




在AI时代,随着大模型应用的深入,高维向量数据的规模日益庞大,应用场景对快速、实时的相似性搜索和复杂查询提出了更高要求。
这需要向量数据库具备高性能的特点,海量数据库Vastbase向量版,能够高效存储、索引和处理向量数据,确保低延迟响应和高精度检索,同时支持大规模数据的扩展和并行处理,满足大模型在实际应用中的高效性和实时性需求。
本期为您解读Vastbase向量版特性——高性能。
点击了解Vastbase 高性能↑
如何衡量向量数据库的性能?
向量数据库是支撑AI应用的数据底座,需要应对大规模向量数据的检索和查询压力。
针对传统的关系型数据库,TPCC测试模型可测试其性能表现,通过tpmC(系统每分钟处理的订单数量)反映数据库的性能。
针对向量数据库,我们通过如下指标来衡量其性能:
召回率:反映系统在检索过程中找到所有相关结果的能力,即数据库的相似检索能力。召回率越高,说明数据库检索的越全面,漏掉的相关结果越少。
召回率=检索到的相关向量数量/总相关向量数量
QPS(每秒查询率):反映系统每秒响应请求的数量,即数据库的最大吞吐量。吞吐量越大,说明数据库每秒响应的请求数量越多,性能表现越好。
Vastbase向量版
亿级数据,毫秒级检索
海量数据库Vastbase向量版在保证99%以上的高召回率下,单节点可承载超1亿数据量(1024维数据),QPS吞吐量大于2000。
相较于目前市面主流的某专有向量数据库产品,在同等环境下,Vastbase向量版表现出更高的吞吐量,具有更加极致的性能表现。
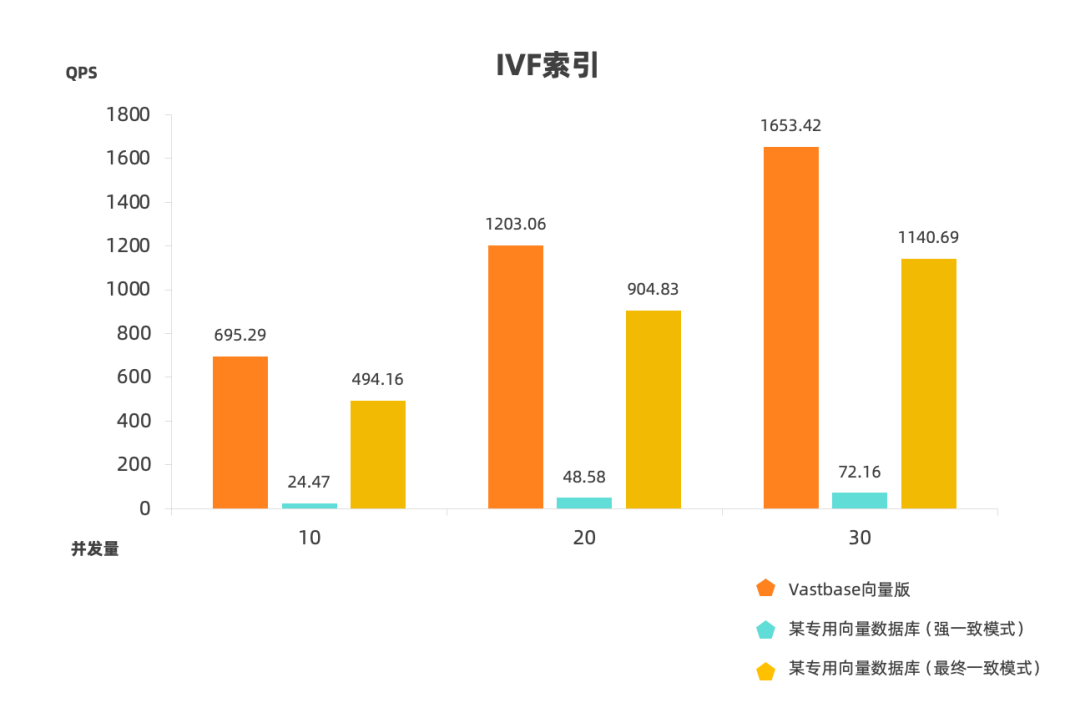
场景1
在同等条件下,数据集为100万(SIFT-128维),在保证召回率(97.7%)前提下,分别测试在不同并发情况下,Vastbase与目前市面主流某款向量数据库的QPS数值。
场景2
在同等硬件条件下,数据集为1000万(SIFT-128维),保证召回率(99%)的情况下,调用HNSW索引,分别测试在不同并发情况下,Vastbase与目前市面主流某款向量数据库的QPS数值。
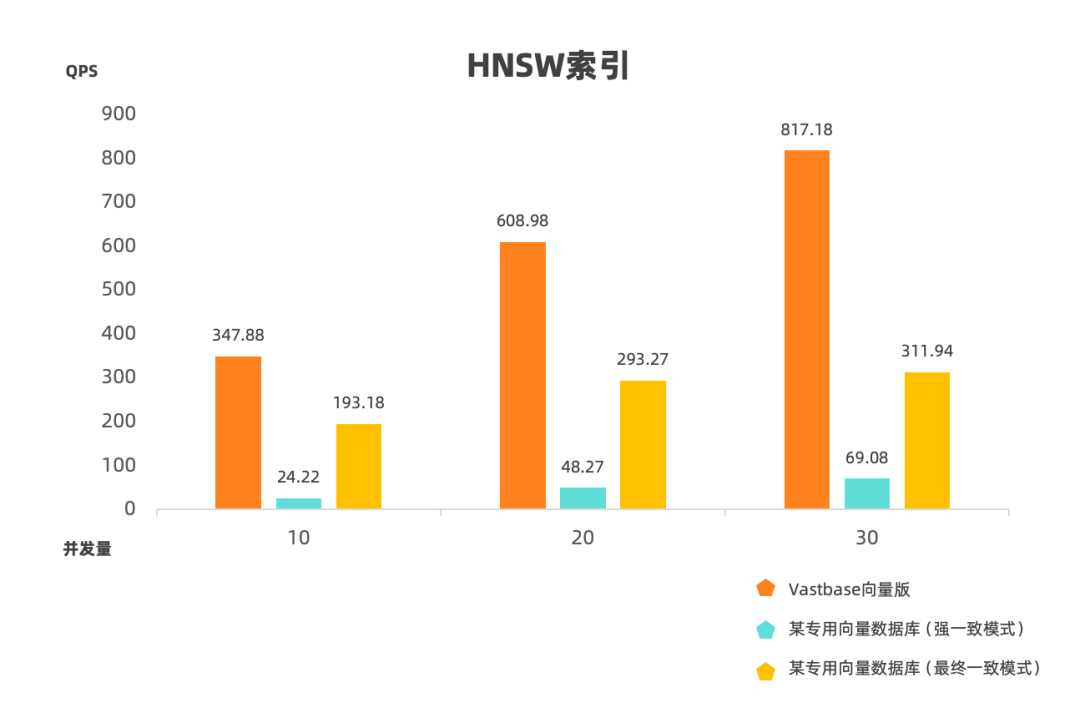
Vastbase向量版保有了关系型数据库的强一致性,即插入的数据即可查看。而某专用向量数据库在即刻可查(强一致模式)下,查询性能会大幅衰减。即刻可查(强一致模式)、同等召回率下,Vastbase向量版的QPS是某专用向量数据库的10~30倍。
高性能背后的“黑科技”
Vastbase向量版高性能的背后,是系统底层和算法层面的深度优化,实现了从算法到内核、从存储到检索的全方位技术突破。
1、通过构图算法、指令加速、索引优化、内存布局等技术,可以显著降低高维向量数据计算复杂度,让检索效率提升10-20%;
2、借助复杂场景预取、系统调度优化、广域冗余指令消除等机制,可以有效减少资源消耗,让系统并行计算效率提高15%;
3、利用多标签向标量联合检索能力,可以将查询精度提升15%。
通过上述一系列技术革新,Vastbase向量版成功实现了高维向量数据处理中的高效检索与计算,显著提升了系统的性能和精度,还大幅降低了资源消耗,为企业落地AI应用提供强有力的数据支撑。
未来以来,在当前AI和大模型的浪潮下,向量数据库不仅是智能时代的数据基座,更是推动技术创新的引擎。选择一款高性能的向量数据库,才能让数据检索更高效,让AI应用更智能!
