




概念
· 文档- 系统中的输入文档。
· 文本块- 要分析的文本块。这些块的大小、重叠以及它们是否遵守任何数据边界可以在下面配置。
· 实体- 从 文本块 中提取的实体。这些实体代表人物、地点、事件或其他实体模型。
· 关系- 两个实体之间的关系。这些关系由协变量生成。
· 协变量- 提取的声明信息,其中包含可能受时间限制的实体的陈述。
· 社区报告- 一旦生成实体,就对它们执行分层社区检测,并为该层次结构中的每个社区生成报告。
· 节点- 该表包含已嵌入和聚集的实体和文档的呈现图形视图的布局信息。
整体流程图
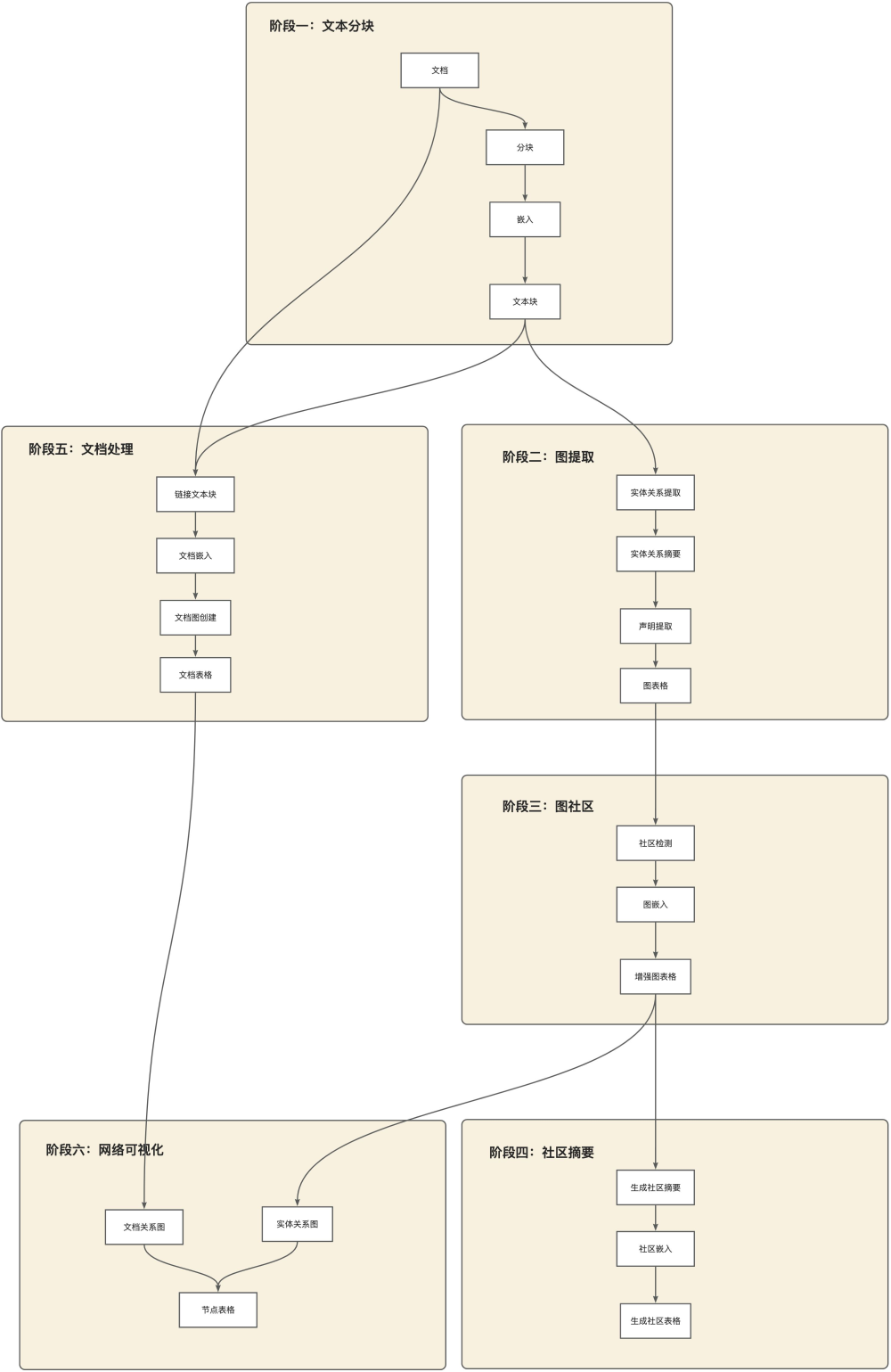
流程图解释
第一阶段:文本分块
一个基本的设计决策是决定从源文档中提取的输入文本应以何种粒度分割成文本块进行处理。而TextUnit是用于图形提取技术的文本块。 它们还被提取的知识项用作源引用,以便将面包屑和概念来源追溯到其原始源文本。
第二阶段:图提取
使用LLM将实例级摘要转换为每个图元素的描述性文本块。使用LLM“提取”源文中表示的实体、关系和声明的描述已经是一种抽象摘要的形式,依赖于LLM创建独立有意义的摘要,这些摘要可能是文本本身暗示但没有明确陈述的概念(例如,暗示关系的存在)。要将所有这些实例级摘要转换为每个图元素(即实体节点、关系边和声明协变量)的单一描述性文本块,需要进一步通过匹配实例组进行LLM摘要。
第三阶段:图社区
使用社区检测算法将图划分为模块化社区。前一步创建的索引可以被建模为一个同质无向加权图,其中实体节点通过关系边连接,边权重表示检测到的关系实例的归一化计数。给定这样的图,可以使用各种社区检测算法将图划分为节点之间相互连接的社区。在流程中使用Leiden算法,因为它能够高效地恢复大规模图的层次社区结构。这个层次结构的每个级别都提供了一个社区划分,以相互独立、集体穷尽的方式覆盖图中的节点,使得分而治之的全局摘要成为可能。
第四阶段:社区摘要
为Leiden层次结构中的每个社区创建报告式摘要。这一步是使用旨在扩展到非常大的数据集的方法为Leiden层次结构中的每个社区创建报告式摘要。这些摘要本身是有用的,因为它们是理解数据集的全局结构和语义的一种方式,并且它们自己可以用来在没有问题的情况下理解语料库。
第五阶段:文件处理
在工作流程的这个阶段,我们为知识模型创建文档表。
将每个文档链接到第一阶段创建的文本单元。这使我们能够了解哪些文档与哪些文本单元相关,反之亦然。
最后,使用文档切片的平均嵌入来生成文档的向量表示。对不重叠的块重新分块文档,然后为每个块生成嵌入。创建这些块的平均值,并按标记计数加权,并将其用作文档嵌入。这将使我们能够理解文档之间的隐式关系,并帮助我们生成文档的网络表示。
第六阶段:网络可视化
在工作流程的这个阶段,我们执行了一些步骤来支持现有图表中高维向量空间的网络可视化。此时有两个逻辑图表在起作用:实体关系图和文档图。
对于每个逻辑图,我们执行 UMAP 降维以生成图的 2D 表示。这将使我们能够在 2D 空间中可视化图并了解图中节点之间的关系。然后将 UMAP 嵌入作为 Nodes 表发出。该表的行包括一个鉴别器,指示节点是文档还是实体,以及 UMAP 坐标。
查询
本地查询
说明
本地查询将知识图谱中的结构化数据与输入文档中的非结构化数据相结合,以便在查询时使用相关实体信息增强 LLM 上下文。它非常适合回答需要了解输入文档中提到的特定实体的问题(例如,“洋甘菊的治疗功效是什么?”)。
流程图
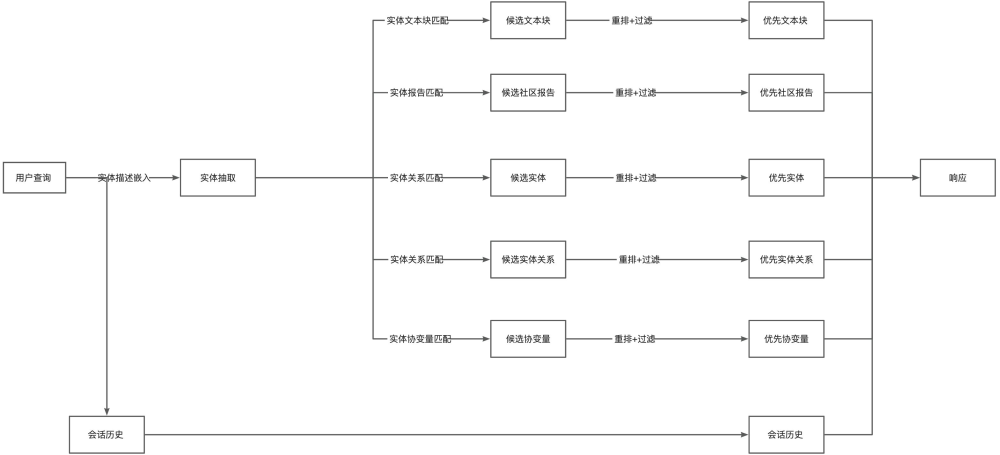
流程图解释
给定用户查询和(可选)对话历史记录,本地查询会从知识图谱中识别出一组与用户输入在语义上相关的实体。这些实体可作为知识图谱的访问点,从而提取更多相关详细信息,例如连接实体、关系、实体协变量和社区报告。此外,它还会从与已识别实体相关的原始输入文档中提取相关文本块。然后对这些候选数据源进行优先排序和筛选,以适应预定义大小的单个上下文窗口,该窗口用于生成对用户查询的响应。
全局查询
说明
传统RAG 很难处理需要汇总整个数据集的信息才能得出答案的查询。诸如“数据中的前 5 个主题是什么?”之类的查询表现不佳,因为传统RAG 依赖于对数据集内语义相似的文本内容进行向量搜索。查询中没有任何内容可以将其引导至正确的信息。
但是,使用 GraphRAG可以回答这些问题,因为 LLM 生成的知识图谱的结构告诉我们整个数据集的结构(以及主题)。这允许将私有数据集组织成预先汇总的有意义的语义集群。使用全局查询方式,LLM 在响应用户查询时使用这些集群来总结这些主题。
流程图
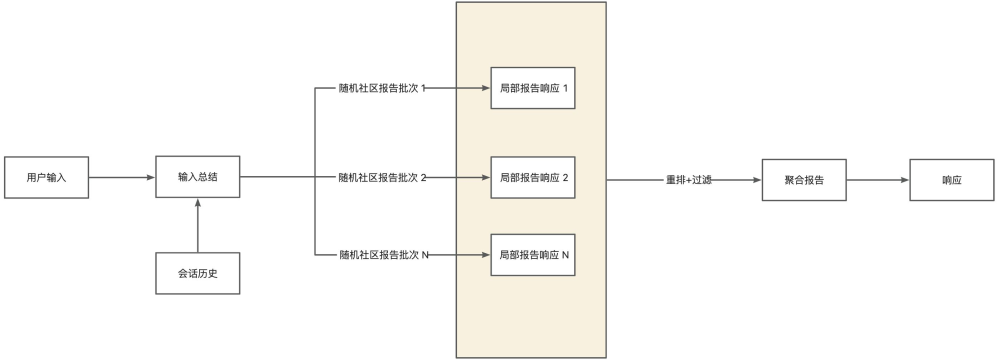
流程图解释
给定用户查询和(可选)对话历史记录,全局查询使用来自图的社区层次结构指定级别的 LLM 生成的社区报告集合作为上下文数据,以 map-reduce 方式生成响应。在此map步骤中,社区报告被分割成预定义大小的文本块。然后使用每个文本块生成一个中间响应,其中包含一个要点列表,每个要点都附有数字评级,表明该要点的重要性。在此步骤中,reduce从中间响应中筛选出的一组最重要的要点被汇总并用作上下文来生成最终响应。
全局查询响应的质量可能在很大程度上受到选择用于获取社区报告的社区层级的影响。较低层级的报告较为详细,因此往往会产生更全面的响应,但由于报告数量较多,生成最终响应所需的时间和 LLM 资源也可能会增多。
