"12) "22"
使用外键的值进行排序
默认情况下,sort使用被排序元素本身作为排序权重,但需要时,用户可以通过BY选项指定其他键的值作为排序的权重。
SORT key BY pattern
示例:使用水果价格进行排序
127.0.0.1:6379> sort fruits by *-price1) "banner"2) "mango"3) "cherry"4) "apple"
上面只展示了水果的名称,想要更全面信息则参考如下命令
127.0.0.1:6379> sort fruits by *-price get # get *-price1) "banner" -- 水果名2) "2.5" -- 水果价格3) "mango"4) "4.5"5) "cherry"6) "5.5"7) "apple"8) "8.5"
同样也可以通过库存排序
127.0.0.1:6379> sort fruits alpha by *-info->inventory get # get *-info->inventory1) "banner" -- 水果名2) "1" --水果库存3) "apple"4) "200"5) "mango"6) "22"7) "cherry"8) "22D"
保存排序结果
127.0.0.1:6379> sort fruits alpha by *-info->inventory get # get *-info->inventory store sorted-fruits(integer) 8127.0.0.1:6379> lrange sorted-fruits 0 -11) "banner"2) "1"3) "apple"4) "200"5) "mango"6) "22"7) "cherry"8) "22D"
EXISTS: 检查键是否存在
EXISTS key [key...]
DBSIZE: 获取数据库包含的键值对数量
DBSIZE
TYPE: 查看键的类型
TYPE key
TYPE 命令返回的结果列表
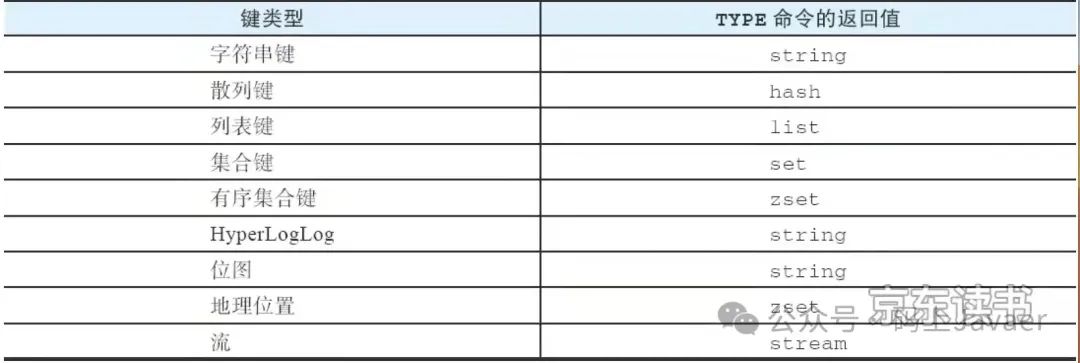
说明:
HyperLogLog&位图:底层都是通过字符串来实现的,所以type返回string
地理位置:底层采用有序集合实现的,所以type返回zset
RENAME, RENAMENX:修改键名
RENAME origin newRENAMENX origin new
MOVE: 将key移动到另一个数据库
move key db
说明:当目标db中存在于给定键同名的键时,MOVE命令将放弃执行移动操作
DEL:移除指定键
DEL key [key...]
UNLINK: 以异步方式移除指定键
UNLINK key [key ...]
说明:
DEL:采用同步方式移除键,如果移除键数量非常庞大或数量众多时,那该过程可能会被阻塞。比如移除一个包含百万元素的集合,或者一次移除成千上万个键,都有可能引起服务器阻塞。
UNLINK:采用异步方式移除键并返回移除的数量作为结果
FLUSHDB:清空当前数据库
FLUSHDB async
说明:
flushdb:同步移除命令
async:异步方式进行移除
FLUSHALL:清空所有数据库
FLUSHALL async
说明:
FLUSHALL:同步移除
async:异步移除
SWAPDB:互换数据库
SWAPDB x y
说明:互换数据库是通过调整指向数据库的指针来实现,整个过程不需要移动数据库中任意键值对,所以SWAPDB的复杂度是O(1) 而不是O(N),也不会阻塞服务器。
