




凌晨六点,一条告警消息打破了寂静:夜间 Spark 批处理任务再次超时,库存数据未能按时更新。如果不及时处理,电商平台的客户投诉可能接踵而至。这不是偶发事件,而是技术团队的常态:面对引擎性能瓶颈,他们不得不频繁调整资源扩缩容,在业务稳定与成本控制之间艰难权衡;面对实时数据的场景,他们不得不临时搭建一个额外的流式数据链路,以支持 11.11 大促活动看板;他们还要达成每年平台降本增效的需求;他们夜复一夜,人力监控 Spark 的 ETL(提取、转换、加载)任务,确保系统底层不崩塌。Spark 体系是否已经跟不上时代的需求?我们似乎正站在一个技术的十字路口,需要重新审视,并决定是否继续依赖这位曾经的“老战友”。
技术的十字路口:Spark 的升级替换与抉择
以 Apache Spark 为代表的通用计算引擎,是通常的组装式架构大数据平台的核心引擎组件。其中“批处理”场景有着最大的数据处理吞吐量,是大数据领域的核心系统。其对处理引擎的效能要求很高、但通常人们对它的时效性也有很高的容忍度——慢一些没关系,只要能在夜间跑完一天的任务即可,不影响第二天业务团队对数据的分析工作。然而当大数据团队也无法容忍一个通常可以高容忍的工具的时候,是时候重新审视了,毕竟我们身处一个数据智能爆炸的时代。
本文将从企业的视角出发,回顾 Spark 的发展历程,剖析其价值与短板,并以 5 年的前瞻视角,探讨分析 Spark 相关的替换升级决策。
Spark 的历史贡献与目前的局限
在大数据技术的发展史上,Apache Spark 无疑是一个划时代的里程碑。作为继 Hadoop 之后最具影响力的开源大数据处理框架, Spark 彻底改变了企业处理海量数据的方式。
贡献:Spark 的历史价值
1.普惠分布式计算
Spark 的首要创新在于 RDD(弹性分布式数据集)概念的提出。在 Spark 出现之前,Hadoop MapReduce 将大数据处理牢牢锁定在磁盘 IO 的瓶颈上。每个 MapReduce 作业之间的数据都需要写入 HDFS,导致迭代计算效率极低。
// Spark RDD迭代计算示例 - PageRank算法var ranks = links.mapValues(v => 1.0)for (i <- 1 to 10) {val contribs = links.join(ranks).flatMap {case (url, (links, rank)) =>links.map(dest => (dest, rank links.size))}ranks = contribs.reduceByKey(_ + _).mapValues(0.15 + 0.85 * _)}
2.广泛的应用场景和生态能力
Spark 体系的一个突出特点在于其集成了多个组件,以覆盖大数据处理中的多样化需求,主要包括:
Spark Core:核心计算引擎,提供 RDD API 和分布式任务调度功能。 Spark SQL:支持结构化数据处理和 SQL 查询。 Spark Streaming:提供基于微批次的流处理能力。 MLlib:分布式机器学习库。 GraphX:用于图计算的引擎。
Spark 的现代挑战
随着业务需求的演变和云原生技术的兴起,Spark架构的一些固有局限性开始凸显。
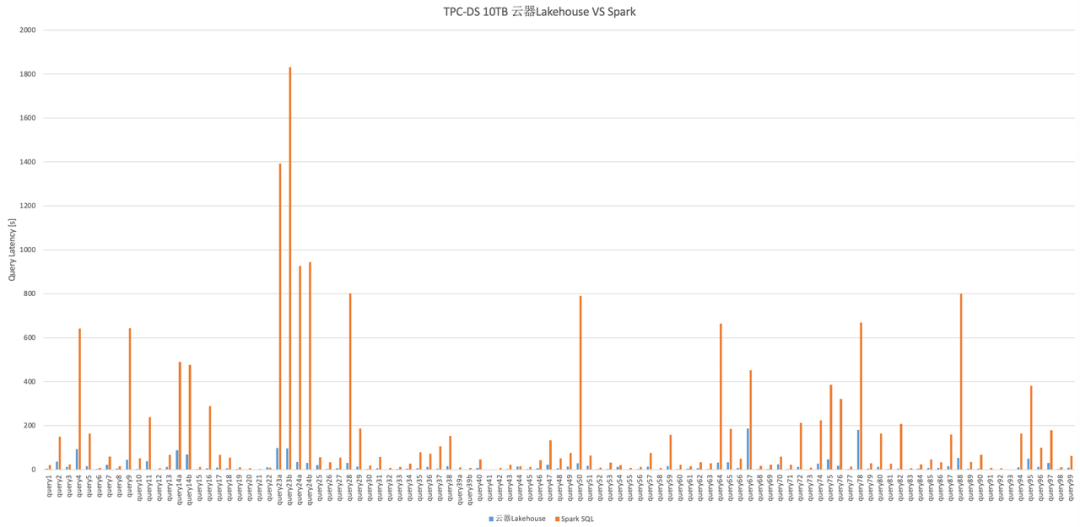
(图:TPC-DS 性能对比测试——云器Lakehouse 对比开源 Spark SQL 快约 10倍)
业界通过向量化引擎与软硬件协同优化,持续突破计算性能边界。当前基准测试表明,开源 Spark 与业界领先解决方案有约10倍的性能差距(参考 Databricks 引擎公布的测试https://www.databricks.com/product/photon,
和云器Lakehouse 公布的性能报告https://www.yunqi.tech/resource/blogs/lakehouse-performance)。
Spark的交互分析场景性能不足,与主流引擎有数十倍差距
在交互式分析和即席查询场景下,Spark 的表现远不如专门的分析引擎:
启动延迟高:Spark 作业启动需要秒级甚至分钟级时间,不适合快速查询。 小查询效率低:Spark 为大数据处理优化,小规模数据查询存在较大开销。 优化器局限:Spark 的 Catalyst 优化器在复杂 SQL 和半结构化数据场景下效果有限。
号称“流批一体”,实则“批流分离”
实际应用中,Lambda 架构具体呈现为分别构建批处理和流处理两套独立系统:在 Spark 批处理引擎旁另辟一条 Flink 的流处理通道。某些厂商称之为“流批一体”,但实则两种计算模式不仅逻辑分离,存储和元数据管理也各自独立,这种割裂带来了显著问题:
代码重复:相同的业务逻辑需在批处理和流处理中分别实现一次,增加了开发工作量和维护负担; 数据一致性挑战:两套系统可能因处理时机或逻辑差异导致结果不一致,给数据治理和下游应用带来隐患; 运维复杂度:企业需同时维护和监控两套系统,DevOps 团队面临更高的资源调配和故障排查压力。
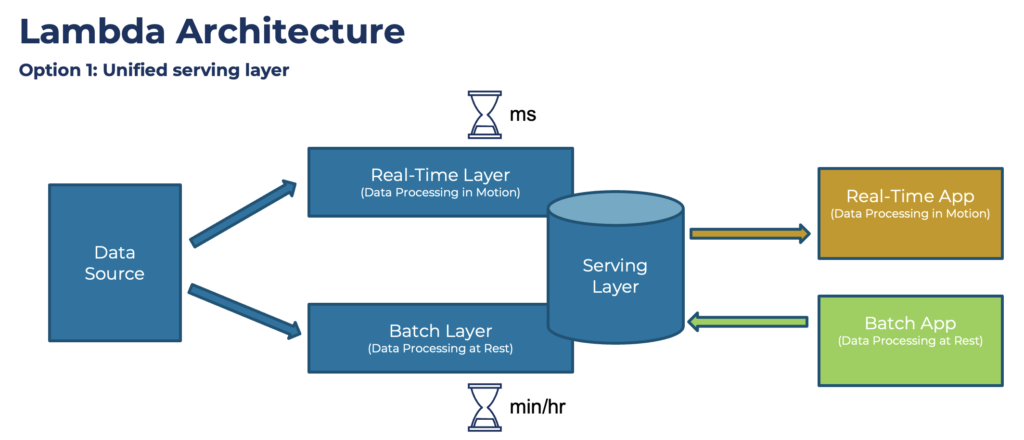
(图:常见 Lambda 数据平台架构图)
批处理向实时处理的改造难题
对于企业已有的批处理任务,向实时化改造的路径充满障碍:
代码语言的隔阂:Spark 的批处理(基于 RDD 或 DataFrame)和流处理(Spark Streaming 或 Flink)采用截然不同的抽象和不同的语法,开发者需重新适应流式思维,增加了学习成本。 状态管理的复杂:流处理引入了批处理中不存在的概念,如状态管理、水印(watermark)和迟到数据处理,这些要求对系统设计和容错能力提出了更高挑战。 测试与调试的困难:相比批处理的静态调试,流处理系统因其动态性和不确定性(如数据到达顺序)而更难测试和验证,增加了开发迭代的难度。
替换 Spark 的技术选型:关键因素与实践
技术决策者面临的关键问题是:如何设计改造升级 Spark 的策略与路径?笔者尝试按照技术思考因素和业务价值因素整理如下:
1.技术考虑因素
1.1考虑批流融合 ETL 的实现路径
“流批一体”听起来很好,但它真的实现了计算模式的统一吗?在实际场景中,许多方案——比如常见的 Spark 搭配 Flink 或 Spark Streaming——是将批处理和流处理拼接在一起,底层仍是 Lambda 架构的两套逻辑。这种方式看似解决了实时性需求,却带来了数据冗余、指标不一致和高昂的维护成本。Flink 与批处理代码的范式差异让重构成本超出预期数倍。”问题的根源不在于引擎本身,而在于这种“流批一体”只是表面的整合,而非真正的融合。
相比之下,笔者主张“流批融合”的方案。它依托新的增量计算技术实现,让同一套代码逻辑无缝适配批处理和流处理,避免了 Lambda 架构的割裂。以云器Lakehouse 的通用增量计算为例,它支持标准 SQL 的完整语义,允许开发者将传统批处理任务通过简单调整(如将 INSERT OVERWRITE 改为 CREATE DYNAMIC TABLE)转为分钟级增量处理。
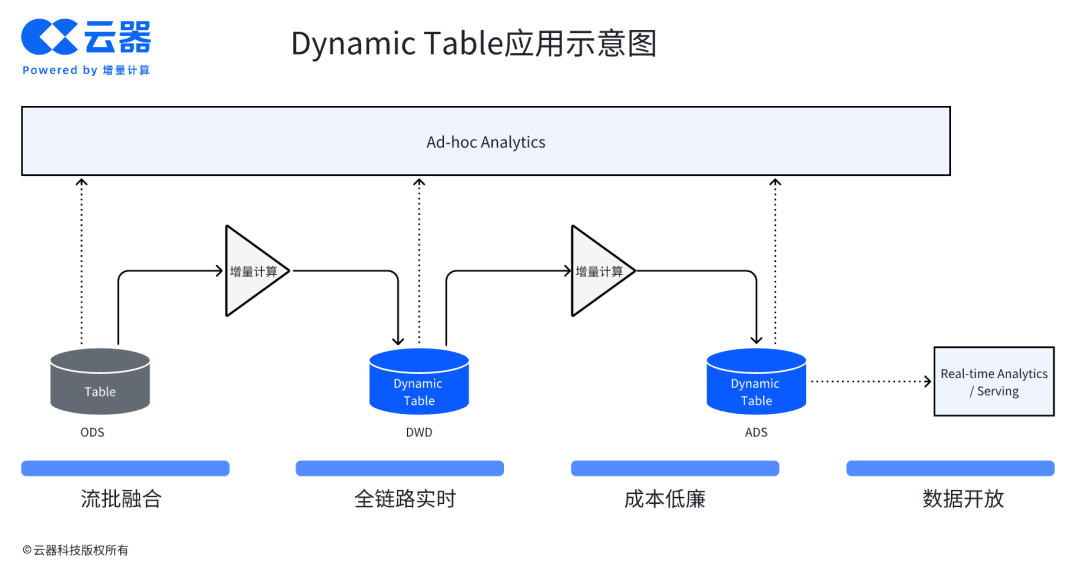
(图:Dynamic Table 应用示意图)
这种统一范式不仅消除了冗余,还确保了数据一致性。这正是我们需要重新审视差异的地方——笔者认为“一体化/融合”才是现代数据架构的方向。
1.2借助资源池化和弹性提高资源利用率
传统 Spark 集群的一个核心痛点是资源利用率低下。传统 Spark 集群(如 Spark on Yarn 固定集群)为了应对峰值负载,通常需要预先分配远超平均需求的固定资源,导致在非高峰时段,集群平均资源利用率可能仅为 20%-40%,造成大量计算和存储资源长期闲置。这种模式直接导致资源成本浪费,企业可能需要为 60%-80% 的未充分利用的资源持续付费,显著增加了总体拥有成本 (TCO)。
总结几个关键因素:
静态资源分配:Spark 作业通常需要预先分配固定资源,无法根据实际负载动态调整。 资源碎片化:不同规模的作业分散在集群中,导致大量资源碎片难以有效利用。 峰谷负载不平衡:业务负载的高峰期和低谷期资源需求差异巨大,静态集群无法灵活应对。
资源池化:将计算资源抽象为统一资源池,多租户共享,消除资源孤岛,大幅提高整体利用率。 弹性调度:根据实际工作负载动态分配资源,峰值自动扩容,低谷自动回收,确保资源使用始终匹配实际需求。
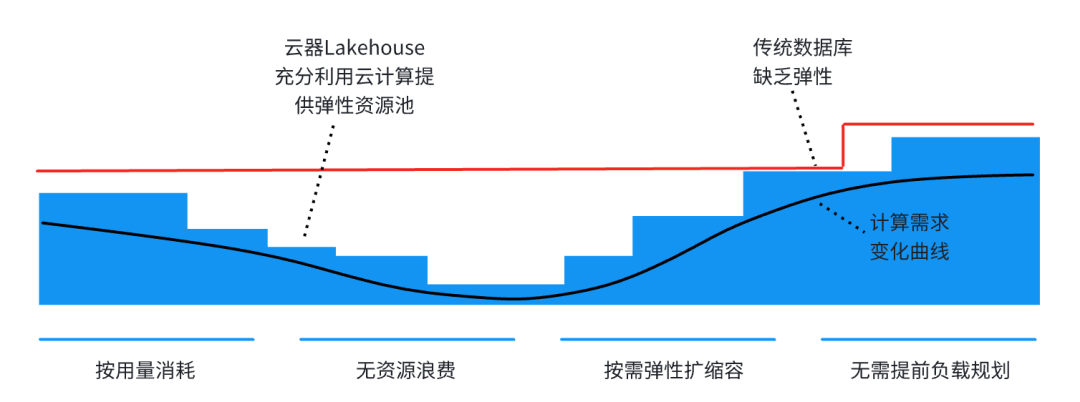
资源池化和弹性调度不仅带来成本节约,还能提供更有价值的业务能力:当面临突发业务需求时,系统可以快速扩展超出传统固定集群的处理能力,确保业务连续性。
对于跨多业务线的企业数据平台,资源池化还能实现更公平的资源分配和优先级管理,确保关键业务获得所需资源,同时避免单一业务线独占计算能力。
2.业务支持策略与价值考量因素
企业在规划数据平台时,往往低估了维护复杂系统的长期成本。尽管保持技术自主可控的观点有其道理,但现实是:并非所有组织都具备能力或必要性去运营一个复杂的 Spark 集群。就笔者所接触的企业中,了解到许多在 Spark 生产环境中每月至少遇到一次需专家干预的性能或稳定性问题,这揭示出自建架构的隐性负担。
维护 Spark 集群意味着什么?
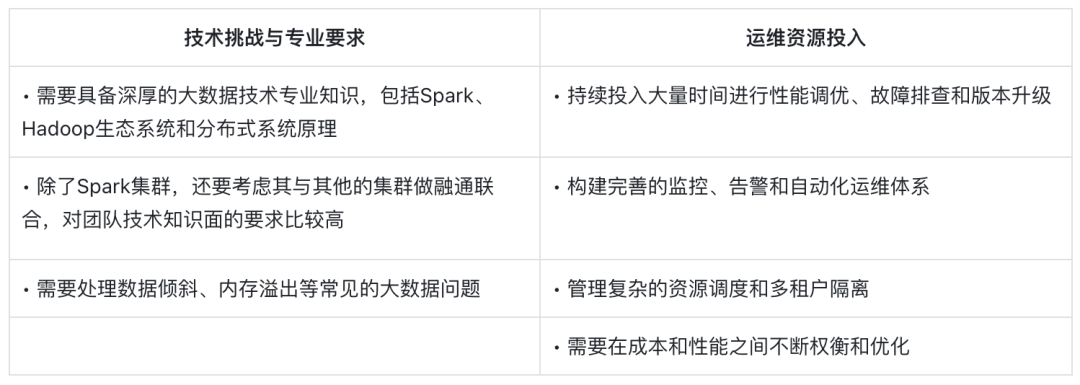
对于大多数组织而言,关键问题不是"我们能否维护 Spark",而是"维护 Spark 是否是最有价值的资源投入"。如果业务和数据资源的分析利用是企业核心竞争力,那么花费大量精力维护一整天 Spark + 生态系统是否是最佳的选择?选择托管服务或更自动化的替代方案可能更为明智,让宝贵的工程资源专注于业务创新而非基础设施维护。
然而,这并不意味着放弃技术掌控力。理想的替代方案应当在提供托管便利的同时,保留对企业的核心“数据”资产的管理,以及“无锁定”及无云锁定的技术方案。这个方向上,更推荐企业通过在数据湖和元数据的标准化上提升技术掌控,例如通过保持企业数据资产的质量,和可接入灵活的数据处理引擎,这样当 Spark 引擎无法达到业务所需的处理性能,可以无缝切换到更强的下一代引擎。关键是保证数据作为核心资产能够持续积累迭代,引擎可以换,数据不能换,这样的方案或是更优的架构选择。
Spark 升级或替换方案
下一个关键问题是:如何升级/替换现有 Spark 架构?以下是几种实用的技术路线,各有其适用场景和价值权衡。
Native 引擎插件优化性能
对于那些已在 Spark 上投入大量开发资源的企业,替换底层执行引擎而保留上层 API 是一种务实选择。例如 Apache Velox 通过Spark的接口做加速提升性能是一种方案。
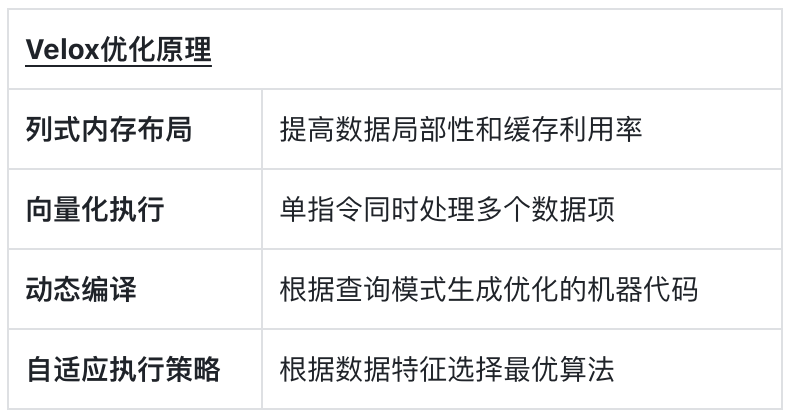
Velox 主要用于批处理优化,如下图所示,通过向量化计算加速批处理性能。
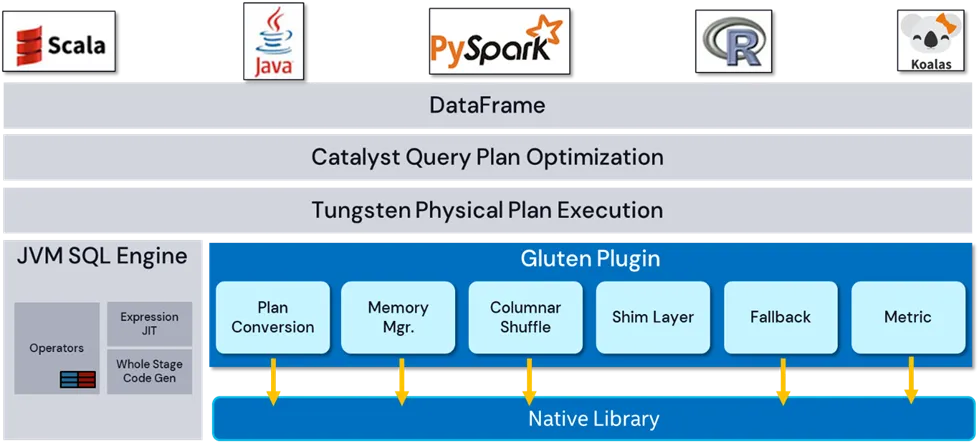
(图:Velox向量化批处理架构示意图)
但需要特别指出的是,通过这类方案来实现加速,并不是一个开箱即用的方案。业界的经验是需要对源代码做二次开发,开箱并不能确保 100% 可用。这类方向的探索更建议留给有资源和引擎自研能力的企业尝试。
数据不动,替换 Spark 批处理:引擎替换路径
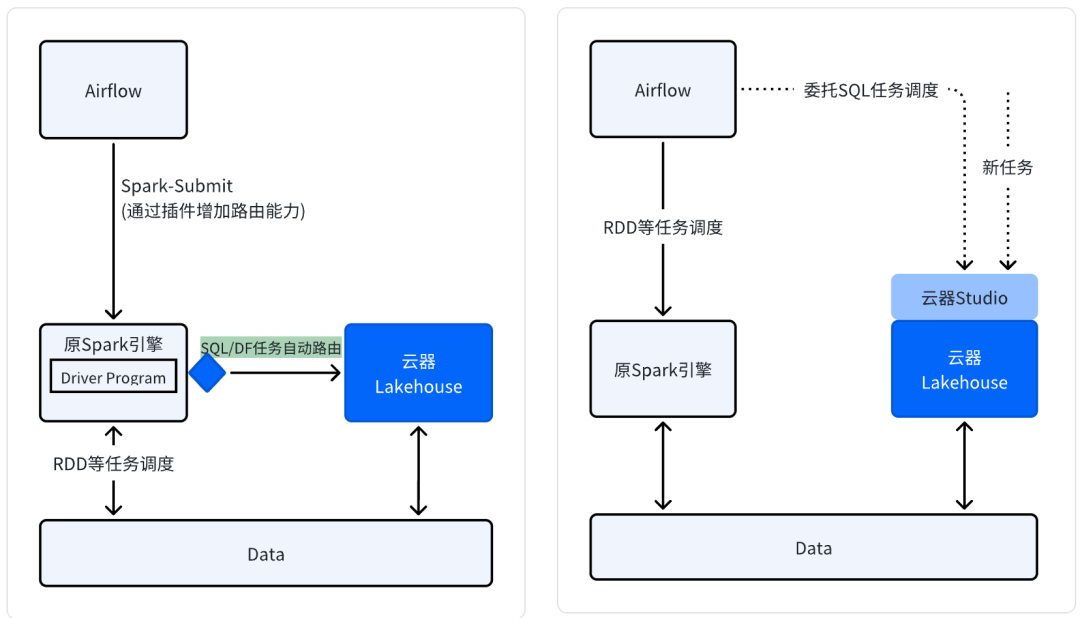
适用场景:
已有大规模复杂批处理工作负载,希望实现引擎的替换。 短期内无法完全重构现有 Spark 代码的企业。 以成本优化为主要目标的场景。
整体升级 Spark 到增量 Lakehouse:增量计算转型路径
相比前述的云原生引擎替换(性能提升但仍受限于批流分离),从 Spark 到云原生 Lakehouse 的整体升级是一条更彻底的转型路径。实现的 Kappa 架构的数据处理链路,如图所示:
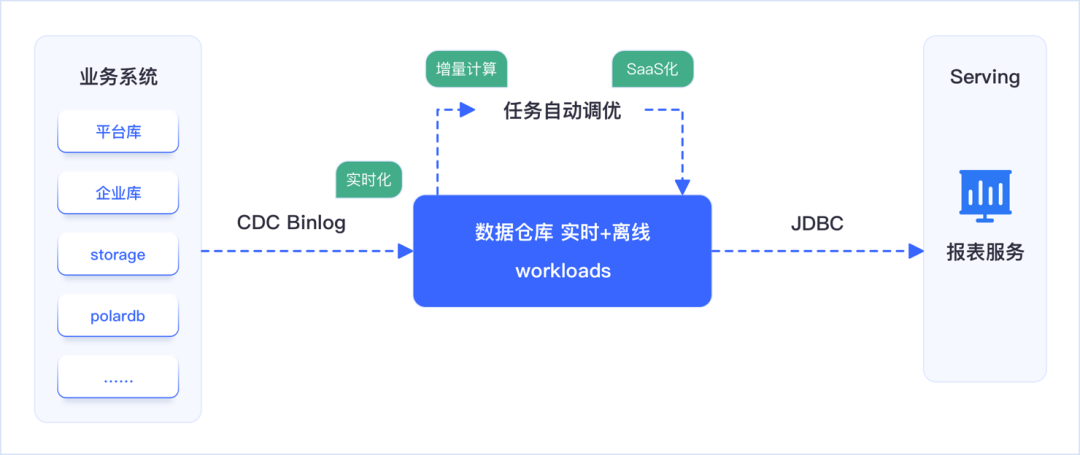
它不仅保留了 Spark 的既有投资(如 SQL 兼容性),还通过以下关键能力实现了无缝过渡和全面提升:
批流融合的统一范式:Lakehouse 摒弃了 Spark 的 Lambda 架构拼装,通过增量计算和 Kappa 架构,让批处理和流处理共享同一代码逻辑。例如,企业可以将现有 Spark 批处理任务调整为分钟级增量处理,无需重写代码即可满足实时需求。 动态资源调度:基于 Kubernetes 的云原生设计,Lakehouse 按需分配计算和存储,峰值时自动扩展,低谷时回收资源。某零售企业迁移后,资源利用率从 Spark 的 35% 提升至 80%,成本降低近 50%。 自动化运维的解放:从 Spark 的手动调优转向自动化监控和故障恢复,运维负担显著减少。例如,日志分析和告警由平台接管,工程师无需半夜处理集群故障。 开放标准的未来保障:采用 Iceberg 等开放格式,Lakehouse 避免了供应商锁定,确保与生态系统的高效集成和长期可维护性。
方案选择
基于上述分析,我们提供以下方案选择建议:
对于短期内注重成本优化的企业: 采用类似云器引擎替换 Spark 底层执行引擎 保持上层 API 和代码不变,降低迁移风险 获得立即可见的性能和成本改善 对于面临业务实时化转型的企业: 选择增量计算范式升级路径,彻底解决批流融合问题 采用分阶段策略,先建立基础架构,再逐步迁移应用 重点关注统一处理模型,降低长期维护成本 对于大型复杂数据生态的企业: 考虑混合策略,不同场景采用不同方案 高价值实时场景优先采用增量引擎 复杂批处理场景可先通过加速引擎优化 制定 3-5 年技术演进路线图,避免短视决策
🎁 云器Lakehouse限时福利
✅ 新用户赠200元体验代金券
✅ 免费领取《云器Lakehouse技术白皮书》
➤ 即刻从下方链接前往云器Lakehouse开始体验吧!
www.yunqi.tech/register
END
▼点击关注云器科技公众号,优先试用云器Lakehouse!
关于云器
往期推荐
